
基于高分辨率遥感影像多维度特征的树种识别方法研究
2017-12-29 06:35靳茗茗王瑞瑞寇珑璇杨致远周彦楠
中南林业调查规划 2017年3期
靳茗茗,王瑞瑞,郑 鑫,寇珑璇,杨致远,周彦楠
(北京林业大学林学院, 北京 100083)
基于高分辨率遥感影像多维度特征的树种识别方法研究
靳茗茗,王瑞瑞,郑 鑫,寇珑璇,杨致远,周彦楠
(北京林业大学林学院, 北京 100083)
以北京市西山试验林场为研究区域,利用Worldview-2影像构建各树种的光谱特征、地形特征、植被指数特征、纹理特征以及形态特征,建立关于山地森林树种识别的知识。采用基于像元和面向对象的方法进行树种识别分类。在基于像元的分类方法中,选择决策树分类和支持向量机分类;在面向对象的分类方法中,选择基于边缘检测的方法分割影像,用最近邻法分类。决策树分类的总体分类精度为65.62%,Kappa系数为0.588 9;支持向量机分类的总体分类精度为62.42%,Kappa系数为0.552 8;面向对象的分类方法总体分类精度为64.27%,Kappa系数为0.580 2。
树种识别;遥感;多维度特征;决策树;支持向量机;面向对象
引言
对于森林植被分类而言,中低空间分辨率的遥感影像通常难以准确获取地物信息,采用传统的分类方法,其精度通常无法满足森林资源管理的要求。然而,当空间分辨率提高时,林区特殊的地理环境和生物分布又会导致“同谱异物”和“同物异谱”现象,极易发生错分和漏分,减弱影像光谱域的统计可分性[1-2],在复杂的地形条件下,这种现象更为严重,一些适用于中低分辨率影像的解译方法在处理高分辨率影像的复杂特征时面临很大困难。
对于树种识别而言,仅依据地物光谱特征的差异进行分类的精度较低,因此通常要结合辅助数据或外在知识、利用改进的分类方法进行分类,如结合地学辅助数据、利用人工神经网络、专家系统、多时相和多源遥感影像融合等[3-4]。陈艳华等[5]利用C4.5算法建立决策树,结合DEM等地学辅助数据,在GIS空间分析的基础上进行了分类后处理,与极大似然法相比显著提高了山区植被分类的精度;张锦水等[6]基于SVM的分类方法,复合光谱、纹理和结构等特征,对IKONOS影像进行了分类;陈君颖等[7]采用决策树分类算法,根据植被光谱特征建立知识库,提出基于光谱信息的植被分类方法,继而引进局部一致性指数对该方法进行改进,提出结合纹理信息的高分辨率遥感植被分类方法。M.Baatz和A.Schape[8]根据高分辨率遥感影像的特点,提出了面向对象的遥感影像分类方法。森林覆盖面积大,同种森林内部结构较为均一,不同类型的森林结构之间在遥感影像上差异较为明显[9],因此面向对象的分类过程更符合遥感影像森林分布的特点。熊轶群等[10]利用面向对象的方法提取城市绿地信息,总体分类精度达到84.4%,比监督分类法提高了24.4%;苏簪铀等[11]基于SPOT5遥感影像利用面向对象分类方法对复杂地形条件下的景观信息进行提取,精度为76%;杨飞等[12]在比较了4种面向对象分类方法 ( 最邻近法、隶属度函数法、决策树和支持向量机)后认为,最邻近分类方法用于山区林地分类时分类精度和稳定性最高。
