
基于Web框架的博客管理系统设计与实现
2017-05-19 12:36刘磊
计算机时代 2017年5期
关键词:网络爬虫
刘磊
摘 要: 设计并实现了一个基于B/S架构的个人博客管理系统,包括游客浏览博客、用户发表博客及使用爬虫抓取网络新闻等功能。系统前端使用当前流行的响应式布局框架Bootstrap开发,页面能匹配不同分辨率;后端使用Hibernate、Spring、Struts三大经典组合框架开发,系统扩展性强。本文论述了本系统的功能设计、流程设计、数据模型设计、效果实现等软件开发关键阶段的开发过程。
关键词: Web框架; SSH框架; Bootstrap框架; 个人博客; 网络爬虫
中图分类号:TP393.02 文献标志码:A 文章编号:1006-8228(2017)05-20-04
Design and implementation of blog management system based on Web framework
Liu Lei
(The Open University of Guangdong(Guangdong Polytechnic Institute), Guangzhou, Guangdong 510000, China)
Abstract: In this paper, a personal blog management system based on B/S architecture is designed and implemented, which includes the functions of the visitors browsing the blog, the blog users publishing the blog and the crawler crawling the network news. The front end of the system is developed with Bootstrap, which makes the page can be matched with different resolutions, and the back-end is developed with the classic combination framework combined with Hibernate, Spring and Struts, which makes the system scalable. This paper discusses the developing process of the software development, such as function design, process design, data model design and the realization of the effects.
Key words: Web framework; SSH framework; Bootstrap framework; personal blog; Web crawler
0 引言
博客,又称网络日志,是一种表达个体思想、彰显个人风格的互联网工具,通常为个人自主管理的网站。用户可以自由的在博客上发表文章,最新的文章排列在最前显示,游客可以浏览博文;除了提供信息展示的功能,博客还提供评论、回复评论的交互功能,以提高博客的用户粘连度。一个典型的博客囊括了文字、图像、其他博客或网站的链接,以及相关媒体,博客是社会媒体网络的一部分。博客系统是指,使用计算机语言编写、安装,方便用户在互联网上建立个人博客的一整套系统[1]。
本文尝试从软件工程的角度,详细阐述个人博客管理系统的功能设计、流程设计和数据模型设计,技术选型使用经典的J2EE企业级开发框架SSH和响应式前端框架Bootstrap,最后分析了系统关键功能實现。
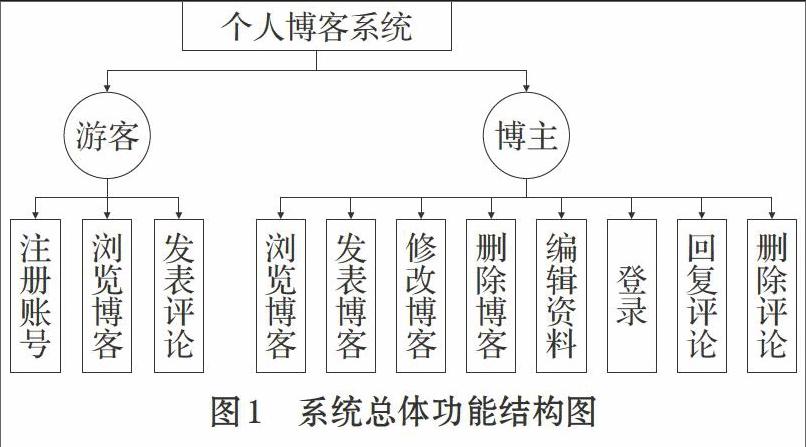
1 功能结构设计
本文设计的博客系统主要实现三个功能:发表和浏览日志、新闻爬虫与收藏、内容评论与回复。
1.1 发表日志
权限控制:未注册的用户只能查看公开日志;需要登录才能增删改,查看隐藏日志。
