
双目标优化的RDF图分割算法
2017-11-28 09:50陈志奎冷泳林
中成药 2017年11期
陈志奎 ,冷泳林 ,2
1.大连理工大学 软件学院,辽宁 大连 116620 2.渤海大学 信息科学与技术学院,辽宁 锦州 121000
双目标优化的RDF图分割算法
陈志奎1,冷泳林1,2
1.大连理工大学 软件学院,辽宁 大连 116620 2.渤海大学 信息科学与技术学院,辽宁 锦州 121000
分布式存储是解决大规模数据存储的一种比较有效的方法,而数据分割是实现分布式存储的前提。面对不断增长的RDF数据,提出一种基于双目标优化的RDF图分割算法(RDF Graph Partitioning algorithm based on Double Objective Optimization,RGPDOO)。RGPDOO将边割和分割平衡两项图分割指标融合到一个目标函数,并依据此目标函数,实现了RDF图的静态和动态分割。其中静态图分割通过对图进行初始划分,将图中顶点分成内核顶点、交叉顶点和自由顶点三类。然后通过计算目标函数增益对交叉和自由顶点进行分配。动态图分割部分,针对RDF元组的插入和删除给出相应的解决方案。同时,为了满足图分割目标,算法每隔一段时间T会根据子图的平衡性和紧密性进行一次动态调整。实验选择合成和真实数据集进行测试,并分别与几种通用的静态和动态图分割算法进行比较。实验结果表明提出的算法能够有效地实现RDF图的静态和动态分割。
RDF图;静态分割;动态分割;边割;负载均衡
1 引言
万维网联盟(W3C)推荐的资源描述框架(Resource Description Framework,RDF)是描述语义网中各种资源与它们之间语义关系的一个重要框架标准[1]。RDF使用三元组〈主语,谓语,宾语>来描述世界,当把主语和宾语看做图中两个顶点,谓语看做是由主语指向谓语的有向边时,RDF数据集可以被看做是一个有向图。随着Link Open Data(LOD)[2]和DBpedia等项目的全面展开,语义Web的数据量不断增加,大量RDF数据被发布。
面对大规模RDF数据,传统单机模式已经不能满足数据存储需求。数据分布式存储是目前公认地解决大规模数据存储比较有效的方法。而实现分布式存储的前提就是如何有效对数据进行分割。尤其是RDF图本质特征,使数据之间存在大量关联。如果分割不当,就会导致查询时,存储节点之间产生大量通信。另外,分割平衡性也将影响数据并行执行的效率。并且,RDF数据是不断更新变化的,要保持良好的分割状态,对应的数据分割算法就应该具有适应数据变化的能力。
基于以上分析,本文提出一种双目标优化的RDF图分割算法(RDF Graph Partitioning algorithm based on Double Objective Optimization,RGPDOO)。算法以最小化边割和分割平衡作为RDF图分割目标设计了一个双目标优化函数。并基于此目标函数实现了RDF数据的静态和动态图分割算法。实验中,本文选择RDF标准数据集从边割、分割效率和分割平衡三方面验证算法的有效性。实验结果表明,本文提出的双目标函数从边割和平衡两方面保证RDF图数据分割的质量,有效地实现RDF图的静态和动态分割。
文中其他部分内容概括如下:第2章介绍RDF图分割相关工作;第3章详细阐述双目标函数的设计;第4章描述了双目标函数下RDF图的静态和动态分割算法;最后通过实验验证RGPDOO算法的性能并得出结论。
2 相关工作
近年来,随着RDF数据的广泛应用,关于RDF图分割算法的研究也越来越多。SPA[3]采用顶点中心块儿的分割机制对RDF图进行分割。VB-Partitioner[4]扩展了SPA思想,在其基础上对顶点中心块儿进行n跳扩展,来避免查询时节点间的通信。BRGP专门针对RDF图中顶点的不对称关系以及图的幂率特性提出基于模块度的标签传播算法对图进行粗化分割。Wu[5]等人提出了一种基于路径的图分割算法,算法将RDF图分解成由源点到汇点所组成的路径,然后再以路径为单位进行分割。Huang等人将METIS图分割框架直接应用于RDF数据分割,通过副本方式降低SPARQL查询中各分区之间的通信[6]。Wang等人利用标签传播算法对RDF图顶点进行粗化,并结合METIS对粗化图进行分割[7]。以上这些算法都是基于静态RDF图进行分割,并没有给出图动态变化时的解决方案。
朱牧等人提出基于密度的增量聚类算法可以实现图的增量分割,但该算法主要倾向于社交网络中重叠社区发现问题,并没有考虑图分割的边割和平衡两项分割指标[8]。Fennel是一种基于流的图分割框架,该框架在目标函数地限制下结合一定的启发式算法来实现图分割[9]。张晓媛[10]等人提出的基于邻域动态图分割算法NDA在静态图分割的基础上,按照不同的图数据增长方式,根据存储节点最小负载原则或KNN原则进行节点的迁移或添加。该算法在动态图分配阶段只考虑负载均衡来转移不平衡节点,并没有考虑边割问题。Martella[11]等人提出的Spinner是一种基于标签传播的增量图分割算法,Spinner在Pregel分布式图计算平台基础上将标签传播算法扩展成为一种分布式的图分割算法,保证分割算法的可扩展性。Spinner能够根据图和计算环境的变化自动调整图分割结果,避免图的重新分割。在处理增量节点时,Spinner通过重启迭代的方式,让全局顶点都参与到最优计算中,虽然获得了一个很好的分割结果,但这种方式非常耗时。SPAR[12]以最小化副本为分割目标将社交网络中每个用户所有相关信息划分到一个存储节点来保证分割局部语义完整性。并且针对节点、边和存储节点的添加删除给出了图的自适应分割策略。Sedge[13]提出了补充和按需两种分割技术,并依据这两种技术,创建了一个具有两层分割结构的图分割架构:主要分割和辅助分割,来处理变化的图查询。Xu等人提出的LogGP[14]将图和历史分割结构结合到一起,构成一个超图,并且利用基于超图的流分割方法得到初始分割。在分割过程中,还会依据运行时的统计信息评估每个节点的运行时间,对后继执行做出动态调整。以上这些算法在图的动态分割方面做出了贡献,但这些算法并没有针对RDF图特征及其分割目标给出合适的解决方案。
3 双目标优化函数的设定
给定一个RDF图G=(V,E),其中V表示图中顶点集合,E表示图中的边集,|V|=n和|E|=m分别表示图中顶点和边的数目。一个k路图分割就是将RDF图分成 k个不相连接的子图 P={G1,G2,…,Gk},其中Gi={Vi,Ei},i=1,2,…,k是一个分割子图。当 i≠j时,Vi∩Vj=φ并且
边割和平衡性是衡量图分割质量的两项重要指标,其中边割是指连接两个不同子图之间边。子图之间边割越小,表示它们之间的联系越稀疏,数据并行执行时彼此之间需要交换的信息越少,数据并行性越高。本文用inter(Gi,Gj)表示子图Gi和Gj之间的边割,则:

当来自两个不同子图的顶点a和b之间存在连接,则e(a,b)为1,否则为0。同边割相对应,用intra(Gi)表示任意一个子图内部边的数目,本文定义为内割,则:

显然,一个子图的内割越高,子图内部节点之间关系越紧密,即子图独立性越强。
图分割的平衡性是指各分割子图中顶点的数目趋于相等。在分布式系统中各存储节点硬件环境相同情况下,各子图顶点规模越趋于相等,系统并行执行的效率越高。当任意一个分割子图Gi中顶点数目满足公式(3)时,图分割P趋于平衡。其中e是一个介于0和1之间的浮动因子,即允许图规模在一定范围内浮动。
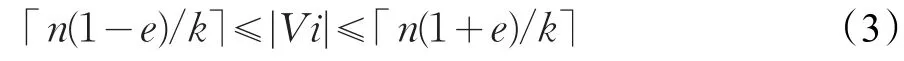
由以上分析,图分割不仅要最小化边割,而且还要保证分割子图的平衡性。为此,本文提出一个基于边割和平衡的双目标函数 f(P),f(P)满足:

其中cut(P)代表图分割的边割,对于一个k路图分割P,cut(P)满足:
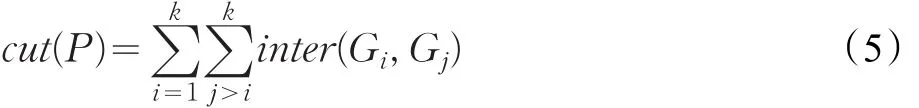

其中:

balance(P)代表图分割的平衡性,balance(P)满足:
综上,当双目标函数 f(P)取最小值时,图分割结果最优。但图分割是一个NP-完全问题,要得到精确分割结果是很困难的。因此目标是寻找一个近似最优解。为实现这一目标,对 f(P)做如下处理。
给定一个函数g(P),如公式(8)所示:
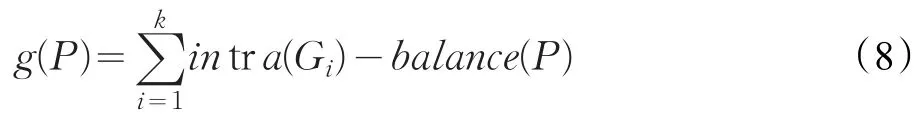
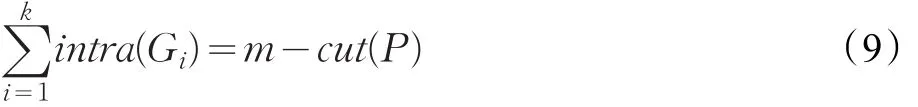
由公式(4)、(8)和(9)可得:

当求 f(P)的最小值时,对应就是求g(P)的最大值。因此,在确定一个顶点v所属分区时,可以通过计算∆g(P,i,v)的最大增益值来确定。
如图1,设n/k=4,两个分割子图G1和G2的 g(p)当前值为7。当新节点i分别加入到子图G1和G2时,g(p)的值为7和8,则产生的增益值分别为∆g(P ,G1,i)=1和∆g(P ,G2,i)=0,因此选择G2分区。从图1中也可以直观看出,加入G2所产生的边割要小于G1,而平衡性的变化是一致的。