在现有的研究中,同时构建多维度分类特征并同时利用基于像元和面向对象分类的研究较少,因此,本研究基于上述分析,拟构建多维度特征,采用基于像元的决策树分类、支持向量机分类,以及面向对象的方法进行树种识别与分类,以充分提取遥感影像信息,提高树种识别的准确性。
1 研究区概况
研究区位于北京市西山试验林场,地跨海淀、石景山、门头沟三区,属于城市景观生态公益型国有林场,气候上属于暖温带大陆性季风气候,年平均降雨量约630 mm,年平均气温11.6 ℃,最高海拔约800 m。该地区土壤质地类型为中壤土,土层较薄且含石砾量较高,平均坡度在15~35°。植被多为上世纪50年代营造的人工林,树种主要有油松,侧柏、刺槐、黄栌、元宝枫、栓皮栎以及山杏等。
2 数据来源与处理
2.1 数据来源
研究数据包括2016-05-18的Worldview-2遥感影像、DEM数据、2014年林业小班调查数据,以及野外实测光谱数据。其中Worldview-2遥感影像包含8个分辨率为2 m的多光谱波段以及1个分辨率为0.5 m的全色波段,影像覆盖范围约116°07′—116°11′E, 39°59′—40°01′N。DEM影像为30 m分辨率的ASTER GDEM V2数据。
2.2 数据处理
2.2.1 影像的校正与融合
对影像进行大气校正、几何校正,并采用Gram-Schmidt变换对多光谱和全色波段进行融合。
2.2.2 阴影区与非阴影区的划分
由于高分辨率影像同类树种在阴影区和非阴影区的差异较大,因此,根据许章华等[13]提出的阴影植被指数(SVI),将影像划分为阴影区和非阴影区,根据影像地物的实际情况,选择恰当的阈值进行分类。其计算公式为:
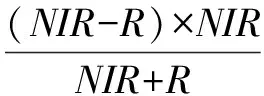
(1)
其中,NDVI为归一化植被指数;NIR为近红外波段灰度值或反射率;R为红光波段灰度值或反射率。
2.3 分类系统的构建
将研究区划分为林地和非林地。根据林业小班调查数据及其他文献资料,在林地中确定研究区的优势树种,包括油松,侧柏、刺槐、黄栌、元宝枫、栓皮栎以及山杏共七种。
在林地的阴影区和非阴影区分别选择以上七种树木的样本,包括非林地在内,训练样本共计15类。在选择验证样本时合并阴影区和非阴影区,包括非林地和七种优势树种样本共计8类。
3 研究方法
3.1 多维度特征的构建
3.1.1 光谱特征
根据野外实测光谱及ROI样本均值统计,不同树种在近红外波段的反射值差异最大。因此,选择第六波段(705~745 mm)、第七波段(770~895 mm)以及第八波段(860~1040 mm)作为光谱特征。
3.1.2 地形特征
在ArcGIS中利用DEM数据生成坡度、坡向图,作为地形特征。
3.1.3 植被指数特征
选择ROI样本光谱均值差异较大的指标,最终确定为归一化植被指数(NDVI)、比值植被指数(RVI)和垂直植被指数(PVI)。其计算公式为:
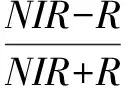
(2)
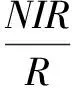
(3)
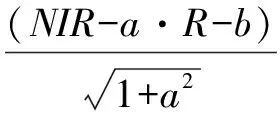
3.1.4 纹理特征
