
基于标签关联规则的挖掘与研究
2017-09-12 03:48刘志刚
科技创新与应用 2017年26期
刘志刚
摘 要:社会化标签系统以其巨大的服务商业价值被越来越多的专家学者关注和研究,在社会化标签系统中,用户可以按照自己的喜好来对各种网络资源帖上标签,能更方便信息的检索和快速查找。标签应用技术也逐渐成熟起来,通过传统的关联规则挖掘方法,对标签数据进行标签预测分析,为用户推荐有参考价值的标签,有助于电商提供产品的精准推广服务,同时促进社会化网络快速、稳定的发展。将文本挖掘、机器学习技术与标签数据相结合,利用Apriori算法来进行基于标签的关联规则挖掘研究。通过研究结果数据分析可知标签预测结果,有很好的标签预测效果,并在各种商业模式的驱动下,作为信息处理的一种抽象形式得到了广泛关注,各种服务即将快速增长。
关键词:服务;标签;社会化标签系统;关联规则;标签预测
中图分类号:TD40 文献标志码:A 文章编号:2095-2945(2017)26-0026-02
本文结合目前的研究现状,利用网络上的真实数据,结合Apriori算法对标签数据进行实验分析,研究一种标签预测算法,有很好的标签预测效果。标签包是标签预测的一种形式,因此文章在标签包的基础上、结合标签的关联规则挖掘框架,并进行了实验分析,给出了实验结果和后续研究的方向。
1 标签包
标签包是一个链接资源的总概括,可以称为标签头。另外还有一个更为具体的子标签集合,可以反映资源的不同方面。利用标签之间的关系来发现与资源相关的标签包。标签不仅能暗示资源的内容,彼此之间含有相似语义关系的一系列标签能组合起来描述一类具有共同特征的资源。但目前网站中“标签包”的构建完全依赖用户手工完成,当用户已经使用了大量标签后,无论是采用标签云还是标签包的方式,用户人工选择标签都非常复杂。另外,“标签包”聚合了用户心中同属一个类别的网络资源,用户浏览标注资源时,可以给用户十分有效的参考。因此,帮助用户寻找语义相关的标签,自动完成“标签包”构建,给用户进行标签的实时推荐,是一项非常有意义的工作。
2 基于标签的关联规则挖掘框架
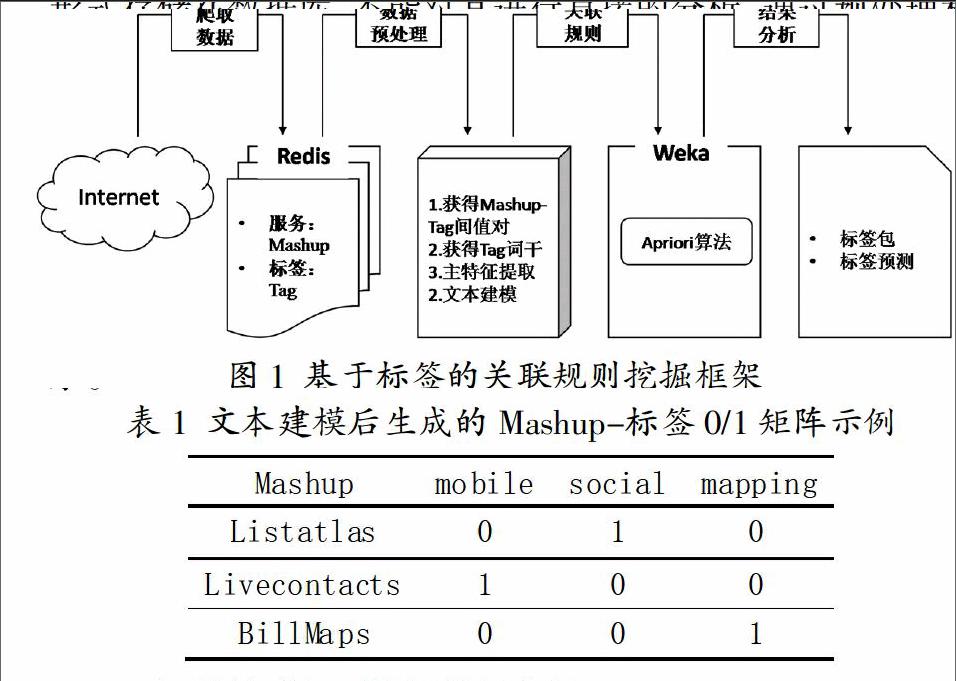
如图1所示,设计一个关联规则挖掘框架,包含四个部分:数据获取;数据预处理;数据利用Apriori算法进行关联规则挖掘分析建模;结果分析。
研究数据通过网络爬虫技术从“http://www.programmableweb.com”网站上爬取得到最新的Mashup、Api和相应的tags数据。在ubuntu12.04系统下,所需配置环境为redis和编ruby爬下来的数据以Key-Value的形式存储在数据库redis中。
数据处理先要获得词干、接着提取主特征值。获得词干:考虑到词的多态与派生,如mails和mail其在描述服务时是完全相同的,所以需要抽取出基本的词根。将一些以复数、过去式、现在进行时等形式出现的标签,通过程序处理生成有相同形式的词干。主特征提取:通过获得词干,生成具有同一形式的標签集合。剩余的词项中仍有很多对分析没有多大贡献。在标签集合中含有大量没有区分度的词,例如:“result”“information”等,很难解释所表达的语义信息。同时含有一些没有代表性的词,这些稀有词项独立表达的信息不强,不足以对关联规则产生影响。通过利用文档频数法(Document Frequency,DF),将在少于50个Mashup服务中出现的关键词去掉,缩减了关键词集合,降低了数据的维度,可以增加关联规则挖掘的效率,降低时间复杂度,对标签预测结果带来比较可观的提升。
