
基于并行队列的众核平台入侵检测系统
2017-11-08 10:21陆遥余翔湛
智能计算机与应用 2017年5期
关键词:并行计算
陆遥+余翔湛
摘要: 本文通过分析和总结以Suricata为代表的现有的主流并行化入侵检测系统的体系结构,并对Suricata的3种工作方式结合现有tilera系列硬件平台的硬件特点进行了理论分析。提出了众核入侵检测系统的设计要点。并设计了一种基于非统一内存访问与内存池的入侵检测结构。该结构将传统的流水线模式与并发模式相结合,在尽可能少地进行核间通讯的前提下,最大程度地提升了单核的内存使用效率和cache命中率。同时使用共享内存池进一步提高了读写密集情况下的内存使用效率,使用改进的无锁通讯队列保证了核间通讯的效率,使得该架构在众核平台具有很高的实用性,其主要模块的设计思想也具有一定程度上的可移植性。本文最终设计并实现了一个高效的基于众核平台的入侵检测系统。
关键词:入侵检测系统; 众核; 流量识别; 并行计算
中图分类号: TP393.08
文献标志码: A
文章编号: 2095-2163(2017)05-0082-05
Abstract: In view of the hardware characteristics of the existing tilera series hardware platform, the three kinds of working modes of Suricata are analyzed theoretically in this paper. The main points of the design of the system for the detection of the multicore intrusion are put forward.Based on the main point of the design, this paper proposes an intrusion detection architecture which has nonuniform memory access and large page memory pool. The structure combines the traditional pipelined mode with the concurrent mode, and improves the memory efficiency and cache hit rate of the single core to the greatest extent. At the same time, the use of shared memory pool further improves the memory efficiency of dense reading and writing, which makes the structure has very high practicability in the multicore platform, and the design of the main module also has a certain degree of portability. Consequently, this paper designs and implements an efficient intrusion detection system based on manycore platform.
Keywords: identification detection system; manycore; flow recognition; concurrent computation
0引言
