
面向大规模计算集群的多轨分割网络
2017-12-08 05:30元国军郇志轩孙凝晖
计算机研究与发展 2017年11期
邵 恩 元国军 郇志轩 曹 政 孙凝晖
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190) 2(中国科学院大学 北京 100049)
(shaoen@ncic.ac.cn)
面向大规模计算集群的多轨分割网络
邵 恩1,2元国军1,2郇志轩1,2曹 政1孙凝晖1
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)2(中国科学院大学 北京 100049)
(shaoen@ncic.ac.cn)
在千万亿次规模的系统中,互连网络设计面临新的挑战.高性能节点和大规模是构建千万亿次系统的主要技术趋势,不断提高的节点计算能力要求互连网络提供更高的性能,而不断增大的规模又对互连网络扩展性提出了更高的要求.此外,随着系统规模的增大,集合通信的执行时间也在不断增长,制约了应用的扩展性,集合通信的性能需要得到进一步优化.除性能之外,可靠性问题也随着系统规模的扩大而日益严重.而随着计算节点性能的不断提高,互连网络逐渐成为限制大规模计算机系统性能的瓶颈.互连网络核心部件交换芯片可提供的聚合网络带宽受到工艺和封装技术的限制.从网络结构与交换机结构的协同设计思想出发,提出了一种在交换机聚合带宽限定的条件下多轨分割网络结构和设计方法.通过数学建模和网络模拟仿真,分析了该多轨分割网络的性能边界.评测结果表明:该网络可将短消息(长度小于128 B)的平均延迟性能提高10倍以上,为以短消息占多数的数据中心网络的性能优化提供了新思路.
大规模计算集群;多轨网络;带宽分割;数据中心网络;大规模网络模拟
随着集群计算机计算节点性能的不断提高,互连网络性能逐渐成为大规模计算集群整体性能提升的瓶颈,然而网络核心部件——“交换芯片”——的性能提升受到工艺和封装的限制[1-2]: 1)高速串行收发器(serdes)的带宽提升缓慢,端口带宽提升依赖于多路高速串行链路的并行,例如100 Gbps端口采用4路25 Gbps链路;2)封装技术限制交换芯片的引脚数目,进而限制交换芯片能够集成的serdes数目.因此,工艺和封装技术限定交换芯片能够提供聚合网络带宽.在聚合带宽限定的条件下,传统追求高阶高带宽的best-effort设计方法将不再有效,交换芯片设计必须考虑最优的带宽分配,如图1所示:1)多端口策略.端口带宽低,端口数目多.2)高带宽策略.端口带宽高,端口数目少.
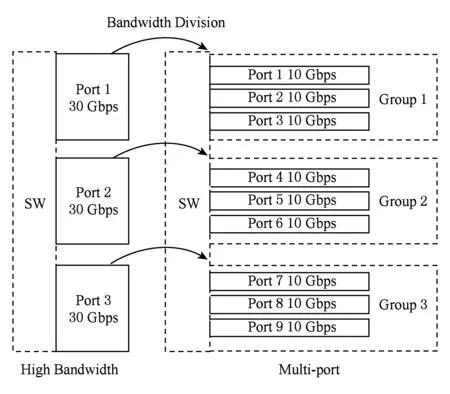
Fig. 1 Strategy between high bandwidth and multi-port图1 高带宽与多端口策略示意图
直观地,多端口策略是高带宽策略的细化分割,更有利于提高组网的灵活性,降低网络流的调度粒度,而高带宽策略则有利于快速缓解网络的拥塞.为评估2种策略的优劣,本文分别使用满足不同策略的交换芯片模型,构建相同拓扑的网络,通过理论分析和网络模拟进行全系统网络性能的评估.
为构建相同的拓扑,本文借鉴多轨网络(multi-rail network)的思想,提出了多轨分割网络结构:将多端口交换芯片抽象为高带宽交换芯片的细分,将其构建的网络(为方便描述,仍称为多轨网络)抽象为基于高带宽交换芯片网络的多轨化实现.但有别于传统多轨网络,本文的多轨网络由多层低带宽网络构成,且层与层之间并不独立,消息可以在不同层之间切换传输.本文多轨网络的构建方法、流量分配、消息分片和路由策略,是本文重点讨论的内容,是对基于高阶交换芯片的组网方法的有益探索.
本文的网络模拟均基于胖树拓扑展开,模拟结果表明多端口策略相比高带宽策略有3个优点:1)使网络具有可扩展性的网络流量调度与带宽分配策略;2)在降低基础网络硬件成本的同时,将短消息(长度小于128 B)的延迟性能提高近10倍以上;3)随网络流量注入率的增加,长消息传输(长度大于2 048 B)出现拥塞的情况会提前10%以上.因此,多轨分割网络能够给目前短消息占据多数的数据中心网络带来明显的性能提升.
1 相关研究
本文所提出的带宽分割化网络借鉴多轨网络的设计思想.多轨网络是指网络拓扑互联节点间用大于一层以上的彼此独立且具有相同结构和功能的网络相互连接,这种网络通过设置多层并行子网的设计思路,将大规模计算集群从单纯高聚合带宽交换模式中解放,成为另一种网络设计选择.网络分割度指网络内具有彼此独立且具有相同结构和功能的子网络的个数;而单轨网络作为多轨网络的特例,其分割度为1.同时,多轨网络因其拥有灵活配置网络带宽资源的设计可能,通过优化设计可以达到比高聚合带宽设计性能更好的可能.但是本文提出的带宽分割网络结构,在包括带宽链路分配、消息分片、路由和虚通道切换等策略方面,与传统多轨网络有很大区别.
对于传统的多轨网络结构,已经有较为充分的研究.文献[3]结合多核网络系统对多轨网络的需求,针对在系统软件层对多轨网络子网利用率低的问题,提出独立的一套软件层通信库,结合该通信库对小包通信场景的优化,降低CPU通信开销并提高通信并行性能.此论文所提出的通信协议优化策略,并未全面分析多轨网络的网络结构.文献[4]基于InfiniBand与RDMA的特征,通过增高带宽数据传输缓冲方式提高多轨HCA网络的通信性能,并针对MPI多轨中数据乱序处理进行优化.文献[5]希望通过在多轨网络中设置静态和动态的路径分配算法来提升网络的整体通信性能,虽然对路径分配算法描述得非常清楚且给出数学模型,但是从模拟的结果上看整体通信性能并没有提高,反而有恶化的现象.文献[6]结合MPI在多轨网络中上对失效备援和系统灾备恢复方面的需求,设计并评测一套建立在多轨网络上的系统切换与恢复算法.
文献[7]面向Quadrics QsNetII集群系统,基于多核多轨网络设计思想,通过增加源节点到目的节点的连接通道,即增加通信聚合带宽,提高网络的通信性能.该文与本文虽然都对多轨网络的结构和通信行为进行分析,但是本文旨在不改变通信总带宽的基础上进行优化策略,与文献[7]侧重点不同.