最后文本关联规则挖掘分析建模:由于标签是字符串的形式存储在数据库,不能对其进行直接的分析。通过预处理和特征选择,最终得到表示该Mashup服务的关键词集合:Addressdoctor=[validation shipping address mail] 在Mashup服务关键词集合的基础上,所有的Mashup集合可以表示为一个 M×N的Mashup-Tag矩阵 R,这里每个不同的Mashup对应矩阵 R 的一行;而每一个不同的标签对应于矩阵 R 中的一列。R表示为:R=[rij],其中rij为0或1,表示第 j个标签在第i个Mashup服务中是否出现。建模处理后结果数据如表1所示。
3 标签关联规则挖掘数据分析
通常基于某种意图来创建Mashup服务,例如一个与旅游相关的Mashup服务可能是包含了旅游景点的选择、机票的预定、天气预报的查看等等一系列功能的服务组合起来构成的。对于这种含有特定功能的Mashup服务,需要为它添加一些类似于“旅游、天气、酒店、机票”等标签,当这些标签同时出现的时候,对一个未知的Mashup就可以预测到这个Mashup服务的主要功能的内容。所以在进行搜索查询时,可以通过标签之间的一些关联规则来快速的定位想要获取的内容。网站标签推荐系统可以根据整个网站现有的大量信息,通过挖掘出标签的频繁项集,以及标签与资源之间的关联,研究标签经常同时出现的频率,进行标签预测,将规范的标签内容推荐至用户,使用户有更好的体验。
根据所描述研究对象,通过机器学习来挖掘出Mashup的标签之间的一些关联规则,对挖掘出来的频繁项集合关联规则作出恰当分析。
数据中包含4000个Mashup和相应的1528个标签(tags)。由于有些标签的使用量太少(只被几个Mashup使用过),因此生成的0/1矩阵维度很大,并且数据很稀疏。经过数据预处理后,留下64个使用频度比较大的标签作为最终的关联规则分析的实验数据。数据中Mashup作为行属性,tags作为列属性,Mashup服务Mi如果包含标签Tj那么阵Mij=1,反之Mij=0。用weka的Aprior算法对输入的实验数据M4000x64的0/1矩阵进行试验,测试数据表明标签之间的支持度和置信度比较高。因此对于上面提到的标签预测功能,当用户输入像“lyrics”的标签,可以预测出另外一个标签“music”很有可能是用户有意图使用的标签,同样的如果用户输入像“mapping”的标签时,可以给他推荐另外的“travel,hotels”的标签,挖掘出标签mapping的标签包,如下图2所示。
4 结束语
通过解决社会标签预测问题有两个优点:(1)能掌握标签最基本的“信息内容”;(2)可以使用一个标签的预测来改善社会标签网站。后续研究可以通过以下2种方法进行改进:
增加单标签查询的召回率。在标签系统中,大部分的查询对象都有被一个特定的标签标记过。同样,许多标签系统允许用户监控标有特定标签的资源。例如,一个社会书签网站的用户可能会成立一个与“摄影”标签相关的网页导航。标签的预测可以作为一种查询和导航的召回率提高策略。
用户间的协同。许多用户具有相似的兴趣,但可能使用不同的词汇。标签的预测将实现对象的轻松共享,尽管词汇之间存在一定的差异。
参考文献:
[1]魏建良,朱庆华,基于社会化标注的个性化推荐研究进展[J].情报学报,2010,29(4):625-633.endprint
猜你喜欢
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
Coco薇(2015年11期)2015-11-09
股市动态分析(2015年49期)2015-09-10
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
海外英语(2013年7期)2013-11-22
科技智囊(2009年8期)2009-08-26
世界知识(2009年8期)2009-06-10
家教世界·创新阅读(2009年5期)2009-05-26