利用原始影像的主成分第一波段提取纹理特征,选择相关性较小且ROI样本光谱均值差异较大的指标,最终确定为均值(Mean)、对比度(Contrast)和二阶矩(SecondMoment)。其计算公式为:
Mean=∑ni=1∑nj=1if(i,j)
(5)
Contrast=∑ni=1∑nj=1(i-j)2f(i,j) (6)
SecondMoment=∑ni=1∑nj=1f(i,j)2(7)
3.1.5 形态特征
在以上四种分类特征的基础上 利用基于边缘检测的影像分割方法构建形态特征。
3.2 分类方法
3.2.1 决策树分类
决策树分类算法是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的事例中推理出决策树表示的分类规则[15]。该方法先利用训练空间实体集生成判别函数,再根据不同取值建立树的分支,在每个分支子集中重复建立下层结点和分支,形成决策树,然后用测试数据集中的数据校验决策树生成过程中产生的初步规则,并用代价复杂性剪枝(cost-complexity pruning)简化过拟合的决策树。
本研究采用CART(Classification and Regression Tree)算法建立决策树,它采用二分递归分割的技术,节点分裂建立在Gini指数上,以找出最好的二分方法。
Gini指数刻画了信息的纯度,用于计算从相同的总体中随机选择的两个样本来自于不同类别的概率,其计算公式为:
Gini(D)=1-∑cipi2
(8)
其中c表示数据集中类别的数量,Pi表示类别i样本数量占所有样本的比例。
若选取的属性为A,则分裂后数据集D的Gini指数计算公式为:
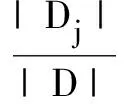
(9)
选择基尼指数增益值最大的特征作为该节点的分类条件,其公式如下:
△Gini(A)=Gini(D)-GiniA(D)
(10)
3.2.2 支持向量机分类
支持向量机方法建立在统计学习理论的VC维理论和结构风险最小原理基础上,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力,是可以克服“维数灾害”和“过学习”等传统困难的有力工具[16-18]。
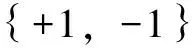
g(x)=w·x+b=0
(11)
满足条件:
yi[(w·xi)+b]-1≥0,i=1,…,n
(12)
求解最优分类面可以表示为在式(12)的约束下求以下函数的最小值
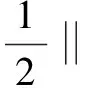
(13)
对于线性可分的训练集,其最优分类函数为:
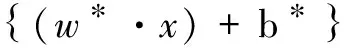
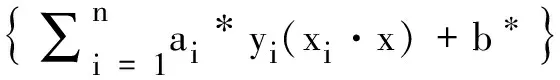
(14)
其中,sgn()为符号函数,b*是分类的阈值,可由任意一个支持向量由式(12)求得,ai*为最优解,w*=∑ni=1ai*yixi
当训练样本集线性不可分时,需要在约束条件中引入松弛系数εi≥0,即
