
基于贝叶斯网的评价数据分析和动态行为建模
2017-08-12 15:31孙正宝
计算机研究与发展 2017年7期
王 飞 岳 昆 孙正宝 武 浩 冯 辉
1(云南大学信息学院 昆明 650504)2 (云南大学科技处 昆明 650504)
基于贝叶斯网的评价数据分析和动态行为建模
王 飞1岳 昆1孙正宝2武 浩1冯 辉1
1(云南大学信息学院 昆明 650504)2(云南大学科技处 昆明 650504)
(wangfei_989@163.com)
随着Web2.0的不断普及和电子商务应用的迅速发展,大规模的在线评价数据不断产生,使用户行为数据分析和用户行为建模成为可能,具有重要意义.考虑到用户评价数据和评价行为的动态性,提出以带有隐变量的贝叶斯网作为各属性间依赖关系及其不确定性表示的基本框架,构建既能刻画用户评价数据中各属性间相互依赖的不确定性、也能描述用户行为动态性的评价行为模型.首先,以贝叶斯信息标准(BIC)分值作为模型与数据拟合度的度量标准,提出基于打分搜索方法来构建各时间片的隐变量模型,并给出基于期望最大(EM)算法的隐变量取值填充方法;其次,基于条件互信息和时序的不可逆性,提出了相邻时间片间隐变量模型的构建方法.建立在MovieLens数据集上的实验结果验证了提出的动态用户行为建模方法的高效性及有效性.
用户评价数据;时序性;隐变量模型;贝叶斯网;动态行为建模
随着Web2.0和电子商务的迅速发展,人们越来越多地参与到了网上购物和对商品的评价中,产生了大规模的用户评价数据(简称评价数据).这些评价数据,一方面,能有效支持电子商务应用领域中的个性化推荐、行为定向和计算广告等问题[1]的解决.例如实际应用中,用户的评价行为反映了用户偏好[2],即用户对特定商品类型的喜好或倾向.因此,商家可以在评价数据分析的基础上建立用户评价行为模型,从而预测用户的兴趣特点和购买行为,并根据不同的用户兴趣或偏好制定合理的个性化营销策略,准确地给用户推荐其感兴趣的商品[1];另一方面,评价数据和评价行为具有动态性[1],也就是说,新的评价数据不断追加,且用户评价行为也随时间推移而逐渐演化,如图1所示.这使得精准捕获用户偏好方法的研究具有实际意义,也具有一定的挑战.因此,分析用户的评价数据、对用户评价行为进行建模、发现用户偏好,成为了近年来数据分析和知识发现领域研究的热点之一.
Fig. 1 An example of user behaviors evolved over time among variables图1 用户行为随时间演化例子
基于用户评价数据分析的时序评价行为建模,是用户行为分析和预测的核心和关键,也是数据密集型计算在社会数据分析方面亟待解决的问题.近年来,已经有许多研究成果.例如文献[3]从带有时序特征的用户评价数据出发,提出评价数据较少情形下的商品服务评估模型;文献[4]基于概率张量分解技术提出能有效挖掘用户偏好的时序评价行为预测及推荐模型;文献[5]提出采用用户历史反馈信息的时序双线性概率模型,实现对用户偏好的描述和追踪.这些带有时序特征的用户行为建模方法,能够较好反映并体现用户评价行为的动态性.然而,我们把观测到的评价数据中的属性视为显变量(manifest variable),把潜在的用户偏好视为隐变量(latent variable),显变量和隐变量之间存在依赖关系,且这种依赖关系具有不确定性,如图2所示,在这样的情形下,以上建模方法难以描述用户评价数据中相关属性间带有不确定性的依赖关系,进而也无法细致地刻画用户行为影响因素之间的依赖关系.因此,探寻适应在不确定因素下能够对用户评价行为进行有效推理的模型和建模方法,具有重要的意义.
Fig. 2 An example of uncertain relationships图2 变量间不确定性关系例子
贝叶斯网[6](Bayesian network, BN)是由一组随机变量(即节点)及各节点的条件概率表(conditional probability table, CPT)构成的有向无环图(directed acyclic graph, DAG).作为不确定性知识发现和推理的有效工具,它不仅克服了朴素贝叶斯模型为代表的一类方法不能客观描述用户评价数据中性间依赖关系的不足,且为多个变量之间任意形式的依赖关系及其不确定性建模提供了参考.同时,伴随着评价数据时序性和评价行为的动态变化,贝叶斯网能够对用户兴趣模型进行实时更新,从而更好地适应用户不断改变的兴趣[5].
含隐变量的BN简称为隐变量模型[6],由于其中的隐变量能汇聚用户评价数据中相关变量之间的依赖关系、简化模型结构,且可以大幅降低用户评价行为模型构建和推理的复杂度,在表达用户评价数据中相关属性和用户行为之间的不确定性上具有明显的优势,因此被广泛用于用户偏好发现和行为建模等应用领域.例如文献[7]用显变量对应各个评价指标,用一个影响其他显变量的隐变量来表示最终的用户评价行为;文献[8]用隐变量刻画用户的信任偏好,根据变量的含义给出模型的DAG结构;文献[9]提出了基于隐语义概率模型的用户偏好预测方法,用于个性化服务推荐.这些隐变量模型构建方法,为本文中的模型构建提供了参考,但针对用户行为时序性的模型构建仍需要进一步的研究.
基于隐变量模型的时序行为建模,目前,也有许多工作,例如文献[1]将用户偏好和时间情景视为影响用户评价行为的隐变量,提出能鉴别用户评价行为的动态用户评价行为模型;文献[10]基于时序用户数据提出能追踪用户行为变化的时序用户行为模型;文献[11]提出基于隐式用户反馈的实时个性化推荐方法.然而,以上根据变量含义而给定的隐变量模型结构,缺乏对数据中相关属性间任意形式依赖关系的客观描述.且由于无法从用户评价数据中获得隐变量自身的取值,使得时序评价行为模型的构建与传统BN的构建不同,即隐变量与显变量之间依赖关系的确定及隐变量值的填补计算方面,存在着较大差异[12].又因为评价数据具有时序性,需构建时序隐变量模型来体现用户行为的动态性,这使得含隐变量的时序评价行为模型的构建具有挑战性.
基于上述分析,本文基于含隐变量的概率图模型研究时序评价数据中的行为建模方法,即从带有时序特征的用户评价数据出发,首先,针对每个时间片构建用于描述用户评价数据中相关变量间依赖关系的DAG结构,称为评价行为模型(rating behavior model, RBM);然后,构建相邻时间片间描述相关变量间依赖关系的DAG,从而得到既能反映属性间相互依赖的不确定性,也能反映用户评价行为动态性的时序评价行为模型(time-series rating behavior model, TRBM).