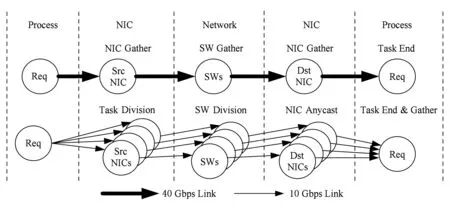
Fig. 2 The algorithm comparison between of multi-rail and single-rail图2 多轨与单轨链路算法对比
目前已实现[8-9]针对多轨QsNetII网络中基于多端口RDMA软件通信层数据分片和归集算法,并对小数据包进行性能评测.2篇论文对多轨网络研究集中在弥补现有软件通信库功能的不足,与本文侧重点不同.文献[10]着眼于uDAPL独立通信库在对多轨网络中通信功能支持方面进行的补充,通过实现2种多轨网络的配置方法,实现在InfiniBand集群上的多轨通信性能优化,也与本文侧重点不同.
文献[11-12]中分别对微软与Facebook数据中心网络的负载特性进行了分析,通过真实的网络平台实验测试,分析并总结主流数据中心网络负载的数据包长度上具有固定性分布,超过50%以上的负载数据包长保持在100~400 B之间,表明低负载数据包在数据中心网络中占有重要比重.
2 多轨网络模型分析
本节将基于网络多轨化构建思想对网络多轨分割方法进行阐述,结合传输延迟性能理论推导,对其性能预期进行量化分析.
2.1多轨分割方法论
建立多轨网络存在的2种策略:1)少量的高带宽端口,即高带宽策略;2)较多的低带宽端口,即多端口策略.本节的目的就在于分析2种策略的性能差别,使用如下场景:单轨网络使用一个高带宽端口,多轨网络使用多个低带宽端口,但二者的聚合带宽相同.下面将根据网络结构搭建方法和多轨分割在网络通信行为上的变化进行说明.
这2种构建多轨网络的策略在拓扑搭建上,多端口策略是由高带宽策略进行多轨带宽分割变形而来,如图2网络分割方法所示,该方法不受网络拓扑结构所限制.图2中40 Gbps link的网络链路为具有少量端口数且单条端口和链路带宽都较高的高带宽策略;10 Gbps link的网络链路为具有较多端口数且单条端口和链路带宽都较低的多端口策略.图2罗列出从系统进程层面之间的数据传输通路,具体的分割算法可以视为将40 Gbps link的每一条链路都拆分为4条10 Gbps link,由此保证单条链路的聚合带宽不变,同时单一链路的目的也要相应地多出端口来承载分割多出的链路.
网络通信行为方面,40 Gbps link网络链路由于网卡端口的唯一性,会在进程分发task和目的NIC接收数据的2处链路造成网卡数据聚集(NIC gather)现象;又由于网络流量指向非定向行,在网络链路传输过程中也会在交换机上产生交换数据聚集(switch gather)现象. 而这些收集现象在数据载荷较轻的流量传输过程中,往往会造成网络的局部拥塞.

Fig. 3 Network delay model of single-rail图3 单轨网络延迟模型
在进行网络分割后,在图2所示的10 Gbps link网络中,进程在进行task分发以及网络转发时,由于网卡和交换设备端口的分割,数据包产生开始以及网络转发阶段都进行task pipeline.而在交换机将数据传输到目的网卡时,由于网卡端口的分割带来的可选传输端口增多,因而任播通信方式也可以得以实现.虽然从以上分析来看,分割后网络在通信行为上能够更好地进行流水线传输;但是由于单端口带宽降低,网络中对单一数据包转发时延也会增大.而多轨网络中网络分割策略究竟对网络性能有怎样的影响,还需要进行定量分析.
2.2多轨网络性能理论分析
本节理论分析做如下设定:虚切入网络中的最大包长(MTU)为L,共有n个长度为L的网络数据包连续传输,网络接口控制器的输入带宽为BW_i,单轨模式下的网络链路带宽为BW_sl,多轨模式下单层网络链路带宽为BW_ml,交换机单级交换延迟为Tswitch,单级传输延迟为Tline,网络跳步数为Hop_cnt,并行网络层数为m,数据传输延迟为LBW_sl与交换延迟Tswitch.令单轨网络的带宽BW_sl=m×BW_ml,网络控制器输入带宽BW_i=k×BW_ml.
单轨网络的信息注入模型如图3所示.
在单轨网络中,消息的传输延迟Ts为
Ts= t0+(n-1)×max(LBW_sl,Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_sl.
(1)
根据多轨网络中的2种策略相应地存在对应的信息注入模型,如图4所示.多轨网络中,消息的传输延迟Tm为
Tm=t0+(m-1) ×LBW_i+(nm-1) ×
max(LBW_ml,m×LBW_i,Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_ml.
(2)
设如下场景:单轨网络使用一个高带宽端口,多轨网络使用多个低带宽端口,但二者的聚合带宽相同.令单轨网络的带宽BW_sl=m×BW_ml,网络控制器输入带宽BW_i=k×BW_ml.可得多端口策略比高带宽策略的性能提升倍数为
G=((n-1)×max(L(m×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+L(m×BW_ml))
max(LBW_ml,m×L(k×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_ml).
可得多端口策略比高带宽策略的性能提升倍数为
G=((n-1)×max(L(m×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+L(m×BW_ml))
max(LBW_ml,m×L(k×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_ml).
(3)
(Tswitch+Tline))((1+kn-1n)×LBW_ml+
当持续传输消息时,n趋于无穷,则提升倍数的极限为
(4)
(Tswitch+Tline)+k×L(m×n×BW_ml))
Hop_cnt×(Tswitch+Tline)).
当持续传输消息时,n趋于无穷,则提升倍数的极限为
(5)
(Tswitch+Tline))((k+m2n-mn-
Hop_cnt×(Tswitch+Tline)).
当持续传输消息时,n 趋于无穷,则提升倍数的极限为
(6)
(Tswitch+Tline)+L(n×BW_ml))
((1+(m2-m)(k×n)-mn)×LBW_ml+
当持续传输消息时,n 趋于无穷,则提升倍数的极限为
(7)
5) 当Tswitch≥max(LBW_ml,m×L(k×BW_ml))时,则提升倍数为
(Tswitch+Tline)+L(m×n×BW_ml))
(Tswitch+Tline)+L(n×BW_ml)).
当持续传输消息时,n趋于无穷,则提升倍数的极限为
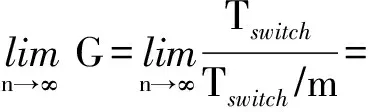
(8)
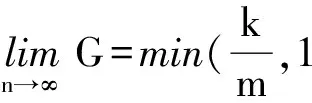
(9)
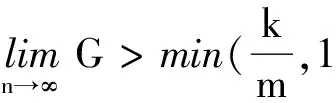
(10)
当Tswitch≥LBW_ml时(数据包较短),多端口策略相比高带宽策略可以获得m 倍的性能提升;当Tswitchlt;LBW_ml时(数据包较长),多端口策略的性能提升却与m成反比.
