
稀有事件Logitsic模型及其在我国上市公司财务困境预测中的应用研究
2017-03-31 23:58张锡
时代金融 2017年8期


【摘要】我国上市公司一般具有较大的资产规模与较强的盈利能力,发生财务困境的概率较低,數据呈非平衡性。采用传统Logistic回归会受到因变量分布不平衡的影响。本文将西方学者在医学现象研究中普遍使用的稀有事件Logistic回归引入我国上市公司财务困境预测的研究中,根据财务困境发生实际概率确定样本观察单位的权重,构建Relogit回归模型。研究结果表明,Relogit模型预测效果优于传统Logistic模型。
【关键词】上市公司 财务困境 Logistic回归 Relogit回归
一、引言
Logistic回归模型由于其假设宽松、形式简洁、易于解释等优点,近年来被广泛应用于因变量为类别变量的各种预测、判别模型当中(付仲良等,2016;方匡男等,2016)。但在实际研究过程中,当因变量分布不均衡时,模型的残差方差较大,会导致传统Logistic模型产生有偏的预测结果(魏瑾瑞等,2016)。
国内学者在对我国上市公司发生财务困境的概率进行预测时,一般将上市公司当期是否被特别处理作为因变量(被ST、ST*公司Y=1,否则Y=0),上一期的各项财务指标作为自变量,使用传统Logistic模型回归得到判别模型(曾繁荣等,2014;宋晓娜等,2016)。但在我国,上市公司一般具有较大的资产规模与较强的盈利能力,发生财务困境的概率很低,2016年我国A股上市公司发生财务困境的概率不足2%。使用传统Logistic回归模型的效果也就打了折扣。针对这一问题,我们虽然可以通过抽样的方法提高建模样本中发生财务困境公司的比例,但这样做一方面会丧失许多优质上市公司的数据,减少样本量;另一方面,样本配比的选择也没有公认的标准。
与此同时,西方学者Asher et al.(2011),Haem et al.(2014)在医学现象研究中开始使用稀有事件Logistic回归(Rare Events Logistic)方法。其思想是基于稀有事件发生的概率,对传统Logistic回归结果进行校正。具体校正方法分为先验校正和加权校正。Prentice和Pyke(1979)首先提出了根据总体中因变量Y=1的抽样概率进行先验校正(prior correction)的Relogit方法。由于样本选择容易产生偏差,抽样概率与总体概率之间存在难以克服的差异,Zare et al.(2013)又在此基础之上提出了加权校正(Weight Correction)的Relogit方法。相比于传统Logistic回归模型,Relogit模型根据实际概率确定样本观察单位的权重,并且允许更大的建模样本,模型的估计更加准确。
考虑到我国上市公司发生财务困境概率小于10%,满足稀有事件的定义标准(赵晋芳等,2011)。同时,本文的研究对象包含了2016年A股的所有上市公司,样本量满足大样本条件,在这种情况下加权校正的模型精度要高于先验校正,因此本文使用加权校正的Relogit(Weight Correction Relogit)方法进行研究,并与传统Logistic回归分析所得结果进行比较。
二、Relogit方法
实证研究中,当因变量为二分类变量,自变量为连续变量或虚拟变量时,传统Logistic方法可以将因变量Y=1的概率表示为
P(X)=■
其中,X1为自变量的观测值,α、β分别为截距项和回归参数向量。传统Logistic回归系数的极大似然估计值β具有一致性、渐近有效性和渐近正态性,并且在样本因变量Y的两类取值频率相等时建模效果最为理想。
但对于上市公司而言,大部分公司处于财务健康状态(Y=0),而出现财务困境的上市公司所占比率很小(Y=1)。这会导致传统Logistic回归在参数估计和概率预测产生偏差。基于前文所述,本文采用加权校正的Relogit方法进行实证分析。这里简要介绍加权校正的具体步骤。