图1 计算最大增益值
4 基于双目标函数的RDF图分割算法
基于以上目标函数,本章给出两种不同状态RDF图分割算法。第一种是针对已经存在的静态RDF图,另一种是针对变化的RDF图给出的动态分割方案。
4.1 静态图分割
本文基于双目标函数,改进了k路贪婪图分割算法(Improved k-way Greedy Graph Growing Partitioning,IKGGGP)[15],实现了对静态RDF图的分割。不同于KGGGP算法,IKGGGP算法首先对RDF图进行初始划分,将图中顶点划分成只属于一个分区的内核顶点;存在于多个分区的交叉顶点和不属于任何分区的自由顶点。对于内核顶点,它们只属于一个唯一分区,无需再进行分配。而交叉顶点和自由顶点,IKGGGP通过计算目标函数的最大增益值为它们选择合适分区。
4.1.1 初始划分
SPARQL查询本质是子图匹配问题,如果将紧密联系的节点分配到同一分区,将极大地降低查询时存储节点之间的通信。当图中顶点同其邻域具有很大相似性时,这个顶点更容易成为图中的一个核心顶点。本文就从图中的k个核心顶点开始向外扩展,对RDF图进行初始划分。经过初始划分的图中存在一类特殊顶点,它们是只与分区内的顶点有关联的内核顶点。如图2所示的红色顶点即是内核顶点。内核顶点只属于一个分区,因此一旦初始区域划分结束,这些顶点的分区也就固定,不需要在进行分区选择。
给定一个RDF图,Γ(v)是顶点v的邻域集合。Γε(v)表示顶点v的邻域中与v的相似度大于或等于阈值ε的顶点集合。如果|Gε(v)|的邻域数目超过阈值δ,称顶点v是图中的一个核心顶点。
在寻找RDF图中核心顶点时需要计算顶点v与其邻域顶点的相似性。传统地计算图节点相似性的方法都是基于顶点的结构信息,如随机游走[16]、计算公共邻域[17]等方法。本文由于RDF图是一个语义图,节点间存在一定的语义关系。如果将语义上联系紧密的顶点划分到一个分区,将更有利于查询的并行执行。因此本文提出了一种基于语义的顶点相似性度量方法。
RDF采用统一资源标识符(Uniform Resource Identifier,URI)来标识图中的顶点和边。URI通过目录结构体现图中顶点所属类、超类及节点信息。如果图中两个顶点所属公共超类越多,说明它们的相似性就越大,即这两个顶点联系越紧密。用函数sup(v)来计算顶点v所属超类,则衡量两个顶点u和v的语义相似性,如公式(11)所示:

当某一个顶点只有一个入边,则它与指向它的顶点的相似性为1。当确定图中核心点后,就可以对图进行初始划分了。算法1给出了初始划分的伪代码。
算法1初始划分
输入 核心顶点集core,图G
输出 初始划分P={G1,G2,…,Gk}
方法:
Initialqueue(q);p<—1;//初始化队列q和分区编号
Do while p<=k
v〈—select(core);//从核心顶点集随机选择一个顶点
remove(core,v);//从核心顶点集移除v
inqueue(q,v);//顶点v入队列
i<—1;
partition(v)<—p;//为顶点分配分区编号和分区内序号
number(v)<—i;
i<—i+1;Gp=Gp⋃v;
Do while not isempty(q)andi<n/k
v<—outqueue(q);
for each u in Γε(v)do
ifu∈core
remove(core,u);
ifu∉Gp
inqueue(q,u);
partition(u)<—p;
number(u)<—i;
ifi=n/k
exit for
i<—i+1;Gp=Gp⋃u;
end for
end do
p=p+1;
clearqueue(q);//清空队列
end do
4.1.2 交叉顶点和自由顶点分配
当RDF图经过初始分割后,内核顶点的分区已经确定。除了内核顶点,初始分割结果中还存在两类顶点,如图2中紫色的交叉顶点和蓝色的自由顶点(统称为待分配节点),需要计算它们所属分区。本文通过计算函数g(P)的最大增益值,来确定这两类顶点的分区,即:

图2 RDF图分区的核心顶点

IKGGGP算法中待分配顶点分配执行步骤如下:
步骤1计算所有待分配顶点分配到各个分区所产生的增益值Δg。
步骤2选择产生最大增益的顶点v和其对应的分区i,将其分配到分区i,从待分配顶点集合移除v。
步骤3如果待分配顶点集合不为空,更新其他待分配顶点的增益值Δg,返回步骤1,否则,执行步骤4。
步骤4输出分区结果。
为提高算法效率,本文对以上执行步骤做了如下两方面处理:
(1)设计一个二维数组存储待分配顶点分配到不同分区产生的增益值∆g,其中二维数组中的每一行对应一个待分配顶点,每一列对应一个分区。当将一个顶点v分配到分区i后,其他待分配顶点在各个分区增益变化遵循公式(13):
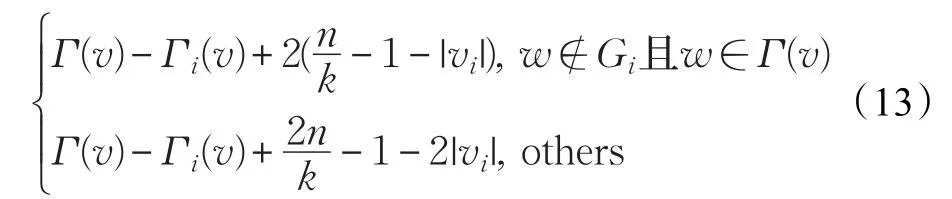
(2)为方便寻找能够产生最大增益的顶点,IKGGGP算法采用邻接表的方式记录每个节点最大增益值产生时所对应的相关信息。其中一维数组的每个元素对应最大增益范围内的一个值,并且这些值按降序排列。同时,每个元素指向一个双向链表,用于存储产生相同最大增益值的顶点信息。本文将最大增益顶点按降序排列可以方便选择产生最大增益的顶点,采用双向链表是为了方便删除处理过的顶点。
4.2 动态图分割
实际应用中,RDF数据是在不断变化的。对应的图分割算法也应该针对这些变化给出合理的解决方案,以保证数据分割一直满足边割和平衡性的要求。本文针对RDF图动态变化(元组的插入和删除两方面,更新操作可以用删除和插入实现)设计了RDF图的动态分割及调整策略(Dynamic Partitioning and Adjustment Strategy of RDF,DPAS)。
4.2.1 插入元组insert(s,p,o)
新增元组插入到原RDF图中分三种情况:(1)新增元组的主语和宾语在原始图中存在;(2)新增元组的主语或宾语只存在一个;(3)新增元组对应的主语和宾语都不存在。
(1)s和o都存在
当s,o在分割图中已经存在时,插入元组就是在图中增加一条边。如果s,o∈Vi,则增加元组不改变目标函数,因此直接插入该元组即可。如果 s∈Vi,o∈Vj,且i≠j,需要判断以下情况,选择增益值最大的一种情况添加。
①不移动顶点,直接在s和o之间添加一条边,∆g增益值为-1。
②将顶点s或o迁移到对方所在分区(顶点迁移的前提是满足负载均衡条件)时,∆g的增益值变化如公式(14):

(2)s或o中有一个是新顶点
设已经存在的顶点为s,s∈Vi,待加入新节点为o,则顶点o有两种分区选择。一种是将o加入到分区i,另一种将o加入到其他某一分区。产生的增益值如公式(15)。同样,在保持负载均衡的前提下选择具有最大增益值的分区。

(3)s和o都是新顶点
如果一个元组的主语和宾语都不存在,说明这两个顶点和图中任意一个顶点都没有关联,分配策略是将这两点分配到具有最少顶点的分区。
4.2.2 删除元组delete(s,p,o)
删除元组就是删除由顶点s指向o的一条有向边,如果 |Γ(s)|>1且 |Γ(o)|>1,并且 s和 o分别属于不同的分区,则删除边e可以降低整体边割又不影响分割平衡性,因此直接删除边e即可。
当|Γ(s)|=1并且|Γ(o)|=1,或者满足 s和o的一个顶点邻域为1时,需要将邻域为1的顶点连同边一起删除。边割的降低会提高图的分割质量,但顶点的删除有可能导致分割的负载失衡。又由于插入元组只是局部调整节点的分配,因此经过一个时间间隔T,图分割有可能出现局部最优的情况。为避免上述情况的发生,每经过时间T,将对图进行一次动态调整。
(1)平衡性调整
由于元组的删除,会导致分割子图不均衡。如果存在子图Gi不满足负载均衡的要求,需要对其进行调整。当|Vi|<「n(1-e)/k⏋时,用 Γ(Vi)表示子图 Gi的邻域顶点集合。∀v∈Γ(Vi),P(v)=j,当将顶点v从分区j移至分区i时,目标函数的增益值为:

从Γ(Vi)中选择能够产生最大增益值的顶点v,将其移到分区Gi中,直到|Vi|满足公式(3)。
相反,当子图Gi中的顶点 |Vi|>「n(1+e)/k⏋时,用η(Vi)表示子图Gi中与其他子图有关联的顶点集合。∀v∈η(Vi),∃u∈Γ(v),P(u)=j,j≠i,当将 v从分区 i移至分区 j时,目标函数的增益值为:
同样从η(Vi)中选择能够产生最大增益值∆g的顶点v,将其加入到分区Gj中,直到|Vi|满足公式(3)。
(2)子图紧密性
当图分割满足负载均衡条件时,分割子图内部顶点应具有紧密的联系,而子图之间顶点联系应该比较稀疏。本文用子图的内聚度和耦合度来衡量分割子图的紧密性。公式(18)和(19)分别给出计算分割子图内聚度和耦合度的方法。

