
一种利用语义相似特征提升细粒度情感分析方法
2017-04-14 00:46陈自岩傅兴玉
计算机应用与软件 2017年3期
陈自岩 黄 宇 王 洋 傅兴玉 付 琨
1(中国科学院大学 北京 100049)2(中国科学院空间信息处理与应用系统重点实验室 北京 100190)
一种利用语义相似特征提升细粒度情感分析方法
陈自岩1,2黄 宇2王 洋2傅兴玉2付 琨2
1(中国科学院大学 北京 100049)2(中国科学院空间信息处理与应用系统重点实验室 北京 100190)
情感分析主要研究人们正面或负面情感的表达。随着网页文本的爆炸式增长,情感分析在学术研究和实际应用中都成了热门话题。细粒度的情感分析方法通常采用两步策略,从而极易产生自底向上的层叠错误问题。为了解决这个问题,研究者们提出了一种基于马尔科夫逻辑的细粒度的情感分析联合框架。其中最常用的传统全局特征是自底向上和自顶向下特征。为了更好地提升细粒度情感分析的联合学习能力,一种新的语义相似特征被提了出来,中文情感分析数据集上的实验证明,此特征能对情感分析联合框架带来极大的改进。
细粒度的情感分析 马尔科夫逻辑 语义相似特征
0 引 言
情感分析也叫观点挖掘,主要用来分析人们在传达信息时所含的情绪观点,以及对人们的态度、感情色彩进行判别或者评估[1]。随着互联网技术的进步,情感分析自2000年以来呈现出蓬勃发展的趋势,支持向量机(SVM)、条件随机场(CRF)和基于词典等方法的提出,使得情感分析在舆情监控、异常事件监测、金融预测等领域得到广泛应用。
通常,情感分析按粒度可以分为文档级、句子级、子句级和短语级。文档级的情感分析旨在对整个文档分成正面、负面及中立,其主要应用在微博等短文本中[2-3],但在长文本中则显得比较粗糙,因此细粒度的情感分析应运而生。例如,文献[4]针对句子级的情感分析提出了一系列的方法来挖掘产品评论;文献[5]采用两步策略分析短语的情感倾向。由于一个句子中可能表达不止一种情感倾向,因此本文选择子句级的情感分析粒度。子句级的情感分析最重要的预处理工作是子句分隔,文献[6]选择语篇分隔理论作为基本的分类单元;文献[7]则粗略地用汉语逗号进行子句分隔。
