
基于深度增强学习的自动游戏方法
2017-11-21 09:42,,,,
长江大学学报(自科版) 2017年21期
,,,,
(长江大学信息与数学学院,湖北 荆州 434023)
基于深度增强学习的自动游戏方法
袁月,冯涛,阮青青,赵银明,邹健
(长江大学信息与数学学院,湖北荆州434023)
增强学习近年来多被用于智能体自动游戏,但增强学习在面对过大的状态或者行动空间时不能很好地处理。深度增强学习结合深度学习的感知能力和增强学习的决策能力,可以有效解决环境复杂问题。将增强学习与深度学习结合,通过改进的Markov决策过程逐步学习最优策略。首先找到目前的环境中最有价值的状态,从而产生最大积累奖励的行动,然后通过利用深度增强学习方法训练计算机自动完成一个简单游戏,使用控制变量法分别分析迭代次数和游戏难易程度对游戏得分的影响。试验结果表明,在外界环境相同时,准确率随着试验迭代次数的增大或游戏难度的减弱而增大,从而验证了智能体可以通过外界因素的改变进行更有效训练,最终获取最优结果。
深度增强学习;自动游戏;智能体
近年来,深度学习已经成为人工智能领域的研究热点,其主要思想是通过训练深度神经网络,从高维数据中提取数据的深层特征[1]。增强学习作为一种重要的机器学习方法,其目的在于根据不同目标构造一个最优策略。即当智能体(Agent)处于某种动态的未知环境时,通过与环境状态的交互作用,以环境反馈为输入,然后不断学习,改进自身性能并调整行为,最终使所获的累计奖励最大化[2,3]。深度增强学习结合深度学习的感知能力和增强学习的决策能力,引起了研究者的广泛关注,形成了人工智能领域新的研究热点,在游戏、机器人控制、机器视觉等应用领域都有着广泛的应用[4,5]。下面,笔者利用深度增强学习方法训练计算机自动完成一个简单游戏,并且分析训练次数对游戏得分的影响。
1 算法描述
1.1策略
Agent执行每一步所获得回报,该回报是对后面每个状态的影响的总和,状态是指Agent在某时刻所能观察到的环境状况,状态决定下一步的动作,动作又对应着一种状态,因此状态和动作存在某种映射关系,这个过程称为策略。策略用策略函数表示为:
at=π(st)
(1)
式中,st是时刻t的图像输入,即Agent在时刻t的状态;at是Agent下一步的行为。
Agent根据自己观测到的st选择一种行为at,环境接收到at后,会更新状态为st+1。在这个游戏里,增强学习的任务就是找到一个最优策略,使得累积回报达到最大。
通常,为了简化增强学习模型,将该模型表示为一Markov过程,即下一状态仅取决于当前的状态和当前的动作。因此,状态由来自游戏的帧序列(由于人眼的视觉暂留特性)以及玩家最近一次的动作(而并非之前所有动作)确定。为确定下一状态,需要定义一个函数,并求出其最优值,即最优动作价值函数。
1.2最优动作价值函数
因为动作对应的状态唯一,而状态对应的动作不唯一,因此用动作产生的回报更有利于找到最优策略。而一个行为产生的奖励肯定发生在行为之后,可以用一个价值函数来定义动作的潜在价值,即对未来回报的期望,表示为:
Qπ(s,a)=E[Rt|st=s,at=a,π]
(2)
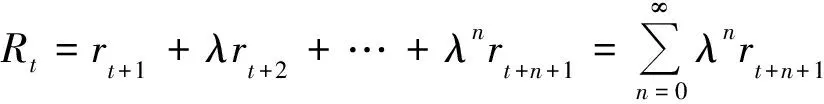
Q*(s,a)=arg maxπQπ(s,a)
(3)
即从所有策略中选择Q值(即累积回报)最大的。计算最优Q值需要进行大量试验,鉴于试验的复杂性,可以通过使用Bellman方程迭代更新得到最优Q值,即:
Q*(s,a)=Es′[r+λmaxa′Q*(s′,a′)|s,a]
(4)
式中,r是t时刻的奖励;maxa′Q*(s′,a′)是使t+1时刻的a′达到最大的Q值。显然,当前状态下是无法得知下一步情况的,但上一步的状态可以得到,因此可以通过每次迭代新得到的r和之前的Q值更新Q值:
Qi+1(s,a)=Es′[r+λmaxa′Qi(s′,a′)|s,a]
(5)
理论上可以证明,当i→∞时,Qi→Q*[7]。
在求解最优动作价值函数时,每次迭代都要将所有的Q值更新一遍,而在此过程中只有有限的样本提供给系统,为了减小估计误差造成的影响,不直接将目标Q值赋给下一个,而是尝试用一个神经网络来近似Q-函数,这个神经网络其实就是一个卷积神经网络,称为深度Q-网络(DQN)[8,9]。
1.3深度Q网络
首先,定义一个用于训练DQN的损失函数:
(6)
其中,要更新的目标是Q网络,θ是神经网络的权重。可以计算出损失函数对参数θ的梯度为:
(7)
Q(st,at)+α(Rt+1+λmaxaQ(st+1,a)-Q(st,at))→Q(st,at)
(8)
式中,α是学习率。
1.4经验回放
为了保证算法的稳定收敛,在训练过程中添加了经验回放技术。时刻t的经验表示为et=(st,at,rt,st+1)。将时刻t之前的所有经验都存储在Dt中,称为回放记忆,表示为Dt={e1,e2,…,et},这样有利于调用学习,大大提高学习效率。每次迭代对神经网络的参数θ进行更新时,就从Dt中随机抽取一小批经验,帮助神经网络的培训。抽取经验样品的随机性避免了相邻经验的过度耦合,使其不再受价值函数波动对环境的影响,同时,Dt也为式(6)中的2个Q-网络提供了不同时刻的输入状态和动作,为计算损失函数提供了回报r。
1.5初始动作的选择
在游戏中,初始动作也需要一个策略来生成,通常有2种做法:一是随机生成一个动作,二是根据当前的Q值得到一个最优的动作,表示为:
π(St+1)=arg maxaQ(St+1,a)
(9)
前者相当于探索未知,有利于Q值的更新,获得更好的策略,而后者利用之前的策略,相对前者对Q值的更新稍弱。笔者把探索与利用相结合,称为ε-贪婪法,ε是指探索的概率,这将鼓励Agent在开始不知道如何玩游戏时大量探索,此时状态空间是非常大的。接着它做大量的随机动作,并开始计算在不同的状态下哪些动作更好,从而利用更多,并试图缩小最佳的行动范围。通过更改ε的值可以调整探索与利用的比例。
综合以上步骤,得到训练游戏的带经验回放深度增强学习算法如下:
初始化经验回放D,容量为D
初始化动作估值函数Q,随机初始化参数
for episode =1,…,Mdo
初始化状态S0,并用特征提取器进行预处理φ1=φ(S0);
fort=1,…,Tdo
以ε的概率选择一个随机动作at
或是根据式(9)选择一个最佳动作
执行at,得到奖励rt;观察下一个输入图像,得到像素数据xt+1
到达下一个状态St+1,同样进行预处理φt+1=φ(St+1);
添加经验et=(φt,at,rt,φt+1)到D中
从D中随机抽样一批样品在10至100之间
通过反向传播和随机梯度更新DQN。
end for
end for
2 自动游戏方法及试验