据统计,互联网流量已达到每12个月即会增长一倍,超过了摩尔定律的速度[1]。相比于在未来一定时间将持续快速增长的网络带宽,单一处理器的计算能力却日趋瓶颈。相关人士认为未来芯片的迭代会变得更慢,其间隔可能会达到2.5~3年。目前英特尔最新一代处理器已采用14 nm工艺,正在逐步接近现有处理器架构的物理极限。若按现在的速度继续发展,到21世纪20年代中期,晶體管的尺寸将仅有单个分子大小,晶体管也将变得非常不稳定,若没有新的技术突破,摩尔定律将会彻底终结。同时,由于单纯提升主频而带来的发热等问题,基于单核、多核处理器的普通网络报文捕获平台的计算性能已经成为大规模网络防火墙、宽带网络入侵检测系统以及高性能路由等网络工程的性能瓶颈。对于现在乃至未来更大规模的高速网络,如何突破普通报文捕获平台的性能瓶颈,研究和实现面向大规模宽带网络的高性能网络数据捕获技术,对并行处理、网络安全、高性能路由器等诸多领域都有着非常重要的意义。
作为突破单核、多核性能瓶颈的手段之一,众核处理器作为拥有强大并行处理能力的新一代处理器,成为有效解决以上问题的手段之一。目前的众核处理器可集成数十至几百个核,每个核是一个执行单元,对整个数据包或其中的一个子任务进行处理。现代高性能并行处理系统通常采用超标量流水线结构,数据包处理划分成多个并行子任务集,每个子任务集是由众核处理器中的若干个核并行执行,子任务集到核资源集的映射由运行时系统完成[2]。随着技术发展和需求推动,未来处理器将集成几百甚至上千个核,这类处理器系统一般称为众核处理器系统。众核处理器核数的增加保证了计算和数据处理能力持续提高,然而如何使这种硬件能力转变成应用性能的提升,是众核时代面临的严峻挑战之一。
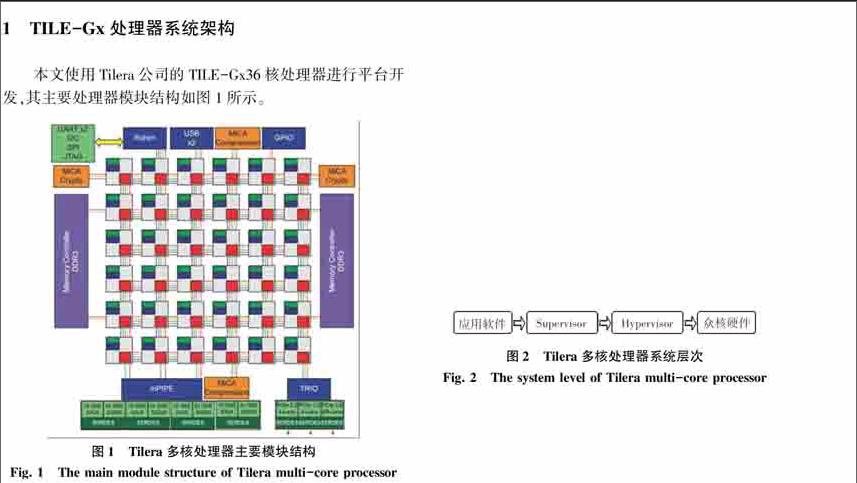
本文基于美国Tilera公司的TILE-Gx系列处理器进行众核平台数据包捕获系统的设计。成立于2004年的Tilera是一家致力于开发通用型多核心处理器的新兴无晶圆半导体业者。该公司的Tile处理器架构源自于Agarwal博士早从1990年代起在麻省理工学院(MIT)研发的多重处理器丛集技术。其TILE-Gx系列处理器是世界上第一款100核心以上的处理器,采用网格化多核架构,通过iMesh网络实现众多处理器核互联,将单芯片处理能力提高了数十到数百倍,在外接2块Intel万兆网卡的情况下可以满足在重要网络出入口上进行高速捕包的硬件性能需求[3]。endprint
该平台具有36个计算核心,64-bit VLIW超长指令字架构并支持64位指令集和40位物理寻址空间,每个通用目的处理核心都有自己的32 KB一级指令缓存、32 KB一级数据缓存、256 KB二级缓存切换开关,共享三级缓存,并集成了智能NIC硬件,用于网络流量的预处理、负载均衡、缓冲管理。TILE-Gx系列采用台积电40 nm工艺制造,37.5×37.5 mm BGA封装,主频为1.2 GHz,所有计算核心共享双通道内存访问控制,可提供3个PCI-E 2.0 x8、2个千兆和2个万兆以太网端口、3个USB 2.0端口,典型功耗48 W,平均每个核心不到0.5 W[4]。配合万兆网络接口探讨此类众核硬件系统的高速捕包系统架构。
由此可以看出,该平台具有典型众核平台所具有的特点,即单核计算能力相比传统单核处理器较弱,相比于已经具有单核4.2 GHz,6 MB三级缓存的最新一代英特尔酷睿i7-7700处理器,单核频率仅有1.2 GHz且只独占256 KB二级缓存的Tilera-GX36处理器在性能上明显较差。然而其具有的36核iMesh网络在大规模并行计算上可以弥补其单核性能的不足。同时其平均每个核心不到0.5 W的功耗也在实用性上更胜一筹。
在系统方面,其系统结构如图2所示,由Hypervisor层、Supervisor层和应用软件层三层构成。在此,针对各层的功能概述可作阐释解析如下。
首先,Hypervisor层是硬件驱动程序层,管理内核间、内核与IO控制器间的通信,提供—个底层的虚拟内存系统;每—个内核上都运行—个单独的Hypervisor实例。
其次,Supervisor层是SMP Linux操作系统,通过Hypervisor管理硬件资源,为用户应用程序和库提供系统命令、IO设备、进程和虚拟内存分配等高级别服务;这一层允许多进程/多线程的应用来提升多核的性能。