传统的细粒度情感分析方法经常采用链式结构的两步策略,即主观分类和极性分类。前者旨在识别出具有主观性的句子或者短语,后者则对识别出的主观性句子或短语进行正面或负面的分类。这种链式结构极易产生层叠错误问题,如果一个没有情感倾向的句子或者短语在主观分类中被误判成主观的,其不可避免地影响极性分类的性能。因此文献[7]提出了一种基于马尔科夫逻辑[8]的细粒度情感分析联合框架,使用自底向上和自顶向下的全局特征将主观分类和极性分类进行联合学习,从而减少了链式结构带来的层叠错误。此文献中还引入了一种二元结构特征,认为同一句子中相邻的子句很有可能具有相似的情感极性,但这种假设在相互转折的子句中就不再成立,如“这本书很贵,但内容确实很精彩”中,两个子句具有相反的极性。
针对以上问题,本文提出了一种新的语义相似特征,认为两个子句在语义上的相似度越高,越具有相同的极性。为了度量两个子句的语义相似度,本文提出了一种基于全局向量GloVe(Global Vectors)[9]模型的相似度计算方法。首先利用全局向量模型在大规模未标注数据上训练词向量,然后采用加权和的方法计算子句向量,最后计算子句向量之间的余弦相似度作为子句间的语义相似度。马尔科夫逻辑是一种统计关系表征语言,其将一阶逻辑融入到无向图模型中,从而能使丰富的特征或领域知识融合在一起联合学习推导。语义相似特征是一种全局特征,可以用马尔科夫逻辑的全局表达式进行表示,从而提升子句间情感分类的联合学习能力。最后本文在谭松波的中文情感分析语料集(ChnSentiCorp)上进行实验,为了满足本文的子句级的情感分析,我们引入了一种人工标注计划对数据进行再加工,从而获得子句级上的标注。
1 马尔科夫逻辑联合模型
本节将简要介绍基于马尔科夫逻辑的子句级情感分析的联合学习框架,其基本思想是将主观分类和极性分类进行隔离,并分别用不同的局部特征集进行独立学习。然后利用全局特征再将主观分类和极性分类整合到一个完整的网络中统一学习,其基本原理可以用图1表示。

图1 子句级情感分析的联合框架
1.1 马尔科夫逻辑网
马尔科夫逻辑网是一种强大的统计关系表征语言,其能将一阶逻辑和马尔科夫随机场进行结合。在一阶逻辑中,一个表达式只代表一个布尔值,即成立与不成立。而马尔科夫逻辑放松了这一限制,其对每个一阶逻辑表达式赋一个权重,在训练阶段,越多的数据满足某一表达式,则其对应的权重越大,对于不满足的则通过惩罚减小权重。一个马尔科夫逻辑网由一系列的(Fi,wi)对组成,其中Fi是一阶逻辑表达式,而wi是此一阶逻辑表达式对应的权重值,其联合概率可以表示为:
(1)
其中,F是一阶逻辑表达式的数目,ni(x)是满足表达式Fi成立的数目。
每个表达式由一系列的一阶变量,谓词和逻辑连接符组成,如:
wicontainadj(s)⟹subjective(s)
