
面向大数据集的递增聚类方法研究
2017-05-18 08:53杨克光
现代电子技术 2017年9期
杨克光
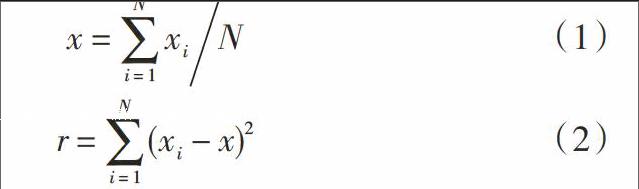

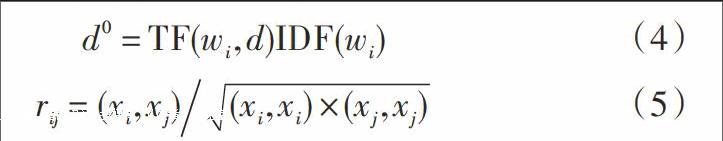
摘 要: 以往提出的面向大数据集的递增聚类方法直接将多维度的大数据集转换成一维大数据集,导致聚类成果不佳,故提出面向大数据集的递增聚类新方法。为取得高聚类效率,在高度保留原始数据维度的情况下,简化了大数据集递增聚类步骤,构建出大数据处理集合,对集合中的标志样本进行局部递增聚类,将未能成功聚类的大数据平均分配到局部递增聚类结果中,使用高斯概率密度函数和证据理论检测其中的错误坐标并进行改正,获取最终的递增聚类结果。实验结果证明该方法具有优越的聚类成果和聚类效率。
关键词: 大数据集; 递增聚类方法; 高斯概率密度函数; 证据理论
中图分类号: TN911?34; TP311.13 文献标识码: A 文章编号: 1004?373X(2017)09?0176?03
Abstract: Since the clustering effect is poor because the previously?proposed incremental clustering method converts the multi?dimensional large dataset into the one?dimensional large dataset directly, a new incremental clustering method for large dataset is put forward. In order to obtain the high clustering efficiency, the incremental clustering step of the large dataset was simplified while highly maintaining the original data dimensions to construct a large data processing set. The local incremental clustering is performed for the logo samples in the set. The large data with failed clustering is distributed into the local incremental clustering results equally, and its fault coordinate is detected with Gaussian probability density function and coordinate evidence theory and modified. The final incremental clustering results are obtained. The experiment results prove that the proposed method has superior clustering effect and clustering efficiency.
Keywords: large dataset; incremental clustering method; Gaussian probability density function; evidence theory
0 引 言
聚类的实质就是把大数据分层,同层中的大数据特征拥有共通性,而不同层中的大数据特征存在明显差异,并且大数据特征是可以被提取和描述的[1]。递增聚类是其中一种无监督式的分析手段,在语音识别、色彩分类和纹理提取等搜索层面中均有涉及,受到了广泛的关注。递增聚类的基本原理类似于度衡量技术和最优函数,它依据特定标准在未经处理过的大数据集中挖掘隐晦的递增聚类架构[2]。在实际应用中,类似度衡量技术的稳定性不佳,经常受到大数据递增结构、聚类密度、大数据维度等方面的約束,致使递增聚类达不到目标聚类的成果[3]。增强递增聚类中类似度衡量技术的稳定性一直是科研人员的研究基础,一些优秀的类似度衡量技术的稳定性解决方法,如相邻大数据共享策略、密度敏感性度量等均是在大数据维度不高的情况下被提出的,在高维度应用中上述方法的迭代次数过多,大幅度降低了聚类效率。