具体而言,本文的主要工作可概括为4个方面:
1) 各时间片中RBM构建的关键在于其DAG的构建,需要确定变量间的相互依赖关系,进而确定有向边的方向.期望最大(expectation maximization, EM)算法是寻找参数最大似然或者最大后验估计的有效算法[13],我们首先采用EM算法对隐变量的值进行填充.经典的用于BN结构学习的打分搜索和爬山算法[7]简单规范、易于确定边的方向.因此,本文以贝叶斯信息标准(Bayesian information criterion, BIC)评分函数为尺度,选择BIC评分值最高的候选模型作为各时间片的RBM,给出了用于构建各时间片内RBM的打分搜索算法.
2) 为了构建相邻时间片间的DAG,我们考虑时序的不可逆性(即有向边的方向只能从前一个时间片中的变量指向后一个时间片中的变量),因此,只需确定变量间的相关性,无需确定有向边的方向.条件互信息为描述随机变量间的相关性提供了良好的基础,本文使用条件互信息来测试相邻时间片间用户评价数据中变量间的条件独立性[14-15],进而确定它们之间存在的相关性、判断节点间是否存在相连的边,给出了构建相邻时间片中变量间DAG的算法.
3) 在构建的DAG基础上,本文给出基于最大似然(maximum likelihood, ML)估计的TRBM中各节点CPT计算方法,从而得到完整的TRBM.
4) 建立在MovieLens数据集上的实验结果,验证了本文所提出方法的高效性和有效性.
1 问题描述及模型定义
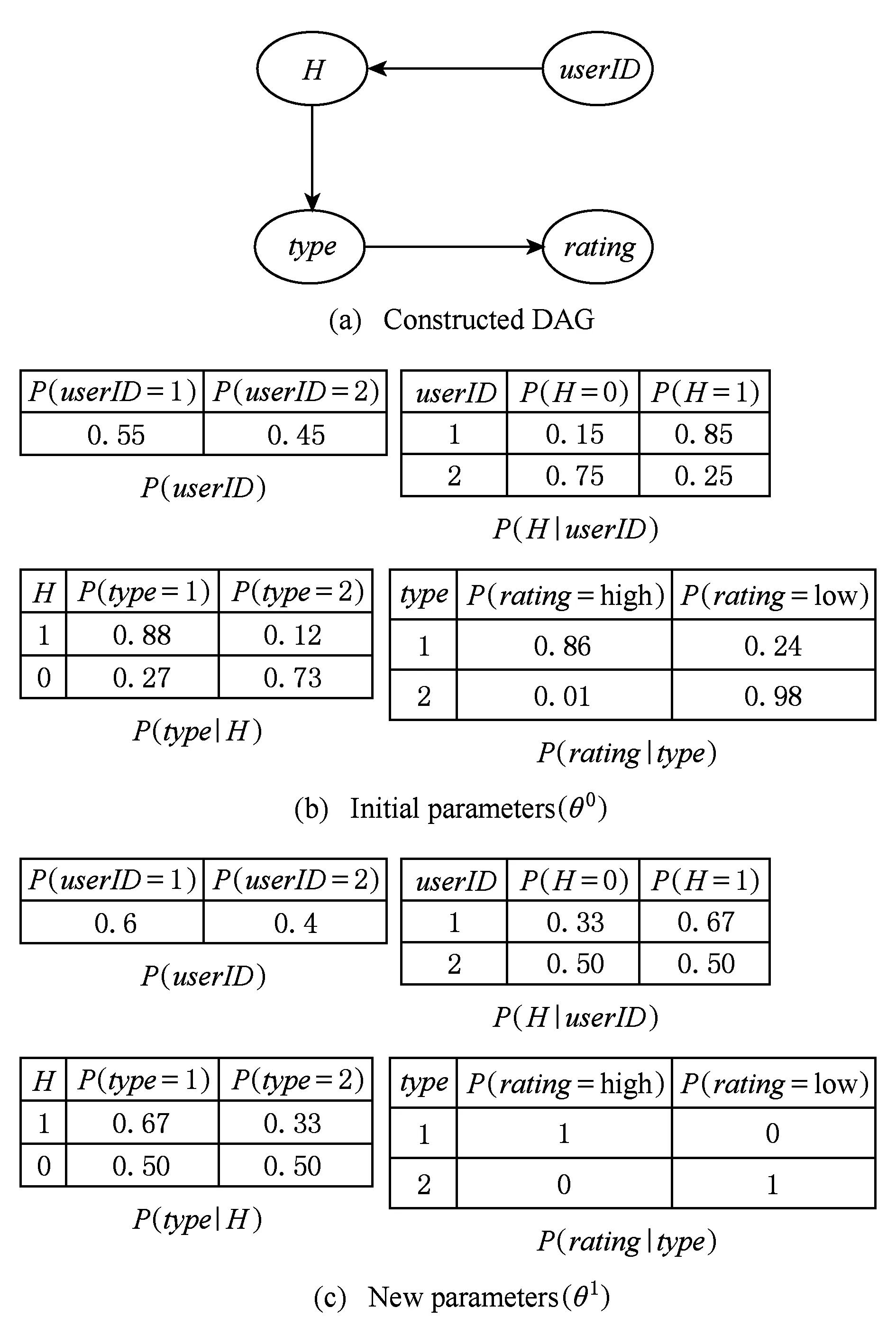
例1. 用户对电影的评价数据包含属性userID,type,rating.其中userID为用户标识,type为电影类型,rating为用户对电影的评分.鉴于讨论的方便,我们将rating的取值简化为low或high.表1展示了相邻时间片中用户对电影的评价数据片段.
