
高维数据集中局部离散文本数据挖掘方法研究
2017-10-12 09:18农晓锋
现代电子技术 2017年19期
农晓锋

摘 要: 提出利用基于多目标优化软子空间聚类理论的关联规则数据挖掘方法对高维数据集中局部离散文本数据实现数据特征有效挖掘。首先,利用多目标优化软子空间聚类思想结合非支配排序遗传理论优化加权类内紧致及加权类间分离函数,获取优化后的目标函数及非占优Pareto最优解集,运用加权子空间划分方法对最优解集完成特征聚类;其次,基于关联规则思想运用一种特征提取和关联文本的识别方法,对聚类后的文本特征进行文本间及文本内部的特征识别和分类,即实现了文本信息数据的有效挖掘。实验证明,利用多目标优化软子空间聚类数据挖掘方法可以有效实现高维集中局部离散文本数据的挖掘。
关键词: 高维数据; 数据特征聚类; 数据挖掘; 关联规则
中图分类号: TN911.1?34; TP391 文献标识码: A 文章编号: 1004?373X(2017)19?0138?04
Research on local discrete text data mining method in high?dimensional dataset
NONG Xiaofeng
(Modern Educational and Technological Center, Guilin Tourism University, Guilin 541006, China)
Abstract: An association rules data mining method based on the theory of multi?objective optimization soft subspace clustering is proposed to mine the data feature of local discrete text data in high?dimensional dataset effectively. The thought of multi?objective optimization soft subspace clustering is combined with the theory of non?dominated sorting genetic optimization to optimize the weighted intra?class compactness and weighted inter?class separation function, and obtain the optimized objective function and non?dominated Pareto optimal solution set. The weighting subspace classification method is used to cluster the features of the optimal solution set. A recognition method for feature extraction and text association based on the thought of association rules is used to recognize and classify the features among texts and within texts for the clustered text features, which can realize the effective mining of the text information data. The experimental results show that the data mining method of multi?objective optimization soft subspace clustering can realize the local discrete text data mining in high?dimensional dataset effectively.