综上所述,以往提出的面向大数据集的递增聚类方法常受限于类似度衡量技术的稳定性,并没有取得优越的聚类成果和聚类效率[4]。解决这一问题的主要方式就是构建出能够有效平衡大数据维度的大数据处理集合,在此基础上分层次地获取到递增聚类结果,再对各层次的递增聚类结果进行汇总,使用合理的处理手段给出统一的递增聚类结果。基于上述分析,提出一种面向大数据集的递增聚类新方法。
1 大数据处理集合的构建
以往提出的面向大数据集的递增聚类方法为了提高聚类效率,直接将多维度的大数据集转换成一维大数据集,导致聚类成果不佳,在实际应用中具有局限性[5]。为此,提出面向大数据集的递增聚类新方法在对运算量高的大数据进行维度简化的同时,补充了递增聚类步骤,保留了大数据集的多维度特性,取得了高聚类效率。
在多维坐标系中选择一个含有个数据的大数据集,用表示,提取出其中的目标大数据,用表示。如果的维度为则可将转换为一个矩阵[6]。递增聚类大数据集的实质就是获取集合矩阵中各层大数据特征的类似度,依据类似度的具体数值为目标大数据定义出一个识别码是递增聚类总数量。一般来讲,在递增聚类中大数据集中的所有大数据都是目标大数据,则可组建出目标大数据识别码集合,用表示[7]。递增聚类的最终目的是无限增大相同层次中大数据特征的类似度。
本文提出的面向大数据集的递增聚类新方法以多维坐标系中的中心坐标点为圆心、离差平方和为半径构建大数据处理集合。假设大数据处理集合中拥有个大数据层次,那么的圆心和半径可表示成:
2 大数据集局部递增聚类方法
由于大数据集同层中的大数据特征拥有共通性,为了提高聚类效率,所提面向大数据集的递增聚类新方法先在大数据集中选择出各层大数据特征的标志樣本,将样本的大数据特征平均值标记为标志坐标,对以标志坐标为圆心的大数据处理集合进行递增聚类[9]。每取得一次递增聚类结果,需要将聚类成功后的大数据删除,避免大数据特征的不断累计增加运算量,其聚类流程如图1所示。
大数据集局部递增聚类方法的思想是在大数据集中任意提取一个样本,如果中涵盖了本层中所有大数据特征,则将其定义为标志样本,并从中提取一个坐标点定义成初值,令初值的半径为初值与本层中大数据特征的密度阈值为MI,要求经由初值构建出的大数据处理集合中,所有大数据的特征密度均大于MI。标志样本的标志坐标使用公式进行计算,表示拥有标志坐标的标志大数据。
从标志坐标开始依次向外进行递增聚类,计算出大数据处理集合中其他大数据坐标与之间的距离:
式中:分别表示到和的轴位移。
当某一大数据的小于或证明局部递增聚类成功。
大数据处理集合的每个层次都需要进行多次递增聚类才能取得聚类结果,聚类结果中的大数据是按照递增聚类成功的先后次序排列的[10]。本文方法将事先给出每个层次的聚类结果文件,初始文件均为空集,每取得一个小于或的大数据,聚类结果文件便会自动将大数据引入并为其赋予编号。产生了第一个聚类结果并将聚类成功大数据删除后,方法才会开始进行第二个聚类结果的提取工作,以防止聚类结果文件对大数据的错误引入,增强了方法的聚类成果。
分层次将大数据处理集合中的所有大数据聚类成功后,可得到个聚类结果,将结果汇总,用集合表示。对于大于、等于或的大数据,大数据集局部递增聚类方法会把这些为数不多的大数据平均分到集合中,得到,并利用大数据整体递增聚类方法进行统一处理。
3 大数据整体递增聚类方法
考虑到局部聚类结果中仍存在递增聚类不成功的大数据,若面向大数据集的递增聚类新方法使用单一的高斯概率密度函数进行整体递增聚类将得不到优越的聚类成果,所以需要在高斯概率密度函数中融合证据理论。
给定一个集合作为大数据集局部递增聚类结果集合的幂数集合,幂数集合中的数据可表示的聚类证据,是证据数量,。证据是指递增聚类中数据点的归属度,在一定程度上代表了聚类成果,是衡量大数据特征类似度的标准。幂数集合的高斯概率密度函数被定义为:
面向大数据集的递增聚类新方法的使用步骤整理如下:
Step1: 输入原始大数据集,无需变更数据维度;
Step2: 使用式(1)~式(3)构建大数据处理集合,使用式(4),式(5)修正集合;
Step3: 选取标志样本,计算标志坐标,进行局部递增聚类,汇总局部递增聚类结果;
Step4: 平均分配未成功进行递增聚类的大数据;
Step5: 使用式(7)检测错误坐标并修改;
Step6: 使用式(8)增强方法类似度衡量技术稳定性;
Step7: 使用式(9)计算信任函数,推导出方法目标函数,给出最终的递增聚类结果。
4 仿真实验
4.1 实验设置
为了精准验证本文提出的面向大数据集的递增聚类新方法的聚类成果和聚类效率,需要在不同维度的大数据集中进行实验,并尽可能采取对比策略,给出具有说服力的验证结果。为此,实验利用计算机模拟出了Tris和KDD64Bio两种大数据集,第一种是二维坐标点大数据集,第二种是多维图像大数据集。与本文方法相对应的对比方法在文献[5]和文献[9]中进行了详细介绍,这两种方法的市场需求和用户反馈均是比较优越的。
4.2 实验结果与分析
由于Tris大数据集拥有精确的数据坐标点信息,因此可从递增聚类准确度中看出三种方法的聚类成果,如图2所示。KDD64Bio大数据集由于数据维度复杂,故需要从聚类结果的数据间隔入手分析聚类成果,数据间隔越短,聚类成果越好,如表1所示。数据间隔包括同层间隔和异层间隔。实验设置三种方法的聚类时间结果将与聚类成果共同输出,如表2所示。
从表1,表2中能够非常明显地看出,实验中对比方法的聚类成果均要远低于本文方法的聚类成果,同时,本文方法还取得了优越的聚类效率。
5 结 论
本文提出一种面向大数据集的递增聚类新方法,其在合理简化大数据集维度、获取高效递增聚类的同时,对重要的递增聚类步骤进行了补充,又依据从局部到整体的递增聚类方式,对类似度衡量技术稳定性进行了加强处理,给出了递增聚类目标函数。实验将本文方法与文献[5]、文献[9]中的方法进行对比,从实验结果中可明显看出本文方法的聚类成果和聚类效率均要高于其他方法。
参考文献
[1] 赵凤娇,贺月姣.基于改进的K?means聚类算法水下图像边缘检测[J].现代电子技术,2015,38(18):89?91.
[2] 向尧,袁景凌,钟珞,等.一种面向大数据集的粗粒度并行聚类算法研究[J].小型微型计算机系统,2014,35(10):2370?2374.
[3] 涂新莉,刘波,林伟伟.大数据研究综述[J].计算机应用研究,2014,31(6):1612?1616.
[4] LIANG C, LENG Y. Collaborative filtering based on information?theoretic co?clustering [J]. International journal of systems science, 2014, 45(3): 589?597.
[5] 罗恩韬,王国军.大数据中一种基于语义特征阈值的层次聚类方法[J].电子与信息学报,2015,37(12):2795?2801.
[6] 张帆,毋涛.基于云计算的服装物料管理系统[J].西安工程大学学报,2015,29(6):740?745.
[7] 孟凡军,李天伟,徐冠雷,等.基于K均值聚类算法的雾天识别方法研究[J].现代电子技术,2015,38(22):80?83.
[8] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839?862.
[9] 潘章明,陈尹立.面向大数据集的共享近邻聚类研究[J].小型微型计算机系统,2014,35(1):50?54.
[10] KHAN S S, AHMAD A. Cluster center initialization algorithm for K?modes clustering [J]. Expert systems with applications, 2014, 40(18): 7444?7456.