Table 1 User Rating Data in Adjacent Time Slices表1 相邻时间片中的用户评价数据
P(X(t0),X(t1),…,X(tm))=P(X(t0))P(X(t1)|
X(t0))…P(X(tm)|X(t0),X(t1),…,X(tm-1)),
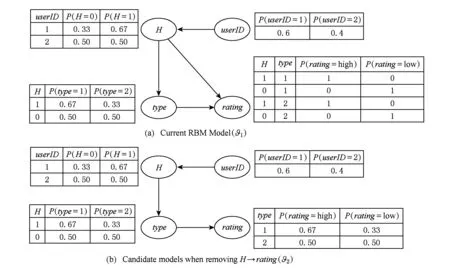
(1)
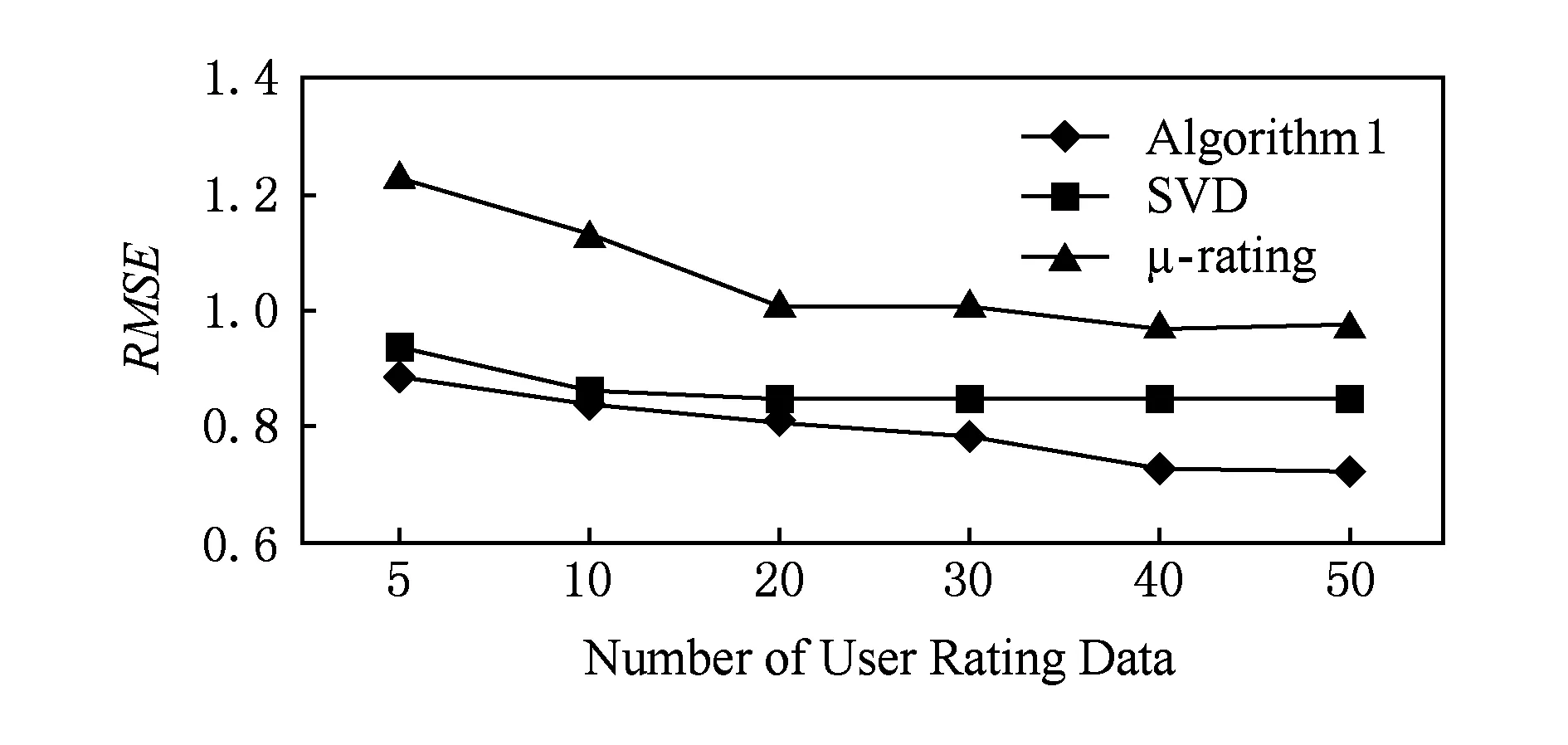
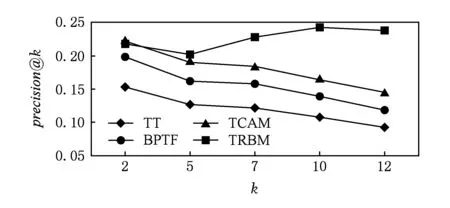
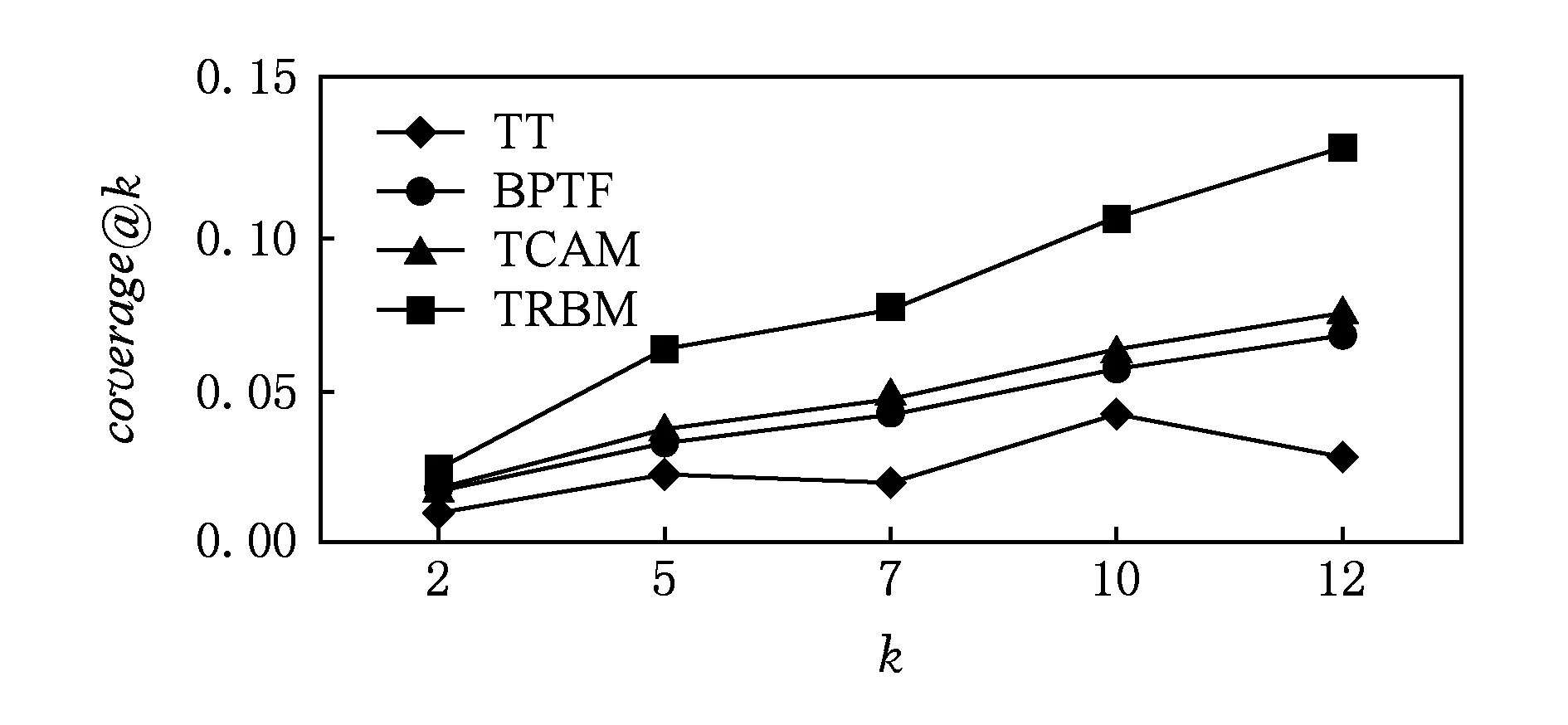
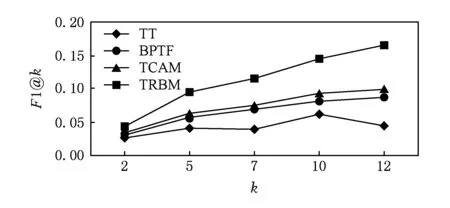
式(1)可解释为ti时间片中的用户评价行为会对其后所有时间片中的评价行为产生影响,而这样的模型复杂度太高、实现代价太大.因此,假设当前用户评价行为只与前一个时间片有关,即X(ti+1)条件独立于X(tj),其中j P(X(t0),X(t1),…,X(tm))=P(X(t0))P(X(t1)| X(t0))…P(X(tm)|X(tm-1)). (2) 可见,用户评价数据中变量的相互依赖关系,同时存在于同一个时间片中,以及相邻时间片之间.其中,X(ti)描述了时间片ti中用户评价数据相关属性间的任意依赖关系(即RBM);P(X(ti+1)|X(ti))描述了相邻时间片间用户评价数据相关变量间的依赖关系,体现了用户评价行为的动态性;直观地,P(X(ti)),P(X(ti+1)),P(X(ti+1)|X(ti))由TRBM表达. 例如,电影评分数据实例“userID=1,type=2,rating=high,H=1”,表示userID=1的用户喜好type=2的电影,对应的评分较高(即rating=high). 本节首先给出用于隐变量取值填充的EM算法;然后给出各时间片中RBM模型的构建算法;接着给出相邻时间片中DAG的构建算法,得到TRBM模型;最后,给出TRBML模型中参数的计算方法. 2.1 各时间片中的RBM构建 在机器学习领域,BN结构构建的经典算法思想为[6]:从任意的初始模型开始,对其采用爬山算法进行加边、减边和反向边搜索,得到若干候选模型后,计算和比较这些候选模型与数据的吻合程度(称为打分值),从而选择分值最高的模型为候选模型.本文借鉴该思路,同时考虑到评价数据中不包含隐变量的值这一特点,首先,采用EM算法对隐变量进行取值填充;然后,计算各候选模型的BIC分值,选择BIC分值最高的候选模型作为各时间片中的RBM. 2.1.1 基于EM算法的隐变量取值填充 对于给定的DAG结构,采用EM算法对含有N个实例的评价数据集Dti的隐变量值进行填充时,从随机产生的初始值θ0开始迭代,设已经进行了l次迭代,参数估计结果为θl.第l+1次迭代过程: 1) E步骤 首先,根据Dti中显变量的值和参数θl,如式(3)所示,计算每一个评价实例中H的每一个可能取值的概率: (3) (4) 其中,X1,X2,…,Xn为给定DAG结构中的n个节点,Xi有ri个取值,Xi的父节点π(Xi)有qi种组合,若Xi无父节点,则qi=1. 2) M步骤 基于填充后的完整数据计算θ的最大似然估计,得到θl+1ijk: (5) 迭代执行上述E步骤和M步骤,直到按式(6)计算得到的θl和θl+1的对数似然值不再变化,选择概率最高的取值作为最终填充值.上述思想见算法1. (6) 算法1. 隐变量取值填充:FillValue(G,Dti,δ). 输入:δ—收敛阈值、Dti—ti中无隐变量值的评价数据集、G—ti中爬山算法得到的候选DAG; 输出:Dti—ti中完整的用户评价数据集. 步骤: l←0;θ0←随机参数值; oldScore←L(θl|Dti); while(true) E-步骤: 按式(3)计算H取值概率; 按式(4)计算H取值概率和; M-步骤: 按式(5)计算参数θl+1; 按式(6)计算θl+1基于Dti的对数似然值; newScore←L(θl+1|Dti); if (newScore-oldScore>δ) oldScore←newScore; l←l+1; else 选择概率最高的填充值填充Dti; returnDti; end if end while 例2. 给定DAG结构及初始参数θ0,分别如图3(a)和图3(b)所示,采用算法1进行隐变量值填充,首先,按式(3)分别计算每个评价实例中隐变量每一种可能取值的概率,如针对(1,2,high,0)和(1,2,high,1)分别计算出概率为0.2和0.8.然后,分别按式(4)和式(5)计算得到新参数θ1,如图3(c)所示.接着,按式(6)计算并比较参数θ0和θ1的对数似然值,L(θ1|Dti)-L(θ0|Dti)=-2 771.293 5-(-6 211.653 2)=3 440.359 8,直到该值小于所设定的收敛阈值δ,即对数似然值基本不再变化时,选择概率最大的取值作为该评价实例的填充值. Fig. 3 Latent variable filling based on Algorithm 1图3 基于算法1的隐变量值填充 2.1.2 基于BIC评分标准的RBM构建 对于时间片ti,采用爬山算法进行搜索后得到的若干个候选模型结构,首先,2.1.1节给出隐变量值填充算法;然后,通过式(7)分别计算出每一个候选模型的BIC分值.最后,比较并选择BIC分值最高的模型作为当前模型.重复搜索迭代,直至BIC分值不再变化后,选择分值最高的候选模型作为ti时间片中的RBM. (7) 其中,X1,X2,…,Xn为候选结构S包含的n个节点,Xi有ri个取值,Xi的父节点π(Xi)有qi种组合,若Xi无父节点,则qi=1;mijk为Dti中Xi=k(1≤k≤ri)且π(Xi)=j(1≤j≤qi)的实例数,mij为Dti中π(Xi)=j的数据实例数;N为Dti中数据实例数. 上述模型构建思想见算法2. Fig. 4 Candidate RBM model by algorithm 2图4 基于算法2得到的候选RBM 算法2. RBM构建:LearnBN-HC(X,Dti,f,ϑ0,δ). 