Keywords: high?dimensional data; data feature clustering; data mining; association rule
0 引 言
文献[1]指出,在人工智能和数据库领域中,目前各种数据挖掘方法也获得了不同程度的关注。20世纪末开始,人们对各种不同的数据挖掘方法进行深入研究。数据挖掘作为一种决策支持手段,帮助各个领域的专家和开发人员分析各种类型的数据[2?3],然后从中挖掘出潜在的模式并做出正确决策判断。文献[4]中提到数据挖掘通常会利用人工智能、机器学习、模式识别、统计学、可视化等技术来实现该过程。
当前数据挖掘研究领域发展迅速,其面临的问题与挑战也越来越多。第一,越来越大的数据规模,也称之为大规模数据问题;第二,不断增加的数据特征维数引起的问题也称为维数灾难问题;第三,有生物学、脑科学、证券金融等学科的知识背景[5?6]。文献[7]中提出基于上述问题面临的挑战,部分学者提出针对大规模数据的流数据分析方法、针对高维数据的特征加权和特征选择方法。目前数据挖掘领域的研究重点包括很多学科的交叉领域。
由于数据挖掘方法被越来越广泛的应用,本文提出对高维数据集中局部离散文本数据进行有效数据挖掘。首先,运用多目标优化软子空间聚类思想获得优化后的目标函数和非占优Pareto最优解集,最优解集的获取即实现了数据特征聚类;其次,以关联规则思想为基础,通过一种特征提取和关联文本的识别方法实现对聚类后的文本特征进行文本之间及文本内部的特征识别和分类,最终达到有效挖掘文本信息数据的目的[8?9]。
1 高维数据集中局部离散文本数据挖掘研究
1.1 基于多目标优化软子空间的数据特征聚类
多目标优化属于最合理的通用优化方法,在特定条件的约束下,能够优化两个以上的多个目标函数,该过程可描述如下:
多目标优化:最小化[M]个目标函数[fx=][f1x,f2x,…,fMx],找出全部可行域[X]范围内的[D]维决策目标向量[x?=x?1,x?2,…,x?D],通过目标函数变换决策目标向量,则:
[x?=argminx∈Xfx=argminx∈Xf1x,f2x,…,fMx] (1)
式中:[i]表示目标函数数量;[fi?]表示目标函数;[x?]代表决策目标向量;[x]表示解向量。
针对多目标优化的可行解问题,其含有的解是多个或者无限多,组成Pareto集合。因为Pareto集合借助目标函数存在相互占优的关系,所以也称之为非占优解集,可将其描述如下。
Pareto解集:最小化[M]个目标函数[fx=][f1x,f2x,…,fMx,]解向量[x]是全部可行域[X]范围内多目标优化问题的可行解,Pareto解集必须满足最优准则,同时在全部可行域[X]范围内,比[x]更加占优的解向量[x]是不存在的,则:
[?i∈1,2,…,M, fix=fix] (2)
式中[fix]表示占优解向量目标函数。目标优化问题的可行解通过Pareto最优准则来获取,称为Pareto解集。
如果所有数据簇的特征加权系数都是[D]维特征向量,用[wi=wi1,wi2,…,wiD1≤i≤C]表示,[C×D]表示含有[C]个数据簇的染色体长度。其中,[w1]表示初始数据簇的特征因子,由前[D]个基因团来表示,[w2]也就是第二个数据簇的特征因子,以此类推。
定义目标函数以及划分数据样本,聚类评价准则选用模糊软子空间聚类目标函数[JFWSC]来优化目标函数,则[JFWSC]可描述为:
[JFWSC=i=1Cj=1Numijk=1Dwτikxjk-vik2] (3)