此表达式隐含的意义是如果一个子句中存在形容词,那么这个子句很有可能带有主观性,权重wi代表了表达式成立的可信度。表达式中s是一个变量,代表每个子句,containadj是已知谓词,而subjective是隐含谓词,需要从已知谓词中推导出来。
1.2 局部表达式
局部表达式用来由已知谓词推导隐含谓词,本节通过定义一系列的局部特征来设计局部表达式,从而实现主观分类和极性分类的分别训练。表1列出了所用到的谓词,其中已知谓词描述了所抽取的特征。极性分数的计算方法可以参考文献[10]。

表1 所用到的谓词
表2和表3分别列出了主观分类和极性分类中的局部表达式,其中加号“+”表示对于变量的不同取值赋以不同的权重值。从两个表中看出分成两个独立步骤的好处是能根据具体的分类任务设计有效的局部特征。

表2 主观分类中的局部表达式

表3 极性分类中的局部表达式
1.3 全局表达式
上节采用局部表达式分别学习了主观分类和极性分类,而这两个步骤之间存在着相辅相成的联系,马尔科夫逻辑通过定义全局表达式,可以使两个独立的局部分类器融入到统一的网络框架中,其中最常用的两个全局特征是自底向上(式(2))和自顶向下(式(3))。
sentiment(s,sen+)⟹polarity(s,″non″)sentiment(s,sen+)⟹!polarity(s,″non″)
(2)
polarity(s,po+)⟹sentiment(s,sen+)
(3)
在自底向上的推导过程中,我们给主观分类的变量赋予分离的权重,从而使主观与客观的子句都能进入到极性分类阶段。而自顶向下的推导为主观分类提供了反馈信息,减少了因主观分类传播下来的层叠错误问题。
除了以上两个全局特征,文献[7]还引入了一种二元结构特征,其认为相邻的子句之间具有相同的情感极性,相应的表达式为:
bigram(s1,s2)∧polarity(s1,″pos″)⟹polarity(s2,″pos″)bigram(s1,s2)∧polarity(s1,″neg″)⟹polarity(s2,″neg″)
(4)
其中已知谓词bigram(s1,s2)表示两个子句之间的相邻性。这种二元结构特征只是单纯地依赖结构上的相邻性,并没有充分考虑子句间的语义描述,因此在遇到语义表达相反的子句时就会出现问题。
2 语义相似特征
马尔科夫逻辑依靠全局表达式将各个子任务整合到一个完整的框架中,好的全局特征可以提升模型的联合学习能力,本节将详细介绍一种有效的全局特征,其能充分利用子句间的语义相似信息,提升各个子句间的相互推导能力。本节首先介绍怎样利用全局向量模型获得词在语义空间上的线性表征(即词向量),然后根据词向量来获得子句向量,继而计算子句之间的余弦相似度,并将其作为子句间的语义相似信息。