因此若采用多端口策略,端口的数目不能无限制增加,其取值受限于k,即网络接口控制器输入带宽与单层网络带宽的比值.当m=k 时,才能保证包长较大的情况下,多端口策略仍具有与高带宽策略相当的性能.
通过3级胖树为例,对以上分析进行计算,设Tswitch=130ns,Tline=100ns,BW_ml=10Gbps,k=6,Hop_cnt=5,n=10 000.可得不同分割度情况下,多轨策略性能提升倍数性能曲线,如图5所示.数据负载重量都集中在小于数据包长度为128B的区间,多轨网络中实行多端口策略较高带宽网络有性能提升优势.实际网络情况具体如何还需要进行模拟仿真进行验证.
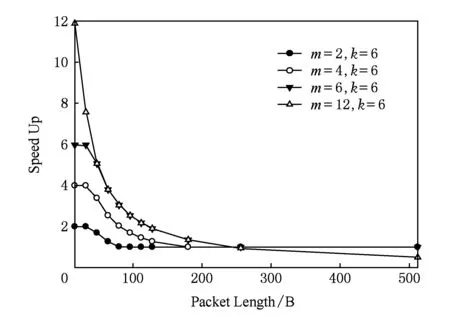
Fig. 5 Performance improvement in multi-rail with multi-port图5 多轨网络多端口策略性能提升倍数
3 多轨胖树网络实例分析

Fig. 6 The topological difference between high bandwidth and multi-rail in Fat-tree network图6 高带宽网络与多轨胖树网络的拓扑区别
标准胖树(Fat-tree)拓扑结构如图6(a)结构所示,具有等分带宽、低网络直径以及易于扩展的特点.图6(a)所示胖树拓扑中,方框图形为网络交换节点,圆形图形为产生数据和接收数据的网卡.图6中网络交换节点各有4个端口,即A~D.在能够满足高带宽、低延迟和可扩展的需求之外,由于标准胖树拓扑结构包含众多冗余链路的结构特性,有效避免网络中死锁问题的出现.
结合本文中所提出的数据分片算法,如2.1节中多轨分割方法所述,标准胖树网络进行带宽分割后,形成的多轨分割胖树网络的拓扑结构如图6(b)所示.图6(b)是基于图6(a)标准胖树网络进行分割度为4的带宽分割变换后形成的网络结构.标准胖树单条带宽为40 Gbps,而多轨胖树由于将单条40 Gbps链路分割成4条10 Gbps链路,对网络交换节点的端口需求也正比增加.在图6(b)中,每个交换节点的都有A~P共16个端口.多轨胖树在拓扑结构中的单层网络拥塞可能性提高,因此需要设计专有负载均衡、数据处理以及通道处理算法.
本节将针对多轨胖树网络的特殊结构,设计流量均衡算法、数据分片算法以及路由和虚通道切换策略.为简单描述,本文中所有的交换机都简写为SW,在集群中作为数据源的网卡简写为NIC.
3.1网络流量均衡算法设计
网络的多轨化为原有网络提供更加丰富的路径选择,但是如果网络中流量出现不均衡,网络性能不但不会提高反倒会因为单一子网拥塞而导致更多不可预期的局部热点,网络也会更容易出现网络拥塞.因此,配套的网络流量均衡策略对多轨网络优势体现尤为重要.本节通过对多轨网络中原址路由算法进行优化,提出一种基于单步均衡思想的流量均衡算法.下面以分割度为4的多轨胖树网络举例来阐述该算法实现过程,设胖树网络中共有编号为0~3的4套胖树子网.
保证在已有的多轨网络源址路由算法中,网络数据包由系统进程产生后,统一集中在4路子网的“0”号子网,即默认第1路子网.首先保证图2中Task Division阶段NIC网卡产生原始数据输出的4路带宽均衡,即进程产生数据包根据网络分割度将task进行分段,形成适合多轨网络均衡的数据包个数,由此保证NIC输出的每一路都是10 Gbps带宽.设连接相同源节点与目的节点的4条子网链路为同一组端口,即端口组.在多轨网络的传输过程期间,在交换机的数据发送的中间处理过程中(即在原址路由表修改的步骤中)根据发往的目的节点端口ID,设置交换机的网络局部变量,在每个交换设备中记录下每个端口组上具有相同目的端口组和源发送节点的数据包所占用的端口号为历史端口占用号.根据历史端口占用号,设置当前数据包转发端口,并修正历史端口信息.在设置当前转发端口时,可以通过依次递增同一端口组中的端口号方式进行历史端口占用号更新,保证每次发往统一交换设备的数据包能够平均分配在4个子网上.
以上是多轨网络中的端口流量均衡算法,在实现上是通过每次数据包在多轨网络中转发时进行单步修正的.结合3.3节中VOQ模式的使用策略,也可以采用相同机理的网络虚通道流量均衡算法来进行实现,实现机理与端口均衡相同,这里不再赘述.这种算法在实现上的优势:1)该流量均衡算法避免使用全局网络状态信息,仅使用网络局部状态信息就可以保证多轨分割网络中同端口组子网间的流量均衡;2)算法可以在源址路由算法执行网络包头修改的过程中进行,没有额外的算法执行时间损耗;3)根据分割度和交换设备的实际端口个数决定算法局部变量的存储损耗,不会额外占用交换设备的过多存储空间.
3.2数据分片算法
如图7所示,进行重载数据(长消息)传输时,根据网络分割度,对重载数据进行数据分割.根据图5中不同分割度多轨网络对网络负载的传输性能的提升倍数,考虑到数据分片带来的信息包头的冗余信息,合理安排重载数据的分片方式,由此一个长消息被分拆为若干数据块,分发到多个链路中同时传递.