式中:[N]表示數据样本的个数;[j]表示常数;模糊聚类指数为[m]的隶属度用[umij]表示;模糊加权指数为[τ]的加权系数用[wτik]表示;维数为[k]的第[j]个可行解用[xjk]表示;[vik]表示聚类中心。获取各个数据簇加权系数[W]及聚类中心[V=vi,1≤i≤C],样本到各个聚类中心的模糊隶属度[uij]可描述为:
[uij=dij-1m-1i=1Ddij-1m-1, i=1,2,…,C; j=1,2,…,N] (4)
式中[dij]表示样本到聚类中心的距离。可描述聚类中心为:
[vik=j=1Numijxjkj=1Numij] (5)
选择聚类评价准则的合理性决定了最终聚类结果的产生,多目标优化问题的适应度函数可选择FWSC目标函数[JFWSC]。然后构建聚类数据集的样本和聚类中心二部图,数据聚类划分可通过图划分方法推导得出。
构建二部图[G=V,E],以二部图[G]为基础,通过谱聚类取得相应聚类中心以及样本点划分的结果,由[VCi]表示每个聚类中心的划分结果,相应的特征加权向量[wi]通过计算得出,同时输出[N]个数据样本的聚类划分。
1.2 关联规则理论下文本数据挖掘
对不同词语数据实现不同加权就是文本特征提取方法,在数据样本中词语的重要性由此表示。加权实现方法中选用布尔加权方式,如果一个文本数据出现在数据样本中,则加权为1,反之为0,加权参数可描述为:
[wij=1,fij≥10,fij<1] (6)
式中:[wij]表示文本加权结果;[fij]表示文本数据在数据样本中出现的频率。
权重可以表示文本数据出现的概率,同时可以反映出文本数据的重要性,是一种基于信息理论的权重计算方法,以熵权重为基础的文本挖掘方法,则:
[wij=logfij+1.0*1+log1Nk=1Nfiknilogfikni ] (7)
式中:[ni]表示研究特征次数;[fik]表示目标函数在数据样本中出现的频率。
通过数字化的归一化方法进行处理实现文本数据挖掘识别过程能够有效地分类度量数据样本中的关键数据,文本个数与最大相关系数互相关联,则可作如下描述:
[maxLac=log2k] (8)
式中:[Lac]表示相关系数;[maxLac]表示各个特征类信息熵的最大值;[k]为常数。
变化加权时采用固定系数coff1和coffconst对IDF1和IDFconst值进行适度调整,可以达到较好的分类效果。
关联挖掘属于一种数据处理的挖掘方法,基于数据关联度挖掘文本特征。文本挖掘首先要将文本挖掘区域划定,参数[xi,yi]表示各文本在区域[Z]中的坐标,也就是文本坐标。假设将该区域视为图像区域,设定像素点为[p,q,]若存在待识别的数据为[K(r),]运用关联规则挖掘该数据的概率为:
[Q(Z)=KZpqp×q] (9)
式中:[Q(Z)]表示在文本[Z]区域内数据信息的挖掘概率;[KZpq]表示区域中的某文本数据样本点。
利用关联度挖掘方法对高维数据集中局部文本数据进行数据样本的特征提取,并利用关联规则求解出数据被挖掘的概率,通过以上步骤可以较好地实现高维数据内部特征的描述,完成数据挖掘过程。
2 仿真实验与结果分析
数据规模的不断增大使数据挖掘成为核心的研究课题,本文以高维数据集中局部离散文本数据为研究对象,运用基于多目标软子空间聚类理论的关联规则法对其进行数据挖掘。通过以下实验验证本文方法的可行性,具体如下。
实验1:在对数据特征实现挖掘前,先对数据进行特征聚类处理,实验设定高维文本数据共8组,每组为400个样本,要求聚类为5个数据簇,每个簇为80个高维文本数据。采用本文多目标软子空间聚类方法及数据流软子空间聚类方法对实验给出的400个文本数据进行聚类处理,获取经过聚类处理后的数据簇结果及每个簇含有的文本数据个数,将结果与设定结果进行比较。具体数据结果如表1,表2所示。