输入:X—用户评价属性集Uti、δ—收敛阈值、f=ScoreBIC(ϑ|Dti)—模型选择BIC打分函数、Dti—ti中评价数据集、ϑ0—初始DAG结构; 步骤: ϑ←ϑ0; θ←FillValue(ϑ,Dti,σ); oldScore←ScoreBIC(ϑ|Dti); while (true) ϑ*←null; θ*←null; newScore←-∞; for (爬山算法对ϑ搜索而得到的候选结构ϑ′) θ′←FillValue(ϑ′,Dti,σ); tempScore←ScoreBIC(ϑ′|Dti); if (tempScore>newScore) ϑ*←ϑ′; θ*←θ′; newScore←tempScore; end if end for if (newScore>oldScore) ϑ←ϑ*; θ←θ*; oldScore←newScore; else return ϑ; end if end while 对于含有n个变量的RBM构建,算法2中,爬山法搜索执行一次时共需要产生O(n2)个获选模型且每一个候选结构需要调用一次算法1进行隐变量值的填充,因此需要调用O(n2)次算法1.对算法2的效率我们将通过实验进行进一步测试. 例3. 若图4(a)为当前模型ϑ1,图4(b)是执行算法2时删去边(H→rating)后得到的候选模型ϑ2.首先,采用算法1对ϑ2中隐变量的值进行填充.然后,计算得到ϑ1和ϑ2对于Dti的ScoreBIC分值分别为:ScoreBIC(ϑ1|Dti)=-4 190.4,ScoreBIC(ϑ2|Dti)=-4 272.7,由于,ScoreBIC(ϑ1|Dti)=max{ScoreBIC(ϑ1|Dti),ScoreBIC(ϑ2|Dti)},因此,选择ϑ1为当前RBM.继续重复搜索过程,直至ScoreBIC分值不再变化为止,从而可得到时间片ti中的RBM. 2.2 基于条件互信息的相邻时间片间DAG结构构建 为了构建相邻时间片的DAG结构,我们基于互信息测试变量间的条件独立性,进而确定它们之间是否存在相关性,定义4首先给出互信息的概念. 定义4. 设U=Uti∪Uti+1,X,Y和Z为U的3个互不相交子集,给定条件Z的情况下,X和Y的条件互信息定义为 I(X|Z|Y)= (8) 其中,X ⊂Uti,Y ⊂Uti+1,Z ⊂Uti∪Uti+1-X-Y,x,y和z分别为X,Y和Z的取值, P(x,y,z)= 若I(X|Z|Y)≤ε成立,则给定Z条件下X和Y条件独立,即P(X,Y|Z)=P(X|Z)P(Y|Z).否则不独立,即P(X,Y|Z)≠P(X|Z)P(Y|Z).其中ε为给定的阈值. 基于上述思想给出相邻时间片间DAG构建算法,如算法3所示. 步骤: forl=1 tondo forj=1 tondo I←CItests(P,Q,R,ε,Dti,Dti); ifI≤εthen S←R; end if end for end for 算法3中,CItests()操作共执行O(n2)次,其中n为Uti中属性的个数.由于有向边的方向只能从ti中的变量指向ti+1中的变量,因此,CItests()很大程度上避免了不必要的测试.算法3的性能将通过实验进行进一步测试. 例4. 如表1所示,时间片ti和ti+1中用户评价数据集为Dti和Dti+1,属性集Uti=Uti+1={userID,type,rating}.对于userIDti和typeti+1,令X={userIDti},Y={typeti+1},Z⊆Uti-X∪Uti+1-Y={typeti,ratingti,userIDti+1,ratingti+1},按照式(8)计算得到userIDti和typeti+1的条件互信息为 . 同理,我们计算相邻时间片中其他所有变量间的条件互信息,基于算法3得到图5中的TRBM结构. Fig. 5 Time-series rating behavior model图5 时序评价行为模型 2.3 时序评价行为模型的参数计算 构建时间片ti(0≤i≤m)中的RBM时,已经通过EM算法对隐变量的值进行了填充.因此,可以通过计算最大似然估计的方法来得到TRBM的参数: (9) 其中,D是用户评价数据集,计算ti时间片中的最大似然估计时,D=Dti;计算相邻时间片间的最大似然估计时,D=Dti∪Dti+1. 基于最大似然估计算法思想,下面我们给出TRBM参数计算方法如算法4所示. 算法4. 参数计算LearnPRM-ML(Dti,Dti). 输入:Dti—ti中用户评价数据集、Dti—ti+1中用户评价数据集; 输出:θ—TRBM的参数估计. 步骤: if (计算时间片ti中DAG参数) then D←Dti; else D←Dti∪Dti+1; end if returnθ. 例5. 对于图5中的TRBM,相邻时间片间的参数:P(Hti+1=0|typeti=1,ratingti=high)=Num(Hti+1=0|typeti=1,ratingti=high)(Num(Hti+1=0|typeti=1,ratingti=high)+Num(Hti+1=1|typeti=1,ratingti=high)) =0.25,Num()表示满足条件的实例数.同理,我们可以计算得到如图5所示的TRBM中所有节点的参数. 为了测试本文提出方法的有效性和高效性,本文使用GroupLens的电影评分数据集MovieLens[16],其中包括1996—2016年11 327个用户对20种电影类型的共1 048 576行评价数据,包括:userID,type,rating,timestamp四个变量.我们用timestamp将数据集按照年份划分成20个时间片数据片,userID,type,rating作为TRBM每个时间片的DAG中的节点. 实验环境如下:Intel®CoreTMi3-3240 CPU 3.40 GHz处理器;4.00 GB内存;Windows7 64 b操作系统;MATLAB R2014b开发平台. 3.1 基准描述 μ-rating[17]也称mean-r[17],是一种传统、简单的评分预测方法,它的基本思想是采用所有用户评价的平均值,对缺失的数据进行填充. SVD[17-18](singular value decomposition)是协同过滤[19]中常见的评分预测算法.其基本思想是先采用梯度下降算法计算得到2个完整的矩阵;然后,用2个矩阵运算得到的值,对缺失的数据进行填充. TT[20](time-topic model)是一种主题模型.