对于任意分割子图,如果它的内聚度大于它与其他子图之间的耦合度,则说明子图内部顶点联系比较紧密。当存在子图的内聚度低于它与其他子图的耦合度时,说明该子图内部存在一些顶点,这些顶点与其他子图联系更加紧密。
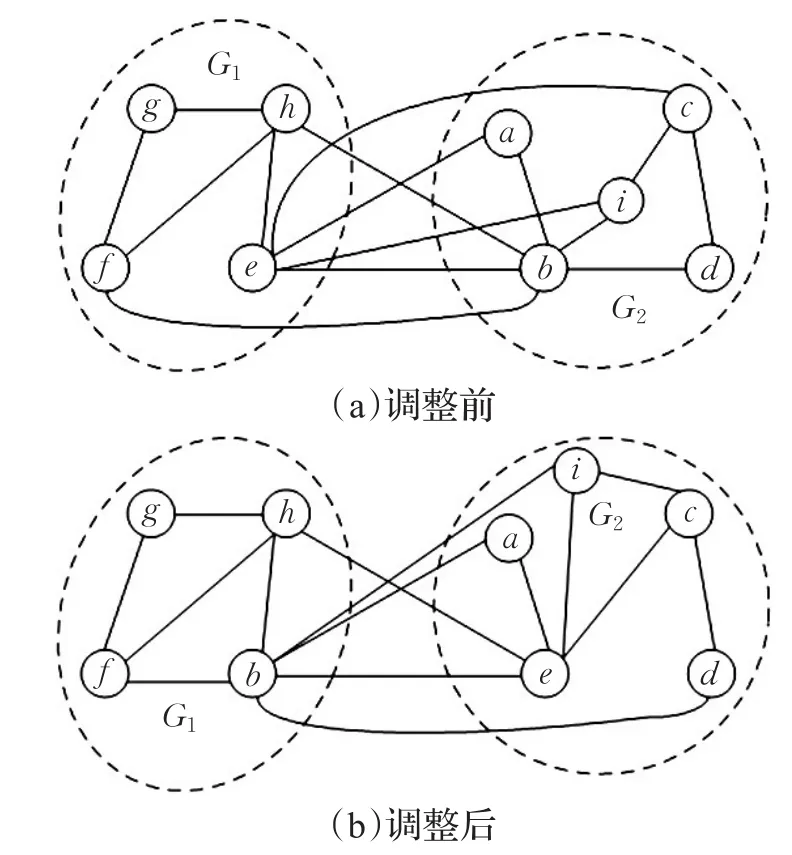
图3 平衡性调整整
图3 (b)是交换(a)中两个分割子图G1和G2中顶点b和e的结果。对于分割子图G1,其在交换节点前的内聚度和耦合度分别是4/10和6/10。当交换顶点后,两个值分别为5/10和5/10。同理,子图G2也由5/11和6/11变成5/10和5/10。由此可见,G1和G2的内聚度都提升了,而耦合度下降了,最直观的体现即两个子图之间的边割降低了。
用η(Vi)表示子图Gi中与其他子图相关联的顶点集合。 ∀v∈η(Vi),u∈Γj(v ),j=1,2,…,k且 j≠i,如果 Γ(u)<Γ(v ),并且u、v在子图Gi和Gj的邻域满足公式(20),就将顶点u和v进行交换。

调整子图内聚度步骤如下:
步骤1根据公式(18)和(19)计算分割子图内聚度及子图间耦合度。
步骤2如果存在子图cohesion(Gi)<connection(Gi,Gj),j=1,2,…,k且 j≠i,执行步骤3;否则,跳转到步骤5。
步骤3如果存在v∈η(Vi),u∈Γj()v 并且 Γ(u)<Γ()
v ,同时满足公式(20),则交换顶点u和v;否则转到步骤5。
步骤4更新子图内聚度及子图之间耦合度,跳转到步骤2。
步骤5输出调整后的分割结果。
5 实验
本文实验选取合成数据集(LUBM)和真实数据集(Uniprot)验证RGPDOO算法在分割静态和动态RDF图时的性能。
5.1 数据集及实验环境
LUBM是一种标准化的评价语义网算法的合成数据集。利用其提供的数据生成器可以生成不同规模大小的RDF数据集。Uniprot是一个可免费访问的关于蛋白质序列和功能信息的真实数据集。表1列出了这两个数据集的一些基本信息。

