
基于数字助听器声音场景分类的噪声抑制算法
2017-09-07 09:50汪家冬邹采荣蒋本聪王青云
数据采集与处理 2017年4期
汪家冬 邹采荣 蒋本聪 王青云
(1.广州大学机械与电气工程学院,广州,510006;2.东南大学信息科学与工程学院,南京,210096)
基于数字助听器声音场景分类的噪声抑制算法
汪家冬1邹采荣1蒋本聪1王青云2
(1.广州大学机械与电气工程学院,广州,510006;2.东南大学信息科学与工程学院,南京,210096)
提出了一种基于声音场景分类的噪声抑制算法。算法使用调制滤波法对纯语音、纯噪音和含噪语音3种场景进行分类,并根据分类结果调整噪声抑制算法参数集,得到不同的抑制系数。本文方法在助听器测试系统中取得了良好的实验效果,场景分类正确率在95%以上。在不同噪声类型情况下,经过本文算法处理的输出语音信号取得了良好的信噪比和MOS评分的提升。本文算法可以有效地提高数字助听器输出语音质量。
声音场景分类;调制滤波;噪声抑制;信噪比
引 言
在数字助听器系统中,语音、噪音和音乐等不同的场景中常常需要调整不同的信号处理策略和参数,而系统对声音场景进行自动分类的能力则制约了系统性能[1]。高性能的数字助听器能够根据当前声音场景自动切换程序,调整参数,处理声音,提高性噪比,改善用户体验[2]。
近年来,针对数字助听器应用,很多学者对声音场景分类算法进行了研究[3]。这些方法各有特色,实验所用的数据库也各有不同。很多学者研究声学特征参数集的选取和分类模型的建立[4]。合理地选取出适合区分声音场景的特征能够提高整个分类系统的性能,降低模型的计算量。在这些研究中,短时能量、线性回归系数、过零率、基音频率、共振峰、熵信息以及倒平共谱信息等都是主要使用的特征。很多学者也对声音场景提出各种分类算法,如人工神经网络[5]、支持向量机(Support vector machine,SVM)、隐马尔可夫模型(Hidden Markov model,HMM)[6]以及混合高斯模型(Gaussian mixture model,GMM)等。2015年Ipek Sen等对这些分类器进行了比较,提出了新的参数设置方法[7]。但是,基于特征提取和模式识别的方法导致数字助听器计算量变大,实时性变差,在实际系统中常常由于功耗过大无法应用。而基于调制深度的声音场景分类算法[8]由于其计算量小、实时性高成为研究热点
本文研究了一种基于调制滤波法的数字助听器声音场景分类算法。利用输入声音的调制深度,区分纯语音、噪音和含噪语音3种场景。并根据场景分类结果,调整噪声抑制参数,获得不同的抑制系数。本方法可以保证语音信号顺利通过系统,而噪声则受到最大程度的抑制,从而在有噪声的情况下提高信噪比。本文方法在助听器测试系统中取得了良好的实验效果,场景分类正确率在95%以上。在不同的噪声类型情况下,经过本文算法处理的输出语音信号取得了良好的信噪比和MOS评分[9]的提升。本文算法可以有效提高数字助听器输出语音质量。
1 基于调制滤波法的声音场景分类算法
在数字助听器中,声音信号经传声器采集、A/D模块转换成数字信号。声音场景分类算法在全带内对输入数字信号进行处理,其处理得到的场景分类结果供后续噪声抑制模块使用,用来调节抑制函数参数。基于调制滤波法的数字助听器声音场景分类算法流程如图1所示,一般以1 s为一个观测窗口,也可以根据实际需要调整观测频度。
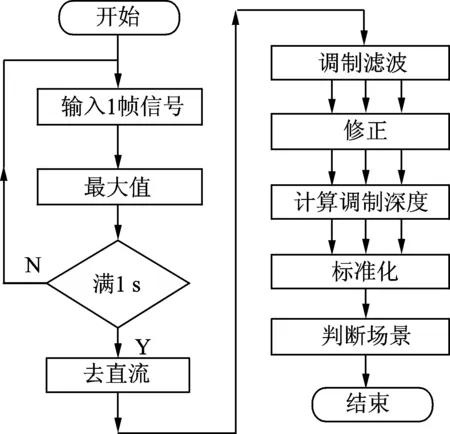
图1 基于调制滤波法的数字助听器声音场景分类算法流程图Fig.1 Algorithm flowchart of acoustic scene classification based on digital hearing aid of modulation filtering method
图1中,每帧信号最大值记为v(i),i=1,…,N,i为帧号,N为一个观测窗口的帧数。则观测窗口的有效值为
(1)
对每个观测窗口的包络曲线v(i)进行微分,有
(2)