最后,应用软件层是软件体系的最上层,该层程序代码通过操作系统调度、管理硬件资源,实现各种具体应用功能[5]。同时,应用软件层除了和x86架构一样支持C实时库、NetlO库等标准库之外,还支持Tilera多核组件库等专用库。因此在本质上,使用Tilera众核处理器的服务器依然具备标准的硬件、底层驱动、操作系统、应用软件的层级结构。
2基于众核平台的入侵检测系统模型
2.1现有x86架构主流入侵检测系统架构分析
人们将即时监视网络中的流量传输,对可疑传输进行报警,并在特定情况下采取主动反制措施的网络安全设备称为入侵检测系统(Intrusion Detection System,IDS)。由定义可以看出在设计上虽然主要行使检测功能,但仍属于主动安全防护技术的一种,这使得IDS区别于其他网络安全设备。
按照IETF的定义,一个入侵检测系统可以分为以下4个组件:
1)事件产生器(Event generators)。功能目的是从整个计算环境中获得事件,并向系统的其他部分提供此事件。
2)事件分析器(Event analyzers)。可经过分析得到数据,并产生分析结果。
3)响应单元(Response units)。就是对分析结果作出反应的功能单元,可以作出切断连接、改变文件属性等强烈反应,也可以只是简单的报警。
4)事件数据库(Event databases)。 是存放各种中间和最终数据的地方的统称,既可以是复杂的数据库,也可以是简单的文本文件[6]。
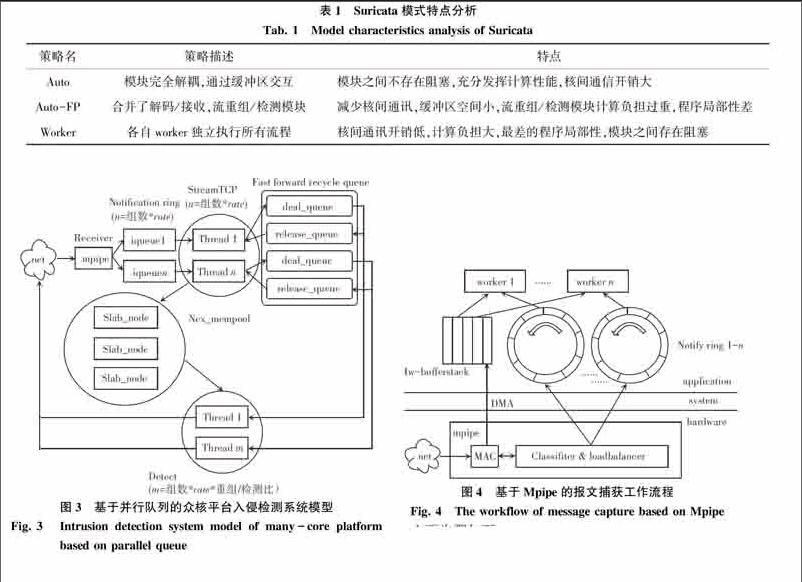
在目前的众多的IDS中,由开放信息安全基金会开发的Suricata应用最为广泛,对多线程与分布式计算支持较好,稳定性较高的系统之一。Suricata通过libpcap、netmap、af-packet等工具获取报文,数据接收模块为从网卡的接收队列中接收数据包,并将封装在Packet结构中,然后放入下一个缓冲区。解码模块对缓冲区中数据包进行解码,主要是对数据包头部信息进行分析并保存在Packet结构中,再交由流重组TCP模块对数据包进行TCP流重组。重组完成的TCP流由协议插件模块检测是否包含入侵行为,再由Verdict模块经过内核对数据包进行接收或丢弃的判断处理。最后通过应答模块调用libnet对要执行阻断操作的数据包进行相应的阻断处理。
策略名策略描述特点
Auto模块完全解耦,通过缓冲区交互模块之间不存在阻塞,充分发挥计算性能,核间通信开销大
Auto-FP合并了解码/接收,流重组/检测模块减少核间通讯,缓冲区空间小,流重组/检测模块计算负担过重,程序局部性差
Worker各自worker独立执行所有流程核间通讯开销低,计算负担大,最差的程序局部性,模块之间存在阻塞
[HT5”SS][ST5”BZ][WT5”BZ][FL(2K2]
2.2现有x86架构主流入侵检测系统架构分析
为了平衡系统核间通讯与程序局部性的开销,最大化发挥众核平台的性能,本系统提出一种基于并行队列的处理模型。该模型采用将模块分组并行的方式,组内采用流水線模式处理数据,组间独立并行运行,系统流程图如图3所示。
该系统依然按照传统入侵检测系统的工作流程设计,划分为3个主要模块:数据接收模块、流重组模块与检测模块。架构采用了基于并行队列的分布式数据流模型,其主要流程为数据接收模块完成Tilera硬件api的调用,通过Mpipe进行数据包的解码与负载均衡,将来自旁路监听的网络端口的数据包解析至ip层后直接拷贝至数据流保存在iqueue中并完成后续模块的硬件绑定与任务派生和相关初始化工作。流重组模块基于Rafal Wojtczuk的网络入侵检测接口Libnids完成tcp流重组与syn表的维护工作,再将数据包还原成数据流写入内存池,并将各内存池所需的描述符结构与缓存数据按照各自对应的检测模块通过改进的无锁循环消息队列分发到相应的处理队列中,进而回收释放队列中的内存池资源。最后由检测模块从内存池中获取内容,并调用相应的插件完成解析与响应工作,将相应句柄放入释放队列中。endprint