表1 实验数据表
本文的实验运行硬件环境为:Inter Xeon 2.00 GHz×24处理器,20 GB内存;软件环境为:Linux操作系统,C++编程语言。
5.2 实验结果及分析
5.2.1 静态分割IKGGGP性能验证
本文选择LUBM50和Uniprot子集(一亿条元组)对静态图分割算法IKGGGP进行了验证。实验中选择METIS,MLP+METIS和BRGP作为对比算法,参数ε=0.3,δ=2m/n。每个分割算法执行三次,取结果的平均值,平衡性取最大子图与分割子图的均值比,四种算法均将数据集分割成4、8和16三种不同大小的分区。图4给出了四种算法在分割时间、边割量和平衡性三方面的对比结果。如图4所示,IKGGGP算法分割时间优于METIS,低于MLP+METIS和BRGP。IKGGGP、MLP+METIS和BRGP的执行效率与图中顶点度数的分布没有直接关系,因此不受图中高度顶点的影响。而METIS算法的顶点粗化速度直接受顶点度数的影响[18]。对于本文的两个数据集,数据集中存在一些高度顶点,这些顶点的度数是普通顶点的几十甚至几百倍,因此造成METIS算法分割效率低于其他三种算法。其中MLP+METIS和BRGP算法中依靠标签传播算法(LPA)来实现顶点的逐层粗化,每层LPA的时间复杂度为O(tm),其中t为LPA算法迭代次数,m对应的是每一层图中的边数。IKGGGP算法需要先计算顶点与其邻域之间的相似性找出核心点,然后再进行节点分配,时间复杂度为O(m+n)。但IKGGGP算法之所以在效率上仍高于MLP+METIS和BRGP,原因在于IKGGGP算法在对待分配顶点进行分配时,需要不断更新待分配顶点的最大增益值。另外,IKGGGP算法的分割效率与待分配顶点的数目有关,图5列出了初始分割时所产生的三类顶点占顶点总数的比例。从图5可以看出,内核顶点随着分区数目的增加在逐渐降低,但总量仍然超过30%,因此在对顶点进行分配时,至少有30%的顶点不参与再分配,这也是IKGGGP算法时间效率高于METIS的一个原因。
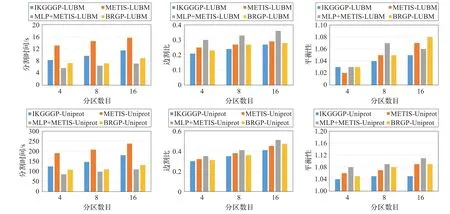
图4 IKGGGP初始分割算法性能验证
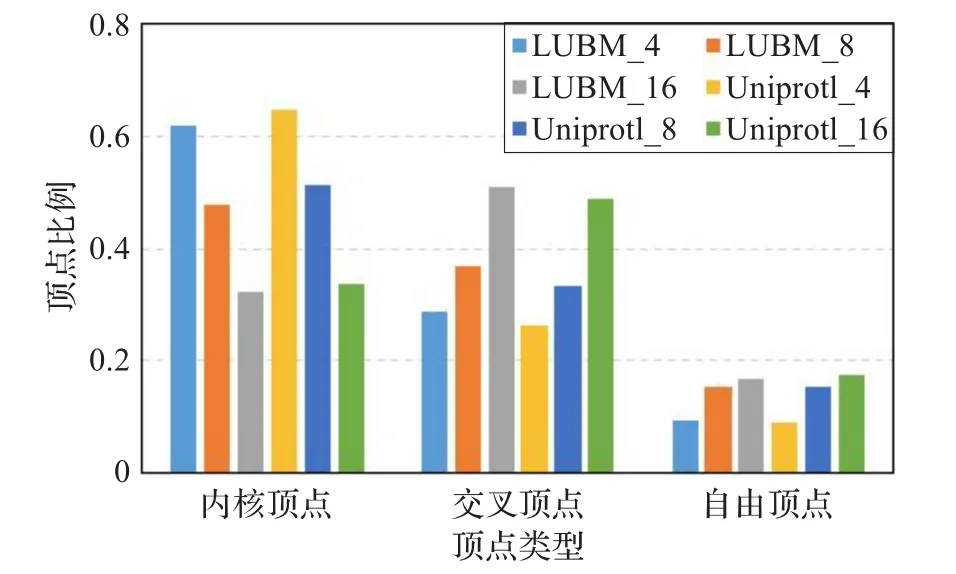
图5 初始分割三类顶点统计
在边割和负载均衡的结果中IKGGGP算法要优于其他三种算法,其原因在于IKGGGP算法中引入的增益函数是直接选择边割和负载均衡最优的情况进行顶点分配,而标签传播则是间接地实现边割和负载均衡的最优,因此IKGGGP算法的边割和负载均衡在几种算法中占有一定优势。
5.2.2 动态图分割DPAS性能验证
本部分验证RGPDOO算法动态分割及调整策略DPAS。DPAS是在已有分割图的基础上,根据RDF图的动态变化执行的。因此,以IKGGGP图分割结果为基础,通过不断向图中插入元组,验证DPAS的性能。本部分选择Spinner和Fennel两种动态图分割算法作为比较算法。实验中DPAS、Spinner将LUBM50和Uniprot1作为初始静态数据,其他数据都以动态插入方式产生。Fennel以流方式直接增加数据,最终插入的数据量使LUBM数据集达到LUBM2000,Uniprot数据集达到Uniprot2,DPAS的动态调整时间间隔设为T=5 s。图6显示了三种算法在分割时间,边割和平衡性三方面的实验结果。其中,Fennel在两种数据集上的分割效率都是最高的,其原因在于Fennel算法采用流式分割,时间效率是线性的。而Spinner的分割效率要低于Fennel和DPAS,主要是由于Spinner在数据变化后,每次都重启迭代,重新寻找最优分割,因此效率会随着节点数目的增加逐渐降低。RGPDOO算法在静态图数据分割中采用的IKGGGP算法效率不高,但动态图分割部分由于DPAS采用线性的节点分配方案,顶点的调整也是基于局部子图,因此其效率介于Spinner和Fennel之间。

图6 IRGPA算法性能验证
在边割和平衡性的实验结果中,DPAS的分割效果明显好于其他两种算法。虽然Fennel算法也是基于边割和平衡目标函数进行分割的,但DPAS在算法中增加了动态调整功能,使整体分割不至于陷入局部最优。而Spinner基于标签的平衡性是以边为基准的,本文比较以节点为主,因此Spinner平衡性要低于DPAS与Fennel。