(3)
式中修正系数K1,K2和K3可以根据不同系统进行修正。
下一步计算3个调制频带的调制深度,具体如下
(4)
对3个通道的调制深度进行正则化,具体如下
(5)
最后,根据正则化后的调制深度进行声音场景分类,具体如下
(6)
式中语音阈值THspeech和噪声阈值THnoise可以在0~1之间进行调整。
2 基于声音场景分类的数字助听器降噪算法
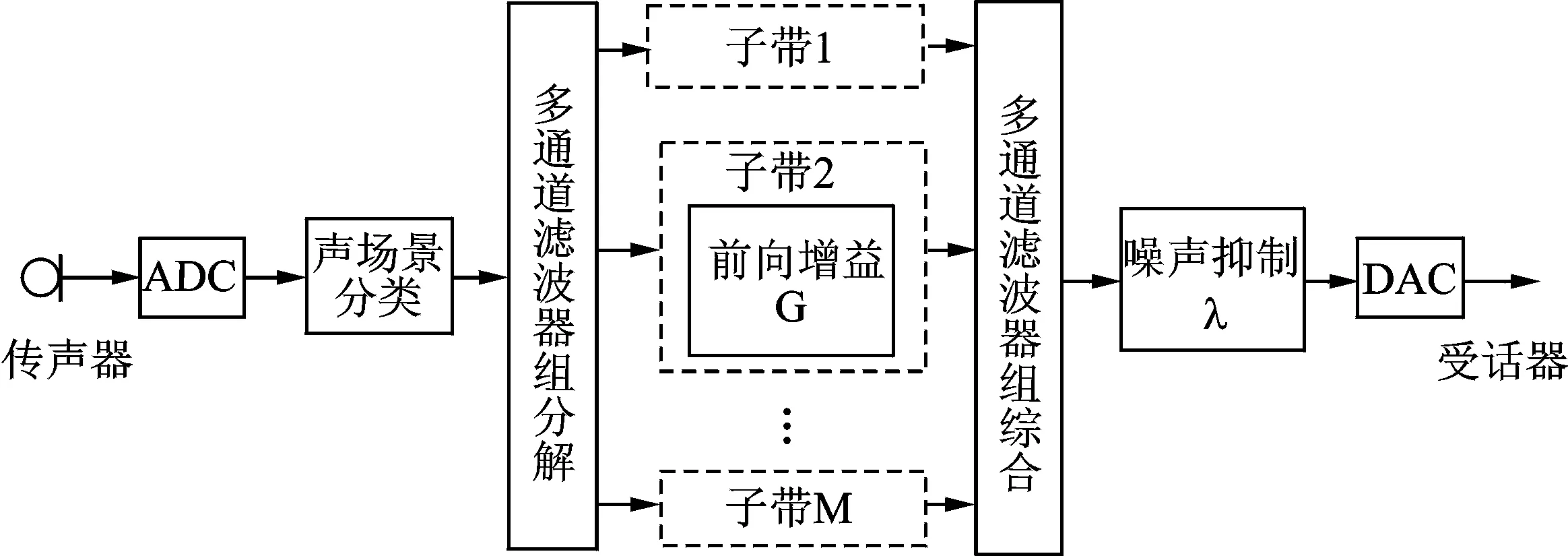
图2 含有降噪单元的数字助听器系统 Fig.2 Block diagram of digital hearing aid comprising the unit of noise reduction