2.1 全局向量模型
在大规模未标注数据中,词与词之间的共现统计是非监督学习词向量的最直接也是最重要的特征。全局向量模型是一种能直接捕获这种特征来训练词向量的有效方法,其基本原理是首先通过词的共现统计形成一个共现矩阵Xij,其中每个元素代表词i和j之间的共现程度,然后设计一系列的函数去近似共现概率,由于词向量空间具有内在的线性结构,因此这些函数可以用下式表示:
(5)
其中,w∈d表示词向量,Pik表示词与词之间的共现概率。为了训练词向量,文献[9]中提出了一种最小方差回归模型作为代价函数,并用AdaGrad获取最优化结果。
2.2 语义相似度计算
通过词向量的加权和,我们可以得到子句向量,由于情感词在子句中的重要性,我们给其赋予较大的权重,用公式表示如下:
(6)
其中,M表示子句中情感词的个数,N表示子句中其它词的个数。由此可以得到子句间的语义相似度为:
(7)
假设子句间的相似度越高,其表达的感情色彩越相近。因此在联合学习之前,我们在整个数据集中找到与每个子句语义相似度最高的子句,并将它们放在如下的全局表达式中:
similarity(s1,s2)∧polarity(s1,″pos″)⟹polarity(s2,″pos″)similarity(s1,s2)∧polarity(s1,″neg″)⟹polarity(s2,″neg″)
(8)
其中已知谓词similarity(s1,s2)表示两个子句之间在语义上的相似性。与公式中的二元结构特征相比,语义相似特征更是一种真正意义上的全局特征,其不再单纯依赖结构上的相邻性,而是在整个数据集中寻找语义上的相似信息,从而更好地提升联合学习的能力。
3 实 验
3.1 数据集
选择谭松波的中文情感分析数据集(ChnSentiCorp)[11],并在子句级上进行再次标注。中文情感分析数据集主要来自携程的宾馆评论、当当的书籍评论和京东的笔记本电脑评论,共有一万多篇,每一篇都有文档级的正负极性标注。为了满足子句级情感分析的需求,选取了覆盖三个类别、长短不齐的300篇文档,同时邀请了三个与本研究无关的标注者对这些文档进行子句判别,同时对每个子句赋予正面、负面、中立等类别的标注。最终形成了4642个子句,其中34%为正面、47%为负面及19%为中立。为了评估三个标注者的标注可信度,我们引入了Fleiss’skappa[12],其能有效地衡量多个标注者标注数据的一致性。对于我们的数据,获得了0.78的Fleiss’skappa值,这个数值基本接近0.8的完美标注。