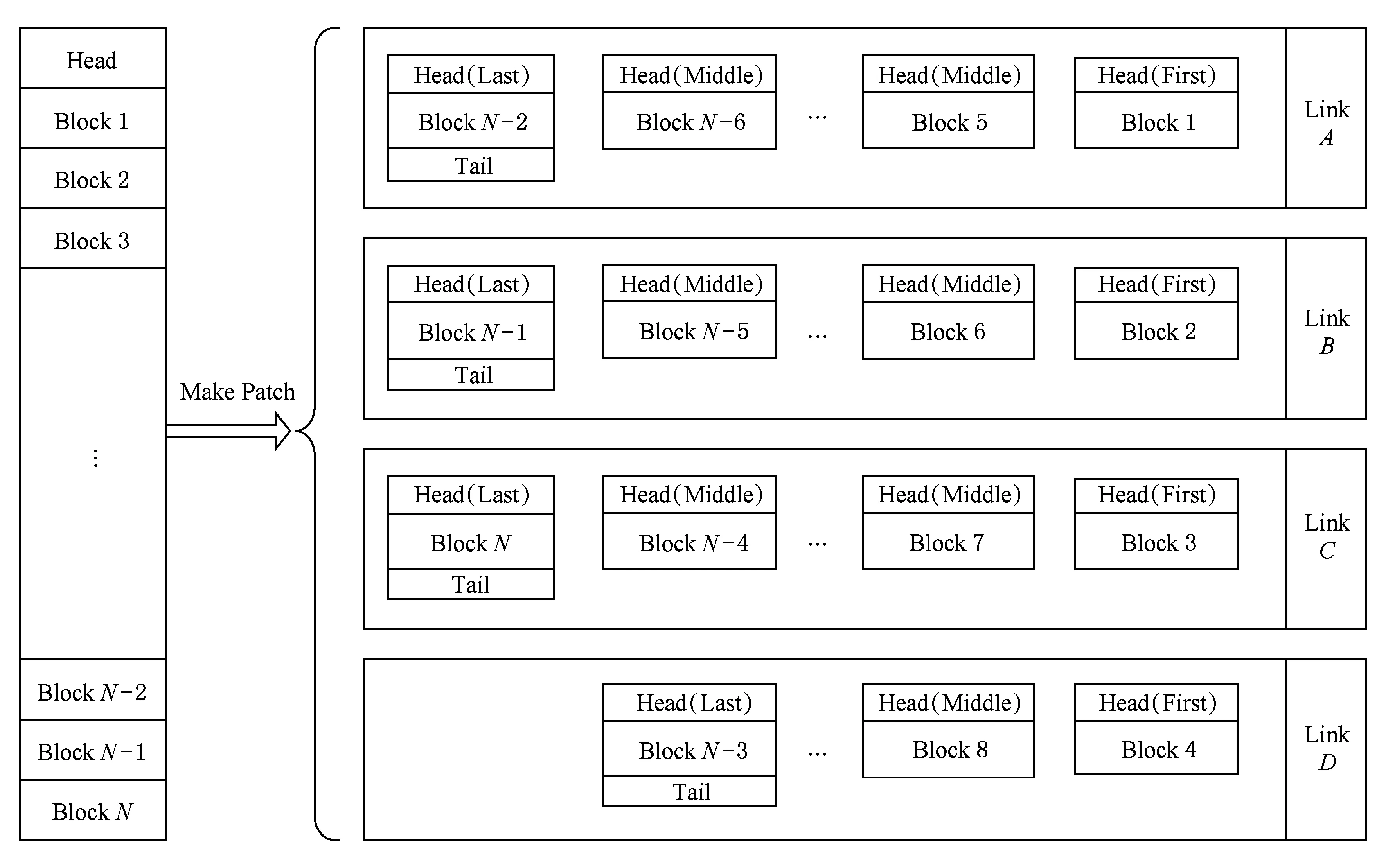
Fig. 7 Patch transmission of weight load图7 重载数据包信息分片传输
在图7某重载数据在分隔度为4的多轨网络中,对重载数据分片后形成N个轻载数据包分别携带N个数据块.这些轻载数据包依次被分配到链路A~D之中,在每个链路中,标记此消息在该链路中的首包和尾包,而此时所有链路中传输的数据包均为分片后的轻载荷数据包.由于单层网络中该消息数据包的传输保序,因此目标节点通过对首包和尾包的记录,即可获得消息在单层网络中的接收状态.本研究后续在对多轨网络实际性能进行评测时所使用的流量,都将使用本节中网络接口设计中数据包分片后形成的流量进行评测.
这样的网络接口和重载数据包处理方法,虽然增加对单个重载包的处理成本,但是通过对多链路并行使用,并根据数据长度决定链路的使用个数,实现多链路的负载均衡和高效利用,因此在网络整体性能角度上看,是极具性价比的网络实现模式.
3.3路由和虚通道切换策略
虚拟输出队列(virtual output queuing, VOQ)结构可以很好地解决队头阻塞(HOL blocking)问题,在VOQ结构下,每个输出端口设置多个虚通道缓冲队列.如图8(a)(b)所示,不同的数据包由于传输路径不同,因而在节点A和节点B上流经不同的虚通道,缓解数据端口缓冲排队的拥塞情况,因此在单、多轨网络中利用VOQ和数据包分片策略,都能发挥数据包传输并行化的优势.结合图5中关于分隔度不同,多轨网络对不同数据包长传输性能的差异,网络结构设计者除了需要确定重负载数据包数据分片的策略和多轨分割度之外,还需要考虑虚通道的设置个数.不同分割度情况下,虚通道策略实现的数据并行效果如图8(c)所示.在图8(c)中表现单轨网络(即分割度为1)和分割度为2的多轨网络,在端口缓冲空间总量相同的前提下,对同样重量的数据载荷进行数据分片后的并行传输效果.相同分割度情况下,受到端口转发速率的影响,数据分片大小没有本质影响数据转发效率.
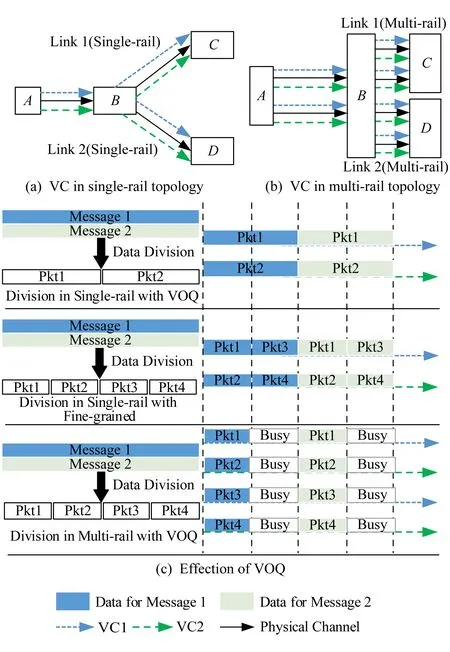
Fig. 8 The design of virtual channel图8 虚通道设计与效果示意图
由于端口缓冲空间总量相同,分割度为2的多轨网络的单独虚通道缓冲队列是单轨队列的一半,因此数据转发效率虽然在并行处理上提高1倍效率,但是独立队列有效使用率出现50%的性能折损.如果图8(c)中多轨虚通道缓冲区的深度与对应单轨虚通道保持一致,即在现有基础上缓冲区的深度翻倍,图8中的“Busy”就也能进行数据包转发,而整体数据转发性能也将翻一倍.因此,要想进一步发挥多轨网络在VOQ模式下的性能,应该根据网络热点严重程度的不同,合理分配端口转发缓冲区的深度.