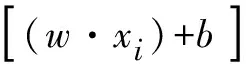
(15)
在此约束条件下求下列函数的极小值:
(16)
其中,C为惩罚系数。
其最优分类函数为:
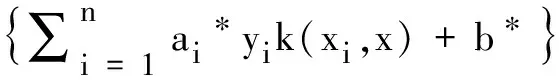
(17)
其中,sgn()为符号函数,b*是分类的阈值,k(xi,x)为核函数。
SVM的关键在于核函数。本研究采用RBF核函数,C和g是必备的两个参数,分别为惩罚系数和间隔,利用libSVM做交叉验证可确定其具体取值。
3.2.3 面向对象分类
传统的分类方法主要基于像元分类,极易出现“椒盐现象”[19],分辨率越高,这种现象越严重。而面向对象的分类方法,以影像对象为分类单元,综合考虑了像元的光谱信息、对象内部的结构、纹理以及与相邻对象之间的关联信息,可在很大程度地减少“椒盐现象”的出现[20-21]。
其一般步骤是:首先,对经过预处理的遥感影像进行多尺度分割,得到“同质”对象;其次,根据需求提取目标地物的各类特征,建立分类体系;最后,采用模糊分类算法进行地物类别的自动分类和提取[22]。
图像分割是将数字图像细分为多个图像子区域(像素集合)的过程,基于灰度、颜色、纹理等特征形成多类区域,在同类区域内,图像具有相同或相近的特征性质,在不同类的区域间,图像特征具有明显差异。本研究选择基于边缘检测的分割方法,分类方法为最邻近法。
基于边缘检测的方法主要通过检测出区域的边缘来进行分割,利用区域之间特征的不一致性,首先检测图像中的边缘点,然后按一定策略连接成闭合的曲线,从而构成分割区域。
最邻近法分类类似于监督分类,需要选择一定的样本[12],通过样本对象特征空间计算得出待分类对象到各个样本的距离,将待分类对象判定为距离最小的样本所属类别[23]。
本研究利用envi软件的Feature Extraction模块进行基于样本的面向对象分类,经多次试验最终确定分割阈值为50,合并阈值为90。
3.3 精度评价方法
分类精度是指分类图像中像元被正确分类的程度,最广泛的精度评价方法是由R.G.Congalton提出的误差矩阵法[24],它是一个r×r的矩阵,元素表示像元数。
在矩阵中,生产者精度(Producer’s Accuracy)表示某一类别的正确分类数占参考数据中该类别像元总数的比例,对应漏分误差;用户精度(User’s Accuracy)表示某一类别的正确分类数占分为该类的像元总数的比例,对应错分误差;总体精度(Overall Accuracy)表示被正确分类的像元总数占总样本数的比例,代表分类结果的总体正确程度;Kappa系数作为分类精度评估的综合指标,其计算公式为:
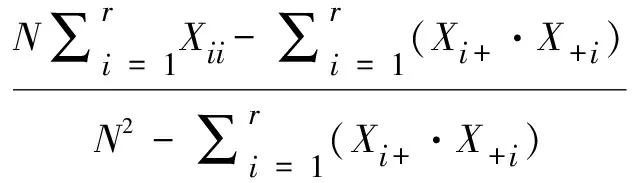
(18)
其中,r为矩阵行数,Xii为第i行i列的值,Xi+和X+i是行总和和列总和,N为总观察值。
4 结果与分析
4.1 分类结果
分类结果见图1:
1) 在决策树分类结果中,油松为研究区主要优势树种,占研究区总面积的21.83%,其次为黄栌,占研究区总面积的14.34%;栓皮栎和山杏的分布较少,分别占总面积的4.85%和7.46%。