该模型假设主题是由时间背景产生的,即用户的行为受时间背景的影响;不考虑用户兴趣对主题或行为的影响.其概率为 P(v|t;ψ)=λBP(v|θB)+ BPTF[4](Bayesian probabilistic tensor factoriza-tion)是概率张量分解技术针对时序特征的拓展,是一种目前主流的评价行为预测模型. TCAM[1](temporal context-aware mixture model)是一种用户行为预测模型,同时考虑了用户兴趣和时间背景对用户评价行为的影响.概率为 3.2 TRBM构建效率 Fig. 6 Execution time with the increase of nodes图6 增加节点数测试运行时间 我们首先测试了相同用户评价数据量情形下,随着节点数的增加使用本文方法和传统的BN学习方法来构建TRBM的运行时间,如图6所示;同时,测试了相同节点数的情形下,随着用户评价数据量增加使用2种方法构建TRBM的运行时间,如图7所示.可以看出,使用本文方法构建TRBM的执行时间比基于BN学习方法构建TRBM的执行时间少,这从一定程度上说明了本文构建TRBM的方法具有高效性.其次,我们针对上述2种情形,分别测试了TRBM构建过程中算法1、算法2和算法3的执行时间,如图8和图9所示.可以看出,构建TRBM时算法1计算隐变量填充值的耗时最多.因为,算法2每执行1次爬山搜索需要调用O(n2)次算法1来填充数据,因此,这成为了影响TRBM构建效率的瓶颈. Fig. 7 Execution time with the increase of user rating data图7 增加用户评价数据量测试运行时间 Fig. 8 Execution time of algorithm 1-3 with the increase of nodes图8 随着节点数增加各算法的执行时间 Fig. 9 Execution time of algorithm 1-3 with the increase of user rating data图9 增加用户评价数据量各算法执行时间 3.3 填充数据准确性 我们将MovieLens数据集中能够观测到值的显变量rating值视为空值,采用本文算法1、μ-rating方法及SVD方法对其值进行填充.鉴于均方根能够反映填补数据与真实数据的接近程度,即均方根值越小,填补的值与真实值越接近.我们计算填补数据与真实用户评价数据间的均方根值: (10) 如图10所示,算法1对隐变量值填补的均方根值最小,表明相比于μ-rating方法和SVD方法,算法1能够更为准确地填充隐变量的值,且随着评价数量的增加,算法1填充数据的准确性增加. Fig. 10 Accuracy of filled data图10 填充数据的准确性 3.4 TRBM有效性 我们将20个时间片数据中的前80%作为建模数据,后20%作为测试数据,并将测试数据中,所有用户评价为”high”的电影类型视为用户偏好的类型.测试了TRBM,TT,BPTF,TCAM用户行为预测的准确率(precision)和覆盖率(coverage).其中,用precision@k表示TRBM返回k个用户偏好的准确率,用coverage@k表示TRBM返回k个用户偏好的覆盖率: (11) (12) 其中,Num(preference)是TRBM模型计算出的k个电影类型中实际为用户偏好的电影类型数,Num(Allpreference)是实际用户偏好的电影类型数. 进一步,我们测试了反映准确率和覆盖率综合性能的F1值: (13) Fig. 11 Precision图11 准确率 Fig. 12 Coverage图12 覆盖率 Fig. 13 F1 score图13 F1值 准确率、覆盖率和F1值分别如图11、图12和图13所示,不难看出TRBM对用户行为预测的准确率、覆盖率、F1值均高于其他动态行为模型,这从一定程度上验证了本文所提出方法的有效性. 本文针对用户评价数据具有时序性和评价行为具有动态性的特点,提出了一种既可以描述用户评价数据相关属性间任意依赖关系、又可以反映用户评价行为动态性的时序评价行为模型,实验验证了本文所提出方法的高效性和有效性. 本文的研究为针对一段时间内多个时间片的动态行为模型构建、用户不同偏好之间的联系提供了一种思路.但是,作为这一问题的初步探索,在针对新追加的评分数据来定量地确定模型中需要修改的部分,从而对当前模型进行增量修改,而不需要重新学习,以保证模型构建的高效性和实时性,仍然需要进一步研究,也是我们将要开展的工作. [1]Yin Hongzhi, Cui Bin, Chen Ling, et al. Dynamic user modeling in social media systems[J]. ACM Trans on Information Systems, 2015, 33(3): Article No.10 [2]McAuley J, Leskovec J. Hidden factors and hidden topics: Understanding rating dimensions with review text[C]Proc of the 7th ACM Conf on Recommender Systems. New York: ACM, 2013: 165-172 [3]Zhao Guoshuai, Qian Xueming, Xie Xing. User service rating prediction by exploring social users’ rating behaviors[J]. IEEE Trans on Multimedia, 2016, 18(3): 496-506 [4]Xiong Liang, Chen Xi, Huang Tzu-Kuo, et al. Temporal collaborative filtering with Bayesian probabilistic tensor factorization[C]Proc of the 2010 SIAM Int Conf on Data Mining. Philadelphia, PA: SIAM, 2010: 211-222 [5]Luo Cheng, Cai Xiongcai, Chowdhury N. Probabilistic temporal bilinear model for temporal dynamic recommender systems[C]Proc of 2015 Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2015: 1-8 [6]Zhang Lianwen, Guo Haipeng. Introduction to Bayesian Networks[M]. Beijing: Science Press, 2006 (in Chinese)(张连文, 郭海鹏. 