4 网络分割性能模拟与分析
本节中所进行的性能仿真都是基于(m-port,n-tree)胖树网络所进行的.其中,m为网络中交换设备的端口总数,n为树的最大层级数,记(m-port,n-tree)胖树网络为FT(m,n),树的高度为n+1,包含2×(m/2)n个计算节点和(2n-1)×(m/2)n-1个交换机.本节仿真使用m=4,n=3标准胖树网络以及其多轨分割后形成的多轨胖树网络为仿真对象.在仿真所采用的网络拓扑中,网络交换节点从结构上共分为3级,最接近节点网络一级的网络交换节点为边界交换节点asymmetricSW,作为第3级switch.除此之外,另外还有2级交换节点,其中距离网卡最远的switch层级为第1级,另外一层为第2级.流量产生方式上,仿真流量采用uniform随机流量模型.NIC端带宽分割和网络数据流量分配后,switch,asymmetricSW交换机的工作时钟周期f(单位为ns)与数据位宽b(单位为B)的设置对网络性能的影响;分割度d作为区别多轨分割网络结构的特征参数.网络交换节点的聚合带宽B计算为
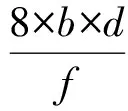
(11)
因此在各个参数共同影响下的B,可以表示当前网络聚合带宽,其中d还单独表示当前因为带宽分割度不同所表现的多轨网络拓扑结构的差异.结合NIC端带宽分割和网络数据流量分配的情况下,本节仿真分为2部分:1)多轨极限性能仿真,用以模拟网络多轨分割后网络可达到的极限性能;2)数据均衡分片对比仿真,用以验证多轨网络的性能提升倍数理论.
本文网络模拟基于cHPPNetSim(configurable HPP network simulator)多功能可配置并行网络模拟器进行仿真.该模拟平台主要功能是对大规模并行网络进行细粒度的模拟,模拟结果可以得到网络整体性能、局部性能,获取每个网络部件运行状态.
4.1多轨极限性能仿真
本次仿真中的多轨网络除对40 Gbps网络进行带宽4等分之外,子网间流量可以交叉,与此对比的对象是未分割独立带宽10 Gbps网络.独立10 Gbps网络可以表示4路独立10 Gbps网络在网络设备独立、子网路径独立不共用情况下40 Gbps网络的网络性能.由于子网间没有相互串扰,较少因跨网串扰导致的局部子网拥塞,所以10 Gbps网络模拟组的网络性能在理论上是40 Gbps网络进行带宽4等分网络的极限性能.
如图9所示的是2个网络的最大延迟性能差对比图.受工作频率影响,以高频工作的40 Gbps的分割网络在接收带宽小于32 Gbps的情况下,分割后性能优于10 Gbps独立网络50%左右;但从高强度注入率的情况看出,分割40 Gbps网络性能在处理拥塞情况时仍然处于劣势,性能较10 Gbps独立网络要差很多.
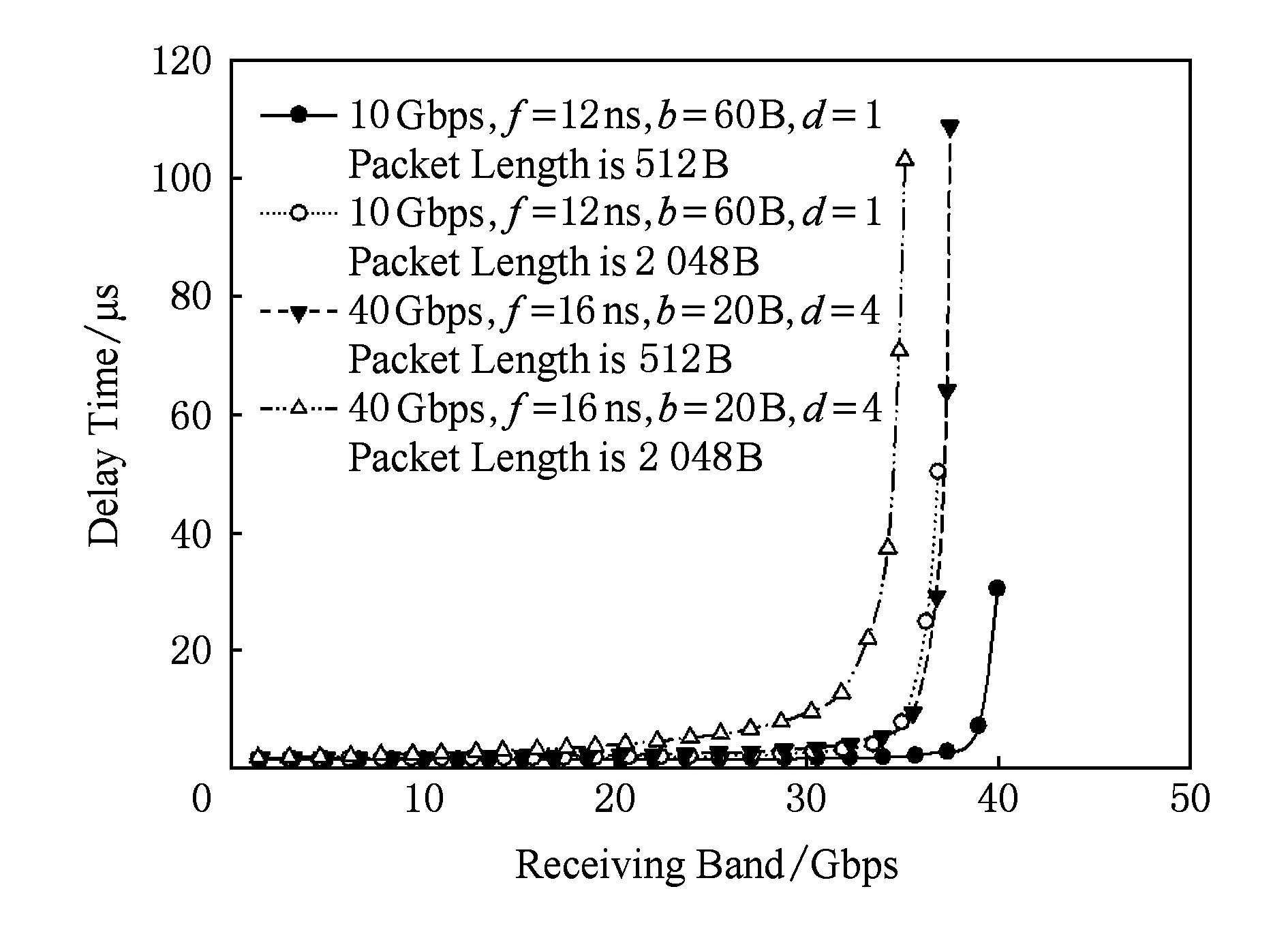
Fig. 9 The simulation of flow partitioning strategy of multi-rail图9 流量均分策略多轨分割性能仿真
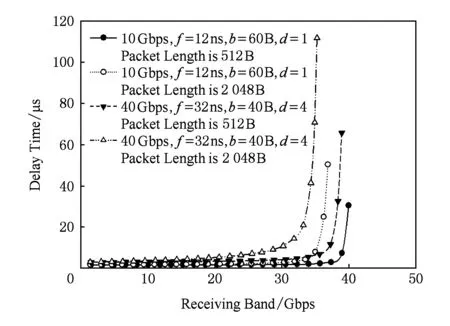
Fig. 10 Supplement simulation of flow partitioning图10 流量均分策略性能补充仿真
为减少因为工作频率较高带来的网络延迟性能提高,本节仿真特意增加40 Gbps,f=32 ns,b=40 B,d=4仿真组,代表40 Gbps分割网络在低工作频率情况下网络特性的情况.如图10所示2个网络的最大延迟性能差对比图.可以看出整体趋势受到降低工作频率的影响,在低注入率时性能提升幅度减小到10%左右.