图3 噪声抑制系数λ调节曲线Fig.3 λ adjustment curve of noise suppression coefficient
在上述算法得到数字助听器所处声音场景之后,可以通过调节噪声抑制系数λ对输入信号进行降噪,系统框图如图2所示。图2所示的多通道数字助听器中,经过A/D转换的数字声信号首先进行声音场景分类。在通过子带增益进行多通道响度补充之后,增加了噪声抑制单元,通过抑制系数λ实现降噪功能,其中λ取值在0~1之间,根据声音场景和信噪比进行调整,具体如图3所示。在不同的声音场景中,参数K0,K1,K2,A0,A1,A2,B0和B1取值不同,其取值可以根据实验进行确定,1组典型取值如表1所示。
降噪算法具体步骤为:

表1 不同声音场景下的系数取值表
(1)对每帧信号取绝对值,并对绝对值求平均值Savg;
(2)将平均值转到dB域,得到SdB=20lg(Savg);
(3)计算信号包络
(7)

(4)计算噪声包络
(8)
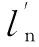
(5)计算信噪比
SNR=ls-ln
(9)
根据声音场景选择噪声抑制函数的参数并计算衰减值,即有
λ=Kn·SNR+An
(10)
(6)执行衰减,抑制噪声。
3 实验与仿真
3.1 测试系统组成
测试系统由计算机、测试用助听器算法实时测试电路板、示波器等组成。测试用源信号由计算机软件产生,通过计算机声卡的Line out(线路输出)接口输出至测试电路板的Line in(线路输入)接口,经测试电路板运行的助听器声音场景分类及降噪算法程序处理后,由测试电路板的Line out(线路输出)接口输出,通过计算机声卡的Line in(线路输入)接口输入至计算机软件进行分析,并可以通过示波器观察并测量波形。具体如图4所示。
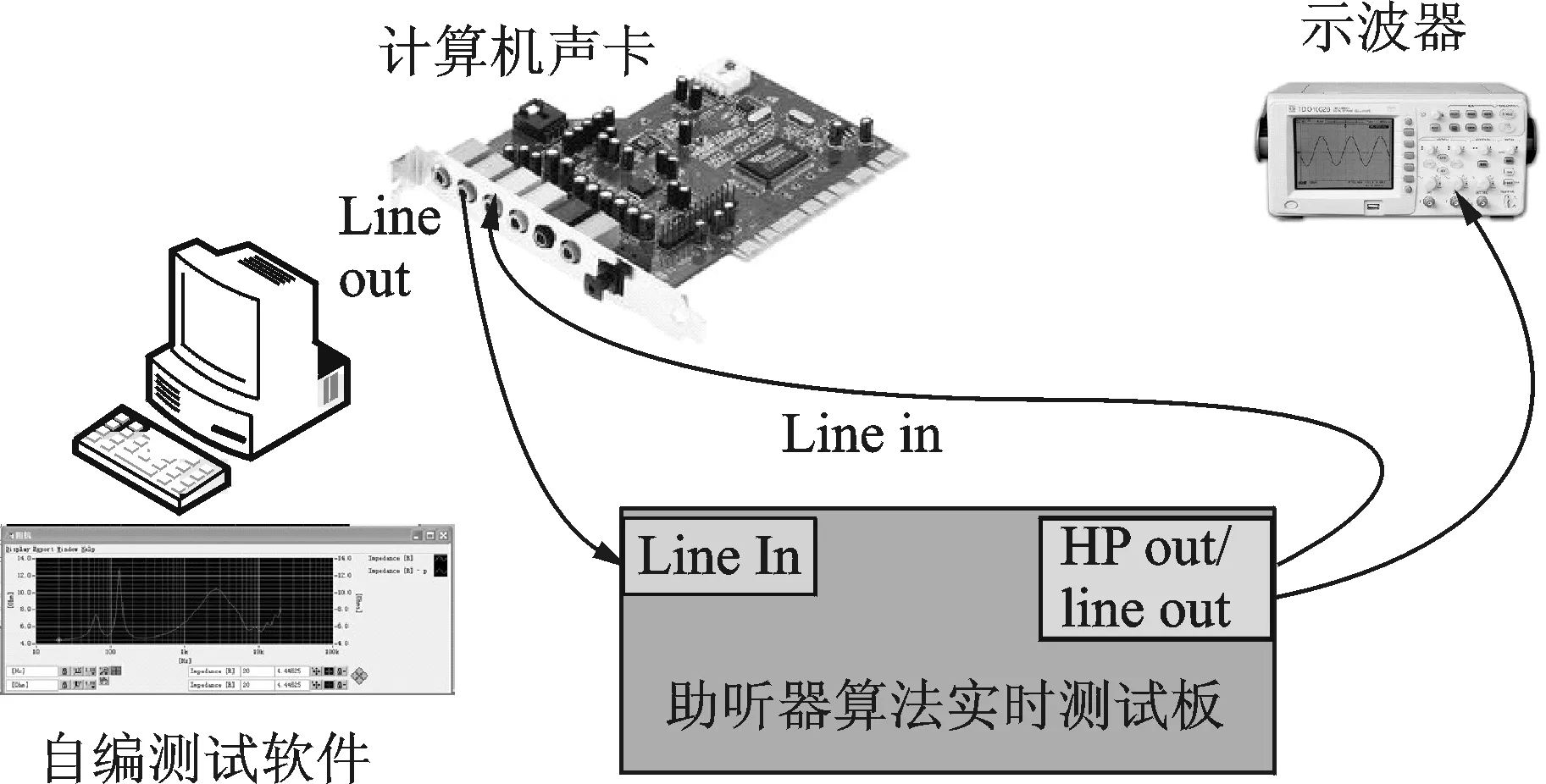
图4 响度补偿与降噪测试系统组成Fig.4 System composition of loudness compensation and noise test
3.2 声音场景分类实验
采用系统事先录制的音频数据库进行了声音场景分类实验。数据库内有纯语音、含噪语音、纯噪音3种类型音频文件,其中纯语音选用人民卫生出版社出版的《汉语普通言语测听CD》中的句表,纯噪音采用NOISEX-92噪声库中的白噪声(White noise)、坦克车内噪声(Tank noise)、餐厅噪声(speech babble)和高频信道噪声(HF channel noise),含噪语音由SurroundRouter专业声场景仿真软件进行合成并播放,信噪比可以调节。其中,信噪比为0 dB情况下的声音场景分类正确率如表2所示,无论是在纯语音、纯噪音还是含噪语音场景,其分类正确率都超过了95%。