2) 在支持向量机分类结果中,黄栌为研究区主要优势树种,占研究区总面积的20.7%,其次为油松,占研究区总面积的20.23%;栓皮栎和山杏的分布较少,分别占总面积的6.34%和8.78%。
3)在面向对象分类结果中,油松为研究区主要优势树种,占研究区总面积的24.05%,其次为黄栌,占研究区总面积的16.48%;栓皮栎的分布最少,占总面积的2.89%。

a)决策树分类

b) 支持向量机分类

c) 面向对象分类
图1分类结果
4.2 分类结果评价
1) 决策树分类的总体精度为65.62%,Kappa系数为0.588 9。非林地的分类精度最高,林地中,山杏和栓皮栎的分类精度较低,其余树种的精度相近,均在60%以上(表1)。
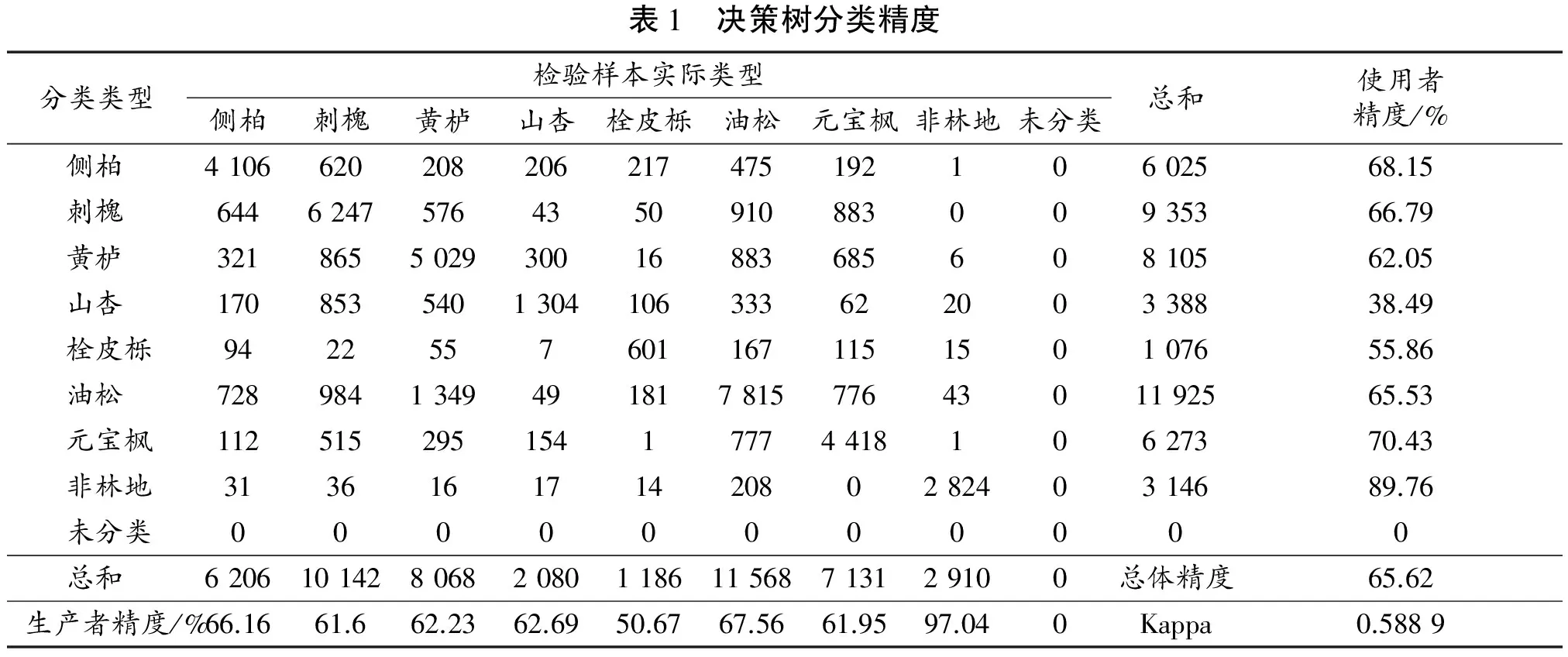
表1 决策树分类精度分类类型检验样本实际类型侧柏刺槐黄栌山杏栓皮栎油松元宝枫非林地未分类总和使用者精度/%侧柏410662020820621747519210602568.15刺槐6446247576435091088300935366.79黄栌32186550293001688368560810562.05山杏170853540130410633362200338838.49栓皮栎9422557601167115150107655.86油松72898413494918178157764301192565.53元宝枫1125152951541777441810627370.43非林地3136161714208028240314689.76未分类00000000000总和62061014280682080118611568713129100总体精度65.62生产者精度/%66.1661.662.2362.6950.6767.5661.9597.040Kappa0.5889
2) 支持向量机分类的总体精度为62.42%,Kappa系数为0.552 8。非林地的分类精度最高,林地中,元宝枫、油松和侧柏的精度较高,山杏、黄栌和栓皮栎的精度较低,尤其是山杏,其用户精度只有21.97%(表2)。

表2 支持向量机分类精度分类类型检验样本实际类型侧柏刺槐黄栌山杏栓皮栎油松元宝枫非林地未分类总和使用者精度/% 侧柏4021611194130935633810565171.16 刺槐1324625066721217755149700967864.58
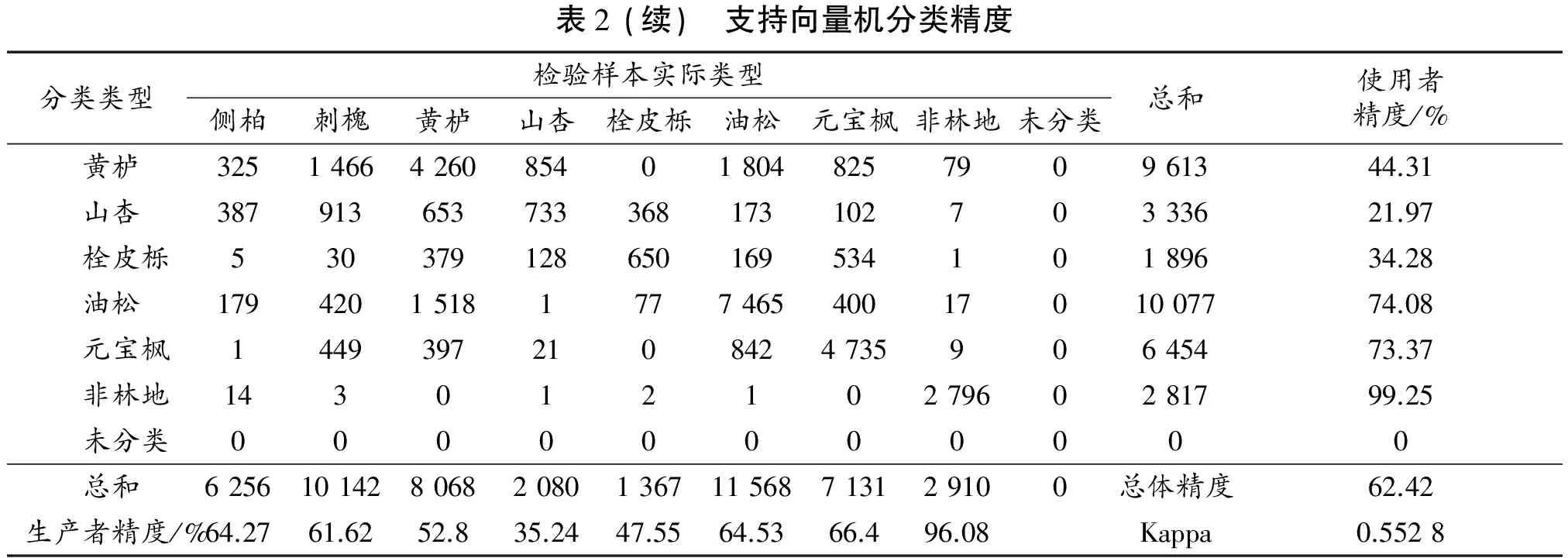
表2(续) 支持向量机分类精度分类类型检验样本实际类型侧柏刺槐黄栌山杏栓皮栎油松元宝枫非林地未分类总和使用者精度/% 黄栌3251466426085401804825790961344.31 山杏38791365373336817310270333621.97 栓皮栎53037912865016953410189634.28 油松179420151817774654001701007774.08 元宝枫1449397210842473590645473.37 非林地1430121027960281799.25 未分类00000000000 总和62561014280682080136711568713129100总体精度62.42生产者精度/%64.2761.6252.835.2447.5564.5366.496.08Kappa0.5528