4.2数据均衡分片对比仿真
在2.2节中对多轨网络性能的理论分析,没有考虑到网络拥塞情况;但是在实际网络中,拥塞情况往往会让网络性能急剧恶化.结合之前对多轨网络的研究,多轨网络虽然拥有结构灵活,且解放高带宽网络设备依赖等问题;但是由于网络路径数量随分割度正比增加,分割多轨网络的通信性能会因任何一条拥塞的链路导致整个网络的通信传输性能下滑.
本次仿真中对20 Gbps,40 Gbps,80 Gbps高带宽网络中传输的数据包进行数据均匀分片,比如4 096 B数据包在4×10 Gbps网络中,通过(4 096-16)/4+16=1 036 B在4段均分数据分片网络中4路子网并行传输1 036 B数据包.结合之前所实现的子网间流量均衡,4 096 B数据包在40 Gbps高带宽网络传输的网络性能对比对象即为:1 036 B数据包在4×10 Gbps多轨分割网络传输的网络性能,以此类推.所得到的网络特性结果如图11~16所示:
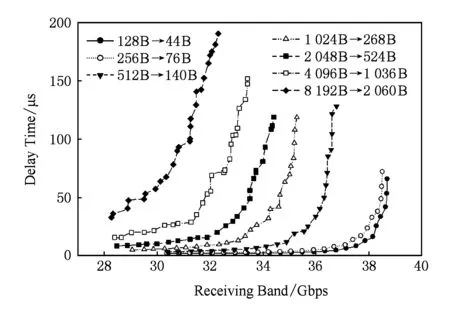
Fig. 11 Network latency performance of multi-rail in 4×10 Gbps图11 4×10 Gbps多轨网络延迟性能
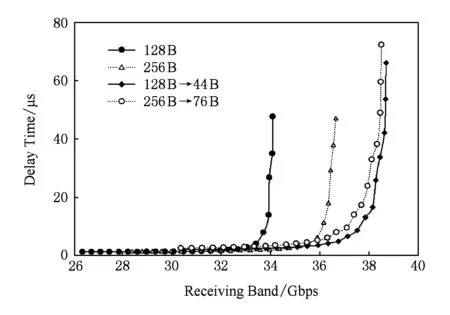
Fig. 12 The performance of light load图12 轻重量数据载荷性能对比

Fig. 13 The performance of medium load图13 中等重量数据载荷等性能对比
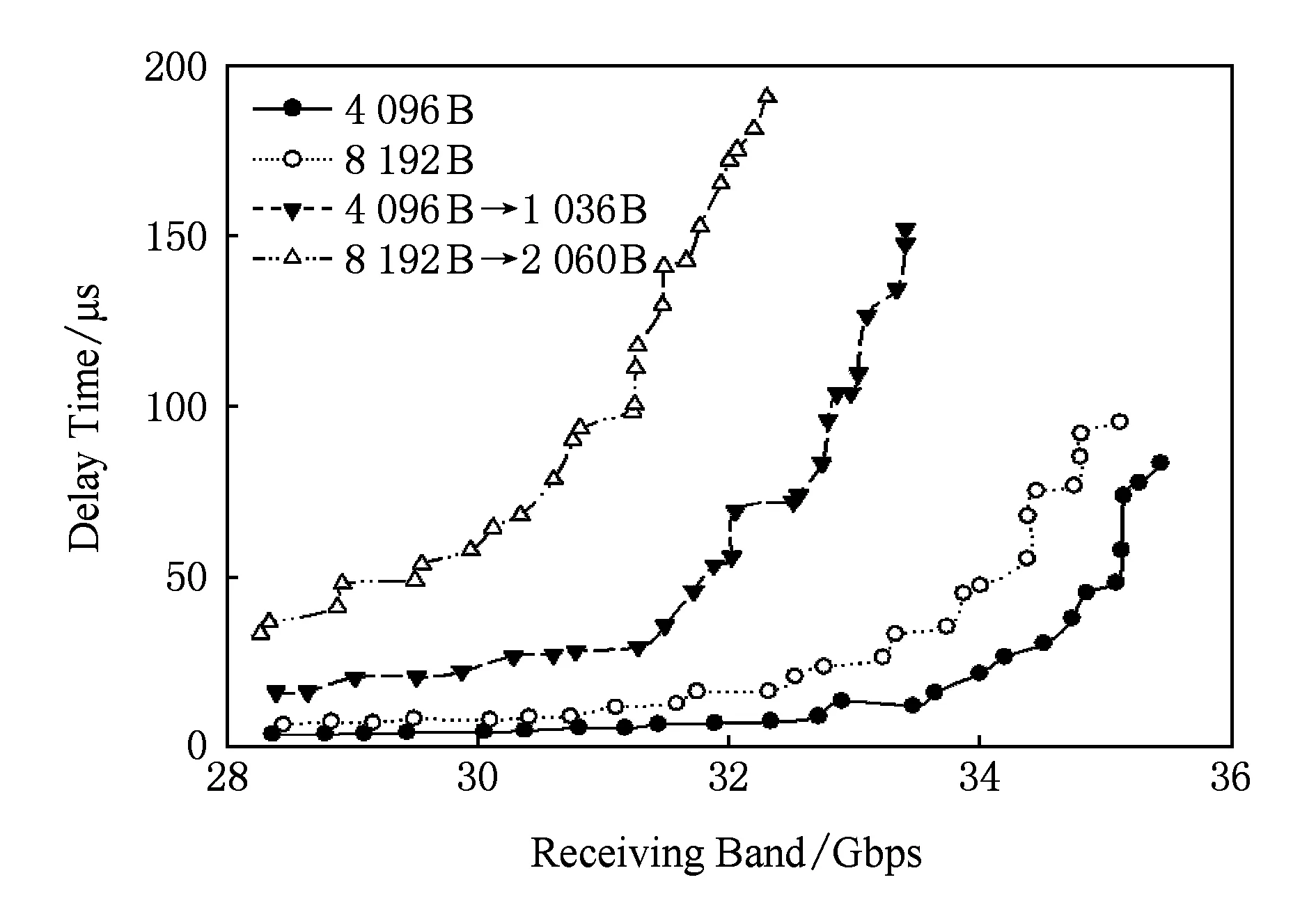
Fig. 14 The performance of weight load图14 重度重量数据载荷度性能对比
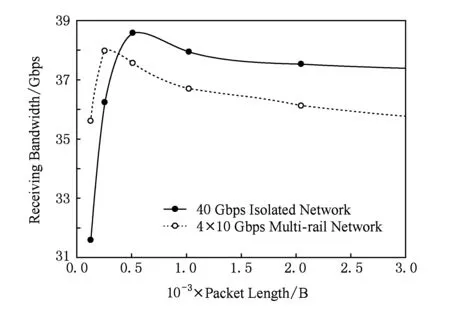
Fig. 15 The bandwidth variation of maximum load图15 网络的最大负载带宽变化曲线
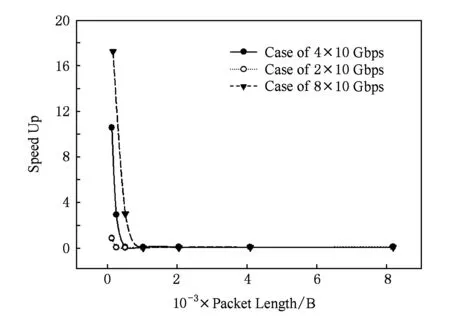
Fig. 16 Practical improvement of multi-real network图16 多轨网络的实际性能提升倍数
4×10 Gbps多轨网络进行不同数据大小传输下的网络延迟性能,如图11曲线所示.多轨网络的网络传输性能随网络负载数据包的包长逐步增大,网络出现拥塞的情况就会更早地出现,且网络负载数据包越长,网络最大流量带宽随之降低.结合图1中的数据可体现出网络最大流量带宽的范围.