下面,笔者将通过一个游戏来验证提出的深度增强学习算法的有效性。首先利用Python编写一个简单的游戏,如图1所示,游戏规则如下:在屏幕的左上角有一个小方块,底部放置了一个可移动的木板,小方块每移动一步,玩家控制木板左移一步或右移一步或保持不动,待小方块因碰撞屏幕四壁而改变飞行轨迹最终掉落下来时,观察木板是否能够接住小方块。若木板成功接住小方块,则能够获得分数奖励且小方块反弹上去;若木板未能接住小球,则不得分,且小方块与底部发生碰撞反弹上去。木板接住小方块的次数越多,则获得的分数越高。

图1 游戏在3种不同难度下(困难,中等,简单)的示意图
在利用笔者提出的深度增强学习算法训练时,DQN的结构如下:该网络采用84×84输入图像,第1层是一个卷积层,有32个步幅为4、8×8的滤波器,由整流非线性跟随;第2层也是卷积层,有48个步幅为2、4×4的滤波器,另一个整流线性单元的滤波器跟随;第3层是卷积层,具有64个步幅为2、3×3的滤波器,跟随有整流线性单元。接着是全连接层,具有3456个输出,最后输出层也是全连接,具有784个输出层,每个动作有一个输出,如图2所示。算法的相关参数设置如下:首先程序输入的是屏幕大小为[320,400],小方块的大小为[15,15]以及木板尺寸为[50,5],神经网络中学习率为0.99,存储过往经验的回放记忆Dt为500000,批量设定为100,训练次数为500000,测试为50000。假设要教会Agent玩这个游戏,输入以上数据后,对于木板将会输出3个动作:左、右以及原地不动接小方块。其次是当小方块每一个动作完成,会输出屏幕图像即每一个游戏画面,它隐含地包括了所有得分情况的相关信息。最后是小方块的速度和方向。以上3个方面的因素共同影响着动作的值,进而影响了下一个像素中木板的左右移动方向,用一个神经网络代表Q函数,以状态(游戏屏幕)作为输入和动作作为输出对应的Q值。
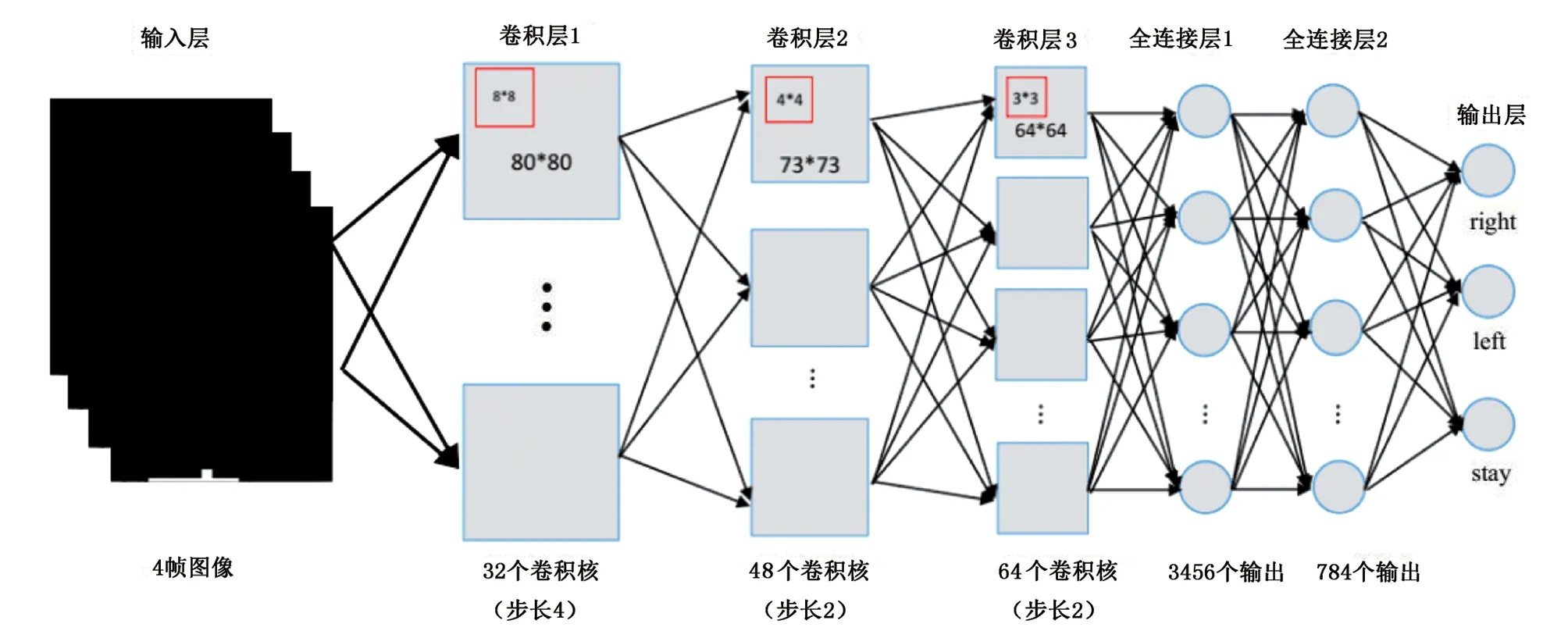
图2 DQN结构
在试验中,设置小方块的大小为15mm×15mm,木板的高度为5mm,长度分别为50、150、250mm,分别对应游戏难度为困难、中等、简单。由于迭代次数较大,用小方块的掉落次数表示(小方块每掉落在底端或木板上一次,迭代次数为上百次),以木板成功接住小方块的准确率为试验结果,如表1所示。
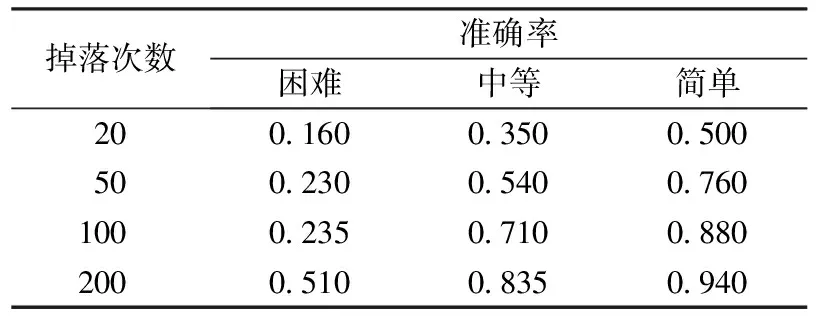
表1 不同环境下的准确率
表1给出了小方块的掉落次数与不同难易程度的关系,其中小方块掉落200次对应的木板移动步数大概为50000。由表1可以看出,在不同难易程度中,木板接住小方块的准确率会随着掉落次数增大,最终趋于平缓。并且,游戏由简单到困难,准确率上升的速率也不尽相同。在困难的环境下,准确率上升速率远远慢于在简单的环境下。
图3表示了在中等难度下木板接住小方块的准确率的曲线图,横坐标依然是小方块的掉落次数,纵坐标是准确率。首先,由于游戏刚刚开始,准确率会有很大的波动(如木板在第一次就接住小方块,此时准确率就是100%),在接近掉落次数单位为12的地方,除了小小的波动,准确率开始以较大的速率增长,慢慢地,在接近掉落次数单位为70的地方,准确率缓慢增长,大概保持在0.83。
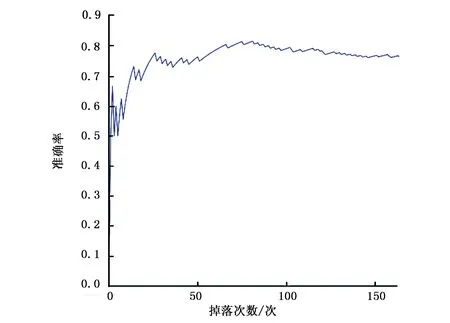
图3 中等难度下的准确率曲线图
3 结语