3) 面向对象分类的总体精度为64.27%,Kappa系数为0.580 2。非林地的分类精度最高,林地中,油松的分类精度最高,栓皮栎的分类精度最低,不同树种间分类精度的差异相对较大(表3)。
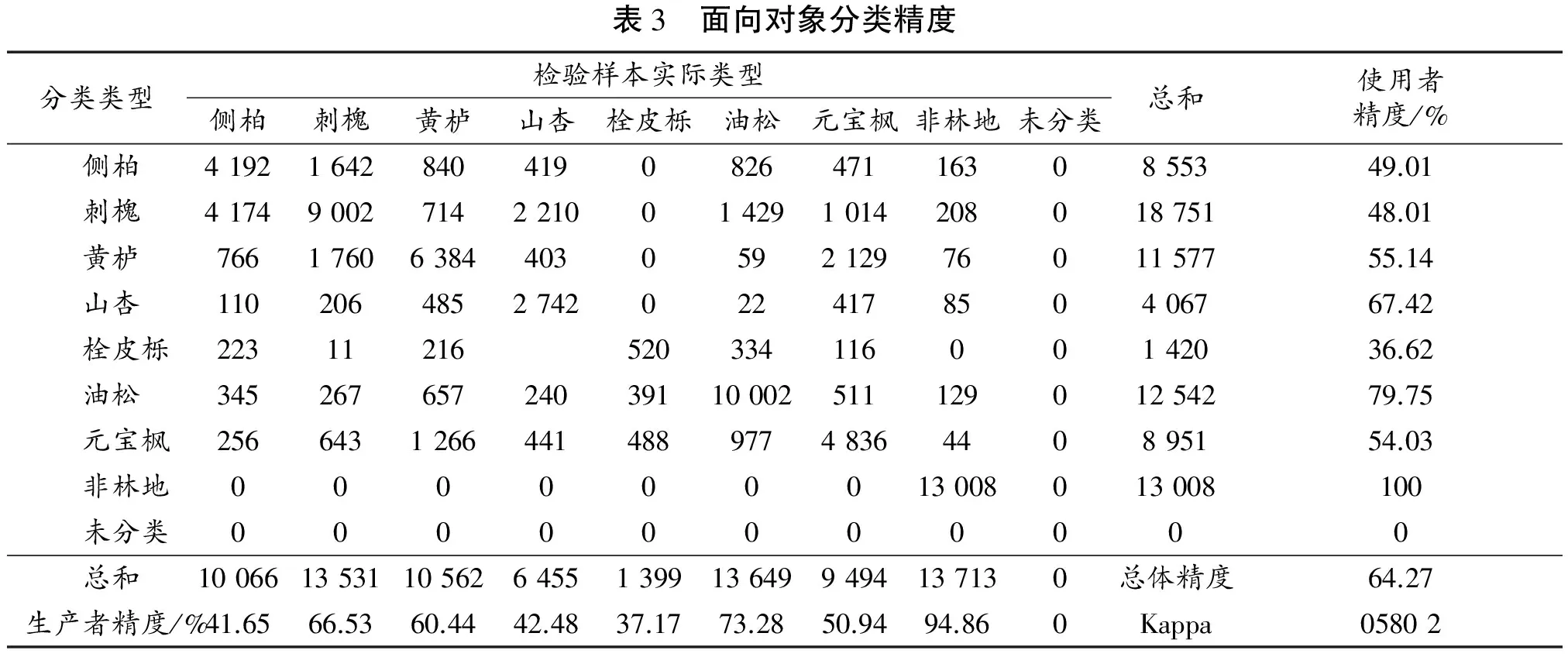
表3 面向对象分类精度分类类型检验样本实际类型侧柏刺槐黄栌山杏栓皮栎油松元宝枫非林地未分类总和使用者精度/% 侧柏4192164284041908264711630855349.01 刺槐41749002714221001429101420801875148.01 黄栌7661760638440305921297601157755.14 山杏1102064852742022417850406767.42 栓皮栎2231121652033411600142036.62 油松3452676572403911000251112901254279.75 元宝枫25664312664414889774836440895154.03 非林地000000013008013008100 未分类00000000000 总和10066135311056264551399136499494137130总体精度64.27生产者精度/%41.6566.5360.4442.4837.1773.2850.9494.860Kappa05802
5 讨论
1) 根据野外实测光谱以及ROI样本在光谱、地形、植被指数和纹理特征上的统计结果,各树种在不同的特征指标上均有差异,某些特定树种在一些指标上与其他树种有较显著的差异。在野外实测光谱中,黄栌的反射值最高,元宝枫次之,侧柏和油松的反射值最低,但二者极为相近。根据ROI样本在地形特征上的统计结果,元宝枫和刺槐一般分布在海拔高于450m的地区,油松一般分布在海拔低于450 m的地区;元宝枫一般分布在阴坡和半阴坡,侧柏和刺槐一般分布在阳坡和半阳坡,这符合树木的生长习性。在植被指数特征中,林地与非林地可以从NDVI上区分,而林地内部各树种在RVI和PVI上的差异更为明显。阴影区和非阴影区树种在纹理特征上差异较大,在对比度指标中,非阴影区元宝枫的均值显著高于其他树种,在二阶矩指标中,阴影区元宝枫显著高于其他树种,而非阴影区的元宝枫显著低于其他树种。
2) 在基于像元的方法中,树种多呈带状分布,在面向对象的方法中树种成块状分布。同时,从影像上可以比较明显看出同样为基于像元的分类方法,支持向量机的分类结果中树种有大面积成片分布,而决策树则存在很多碎斑,决策树分类可能存在过拟合现象,但支持向量机的分类结果中同类树种的大面积分布与实际情况不符。