研究中可能存在由于样本选择导致的总体概率τ与样本概率■存在差异,加权校正(Weight Correction)则可以通过对样本观察单位给予合适的权重来修正选择偏倚造成的影响。具体而言,对样本中Y=1的观察单位给予权重w2=τ/■,对Y=0的观察单位给予权重w0=(1-τ)/(1-■)。因此,修正后的加权对数似然函数为
L=w■■ln(P■)+w■■ln(1-P■)
L=■wiln(1+exp[(1-2yi)(α+x'β)])
其中,wi=wiyi+w0(1-yi)
此外,Gary King和Langche Zeng(2001)还提出了基于小样本Relogit回归的MCN校正法,考虑到本文使用的数据具有大样本性质,在此不对其进行过多讨论。
三、实证分析
(一)数据和变量
本文的样本选取了2016年中国A股所有上市公司进行研究,所有数据均来自于同花顺iFind数据库。为避免样本企业同时发行A、B(H)股所带来的数据不一致,统一取A股市场的数据进行研究。删除数据缺失样本后,实际样本共包含2370家上市企业,其中正常公司(Y=0)2318家,财务困境公司(Y=1)52家。财务困境公司所占比例为2.19%,满足“稀有事件”的定义条件。
由于本文选取了具有高频变动特点的股票市场相关指标作为解释变量,若采用面板数据研究容易忽略不同年份宏观政策、市场背景不同对指标体系的影响,对模型结果所造成的误差。因此我们最终选择截面数据进行研究,通过我国上市公司2015年的所公布的企业财务信息,预测其2016年发生财务困境的概率。
通过参考目前中国银行规定的企业信用评级及国外权威的标准普尔评级指标体系,反映企业财务状况的指标应对其营运能力、偿债能力、盈利能力、发展能力合理评价,同时参考国内现有文献,初步确定的自变量如表1所示。
表1 模型指标的选择
■
(二)变量的筛选
由于數据中的无关变量和多余变量会对模型自由度、预测精度造成负面影响,且过多的财务指标之间本身容易产生共线性问题,因此有必要对初步确定的自变量进行筛选。这里参考史小康和何晓群(2015)使用的数据离散化的筛选方法。数据离散化是指将连续性的变量转化成为有序离散变量,史小康和何晓群(2015)采取的是Fisher精确检验对数据进行离散化处理。如果某一个连续变量经过数据离散化后最终被合并为单一有序变量,则说明这个连续变量与因变量独立,那么这个变量应该被剔除。这里先介绍2x2列联表的Fisher检验。
假定2x2列联表边际频数n1.,n2.,n.1,n.2都是固定的,在两个属性独立的零假设下,给定边际频率时,已知四个频数中的任意一个可以求出其他三个,此时列联表的条件概率只依赖于任一频数的确定。在零假设下,该概率满足超几何分布,对任意的i=1,2和j=1,2,它可以写成:
P(n■)=■=■
其中,n_表示总的频数,如果尾概率P(nij)小于显著性水平,则应该拒绝零假设,这就是2x2列联表Fisher精确检验的基本思想。
连续变量离散化的主要目的是简化数据结构,更好地概括原变量的特征。假定某个变量被离散化为若干有序变量,每个有序变量都对应了若干财务正常(Y=0)或者出现财务困境(Y=1)的公司,这样就可以得到每个区间的相对频数。一个合理的离散算法最终得出的有序变量,相邻离散变量间的相对频数应该有显著差异。
这里的数据离散化方法利用Fisher精确检验来确定两个相邻离散变量的相对频数差异是否显著。如果不显著,将这两个离散变量对应的样本进行合并。该算法包括初始化和自下向上的离散变量合并。初始化是将所有个体按照需要离散化的连续变量的取值从小到大进行排序,然后每个值自成一个有序离散变量,所对应的样本也落入区间之内。合并过程包括两个步骤:
第一,对顺序相邻的离散变量间进行Fisher精确检验,得到所有双边检验p值;
第二,对计算出最小p值的相邻离散变量进行合并,这两个步骤反复进行,直到所有相邻离散变量Fisher精确检验的p值大于预先设定的水平为止,这时数据离散化过程完成。如果最终所有的有序离散变量对应的样本合并在同一个区间,表示该变量与因变量独立,将其剔除。这里我们将显著性水平设定为0.05。