总体上,该系统结构上与autoFP模式有一定的相似之处,其主要不同之处为数据接收模块使用与硬件交互的Mpipe模块完成对数据包的零拷贝缓存、解析、负载均衡分发操作,最终的结果通过iqueue环形队列进行缓存,又直接使用单独的内存池完成对共享内存的管理,并在传输层按照一定的比值对所对应的检测模块进行流分发,在模块间通讯策略上采用了改进的无锁循环队列Fast forward recycle queue。而且由单纯以CPU的倍数决定的并发模型改为按照计算核心的物理空间进行分组同时使用了核心绑定。
3基于众核平台的入侵检测关键技术
3.1基于Mpipe的高性能数据捕获平台设计
为了解决传统网络数据包捕获平台中的性能瓶颈,需要结合新的硬件平台对于数据捕获流程进行优化,减少数据拷贝,数据同步的过程。对于数据包接收、完整性校验、负载均衡等所有网络应用均会用到的,原本由系统层面完成的工作,尽可能以新硬件的形式整合进网络接口中。而对于用户层空间,则保留对于不同应用程序的接口以对应不同的需求。
本文设计了基于Tilera公司的Mpipe (Multi-core programmable intelligent packet engine)网络接口的高性能捕包平台。数据的捕获、数据校验、负载均衡等操作均通过Mpipe高性能网络接口完成,Mpipe是基于Tilera平台的一套高性能网络接口,理论上可实现40 Gbps线速数据流的分类转发。通过该平台可以实现在Tilera众核服务器设备中从物理网络接口到用户空间的直接写入,并使用专用硬件完成数据包的完整性校验与负载均衡,极大简化了数据捕获的流程[7]。同时使用无锁环形队列实现了用户层与硬件网络接口的高效无锁通讯,在通讯内容上采用基于描述符的消息传递机制,减少了数据拷贝的开销。主要的数据捕获流程如图4所示。
主要步骤如下:
1)Mpipe对捕获的数据包进行特征提取,并由专用硬件剥离完成以太包头部、计算校验和等操作。
2)发起DMA请求,由网卡通过DMA将接收到的数据包从网卡缓冲区写入内核缓冲区。
3)使用生成的描述符按照一定的规则写入对应用户空间的Notify ring中。
4)worker通过notify ring获取描述符,访问缓冲区,完成上层操作。
3.2改进的无锁队列核间通信技术
一般情况下,为了保证数据不被多个线程同时读写会采用同步锁以确保同步性,然而这会使得大量线程阻塞在临界区,造成性能的急剧下降。Lamport算法已经证明,在顺序一致性模型下,单生产者、单消费者队列的锁可以去掉,从而形成一个并发无锁队列[8]。因此并行程序的一致性问题最好通过算法的方式实现进程的顺序一致性从而避免冲突。
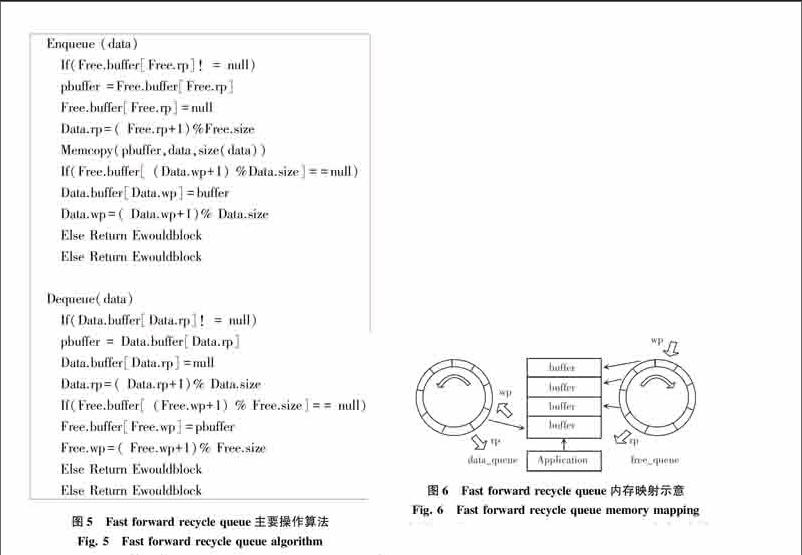
在固定尺寸的循环队列中,由于不存在同步锁带来的延迟,系统核间通信的开销将重新回到内存的读写与分配中。在经典的无锁队列Lamports queue和Fast forward queue中,由于指针指向空间的动态变化,每次环形队列的读写都会伴随一次空间的申请释放操作。如果想要进一步减少核间通讯的开销,必将从减少核间通讯时内存的申请与释放操作入手。本系统基于经典的无锁队列算法,参照下文中内存池的内存块回收思想提出了无锁回收队列算法(Fast forward recycle queue),算法主要操作如图5所示。
[
无锁回收队列算法使用2个Fast forwards CLF Queue分别作为Data queue与Free queue,分别用来保存已使用空间和未使用空间。在队列初始化时,将为Free queue的每一个元素预分配一部分空间。当有数据需要通过队列传输时,将首先从Free队列中申请需要的空间,并直接使用该部分的内存空间保存传输结果。当读写完毕进入传输环节后,将该空间指针pbuffer写入data队列,这样接收端可以直接通过pbuffer访问数据。当数据访问完成后指针从Data queue中取出重新进入Free queue等待下一次申请。相比于Lamports queue,该方法所使用的Data.rp和Free.wp变量为接收端私有,Free.rp和data.wp变量为发送端私有,从而避免了因为共享变量产生的cache颠簸问题。相比于普通的Fast forwards CLF Queue,无锁回收队列算法主要的区别在于内存区块的映射方式,具体的内存区块映射方式如图6所示。