3) 根据林业小班调查数据和实地探查的结果,油松一般分布在海拔较低的地区,很多分布在非林地的周围,分类结果与实际情况相符。基于像元的分类方法对侧柏和元宝枫的分类更符合实际分布,而面向对象分类的结果不准确。刺槐在一些区域内存在纯林的大面积分布,在决策树分类中,虽然其分类精度较高,但仍存在过拟合现象。黄栌在决策树分类的结果更符合实际分布,其余两种方法的结果与实际差异较大,且在支持向量机分类中,黄栌的范围明显大于实际范围。山杏和栓皮栎在三种方法中分类精度都很低,但面向对象的分类结果更符合这两种树种的实际分布情况,从小班数据上看,这两类树种的斑块数很少,且分布比较零散稀疏,在样本选择时会存在一定问题;同时,这两类树种样本在统计特征上没有与其他树种产生较大差异,这也是分类精度较低的原因之一。
6 结论
1) 决策树分类的总体分类精度为65.62%,Kappa系数为0.588 9;支持向量机分类的总体分类精度为62.42%,Kappa系数为0.552 8;面向对象的分类方法总体分类精度为64.27%,Kappa系数为0.580 2。决策树分类的总体精度更高。
2) 对于复杂地形条件下的森林植被分类而言,仅从单一的分类特征上进行分类,其精度较低,受“同物异谱”和“同谱异物”的影响较大,而构建多维度特征进行分类,可以在一定程度上解决这类问题,提高分类精度。
[1] 李国清.南方山地丘陵森林主要树种遥感信息提取研究[D].福建:福建农林大学,2009.
[2] Bruzzone L,Carlin L.A multilevel Context-based System for Classification of Very High Spatial Resolution Images[J].IEEE Transactions on Geoscience and Remote Sensing,2006,44(9):2587-2600.
[3] 张海霞,卞正富.遥感影像植被信息提取方法研究及思考[J].地理空间信息,2007,5(6):65-67.
[4] Kontoes C,Wilkinson GG,Burrill A,etal.An Experimental System for the Integration of GIS Data in Knowledge-based Analysis for Remote Sensing of Agriculture[J].International Journal of Geographical Information Systems,1993,7(3):247-262.
[5] 陈艳华,张万昌.地理信息系统支持下的山区遥感影像决策树分类[J].国土资源遥感,2006(1):69-74.
[6] 张锦水,何春阳,潘耀忠.基于SVM的多源信息复合的高空间分辨率遥感数据分类研究[J].遥感学报,2006,10(1):50-57.
[7] 陈君颖,田庆久.高分辨率遥感植被分类研究[J].遥感学报,2007,11(2):221-227.
[8] Baatz M,Schape A.Object-oriented and Multi-scale Image Analysis in Semantic Networks[C].In:Proc of the 2nd International Symposium on Operationalization of Remote Sensing,1999.
[9] 马浩然.基于多层次分割的遥感影像面向对象森林分类[D].北京:北京林业大学,2014.