数据离散化结果显示,“速动比率”、“产权比率”、“加权净资产收益率”、“应收账款周转率”、“营业收入增长率”、“资本积累率”、“股票日均换手率”、“分市场年Beta值”这八个变量最终被合并为一个区间,应该被剔除。最终选定的自变量见表2。
表2 模型指标的选择
■
(三)模型的建立
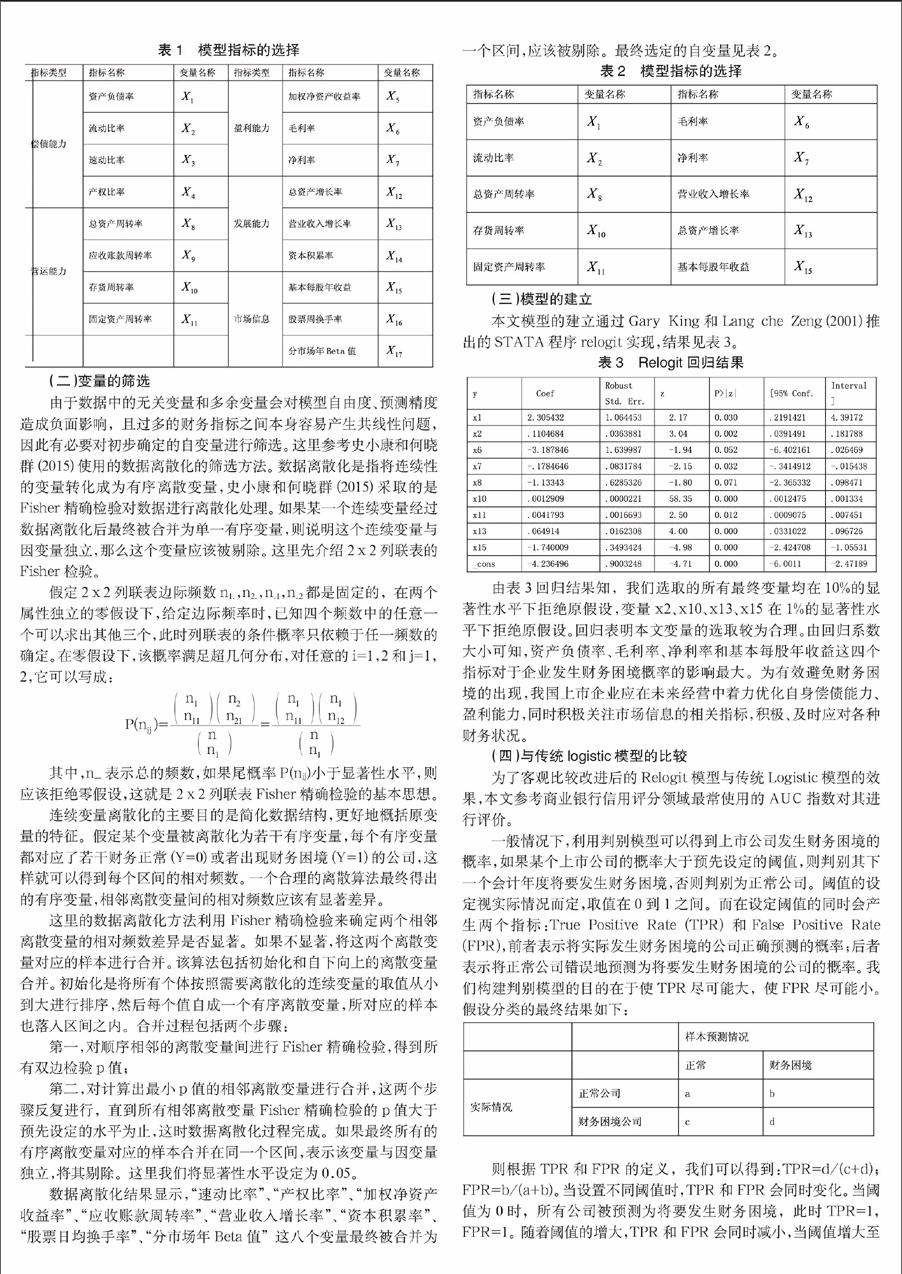
本文模型的建立通过Gary King和Lang che Zeng(2001)推出的STATA程序relogit实现,结果见表3。
表3 Relogit回归结果
■
由表3回归结果知,我们选取的所有最终变量均在10%的显著性水平下拒绝原假设,变量x2、x10、x13、x15在1%的显著性水平下拒绝原假设。回归表明本文变量的选取较为合理。由回归系数大小可知,资产负债率、毛利率、净利率和基本每股年收益这四个指标对于企业发生财务困境概率的影响最大。为有效避免财务困境的出现,我国上市企业应在未来经营中着力优化自身偿债能力、盈利能力,同时积极关注市场信息的相关指标,积极、及时应对各种财务状况。
(四)与传统logistic模型的比较
为了客观比较改进后的Relogit模型与传统Logistic模型的效果,本文参考商业银行信用评分领域最常使用的AUC指数对其进行评价。
一般情况下,利用判别模型可以得到上市公司发生财务困境的概率,如果某个上市公司的概率大于预先设定的阈值,则判别其下一个会计年度将要发生财务困境,否则判别为正常公司。阈值的设定视实际情况而定,取值在0到1之间。而在设定阈值的同时会产生两个指标:True Positive Rate(TPR)和False Positive Rate(FPR),前者表示将实际发生财务困境的公司正确预测的概率;后者表示将正常公司错误地预测为将要发生财务困境的公司的概率。我们构建判别模型的目的在于使TPR尽可能大,使FPR尽可能小。假设分类的最终结果如下:
■
则根据TPR和FPR的定义,我们可以得到:TPR=d/(c+d); FPR=b/(a+b)。当设置不同阈值时,TPR和FPR会同时变化。当阈值为0时,所有公司被预测为将要发生财务困境,此时TPR=1,FPR=1。随着阈值的增大,TPR和FPR会同时减小,当阈值增大至1时,没有公司被预测将会发生财务困境,此时TPR=0,FPR=0。
通过上述过程可知,TPR与FPR存在同向变化的关系。由于我们构建判别模型的目的在于使TPR尽可能大,使FPR尽可能小。因此我们可以根据不同阈值下,TPR和FPR取值作出二者的ROC曲线图。
■
当ROC曲线越远离直线y=x,表明可以通过设置合理阈值,增加较少的FPR,来增加较多的TPR,因此模型效果越好。信用评分领域现有的习惯做法是将ROC曲线与x轴之间的面积定量地评价模型的效果,记作AUC。AUC值越大,表明模型拟合状况越好。
为了客观比较本文建模使用的加权校正Relogit模型与传统Logistic模型的建模效果,我们采用相同样本和解释变量同时进行Relogit回归和传统的Logistic回归,分别得出了二者的ROC曲线。通过下图可以看出,Relogit模型AUC值为0.9115,大于传统Logistic模型的AUC值(0.9093)。说明在因变量分布不均衡的条件下,采用加权校正的Relogit模型要略优于传统Logistic模型。
■
四、结论
Logistic回归模型在社会科学领域有着广泛的应用,也是近十年来在上市公司财务困境预测领域最受亲睐的模型,但它在因变量分布不平衡的数据中残差方差较大,预测效果降低。本文采取加权校正的方法,对传统Logistic回归模型进行了改进,构造了能更好适应稀有事件偏态数据特征的Relogit模型。通过ROC曲线和AUC值可以发现,Relogit模型对于大样本稀有事件的拟合效果要优于普通Logistic回归模型。由于Relogit模型在实际应用中兼具传统Logistic模型相似的可操作性和可解释性,这也为我们在该领域今后的实证中提供了一种可行的方法。但还须注意,上市公司财务困境预测领域选择的方法较多,譬如神经网络模型、支持向量机等(鲍新中等,2013;倪志伟等,2014),它们各自使用的是不同的算法,不存在所有情况下都是最优的模型,因此,在实际操作中,我们还须针对实际情况和样本数据的特征,对各种方法进行科学地比较后,再做出相应的选择。