40 Gbps高带宽胖树网络与4×10 Gbps多轨网络在轻重量数据载荷传输情况下网络性能对比结果,如图12所示.图12中128 B→44 B与256 B→76 B两条线表示在4×10 Gbps分割网络中分别传输44 B和76 B两种数据流量情况下的网络延迟性能,分别与128 B和256 B两种数据负载在40 Gbps高带宽胖树网络中的网络性能进行对比.图12显示,128 B和256 B这2种数据负载属于轻重量数据载荷;在这种负载情况下,多轨网络表现出网络传输性能优势的现象,且多轨网络的接收带宽也比单独高带宽网络要高.
40 Gbps高带宽胖树网络与4×10 Gbps多轨网络在中等重量数据载荷传输情况下网络性能对比结果,如图13所示.从图13中可以看出,在512 B,1 024 B,2 048 B这3种数据负载属于中等重量数据载荷;在这种负载情况下,多轨网络表现出网络传输性能出现劣势的现象,且多轨网络的接收带宽也比单独高带宽网络要低.
40 Gbps高带宽胖树网络与4×10 Gbps多轨网络在重度重量数据载荷传输情况下网络性能对比结果,如图14所示.从图14中可以看出,在4 096 B和8 192 B这2种数据负载属于重度重量数据载荷;在这种负载情况下,多轨网络表现出网络传输性能出现更加劣势的现象,多轨网络的接收带宽不仅比单独高带宽网络要低,而且比中等载荷仿真中更加明显.
40 Gbps高带宽胖树网络与4×10 Gbps多轨网络在不同数据包长载荷情况下网络的最大负载带宽情况,如图15所示.从图15中看到,在较低负载情况下虚线的多轨网络接收带宽还处于较高的位置,但在数据负载大于400 B后,表明多轨网络的整体网络处理能力的最大负载带宽要低于高带宽胖树网络,且随着网络负载包长的增加,最大负载带宽有进一步降低的趋势.从图15中的波峰位置可以看出,无论是高带宽胖树网络还是多轨网络,2种网络都有最佳网络负载点,低于或高于该点网络整体性能都会有所下滑.针对同一总网络带宽情况下网络分割程度不同,如何影响最佳网络负载点的移动,还需对如40 Gbps高带宽胖树网络与8×5 Gbps多轨网络对比仿真的类似仿真进行分析.
单链路带宽20 Gbps,40 Gbps,80 Gbps的3种网络的高带宽胖树网络与相应的10 Gbps多轨网络在不同数据包长载荷情况下的实际策略性能提升倍数,如图16所示.结合第2节的理论分析可以证实,理论分析的整体趋势确实存在,但是受到网络拥塞和多轨网络流量分配策略误差等综合情况的影响,提升倍数与理论分析结果间存在差异.
5 总结及下一步工作
在交换芯片聚合带宽确定的条件下,本文所提出的多轨分割网络的每条子网带宽需要根据分割度进行等比例缩减.网络多轨分割后,带宽分配的网络可扩展性更好.应对多发性局部流量拥塞造成的网络阻塞情况,单一的高带宽网络拓扑结构由于流量分配、拥塞避免算法的路径切换颗粒度不够小,无法避免多发性拥塞造成的拥塞情况.
轻载荷网络负载下的网络延迟性能根据分割度的提升也展现出了正比优势.在实际的系统中,短消息占据了数据中心网络的大部分流量.在文献[11]中,根据Facebook数据中心对数据负载情况的统计结果,主要数据负载集中在长度小于200 B的数据包上,基于Hadoop的大数据应用也存在同样的负载特征.以PageRank为例,在map,shuffle,reduce在内的3个主要工作阶段中数据负载包长接近60%的负载流量都集中在小于128 B区间.
分析结果表明,本文的多轨分割网络有利于提高短消息的延迟性能,因此该结论对于优化实际网络系统的性能有重要指导意义.评测结果客观体现了多轨分割网络自身固有的性能局限.在网络拥塞状态下,相较于高带宽网络,多轨分割网络会出现更快的网络性能下降现象.而该现象的主要成因是网络流量处于非绝对平均状态,且多轨策略铺设了更多的网络路径,链路出现拥塞的概率得到增加.所以,网络设计者在进行多轨网络设计时,除了需要根据网络路径和端口虚通道流量分配策略进行体系结构设计,还需要结合网络流量的实际热点特征,针对网络热点端口,加大网络端口队列缓冲深度或提升关键路径的路径带宽,来缓解多轨化分割后热点路径的拥塞问题.本文对多轨分割网络的研究还仅仅处于初步探索阶段.未来工作中会将非对称网络与网络多轨化相结合.深入网络局部性多轨化策略以及非对称交换机方面的研究,针对实际大规模计算集群部署时出现的问题展开新的工作.同时,也将会进一步深入到目前实际集群应用的相关通信特性分析,探讨针对各种实际应用使用下的网络多轨优化设计方法和相应的优化策略.网络多轨化策略目前值得进一步研究的问题还有很多,该思想会逐步成为高性能计算和大数据网络体系结构的重要研究热点.