[10] 熊轶群,吴健平.面向对象的城市绿地信息提取方法研究[N].华东师范大学学报:自然科学版,2006(4):84-90.
[11]苏簪铀,邱炳文,陈崇成.基于面向对象分类技术的景观信息提取研究[J].遥感应用,2009,10(2):42-46.
[12]杨飞,刘丽峰,王学成.基于面向对象方法和SPOT5的丘陵山区林地分类研究[J].林业资源管理,2014,10(5):92-99.
[13]许章华,刘健,余坤勇,等.阴影植被指数的构建及其在四种遥感影像中的应用效果[J].光谱学与光谱分析,2013,33(12): 3359-3365.
[14] Qi J, Chehbouni A, Huete AR.etal.A Modified Soil Adjusted Vegetation Index[J].Remote Sensing of Environment,1994(48):119-126.
[15]史忠植.高级人工智能(第二版)[M].北京:科学出版社,2006.
[16]何灵敏,沈掌泉,孔繁胜.SVM 在多源遥感图像分类中的应用研究[J].中国图象图形学报,2007,12(04):648-654.
[17]Cortes C, Vapnik V.Support-Vector Networks[J].Machine Learning,1995,20(3):37-297.
[18]张友静,高云霄,黄浩,等.基于 SVM 决策支持树的城市植被类型遥感分类研究[J].遥感学报,2006,10(2):191-196.
[19]常春艳,赵庚星,王凌,等.滨海光谱混淆区面向对象的土地利用遥感分类[J].农业工程学报,2012,28(5):226-231.
[20]张秀英,冯学智,江洪.面向对象分类的特征空间优化[J].遥感学报,2009,13(4): 664-669.
[21]陶超,谭毅华,蔡华杰.面向对象的高分辨率遥感影像城区建筑物分级提取方法[J].测绘学报,2010,39(1): 39-45.
[22]王新辉.面向对象的高分辨率影像香榧分布信息提取研究[D].浙江:浙江大学,2008.
[23]韩凝,张秀英,王小明,等.基于面向对象的IKONOS影像香榧树分布信息提取研究[J].浙江大学学报,2009,35(6):670-676.
[24] Congalton RG.A review of Assessing the Accuracy of Classifications of Remotely Sensed Data[J]. Remote Sensing of Environment. 1991,37(1):35-46.
StudyonTreeSpeciesRecognitionMethodsBasedonMulti-DimensionalFeatureofHighResolutionRemoteSensingImage
JIN Mingming,WANG Ruirui,ZHENG Xin,KOU Longxuan,YANG Zhiyuan,ZHOU Yannan
(The College of Forestry of Beijing Forestry University, Beijing 100083,China)
Taking the Xishan Experimental Forest Farm in Beijing as the research area , we established the spectral features, topographic features, vegetation index features, texture features and morphological features of the tree species based on the Worldview-2 remote sensing data, established knowledge about mountain forest tree species recognition. Image classification based on pixel and object-oriented methods were used in this study. In the pixel-based classification method, decision tree classification and support vector machine classification were chosen. In the object-oriented method, the image was segmented by edge detection and classified by k-nearest neighbor method. The overall classification accuracy of the decision tree was 65.62% and the Kappa coefficient was 0.5889. The overall classification accuracy of the support vector machine was 62.42% and the Kappa coefficient was 0.552 8. The overall classification accuracy of the object-oriented method was 64.27% and the Kappa coefficient was 0.5802.
tree species recognition;remote sensing;multi-dimensional features;decision tree;support vector machines;object-oriented
2017-04-14
北京市大学生科学研究与创业行动计划(S201610022013);中央高校基本科研业务费专项资金资助(YX2014-09)。
靳茗茗(1994-),女,北京林业大学林学院地理信息科学专业本科生。
王瑞瑞(1983-),女,北京林业大学林学院副教授,主要研究方向为林业遥感智能信息提取。
TP 392
A
1003-6075(2017)03-0030-07
10.16166/j.cnki.cn43-1095.2017.03.008
猜你喜欢
农业工程学报(2022年12期)2022-09-09
世界科学技术-中医药现代化(2021年8期)2021-12-21
中国林业产业(2021年5期)2021-12-14
民主(2019年4期)2019-08-15
电子制作(2019年7期)2019-04-25
吉林农业(2019年9期)2019-01-06
数码世界(2018年10期)2018-12-19
电子制作(2018年16期)2018-09-26
电子制作(2017年24期)2017-02-02
农村农业农民·B版(2016年12期)2017-01-11