由图6可见,Fast forward recycle queue与标准的Fast forward不同之处主要区别在于其拥有2个队列,队列中仅保存buffer指针,而实际的buffer空间是由data_queue与free_queue共享的。当应用程序申请队列空间时可以直接使用申请的buffer空间作为自身共享缓存,同时通信完成后该区域也并不释放,只是将指针归还到free_queue中,当下一次buffer被申请时数据将直接覆盖写入该内存块。由于一般类型的数据结构大多都有内建的边界控制或同时传输缓存区尺寸的描述符,因此无需考虑此处的数据污染问题。通过该方式可以实现仅在系统启动时完成一次内存申请,之后便可直接读写重复利用空间。
4系统综合性能评估
采用了基于并行队列的系统整体性能评估方法测量系统整体吞吐量(Throughput)。其定义为:在没有包丢失的情況下,设备能够接受的最大速率,这是衡量入侵检测系统性能的主要指标之一。
Tilera Gx36处理器拥有36个计算核心,使用2路NUMA完成内存访问,本系统采用将计算核心镜像划分为2组的方式最大限度地使用内存控制器的带宽。通过前一章节对于入侵检测系统的模块计算资源占用测量,可以得到计算量占比最大的分别为检测和流重组模块。因此各组均固定使用一个核心作为接收模块完成数据接收与Mpipe调用,之后的其他核心均用作流重组/检测模块,其计算核心的比值作为重组/检测比。在不同协议/流量环境,不同计算平台上可能会存在不同的最优值,从而实现最佳的系统性能。本次实验环境采用的是每组17个计算核心,出于方便分组考虑使用16个核心绑定流重组/检测模块,可采用的重组/检测比为1/1、1/2、1/3、1/5、1/7,其中1/2为5组重组检测比为1/2的核心与1组重组检测比为1/1的核心,1/5为2组1/5的核心与1组1/3的核心,当重组检测比不一致时存在的负载均衡问题,会结合检测结果进行探讨。endprint
将本系统部署于最高可达20 Gb/s以上日常流量的某网络节点测试环境中进行测试,同样使用随机生成的1 000条http规则作为参照。经测量该实际流量的平均包尺寸为780 byte,其中http协议流量数据包占比约为72%。系统注册插件为基于AC自动机的http关键字检测模块,配置有1 000条常用http关键字检测规则。通过对不同重组/检测比的系统吞吐量进行测量,并将其与Suricata运行模式中定义的Worker模式为标准的传统并发式系统架构的吞吐量进行对比,同时并发架构未采用计算核心绑定、ncx_pool、无锁回收队列等本系统的改进点,系统总体性能如图7所示,其中横坐标为重组/检测比中的分母,即1个重组模块对应的检测模块个数,纵坐标为吞吐量Gb/s。
从图7中可以看出,基于非统一内存的计算核心分配方案当重组/检测比较低,即在流重组分配内核较多的情况下主要瓶颈在于检测模块,当重组检测比为1/1时相当于只对应一个检测模块,其性能略低于未采用任何优化的并发模型,说明其架构性能要明显弱于系统的并发模型。随着重组/检测比的不断降低,系统吞吐量显著提高,这也说明了由于测试流量中http流量占比较高,http关键字检测的计算流程涉及到较为复杂的多模式匹配,同时http实际流量中包含了图片等容量较大的信息,网络流量数据的检测开销明显大于流重组开销。随着检测模块的增加开始比达到1/3和1/5时系统性能达到最高值6.9 Gbps。之后随着流重组模块的减少,系统吞吐量出现了逐渐下降。