表2 不同声音场景下的分类正确率
3.3 噪声抑制实验
对本文提出的降噪算法进行测试,并与传统维纳滤波降噪法进行对比。实验在NOISEX-92噪声库中的White noise,Tank noise,Speech babble和HF channel noise 4种噪声情况下,在输入信噪比为0 dB,5 dB和10 dB下分别测试。实验中语音信号的采样率为16 kHz,帧长为256点,帧移50%。降噪后的语音从输出信噪比、MOS得分、语谱图等方面来评价增强效果。MOS得分采用40人在静音室进行试听,每人试听3种信噪比下的输出语音样本,每种信噪比下的样本试听50句。MOS得分采用5级评分标准,得分越高表示语音质量越好。输出信噪比和MOS得分结果见表3。

表3 本文方法与传统维纳滤波测试结果
在输入为含Tank noise噪声且信噪比为0 dB情况下,维纳滤波法输出信号语谱图与本文方法语谱图如图5所示。从图中可以看出,两种降噪算法都取得了比较好的效果,但本文方法输出信号语谱图背景更干净,声纹更清晰,说明输出语音质量更高。经真耳试听,背景噪声明显变小,语音更清晰。同样条件下,White noise,HF channel noise和Speech babble类型噪声也取得了良好的输出语音质量。
4 结束语
本文针对数字助听器应用,提出了一种基于声音场景分类的噪声抑制算法。算法使用调制滤波法对纯语音、纯噪音和含噪语音3种场景进行分类,并根据分类结果调整噪声抑制算法参数集,得到不同的抑制系数。本文方法在助听器测试系统中取得了良好的实验效果,场景分类正确率在95%以上。在不同的噪声类型情况下,经过本文算法处理的输出语音信号取得了良好的信噪比和MOS评分的提升。本文算法不仅具有良好的信噪比提升效果,而且实时性好,可以应用于需要实时语音增强的其他声学系统,如会议系统、语音通信等。