参考文献
[1]Haem,E.,Heydari,S.,et al,“Ovarian Cancer Risk Factors in a Defined Population Using Rare Event Logistic Regression”,Middle East Journal of Cancer,2015,6(1),1-9.
[2]Asher G.W,Archer J.A,Ward J.F.,Scott I.C.,and Littlejohn R.P.,“Effect of melatonin implants on the incidence and timing of puberty in female red deer”,Animal Reproduction Science,2011,123 (3-4),202-209.
[3]Zare,N.,Haem,E.,Lankarani,K.,Heydari,S.,Barooti,E.,“Breast Cancer Risk Factors in a Defined Population: Weighted Logistic Regression Approach for Rare Events”,Journal of Breast Cancer,2013,16 (2),214-219.
[4] King G.,Zeng L.C.“Explaining rare events in international relations”,International Organization,2001,55(3):693-715.
[5] Prentice R.L.,Pyke R.,”Logistic disease incidence models and case-control studies”,Biometrika,1979,66(3):403-411.
[6]付仲良,楊元维,高贤君,赵星源,逯跃锋,陈少勤.利用多元Logistic回归进行道路网匹配[J].武汉大学学报(信息科学版),2016,02:171-177.
[7]魏瑾瑞,吕晓云.Logistic模型对非平衡数据的敏感性:测度、修正与比较[J].统计研究,2016,02:79-85.
[8]方匡南,范新妍,马双鸽.基于网络结构Logistic模型的企业信用风险预警[J].统计研究,2016,04:50-55.
[9]宋晓娜,黄业德,张峰.基于Logistic和主成分分析的制造业上市公司财务危机预警[J].财会月刊,2016,03:67-71.
[10]赵晋芳,罗天娥,范月玲,曾平,仇丽霞,刘桂芬.稀有事件logistic回归在医学研究中的应用[J].中国卫生统计,2011,06:641-644.
[11]史小康,何晓群.有偏logistic回归模型及其在个人信用评级中的应用研究[J].数理统计与管理,2015,06:1048-1056.
[12]倪志伟,薛永坚,倪丽萍,肖宏旺.基于流形学习的多核SVM财务预警方法研究[J].系统工程理论与实践,2014,10:2666-2674.
[13]曾繁荣,刘小淇.引入非财务变量的上市公司财务困境预警[J].财会月刊,2014,08:25-30.
[14]鲍新中,杨宜.基于聚类-粗糙集-神经网络的企业财务危机预警[J].系统管理学报,2013,03:358-365.
作者简介:张锡(1993-),女,汉族,安徽阜阳人,毕业于华中农业大学,研究方向:会计学。