贝叶斯网引论[M]. 北京: 科学出版社, 2006) [7]Kim J S, Jun C H. Ranking evaluation of institutions based on a Bayesian network having a latent variable[J]. Knowledge-Based Systems, 2013, 50(3): 87-99 [8]Fang Hui, Bao Yang, Zhang Jie. Misleading opinions provided by advisors: Dishonesty or subjectivity[C]Proc of the 23rd Int Joint Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2013: 1983-1989 [9]Hu Yan, Peng Qimin, Hu Xiaohui. A personalized Web service recommendation method based on latent semantic probabilistic model[J]. Journal Computer Research and Development, 2014, 51(8): 1781-1793 (in Chinese)(胡堰, 彭启民, 胡晓惠. 一种基于隐语义概率模型的个性化Web服务推荐方法[J]. 计算机研究与发展, 2014, 51(8): 1781-1793) [10]Kapoor K, Subbian K, Srivastava J, et al. Just in time recommendations: Modeling the dynamics of boredom in activity streams[C]Proc of the 8th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2015: 233-242 [10]Kapoor K, Subbian K, Srivastava J, et al. Just in time recommendations: Modeling the dynamics of boredom in activity streams[C]Proc of the 8th ACM Int Conf on Web Search and Data Mining. New York: ACM, 2015: 233-242 [11]Wang Zhisheng, Li Qi, Wang Jing, et al. Real time personalized recommendation based on implicit user feedback data stream[J]. Chinese Journal of Computers, 2016, 39(1): 52-64 (in Chinese)(王智圣, 李琪, 汪静, 等. 基于隐式用户反馈数据流的实时个性化推荐[J]. 计算机学报, 2016, 39(1): 52-64) [12]Yue Kun, Fang Qiyu, Wang Xiaoling, et al. A parallel and incremental approach for data intensive learning of Bayesian networks[J]. IEEE Trans on Cybernetics, 2015, 45(12): 2890-2267 [13]Dempster A P. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society, 1977, 39(1): 1-38 [14]Wang Shuangcheng, Yuan Senmiao. Research on learning Bayesian networks structure with missing data[J]. Journal of Software, 2004, 15(7): 1042-1048 (in Chinese)(王双成, 苑森淼. 具有丢失数据的贝叶斯网络结构学习研究[J]. 软件学报, 2004, 15(7): 1042-1048) [15]Liu Weiyi, Yue Kun, Liu Shuangxian, et al. Qualitative probabilistic network based modeling of temporal causalities and its application to feedback loop identification[J]. Information Sciences, 2008, 178(7): 1803-1824 [16]GroupLens. MovieLens data sets[EBOL]. [2016-02-28]. http:grouplens.orgdatasetsmovielenslatest [17]Harvey M, Carman M J, Ruthven I, et al. Bayesian latent variable models for collaborative item rating prediction[C]Proc of the 20th ACM Conf on Information and Knowledge Management. New York: ACM, 2011: 699-708 [18]Zhao Guoshuai, Qian Xueming. Service objective evaluation via exploring social users’ rating behaviors[C]Proc of 2015 IEEE Int Conf on Multimedia Big Data. Piscataway, NJ: IEEE, 2015: 228-235 [19]Sun Guangfu, Wu Le, Liu Qi, et al. Recommendations based on collaborative filtering by exploiting sequential behaviors[J]. Journal of Software, 2013, 24(11): 2721-2733 (in Chinese)(孙光福, 吴乐, 刘淇, 等. 