图5 Tank noise噪声、信噪比为0 dB时维纳滤波法与本文方法输出信号语谱图Fig.5 Output signal spectrogram of Tank noise with 0 dB SNR Wiener filtering method and the proposed method
[1] Scharrer R, Vorlander M. Sound field classification in small microphone arrays using spatial coherences[J].Audio, Speech, and Language Processing,IEEE Transactions on,2013,21(9): 1891-1899.
[2] Gil-Pita R, Ayllon D, Ranilla J, et al. A computationally efficient sound environment classifier for hearing aids[J].Biomedical Engineering, IEEE Transactions on,2015,62(10): 2358-2368.
[3] Büchler M C. Algorithms for sound classification in hearing instruments[D]. Zurich:Swiss Federal Institute of Technology, 2002.
[4] Alexandre E, Cuadra L, Rosa M, et al. Feature selection for sound classification in hearing aids through restricted search driven by genetic algorithms[J].Audio, Speech, and Language Processing, IEEE Transactions on,2007,15(8): 2249-2256.
[5] Maas A L, Le Q V, O'neil T M, et al. Recurrent neural networks for noise reduction in robust ASR[J]. INTERSPEECH,2012,Citeseer: 22-25.
[6] 蔡明琦, 凌震华, 戴礼荣. 基于隐马尔可夫模型的中文发音动作参数预测方法[J]. 数据采集与处理, 2014, 29(2): 204-210.
Cai Mingqi, Ling Zhenhua, Dai Lirong. Hidden-Markov-model-based articulatory movement prediction for Chinese[J]. Journal of Data Acquisition and Processing,2014, 29(2): 204-210.
[7] Sen I, Saraclar M, Kahya Y P. A comparison of SVM and GMM-based classifier configurations for diagnostic classification of pulmonary sounds[J].Biomedical Engineering, IEEE Transactions on,2015,62(7): 1768-1776.
[8] Greenberg S, Kingsbury B E. The modulation spectrogram: In pursuit of an invariant representation of speech[J]. Acoustics, Speech, and Signal Processing, IEEE International Conference on, 1997,3(1):1647.
[9] Dubey R K, Kumar A. Comparison of subjective and objective speech quality assessment for different degradation/noise conditions[C]//Signal Processing and Communication (ICSC), 2015 International Conference on. [S.l.]:IEEE, 2015: 261-266.
Noise Reduction Algorithm Based on Acoustic Scene Classification in Digital Hearing Aids
Wang Jiadong1, Zou Cairong1, Jiang Bencong1, Wang Qingyun2
(1.School of Mechanical and Electric Engineering, Guangzhou University, Guangzhou, 510006, China;2.School of Information Science and Engineering, Southeast University, Nanjing, 210096, China)
A new noise reduction algorithm based on acoustic scene classification is proposed. Three acoustic scenes of pure speech, noise, noisy speech are classified by modulation filter. The parameters of noise reduction algorithm are adjusted by the result of scene classification. Different attenuation coefficient is adopted according to the different acoustic scene. Satisfied experimental results are achieved in the digital hearing aid testing system. Better than 95% accuracy is acquired in acoustic scene classification experiment. In the environment of different kinds of noises input, the signal-noise ratio (SNR) and MOS score are increased apparently. The quality of output speech in digital hearing aids is improved effectively.
acoustic scene classification; modulation filter; noise reduction;SNR
国家自然科学基金(61375028)资助项目;广东灯光和声视频工程技术研究中心开放基金(KF201601,KF201602)资助项目。
2016-02-04;
2016-03-18
TP391.42
A

汪家冬(1990-),男,硕士研究生,研究方向:数字语音信号处理,E-mail:1304943689@qq.com。
王青云(1972-),女,博士,研究方向:语音信号处理。

邹采荣(1963-),男,教授,博士生导师, 研究方向:声信号与语音信号处理。

蒋本聪(1992-),男,硕士研究生,研究方向:数字语音信号处理。
猜你喜欢
现代特殊教育(2022年10期)2022-10-13
现代仪器与医疗(2022年1期)2022-04-19
中老年保健(2021年7期)2021-08-22
北京航空航天大学学报(2019年9期)2019-10-26
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
中华诗词(2018年11期)2018-03-26
雷达学报(2017年3期)2018-01-19