需要实现的模块有七个。①用户登录:用户使用帐号密码登录系统,认证成功则转入个人主页,失败则显示错误信息;②用户注册:填写用户名、密码、个人信息,提交数据库保存;③个人资料:填写博主基本信息,包括博客名、作者简介、性别、邮箱等;④发表日志:用户发表日志,内容包括主题主题、正文、图片、媒体等信息,可以选择是否公;⑤删除日志:用户可以选择删除已经发表的日志,系统会从数据库删除这些信息;⑥查看日志:用户或游客可以浏览公开的日志内容;⑦修改日志:用户修改已经发表的日志,系统保存修改内容。
1.2 新闻爬虫与收藏
权限控制:未注册用户只能查看爬虫新闻,需要登录才能设置爬虫筛选条件和进行收藏。
需要实现的模块有二个。①新闻爬虫:博客用户可以设置筛选条件,爬虫程序根据预定义规则获取网络信息并存储到系统数据库;②收藏:博客用户可以收藏本网站其他用户的日志,查看收藏记录。
1.3 评论与回复
权限控制:允许匿名用户发表评论,只有被评论的日志作者有权限回复、删除评论。
需要实现的模块有四个。①发表评论:系统允许访客匿名评论所阅读的日志;②回复评论:日志作者可以对日志的评论进行回复,与访客进行互动;③删除评论:博客用户可以指定删除对日志的评论;④自动显示:评论自动显示在对应日志的下方。
系统总体功能结构设计如图1所示。
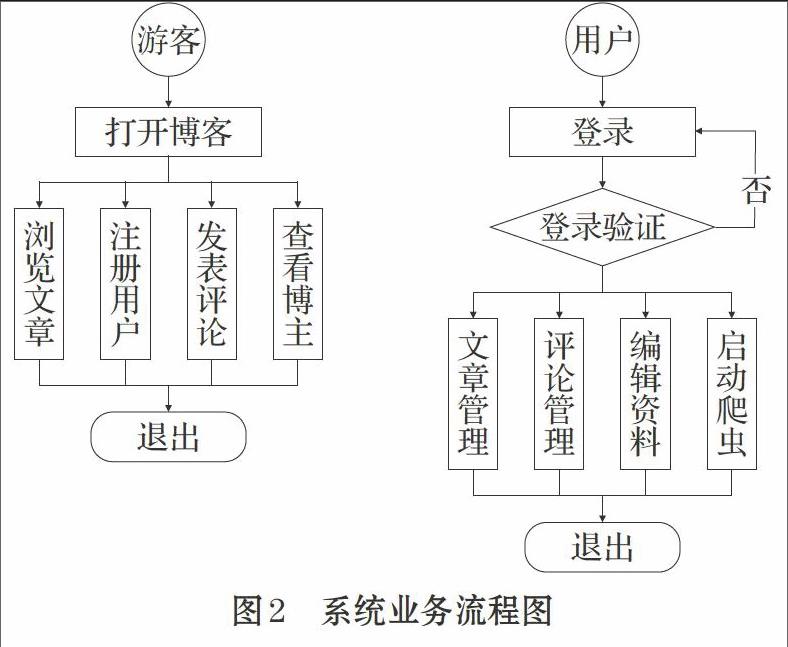
2 业务流程设计
本系统角色包括游客与用户,游客可以浏览博客文章列表、查看博主详细资料、查看博文内容、发表匿名评论等;游客无需登录,进入系统主页后,点击菜单即可使用博客功能。用户注册账号即成为博主,可以发表博文、编辑博文、删除博文、编辑个人资料;同时系统提供了从互联网抓取最新新闻到博客系统的功能,用户可以启动新闻爬虫抓取新闻、删除新闻内容等。系统业务流程设计如图2所示。
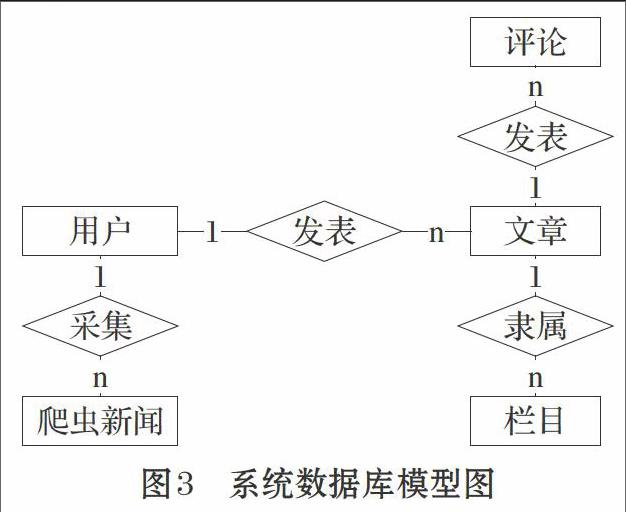
3 數据库模型设计
个人博客管理系统主要关注博客文章的发表,分析系统需求,博客系统最关键的是用户实体、文章栏目实体和文章内容实体,本系统加入了评论和新闻爬取功能,所以需要提供评论和新闻两个实体。数据库模型设计如图3所示。
4 技术框架选型
本系统前端选用流行的Bootstrap框架,Bootstrap是目前很受欢迎的HTML、CSS和JS框架,用于开发响应式布局、移动设备优先的Web项目,它简洁灵活,使得Web开发更加快捷,Bootstrap基于HTML5、CSS3、jQuery开发,Bootstrap内置的CSS媒体查询(Media Query)功能,可以开发出响应式布局的网页,自动适应不同分辨率效果;同时提供了丰富的Web组件,包括下拉菜单、按钮组、按钮下拉菜单、导航、导航条、路径导航、分页、排版、缩略图、警告对话框、进度条、媒体对象等。使用这些组件,可以快速地搭建一个漂亮、功能完备的网站前端[5-6]。
本系统后端选用经典的SSH集成框架开发,SSH集成框架是Hibernate、Spring、Struts三大框架的组合,基于SSH框架的系统从职责上分为四层:表示层、业务逻辑层、数据持久层和域模块层,可以帮助开发人员在短期内搭建结构清晰、可复用性好、维护方便的Web应用程序。其中使用Struts作为系统的整体基础架构,负责MVC的分离,在Struts框架的模型部分,控制业务跳转,利用Hibernate框架对持久层提供支持,Spring做管理,管理Struts和Hibernate。具体做法是:首先用面向对象的分析方法,根据需求提出一些模型,将这些模型实现为基本的Java对象;然后编写基本的DAO(Data Access Objects)接口,并给出Hibernate的DAO实现,采用Hibernate架构实现的DAO类来实现Java类与数据库之间的转换和访问;其次使用Struts连接业务逻辑和视图展现,接收、处理、发送数据并控制流程;最后由Spring做整合,管理Struts和Hibernate,提供IOC容器使代码松耦合以及AOP框架的切面功能[2-4]。
5 关键功能与实现
本系统的关键功能包括发布博客日志、新闻爬虫等模块,用户登录成功后可以发表博客、启动新闻爬虫可以抓取互联网上的新闻链接和内容,下面分析关键功能的实现。
5.1 发布博客日志
一篇博客日志可以由文字、图片、视频、音频等元素组成,发布博客日志功能包括添加日志标题、添加发布时间、添加日志内容等。其中添加日志内容最复杂,需要实现添加各种元素和布局排版元素,添加日志内容通常使用富文本编辑器实现。本系统使用UEditor编辑器,UEditor是百度公司开发的所见即所得富文本web编辑器,具有轻量级、可定制、注重用户体验等特点,开源基于MIT协议,提供了基本文档格式化、网络图片、视频、地图、表情等丰富的功能,适合于编辑复杂的图文内容。在JSP页面嵌入UEditor的关键代码如下:
<!-- 加载编辑器的容器 -->
<!-- 配置文件 -->
<!-- 编辑器源码文件 -->
<!-- 实例化编辑器 -->

发布博客日志功能效果如图4所示。
5.2 获取网络新闻
通过新闻爬虫程序获取网络新闻,新闻爬虫是一种按照一定的规则,自动地抓取互联网新闻的程序。新闻爬虫程序通常包括控制器、解析器、资源库三部分。控制器主要负责给多线程中的各个爬虫线程分配工作任务;解析器主要负责下载网页,进行页面的处理,主要是将规则外的JS脚本标签、CSS代码内容、HTML标签、空格字符等内容处理掉,解析器是爬虫程序的主要部分;资源库用于存储下载到的网页资源[7]。本系统使用HttpClient实现了一个轻量级新闻爬虫,主要包括四个类。①CrawlBase类:模拟http请求的基类;②CrawlListPageBase类:CrawlBase的子类,实现了从页面中获取链接的URL信息基类;③DoRegex类:封装的一些基于正则表达式字符串匹配查找类;④CharsetUtil类:编码方式检测类。部分关键代码如下:
public void crawl()throws Throwable {
while(continueCrawling()) {
CrawlerUrl url=getNextUrl();
//获取待爬取队列中的下一个URL
if(url!=null) {
printCrawlInfo();
String content=getContent(url); //获取URL的文本信息
//聚焦爬虫,只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if(isContentRelevant(content,this.regexpSearchPattern)) {
saveContent(url,content); //保存網页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings=extractUrls(content,url);
addUrlsToUrlQueue(url,urlStrings);
} else {
程序System.out.println(url+"舍弃");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
6 结束语
博客是互联网发表信息的重要工具,本文以发表博客、新闻获取的需求为出发点,设计并实现了通用的个人博客管理系统,技术方案选用SSH框架开发后端,具有稳定、高效、可扩展性强得优点;使用Bootstrap框架开发前端,页面简洁大方,兼容性强,能自动响应匹配不同终端设备的分辨率。本文实现的个人博客管理系统能方便的发布到互联网,供不同用户注册使用,且基于成熟框架,系统运行稳定,相信对于读者进行软件开发有一定的参考意义,但系统的安全性本文没有涉及,这些还需要进一步研究。
参考文献(References):
[1] 谷岩.博客系统的设计与实现初探[J].电脑知识与技术,2013.35.
[2] 李雷孝,刘志强,杜慧敏,冀强.Struts和Hibernate整合框架研究与应用[J].内蒙古工业大学学报(自然科学版),2010.3.
[3] 屠晓云.基于SSH的学生学习交流平台的设计与实现[J].电脑知识与技术,2012.25.
[4] 周利江.基于SSH框架的J2EE应用研究[J].电脑编程技巧与维护,2012.12.
[5] 李金亮,李春青.基于BootStrap的Web开发设计研究[J].中小企业管理与科技(中旬刊),2014.5.
[6] 张子杰,庄育飞.基于Bootstrap和SSH的求职招聘系统设计与实现[J].软件导刊,2016.10.
[7] 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术,2010.15.
猜你喜欢
电脑知识与技术(2017年1期)2017-03-24
电脑知识与技术(2017年1期)2017-03-24
中国新技术新产品(2017年4期)2017-03-04
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
科技经济市场(2016年2期)2016-06-16
电脑知识与技术(2016年7期)2016-05-19