3.2 实验设置
本实验的流程如图2所示,其中采用现有的系统“ICTCLAS”[13]进行分词与词性标注,并采用基于词典的方法检测否定词、程度副词及观点词。词向量的训练是在一万多篇原始数据集上进行,词向量的维度设置为50,迭代训练次数为100次。最后引入开源工具“MarkovtheBeast”实现马尔科夫逻辑的联合学习与推导。为了验证语义相似特征的有效性,我们设计了两个模型:Base_MLN和Similarity_MLN。其中前者采用二元结构特征,而后者采用语义相似特征。
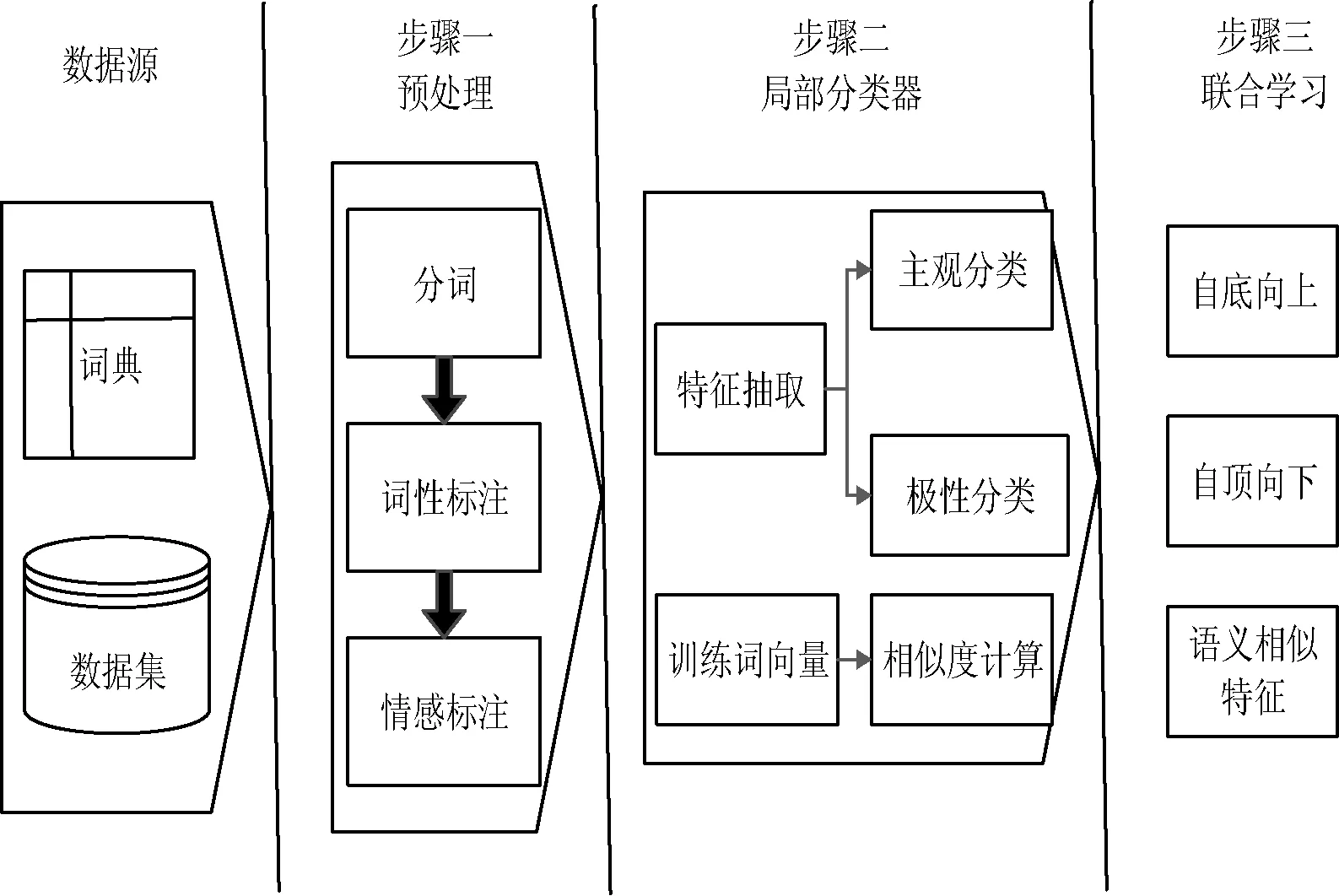
图2 实验流程
3.3 实验结果
由于子句级的情感分析的标注费时费力,因此数据量比较小,为了避免小样本产生的过拟合现象,我们采用十折交叉验证。这个数据集被分成十等分,每一次测试,我们选择其中9份作为训练集,另外一份作为测试集。我们采用正确率(A)、准确率(P)、召回率(R)和F1值来评估方法的有效性。表4和表5分别列出了主观分类和极性分类的结果。
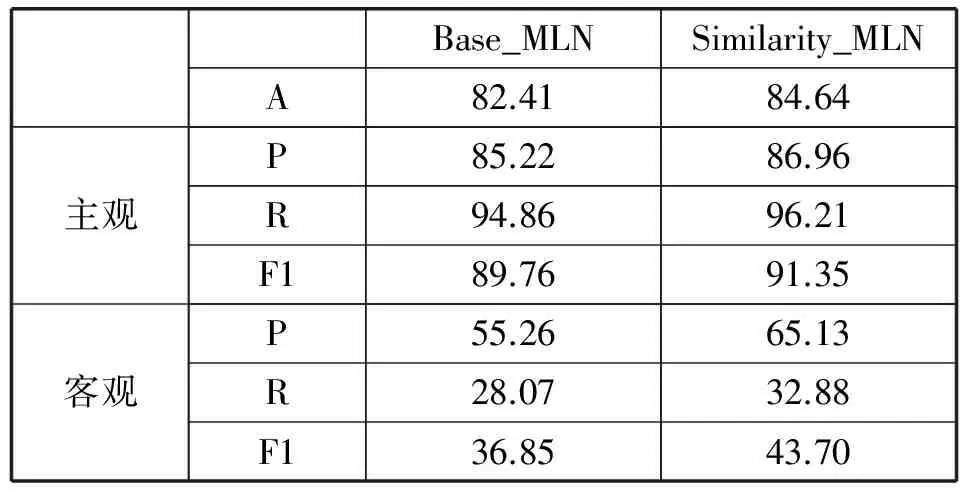
表4 主观分类结果
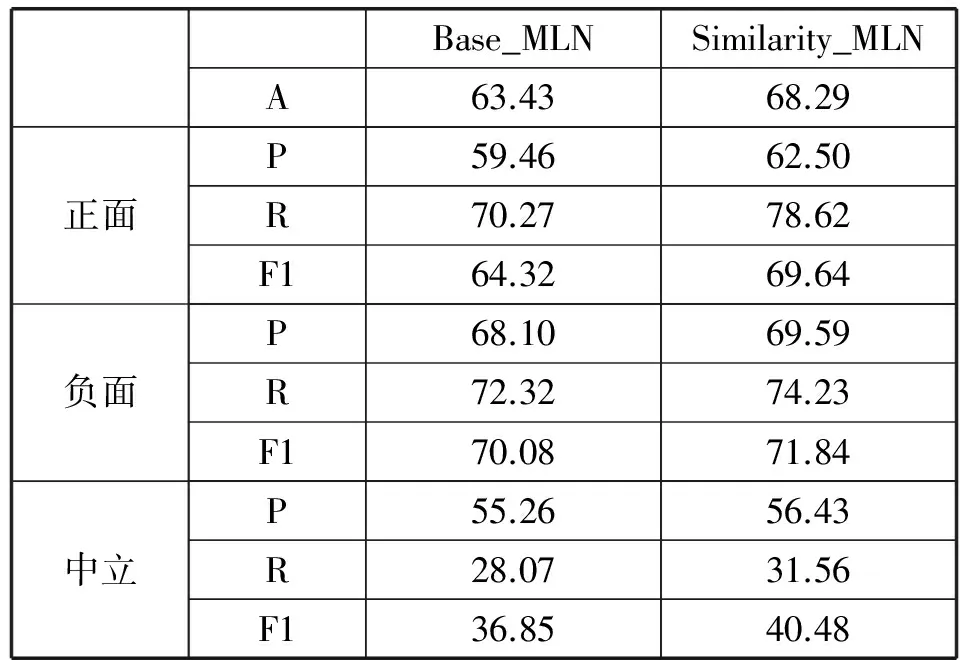
表5 极性分类结果
从以上两个表中可以看出Similarity_MLN在主观分类中提高了约2.23%的正确率,而在极性分类中则提高了约4.86%的正确率,这充分表明了语义相似特征的有效性。
4 结 语
本文重点研究子句级的情感分析,传统的方法往往采用两步策略,这往往产生层叠错误问题。基于马尔科夫逻辑的联合模型使各个子任务融入到统一的框架下,从而有效地减少了层叠错误。本文在此基础上提出了一种新的全局特征,即语义相似特征,充分考虑了语义相似的两个子句很有可能具有相同的情感倾向,有效地提升了联合学习的能力。在中文情感分析数据集上的实验结果表明语义相似特征优于前人的二元结构特征。将来的研究会集中在两个方面:子句分隔和更细粒度的分类(喜、怒、哀、乐等)[14]。
[1] 周胜臣,瞿文婷,石英子,等.中文微博情感分析研究综述[J].计算机应用与软件,2013,30(3):161-164.
[2] 李岩,韩斌,赵剑.基于短文本及情感分析的微博舆情分析[J].计算机应用与软件,2013,30(12):240-243.
[3] 李泽魁,赵妍妍,秦兵,等.中文微博情感倾向性分析特征工程[J].山西大学学报(自然科学版),2014,37(4):570-579.