根据实验条件设定每组为400个数据样本,经过聚类处理后,400个文本数据聚类为5个数据簇,且每个数据簇内包含80个数据样本。对照实验事先设定的条件,表1为利用数据流软子空间聚类法获取的聚类结果,观察聚类后形成数据簇的结果能够看出,利用该方法获取的数据簇个数与实验预先设定结果不相符,表明利用数据流软子空间聚类法对文本数据并未准确实现聚类处理;表2为多目标软子空间聚类方法获取的聚类结果,从表2能够观察出利用该方法经过聚类处理后形成的数据簇个数及每组数据簇包含的文本数据个数与实验事先设定的限制条件吻合,依据结果显示,利用本文多目标软子空间聚类方法能够对高维文本数据进行有效聚类处理。
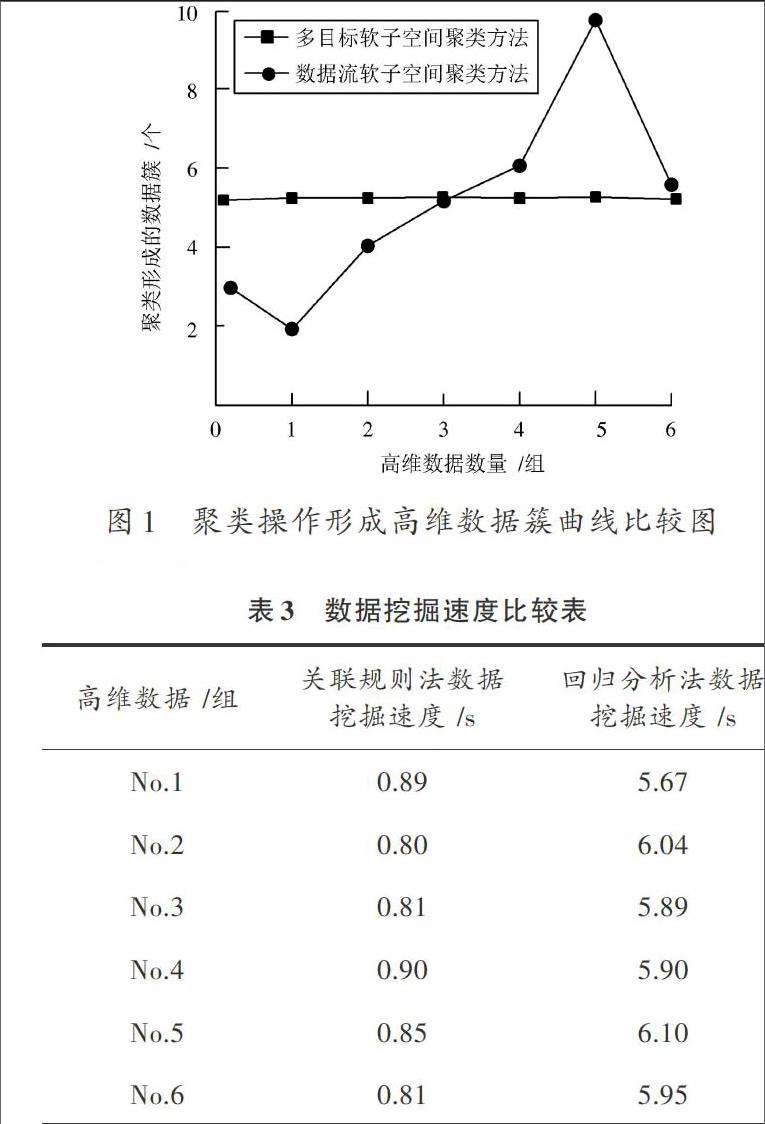
利用数据流软子空间聚类法及本文多目标软子空间聚类方法对文本数据进行聚类处理后形成曲线,并比较两条曲线的差异,具体如图1所示。
观察图1能够看出,运用本文多目标软子空间聚类方法对400个文本数据进行聚类处理后,获取的数据簇为5个,而运用数据流软子空间聚类法进行聚类处理后,形成的数据簇结果与实验预先设定结果不吻合,比较两种聚类方法,本文方法更为有效。
实验2:为测试文中关联规则方法的有效性能,实验给出900个高维数据,将其分为6组。通过运用本文方法及回归分析法对高维数据进行数据挖掘,比较两种方法数据挖掘的速度,具体数据如表3所示。
3 结 论
数据挖掘是对数据进行特征有效分类及挖掘其内部关联性的一种方法,在众多科学领域中得到了广泛应用。因此,本文以高维数据集中局部离散文本数据为研究对象,提出基于多目标软子空间聚类理论的关联规则法对数据实现挖掘。首先,将多目标软子空间聚类理论与非支配排序遗传思想结合,获取Pareto最优解集,对数据实现聚类处理;其次,运用关联规则数据挖掘法在数据特征聚类结果的基础上,采用本文特征提取法对文本数据进行特征分类与识别,最终实现高维数据集中局部离散文本数据的挖掘过程。
参考文献
[1] 张银柯,张骥,赵达.基于CNKI数据库的文献探索我国人工智能的研究状况[J].内江科技,2016,37(1):79?80.
[2] 王元卓,贾岩涛,刘大伟,等.基于开放网络知识的信息检索与数据挖掘[J].计算机研究与发展,2015,52(2):456?474.
[3] 王乐,王芳.数据库异常数据的检测仿真研究[J].计算机仿真,2016,33(1):430?433.
[4] 米允龙,米春桥,刘文奇.海量数据挖掘过程相关技术研究进展[J].计算机科学与探索,2015,9(6):641?659.
[5] 耿娟,焦红兵.统计学专业数据挖掘课程教学探索[J].产业与科技论坛,2016,15(3):202?203.
[6] 何光凝.数据挖掘在计算机网络安全领域的应用研究[J].技术与市场,2016,23(8):13.
[7] 许丽娟.基于自适应波束形成的高维数据挖掘算法[J].电声技术,2016,40(3):65?68.
[8] 邱云飞,狄龙娟.基于簇间距离自适应的软子空间聚类算法[J].计算机工程与应用,2016,52(21):88?93.
[9] 张春生.大数据环境下相容数据集的关联规则数据挖掘[J].微电子学与计算机,2016,33(8):34?39.
[10] 董本清,彭健钧.复杂网络数据流中的异常数据挖掘算法仿真[J].计算机仿真,2016,33(1):434?437.
[11] 郭崇,王征,纪建伟,等.电力用户数据中用电特征数据挖掘模型仿真[J].计算机仿真,2016,33(5):447?450.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电力与能源(2017年6期)2017-05-14
电子技术与软件工程(2016年22期)2016-12-26
移动通信(2016年20期)2016-12-10
中国中医药信息杂志(2016年7期)2016-12-01
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
电子设计工程(2014年18期)2014-02-27