图7 动态调整对图平衡性影响
上述实验DPAS在运行期间都是执行元组插入操作,为验证元组删除及动态调整有效性,本文每隔时间T,采用随机的方式从分割图中删除若干元组。图7给出了执行动态调整前后图分割平衡性变化情况。从图中可以看出,调整前由于元组的删除,图顶点的数目下降,导致最大子图失衡程度上升。当DPAS增加了动态调整功能后,图分割的平衡性会比调整前有所降低,使整体图分割的平衡性始终维持在一个变化范围内。
5.2.3 RGPDOO在增量图分割中性能验证
5.2.1 小节实验表明IKGGGP算法在初始图分割时的效率要低于MLP+METIS和BRGP算法。但其边割和负载均衡性都要优于其他三种算法。然而随着数据量的不断增加,将IKGGGP初始分割结果作为后续图分割的基础,增加的数据采用DPAS进行动态分割,MLP+METIS、METIS和BRGP面对增量数据采用重新分割的方式进行比较,分割效率有了明显的变化。图8分别显示了LUBM和Uniprot两个数据集在几种不同分割算法上将数据集分割成8个分区时的时间性能。其中RGPDOO选择LUBM50数据集和Uniprot1的一亿条数据作为初始静态分割的数据集。METIS、MLP+METIS和BRGP算法对应不同规模大小数据集的分割时间都是直接将算法作用于相应数据集所得到的分割时间。由图中曲线可以看出,随着数据集规模的增加,RGPDOO算法分割时间增加缓慢,而METIS、MLP+METIS和BRGP算法的分割时间明显高于RGPDOO。并且数据集越大,越显示出RGPDOO算法的优势。其原因在于IRGPA的增量图分割算法部分在计算节点分配时,只考虑很少一部分与待分配相关联的节点,因此分割速度很快,而其他的三种算法当数据规模变化时,需要通过更多的迭代得到最终结果,增加了算法的运行时间,由此也说明RGPDOO在增量数据分割时的有效性。
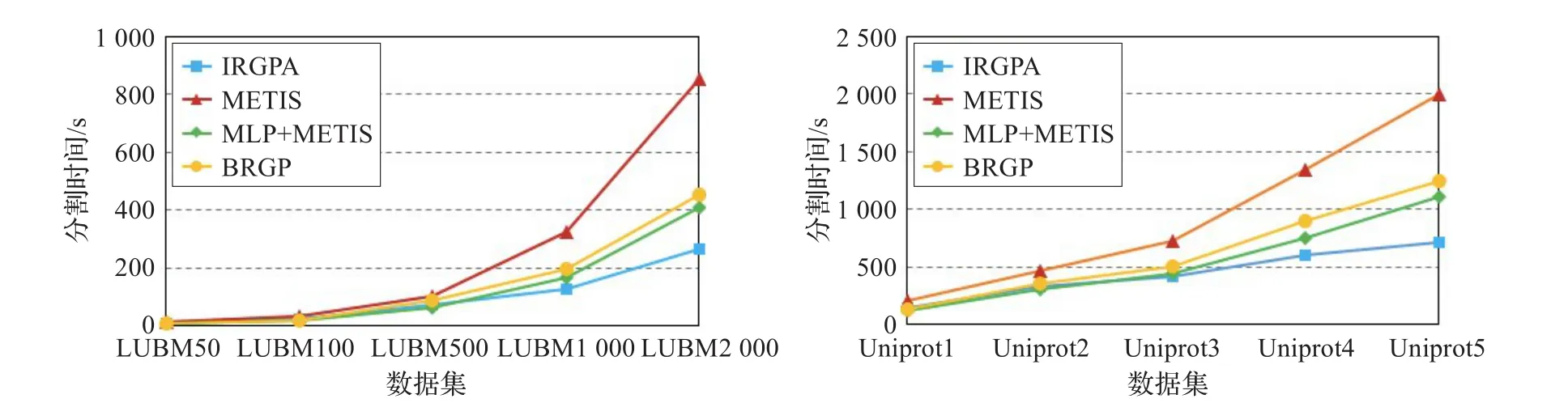
图8 IRGPA增量分割效率
6 结束语
本文从RDF图分割的两个基本目标:边割和平衡性出发,提出一种基于双目标优化的RDF图分割算法(RGPDOO)。RGPDOO将边割和分割平衡两项图分割指标融合到一个目标函数,并依据此目标函数,实现了RDF图的静态和动态分割。其中静态图分割改进了KGGGP算法,不仅通过节点初始分区降低了候选节点集规模,而且通过选择双目标函数增益值实现了候选节点的分配。对于动态分割部分,本文依据目标函数给出了元组插入和删除时节点的分配策略(DPAS)。同时,为了避免局部最优或分割失衡,DPAS每隔时间T,都会依据分割平衡性和子图内聚度对子图进行动态调整,以保证图分割始终满足最小化边割和分割平衡两项目标。实验选择了两种常用的数据集进行测试,分别从分割效率、边割和平衡性三方面验证了静态和动态图分割算法的性能。结果表明RGPDOO能够实现RDF图的有效分割。但同其他分割算法相比,RGPDOO的分割效率略低于其中一些算法,这也是今后研究的方向。
[1]RDF[EB/OL].http://www.w3.org/TR/rdf-concepts/.
[2]Yu L.Linked open data.A developer’s guide to the semantic web[M].Berlin Heidelberg:Springer,2011:409-466.
[3]Lee K,Liu L,Tang Y,et al.Efficient and customizable data partitioning framework for distributed big RDF data processing in thecloud[C]//IEEE Sixth International Conference on Cloud Computing,2013:327-334.
[4]Lee K.Efficient data partitioning model for heterogeneous graphs in the cloud[C]//High Performance Computing,Networking,Storage and Analysis,2013:1-12.
[5]Wu B,Zhou Y,Yuan P,et al.Scalable SPARQL querying using path partitioning[C]//International Conference on Data Engineering.IEEE,2015:795-806.
[6]Huang J,Abadi D J,Ren K.Scalable sparql querying of large rdf graphs[J].Proceedings of the VLDB Endowment,2011,4(11):1123-1134.
[7]Wang L,Xiao Y,Shao B,et al.How to partition a billionnode graph[C]//2014 IEEE 30th International Conference on Data Engineering(ICDE),2014:568-579.
[8]朱牧,孟凡荣,周勇.基于链接密度聚类的重叠社区发现算法[J].计算机研究与发展,2013,50(12):2520-2530.
[9]Tsourakakis C,Gkantsidis C,Radunovic B,et al.FENNEL:streaming graph partitioning for massive scale graphs[C]//ACM International Conference on Web Search and Data Mining,2014:333-342.
[10]张晓媛,张珩,翟健.基于邻域的大规模图数据动态分割算法[J].计算机系统应用,2016,25(9):193-199.
[11]Martella C,Logothetis D,Loukas A,et al.Spinner:scalable graph partitioning in the cloud[J].Computer Science,2015.
[12]Pujol J M,Erramilli V,Siganos G,et al.The little engine(s) that could:scaling online social networks[J].IEEE/ACM Transactions on Networking,2012,20(4):1162-1175.
[13]Yang S,Yan X,Zong B,et al.Towards effective partition management for large graphs[C]//Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data,2012:517-528.