阐述了深度增强学习方法的基本思想,并将其简单应用在一种自动游戏上,得到了智能体经过训练的试验结果,结果表明深度增强学习在进一步的应用上有很大的潜力。在今后工作中,笔者也会尝试将其进行改进应用在其他游戏中,考查更多结果的影响。当然,自动游戏中的深度增强学习还有不少亟待解决的问题,如如何丢掉那些不利于获得奖励的经验,使其不被从回放记忆中取样,如何优先处理能导致更好性能的经验等,这些都有待进一步研究。
[1]孙志军, 薛磊, 许阳明,等. 深度学习研究综述[J]. 计算机应用研究, 2012, 29(8):2806~2810.
[2]高阳, 陈世福, 陆鑫. 强化学习研究综述[J]. Acta 自动化学报, 2004, 30(1):86~100.
[3] 陈学松, 杨宜民. 强化学习研究综述[J]. 计算机应用研究, 2010, 27(8):2834~2838,2844.
[4] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning.[J]. Nature, 2015, 518(7540):529~533.
[5] Sallab A E,Abdou M,Perot E,et al.Deep reinforcement learning frame work for antonomous driving[J].Electronic Imaging,2017(19):70~76.
[6] Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari deep reinforcement learning[J]. Computer Science, 2013,1312(5602):23~32.
[7] Sutton R S, Barto A G. Reinforcement learning I: Introduction[J]. Nature,1998,94720:143~148.
[8]陈先昌. 基于卷积神经网络的深度学习算法与应用研究[D]. 杭州:浙江工商大学, 2013.
[9]卢宏涛, 张秦川. 深度卷积神经网络在计算机视觉中的应用研究综述[J]. 数据采集与处理, 2016, 31(1):1~17.
[编辑]洪云飞
2017-06-28
国家自然科学基金项目(61503047);长江大学大学生创新创业训练计划项目(2016123)。
赵银明(1965-),男,副教授,现主要从事应用数学方面的教学与研究工作,452667017@qq.com。
引著格式袁月,冯涛,阮青青,等.基于深度增强学习的自动游戏方法[J].长江大学学报(自科版),2017,14(21):40~44.
TP391.4
A
1673-1409(2017)21-0040-05
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
江西教育B(2021年9期)2021-09-15
数学物理学报(2020年6期)2021-01-14
少年漫画(艺术创想)(2019年11期)2019-04-20
数学大王·中高年级(2019年2期)2019-01-23
少年文艺·我爱写作文(2018年12期)2018-12-21
作文大王·笑话大王(2017年4期)2017-05-05
中学生数理化·中考版(2017年12期)2017-04-18
科学启蒙(2017年3期)2017-04-10