[4]HuM,LiuB.Miningandsummarizingcustomerreviews[C]//ProceedingsofthetenthACMSIGKDDinternationalconferenceonKnowledgediscoveryanddatamining.ACM,2004:168-177.
[5]WilsonT,WiebeJ,HoffmannP.Recognizingcontextualpolarityinphrase-levelsentimentanalysis[C]//Proceedingsoftheconferenceonhumanlanguagetechnologyandempiricalmethodsinnaturallanguageprocessing.AssociationforComputationalLinguistics,2005:347-354.
[6]ZirnC,NiepertM,StuckenschmidtH,etal.Fine-GrainedSentimentAnalysiswithStructuralFeatures[C]//IJCNLP,2011:336-344.
[7]ChenZ,HuangY,TianJ,etal.Jointmodelforsubsentence-levelsentimentanalysiswithMarkovlogic[J].JournaloftheAssociationforInformationScienceandTechnology,2015,66(9):1913-1922.
[8]RichardsonM,DomingosP.Markovlogicnetworks[J].Machinelearning,2006,62(1-2):107-136.
[9]PenningtonJ,SocherR,ManningCD.Glove:GlobalVectorsforWordRepresentation[C]//EMNLP,2014,14:1532-1543.
[10] 张成功,刘培玉,朱振方,等.一种基于极性词典的情感分析方法[J].山东大学学报(理学版),2012,47(3):47-50.
[11]TanS,ZhangJ.Anempiricalstudyofsentimentanalysisforchinesedocuments[J].ExpertSystemswithApplications,2008,34(4):2622-2629.
[12]FleissJL.Measuringnominalscaleagreementamongmanyraters[J].Psychologicalbulletin,1971,76(5):378.
[13]ZhangHP,LiuQ,ChengXQ,etal.Chineselexicalanalysisusinghierarchicalhiddenmarkovmodel[C]//ProceedingsofthesecondSIGHANworkshoponChineselanguageprocessing-Volume17.AssociationforComputationalLinguistics,2003:63-70.
[14] 欧阳纯萍,阳小华,雷龙艳,等.多策略中文微博细粒度情绪分析研究[J].北京大学学报(自然科学版),2014,50(1):67-72.
A FINE-GRAINED SENTIMENT ANALYSIS METHOD USING SEMANTICSIMILARITY FEATURE
Chen Ziyan1,2Huang Yu2Wang Yang2Fu Xingyu2Fu Kun2
1(UniversityofChineseAcademyofSciences,Beijing100049,China)2(KeyLaboratoryofTechnologyinGeospatialInformationProcessingandApplicationSystem,InstituteofElectronics,ChineseAcademyofSciences,Beijing100190,China)
Sentiment analysis mainly focuses on the study of people’s emotional expressions including positive and negative sentiment. With the explosive growth of web texts, sentiment analysis has become a hot topic in both academic researches and practical applications.The method of fine-grained sentiment analysis traditionally adopts a 2-step strategy, which is extremely easy to result in stack-up bottom-up errors. A joint fine-grained sentiment analysis framework based on Markov logic is proposed to solve this problem. “Bottom-up” and “Top-down” are the two most commonly used traditional overall features. In order to improve the joint learning ability of fine-grained sentiment analysis, a new semantic similarity feature has been proposed. Experiments on the data set of Chinese sentiment analysis prove that the semantic similarity feature can bring a significant improvement to the joint fine-grained sentiment analysis framework.
Fine-grained sentiment analysis Markov logic Semantic similarity feature
2016-02-17。国家自然科学
61331017)。陈自岩,博士生,主研领域:文本信息抽取。黄宇,副研究员。王洋,助理研究员。傅兴玉,助理研究员。付琨,研究员。
TP3
A
10.3969/j.issn.1000-386x.2017.03.005
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
中学生报·教育教学研究(2022年1期)2022-04-18
安徽工程大学学报(2021年5期)2021-11-30
有色金属(矿山部分)(2021年4期)2021-08-30
初中生世界(2020年47期)2021-01-07
安顺学院学报(2020年1期)2020-04-05
时代英语·高一(2019年5期)2019-09-03
现代计算机(2019年6期)2019-04-08
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