[14]Xu N,Chen L,Cui B.LogGP:a log-based dynamic graph partitioning method[J].Proceedings of the VLDB Endowment,2014,7(14):1917-1928.
[15]Predari M,Esnard A.A k-way greedy graph partitioning with initial fixed vertices for parallel applications[C]//Euromicro International Conference on Parallel,Distributed,and Network-Based Processing,2016:280-287.
[16]Zhou Y,Cheng H,Yu J X.Graph clustering based on structural/attribute similarities[J].Proceedings of the VLDB Endowment,2009,2(1):718-729.
[17]Khosravi-Farsani H,Nematbakhsh M,Lausen G.SRank:Shortest paths as distance between nodes of a graph with application to RDF clustering[J].Journal of Information Science,2013,39(2):198-210.
[18]Yao L,Wang Z,Li Z,et al.A novel coarsening scheme for multilevel graph partitioning[C]//International Conference on Biomedical Engineering and Informatics,2011:2091-2094.
CHEN Zhikui1,LENG Yonglin1,2
1.School of Software Technology,Dalian University of Technology,Dalian,Liaoning 116620,China 2.College of Information Science and Technology,Bohai University,Jinzhou,Liaoning 121000,China
RDF graph partitioning algorithm based on double objective optimization.Computer Engineering and Applications,2017,53(21):24-31.
Distributed storage is a more effective method for the mass data storage.And,the data partitioning is the premise of distributed storage.In facing of the growing semantic web data,RDF Graph Partitioning algorithm is proposed by Double Objective Optimization(RGPDOO).RGPDOO fuses edge cut and load balancing together to get an objective function.According to this objective function,RGPDOO achieves static and dynamic partitioning of RDF graph.For the static partitioning,an initial partitionis executed to divide the node into three kinds:kernel nodes,boundary nodes and freedom nodes.And then,the boundary and freedom nodes are distributed to apartition with the max gain of objective function.For the dynamic partitioning,the insertion and deletion solution of triples are given by the objective function.And,RGPDOO will execute a dynamic adjustment at a certain time interval according to the balance and tightness of partitioning subgraph to satisfy the partitioning object.Finally,the algorithm is tested on synthetic and real datasets in comparison with several general graph partitioning algorithms.The experimental results show that RGPDOO is more suitable for RDF graph partitioning.
RDF graph;static partitioning;dynamic partitioning;edge cut;load balancing
A
TP311
10.3778/j.issn.1002-8331.1706-0426
国家自然科学基金(No.U1301253,No.61672123);广东省科技计划(No.2015B010110006);国家重点研发计划(No.2016YFD0800300);辽宁省博士科研启动基金项目(No.201601348,No.201601349)。
陈志奎(1968—),男,博士,教授,研究领域为物联网理论与应用、云计算与大数据处理,E-mail:zkchen@dlut.edu.cn;冷泳林(1978—),女,博士研究生,副教授,研究领域为数据存储与索引,不完整数据填充。
2017-06-30
2017-09-25
1002-8331(2017)21-0024-08
猜你喜欢
黑龙江科学(2021年14期)2021-08-06
电脑报(2021年14期)2021-06-28
计算机与生活(2020年8期)2020-08-12
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
计算机与数字工程(2019年3期)2019-03-26
计算机应用(2018年7期)2018-08-27
科技与创新(2017年5期)2017-03-28
经济研究导刊(2017年1期)2017-03-16
科技视界(2016年1期)2016-03-30