通过以上数据可以看出,由于将内存局部性较强的流还原和检测2个模块拆分,并按照NUMA节点的计算核心分配情况进行了分组,同时加入了计算核心绑定,使用ncx_pool内存池等优化,系统的内存利用率得到了有效提升,有效提高了缓存利用率。主要体现在当系统以合适的重组/检测比运行时吞吐量的明显提升,相比于传统的并行模式,在Tilera Gx36平台下基于非统一内存的计算核心分配方案可以使系统吞吐量提升约50%。同时也应注意,在1/2、1/5处由于重组/检测比会出现负载均衡问题,实际性能会低于该结构下的理论性能。尤其在1/2处可以看到曲线有1个明显的下凹,此处是因为有1个组从1/2降低到了1/1,即通信队列的缓存空间需求增加了1倍,此时可能会造成系统阻塞在缓存空间申请处,[LL]
从而影响了系统整体吞吐量。可以推测,随着可用计算核心数量的增加,在实现核心均匀分配的情况下,相比于当下,1/2、1/5的重组检测比的分配方式具有更高的性能。
5结束语
本文通过对传统并行入侵检测模型与现有Tilera系列硬件平臺的硬件特点进行分析,提出众核平台的并行化系统设计要点,并设计和实现了高速并行化入侵检测系统。本文主要取得的研究成果如下:
1)分析和总结了以Suricata为代表的主流并行化入侵检测系统的体系结构,并对Suricata的3种工作方式结合现有tilera系列硬件平台的硬件特点进行了理论分析,提出了众核入侵检测系统的设计要点。
2)结合提出的系统设计要点,提出了一种基于并行队列的入侵检测结构。该结构将传统的流水线模式与并发模式相结合,在尽可能少地进行核间通讯的前提下,最大程度地提升了单核的内存使用效率和cache命中率。同时使用改进的无锁回收消息队列和共享内存池进一步提高了读写密集情况下的内存使用效率,使得该架构在众核平台具有很高的实用性,其主要模块的设计思想也具有一定程度上的可移植性。最终实现了一个高效的基于众核平台的入侵检测系统。
3)完成了对系统整体在不同核心分配方案下相比于传统并发模型的性能测试。实验结果表明,本系统在众核平台的运行效率要明显优于传统的并行入侵检测系统,体现出了非常高的系统资源使用效率。
参考文献:
谭章熹,林闯,任丰源,等. 网络处理器的分析与研究[J]. 软件学报,2003,14(2): 253-267.
[2] 罗章琪,黄昆,张大方,等. 面向数据包处理的众核处理器核资源分配方法[J]. 计算机研究与发展,2014,51(6):1159-1166.
[3] 陈远知. 多核处理器的里程碑——TILE64[J]. 计算机工程与应用,2009,45(专刊):307-309.
[4] Tilera. Tile Processor Architecture Overview for the TILE-Gx Series, UG130[Z]. USA:Tilera Corporation,2012.
[5] 陈远知,杨帆. Tilera多核处理器网络应用研究[C]//第五届信号和智能信息处理与应用学术会议. 北京:中国高科技产业化研究会,2011:98-100,120.
[6] 叶颖, 严毅. 基于通用入侵规范下网络入侵检测系统的实现[J] . 广西大学学报(自然科学版),2005,30(Supp):55-57.
[7] Tilera. MDE mpipe Programmer's Guide, UG506[Z]. USA:Tilera Corporation,2013.
[8] [JP3]ADVE S V, GHARACHORLOO K. Shared memory consistency models: A tutorial[J]. Computer, 1996,29(12):66-76.endprint
猜你喜欢
软件导刊(2017年1期)2017-03-06
计算机应用(2016年12期)2017-01-13
科学与财富(2016年15期)2016-11-24
大经贸(2016年9期)2016-11-16
中国新通信(2016年16期)2016-10-18
计算机辅助工程(2016年3期)2016-08-01
电脑知识与技术(2016年14期)2016-06-30
科技视界(2016年11期)2016-05-23
电脑知识与技术(2015年12期)2015-07-18
湖南大学学报·自然科学版(2015年2期)2015-04-20