基于时序行为的协同过滤推荐算法[J]. 软件学报, 2013, 24(11): 2721-2733) [20]Wang Xuanhui, Zhai Chengxiang, Hu Xiao, et al. Mining correlated bursty topic patterns from coordinated text streams[C]Proc of the 13th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2007: 784-793 Wang Fei, born in 1989. Master candidate at Yunnan University, and student member of CCF. His main research interests include uncertain data knowledge discovery and social media data analysis. Sun Zhengbao, born in 1985. Received his MS degree in 2012. Experimentalist at Department of Science and Technology, Yunnan University. His main research interests include massive spatial data analysis. Wu Hao, born in 1979. Received his PhD degree in computer science from Huazhong University of Science and Technology in 2007. Associate professor at Yunnan University. His main research interests include information retrieval, recommendation system and service computing. Feng Hui, born in 1993. Master candidate at Yunnan University. His main research interests include uncertain data knowledge discovery and social media data analysis. Analyzing Rating Data and Modeling Dynamic Behaviors of Users Based on the Bayesian Network Wang Fei1, Yue Kun1, Sun Zhengbao2, Wu Hao1, and Feng Hui1 1(SchoolofInformationScienceandEngineering,YunnanUniversity,Kunming650504)2(DepartmentofScienceandTechnology,YunnanUniversity,Kunming650504) With the rapid development of Web2.0 and the e-commerce applications, large-scale online rating data are generated, which makes it possible to analyze users behavior data and model user behaviors. Considering the dynamic property of rating data and user behaviors, in this paper we adopt the Bayesian network with a latent variable (abbreviated as latent variable model) as the framework for describing mutual dependencies and corresponding uncertainties, and then construct the model that can reflect not only the uncertainty of dependence relationships among attributes in rating data but also the dynamic property of user behaviors. We first adopt the Bayesian information criterion (BIC) as the coincidence measure between candidate model and rating data, and then propose the scoring-and-search based method to construct the latent variable model. Then, we give the method for filling latent variable values based on the expectation maximization (EM) algorithm. Further, we propose the method for constructing the latent variable model between adjacent time slices based on conditional mutual information and irreversibility of time series. Finally, experimental results established on the MovieLens data set verify the efficiency and effectiveness of the method proposed in this paper. user rating data; time-series; latent variable model; Bayesian network; dynamic behavior model �born in 1979. his MS degree in computer science from Fudan University in 2004, and received his PhD degree in computer science from Yunnan University in 2009. Professor and PhD supervisor at Yunnan University. His main research interests include massive data analysis and services. 2016-08-02; 2016-10-10 国家自然科学基金项目(61472345,61562090);云南省应用基础研究计划重点项目(2014FA023);云南大学青年英才培育计划项目(WX173602);云南大学创新团队培育计划项目(XT412011);云南省教育厅科研基金项目(2016ZZX006) This work was supported by the National Natural Science Foundation of China (61472345,61562090), the Key Program of Applied Basic Research Foundation of Yunnan Province (2014FA023), the Program for Excellent Young Talents of Yunnan University (WX173602), the Program for Innovative Research Team in Yunnan University (XT412011), and the Science Research Foundation of Yunnan Provincial Education Department (2016ZZX006). 岳昆(kyue@ynu.edu.cn) TP18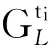
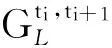
2 时序评价行为模型构建

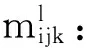
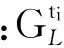
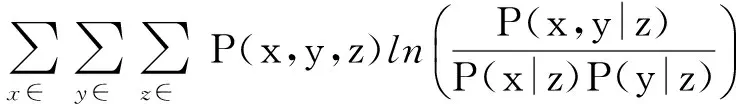

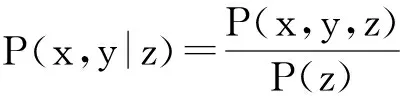
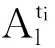
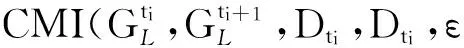
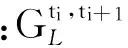
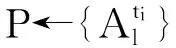
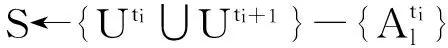
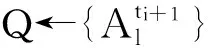
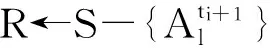
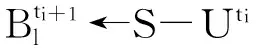
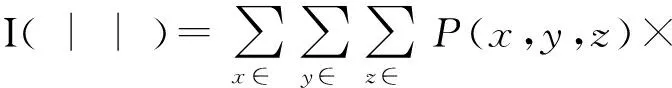

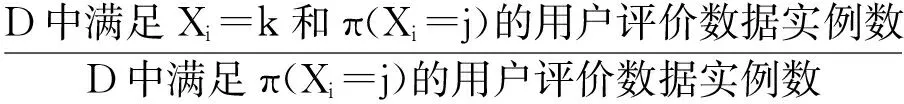
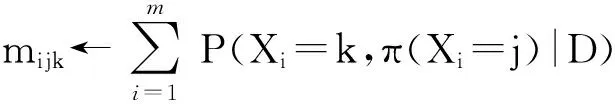
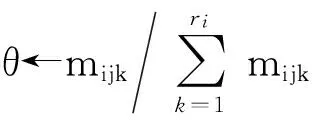
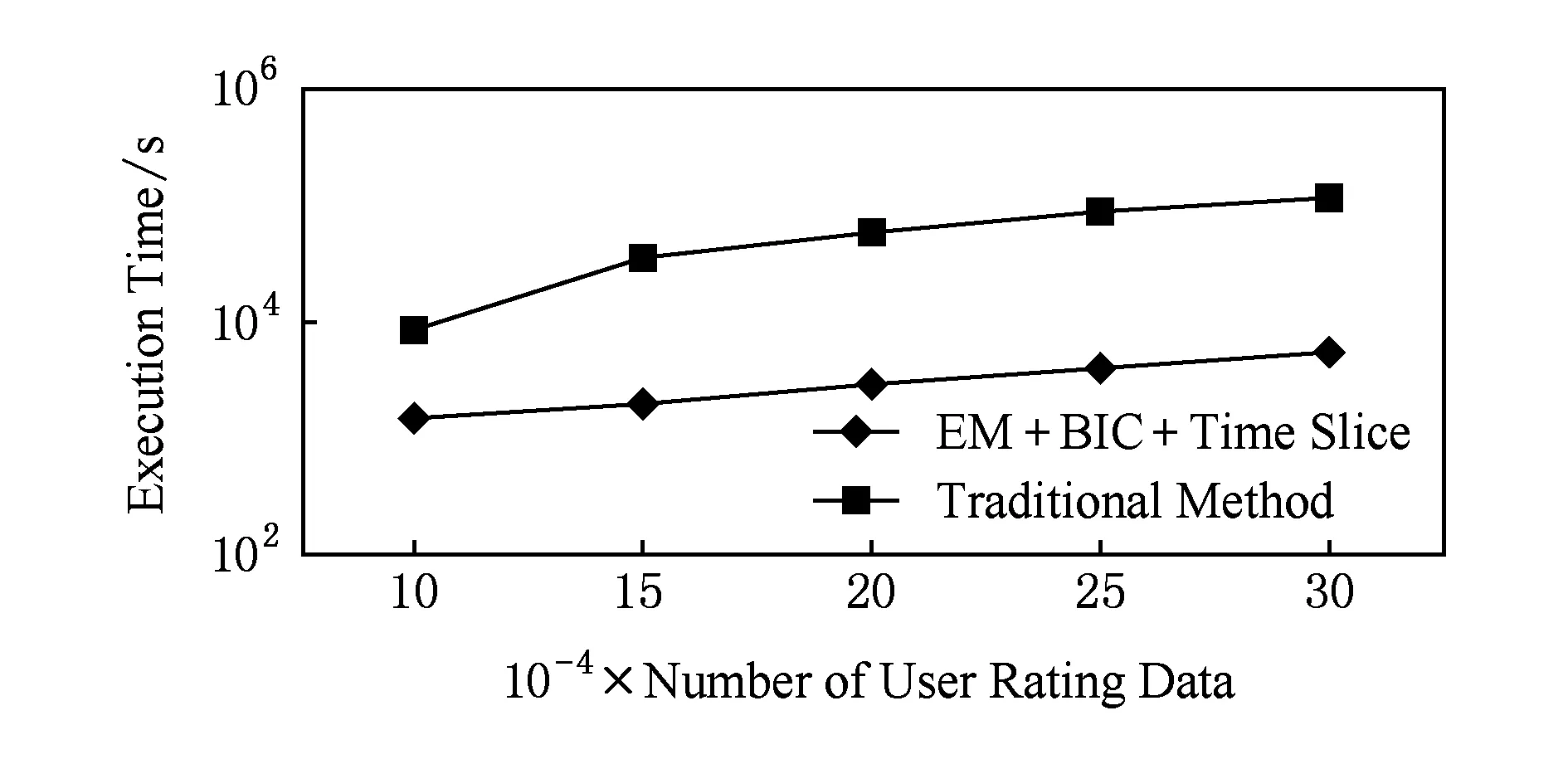
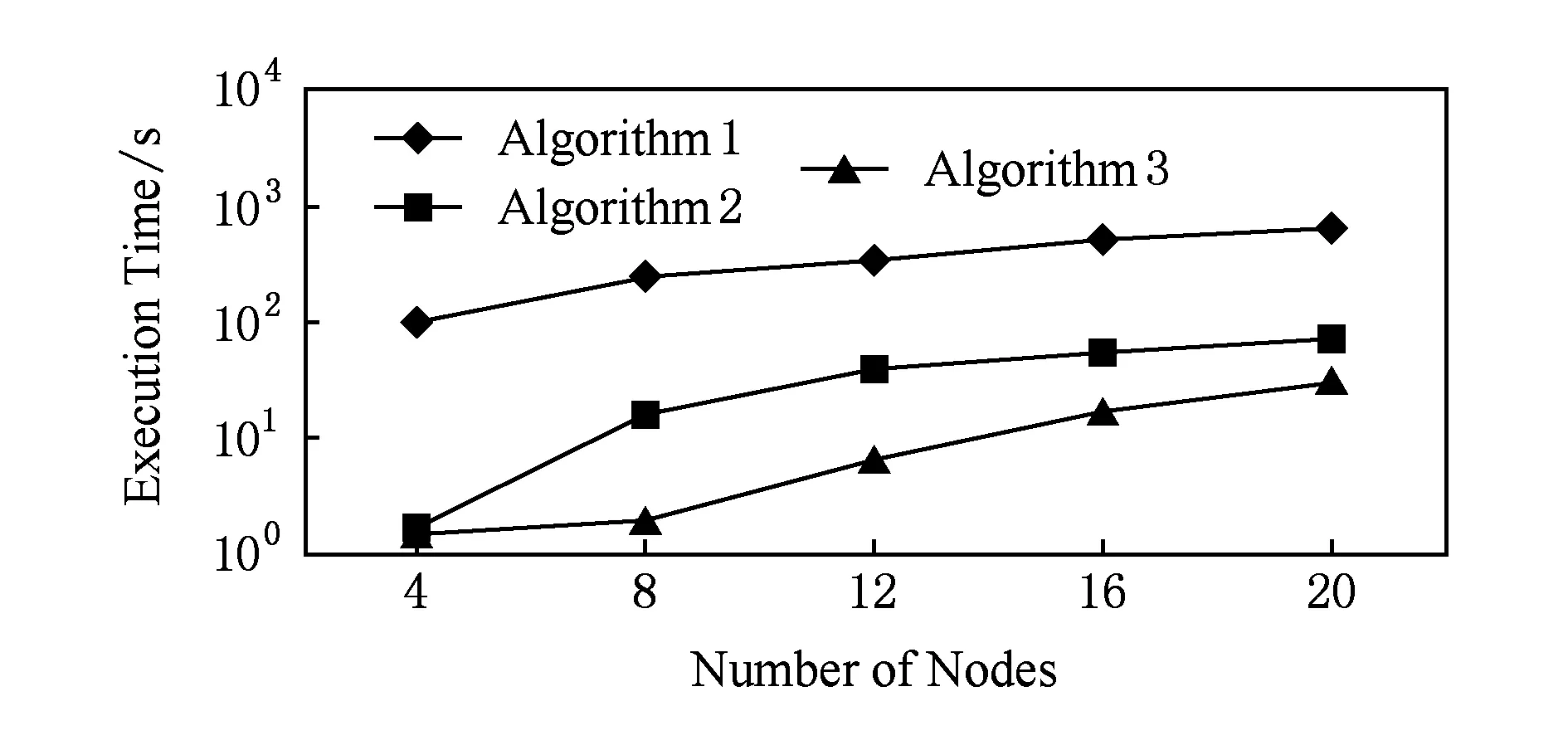
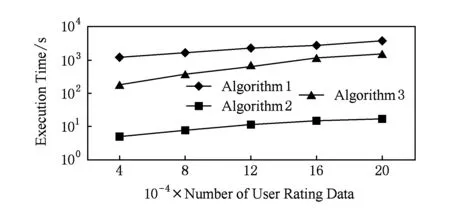
3 实验结果
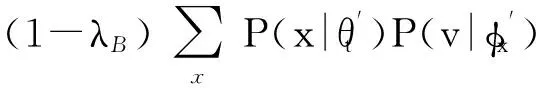
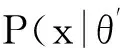
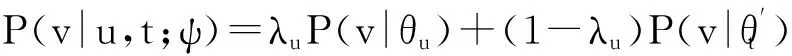
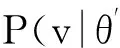

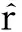
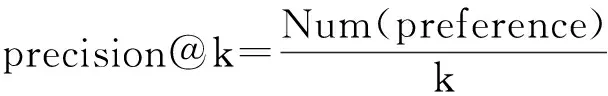
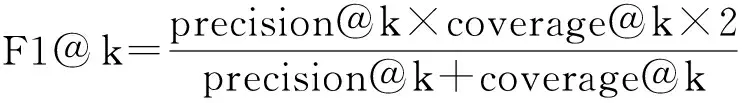
4 总结与展望





猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
河北理科教学研究(2020年2期)2020-09-11
铁道建筑技术(2020年11期)2020-05-22
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
电子制作(2017年13期)2017-12-15
新高考·高二数学(2014年7期)2014-09-18