致谢感谢中国科学院国有资产经营有限责任公司对本论文的大力支持!感谢中科院计算所的王展博士对本论文在网络体系结构方面的技术指导!
[1]Wang Dawei, Cao Zheng, Liu Xinchun, et al. Research and design of high performance interconnection network switch [J]. Journal of Computer Research and Development, 2008, 45(12): 2069-2078 (in Chinese)(王达伟, 曹政, 刘新春, 等. 高性能互联网络交换机研究与设计[J]. 计算机研究与发展, 2008, 45(12): 2069-2078)
[2]Cao Zheng. Research on interconnection network of dawning 5000 high productivity computer[D]. Beijing: Institute of Computing Technology, Chinese Academy of Sciences, 2009 (in Chinese)(曹政. 曙光5000高效能计算机系统的互连网络研究[D]. 北京: 中国科学院计算技术研究所,2009)
[3]Brunet E, Trahay F, Denis A. A multicore-enabled multirail communication engine[C]Proc of IEEE Int Conf on Cluster Computing. Piscataway, NJ: IEEE, 2008: 316-321
[4]Liu Jiuxing, Vishnu A, Panda D K. Building multirail infiniband clusters: MPI-level design and performance evaluation[C]Proc of the 2004 ACMIEEE Conf on Supercomputing. Los Alamitos, CA: IEEE Computer Society, 2004: 33
[5]Salvador C. Static allocation of multirail networks [EBOL]. (2012-08-16)[2015-07-18].https:www.researchgate.netpublication2546969_Static_Allocation_of_Multirail_Networks
[6]Raikar S, Subramoni H, Kandalla, K, et al. Designing network failover and recovery in MPI for multi-rail infiniband clusters[C]Proc of IEEE Parallel and Distributed Processing Symp Workshops. Piscataway, NJ: IEEE, 2012: 1160-1167
[7]Qian Ying, Afsahi A. Efficient RDMA-based multi-port collectives on multi-rail QsNet II clusters[C]Proc of the 20th Int Conf on Parallel and Distributed Processing. Los Alamitos, CA: IEEE Computer Society, 2006: 273
[8]Qian Ying, Afsahi A. High performance RDMA-based multi-port all-gather on multi-rail QsNet Ⅱ[C]Proc of the 21st Int Symp on High Performance Computing Systems and Applications (HPCS 2007). Piscataway, NJ: IEEE, 2007: 3
[9]Qian Ying, Afsahi A. RDMA-based and SMP-aware multi-port all-gather on multi-rail QsNet Ⅱ SMP clusters[C]Proc of the 42nd Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2007: 48
[10]Cai Jie, Rendell A P, Strazdins P E. Non-threaded and threaded approaches to multirail communication with uDAPL[C]Proc of the 6th IFIP Int Conf on Network amp; Parallel Computing (NPC 2009). Piscataway, NJ: IEEE, 2009: 233-239
[11]Arjun R, Hongyi Z, Jasmeet B, et al. Inside the social network’s (datacenter) network [J]. ACM SIGCOMM Computer Communication Review, 2015, 45(5): 123-137
[12]Theophilus B, Ashok A, Aditya A, et al. Understanding data center traffic characteristics [J]. ACM SIGCOMM Computer Communication Review, 2010, 40(1): 92-99

ShaoEn, born in 1988. PhD candidate, engineer. His main research interests focus on SDN, big data, high performance interconnection, and optical network.

YuanGuojun, born in 1983. PhD candidate, engineer. His main research interests include computer architecture and optical flexible network.

HuanZhixuan, born in 1990. MSc candidate. His main research interests include inter-connection networks, computer architec-ture and parallel computing.

CaoZheng, born in 1982. PhD, associate professor. His main research interests include high performance computer archi-tecture, high performance interconnection, and optical interconnection.

SunNinghui, born in 1968. PhD, professor, PhD supervisor. His main research interests include computer architecture, high perfor-mance computing and distributed OS.
ASlicedMulti-RailInterconnectionNetworkforLarge-ScaleClusters
Shao En1,2, Yuan Guojun1,2, Huan Zhixuan1,2, Cao Zheng1, and Sun Ninghui1
1(State Key Laboratory of Computer Architecture (Institute of Computing Technology, Chinese Academy of Sciences), Beijing 100190)2(University of Chinese Academy of Sciences, Beijing 100049)
In large-scale clusters, the design of interconnection network is facing greater challenges. Firstly, the increasing computing capacity of a single node requires the network providing higher bandwidth and lower latency. Secondly, the increasing number of nodes requires the network to have extremely better scalability. Thirdly, the increasing scale of system leads to worse performance of collective communication, which is harmful to the performance and scalability of applications. Fourthly, the increasing number of devices requires the network to have better reliability. As the performance of computing nodes keeps increasing, interconnection network has gradually become the bottleneck of large-scale computing system. However, switch chip, the core component of interconnection network, can offer limited aggregate bandwidth because of the constraint of physical processes and packaging technologies. With the co-design of network architecture and switch micro-architecture, this paper proposes a sliced multi-rail network architecture regarding the given aggregate bandwidth. Through mathematical modeling and network simulation, we studies the performance boundaries of sliced multi-rail network. Evaluation results show that the average latency of the short message (less than 128B)can be increased by more than 10 times.
large-scale clusters; multi-rail network; bandwidth division; data center network; large-scale network simulation
2015-12-09;
2016-05-25
国家重点研发计划项目(2016YFB0200300,2016YFGX030148,2016YFB0200205,2016GZKF0JT006);国家自然科学基金项目(61572464,61331008,61402444);国家“八六三”高技术研究发展计划基金项目(2015AA01A301);华为科研基金项目(YB2015070066);中国科学院战略性先导科技专项(XDB24060600)
This work was supported by the National Key Research and Development Program of China (2016YFB0200300, 2016YFGX030148, 2016YFB0200205, 2016GZKF0JT006), the National Natural Science Foundation of China(61572464, 61331008, 61402444), the National High Technology Research and Development Program of China (863 Program) (2015AA01A301), the Scientific Research Foundation of Huawei (YB2015070066), and the CAS Strategic Priority Program (XDB24060600).
TP303
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
西安航空学院学报(2021年1期)2021-07-24
科学家(2021年24期)2021-04-25
民用飞机设计与研究(2020年4期)2021-01-21
电子制作(2019年13期)2020-01-14
中国信息化周报(2019年20期)2019-07-01
网络安全和信息化(2019年5期)2019-06-04
物联网技术(2018年8期)2018-12-06
大科技·D版(2018年7期)2018-10-21
中小企业管理与科技·中旬刊(2017年7期)2017-09-08
