
基于多特征组合的SVM新闻文本情感分析
2018-02-05 09:02张锦锋重庆邮电大学通信与信息工程学院
数码世界 2018年1期
张锦锋 重庆邮电大学通信与信息工程学院
1 基于词向量的情感词典扩充方法
谷歌公司开发的Word2vec是一款主流的开源Deep Learning学习工具[1-2]。该工具可以将词语转化为向量,利用深度学习的方法,将输入的文本内容转化为M维向量空间中的向量运算,通过训练,输出为词汇向量的集合,文本语义上的相似度表示向量空间上的相似度。通过处理之后的向量能够进行自然语言处理相关的研究,本文利用词向量计算未知情感词和来自Sentiwordnet情感词典的情感词汇的余弦值来判断其情感得极性,从而来扩充情感词典。
2 基于特征组合的SVM文本情感分析
2.1 文本预处理
文本预处理主要是对文本进行分词,剔除情感色彩不明显的虚词,并对文本词性标注,从而使得计算机能够识别文本。文本预处理主要涉及文本分词、停用词处理以及词性标注等操作。英文中单词之间是以空格或者标点符号分割的,利用脚本语言Python同时调用开源工具NLTK易于实现英文文本中的分词以及词性标注。
2.2 文本表示模型
本文选择向量空间模型(VectorSpaceModel)。VSM基本思想是将文本文档看成由一组有区分文本情感类别能力的词或者短语特征项构成,每个特征项的权重是根据该特征对文档情感分类的重要程度计算而来的。例如向量空间中表示文本d的一个n维向量如公式(1)所示。
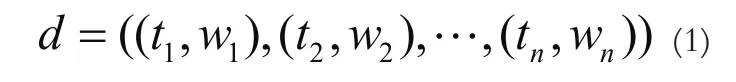
2.3 特征提取与特征选择
文本特征被认为是文本表示时可处理的最小单位。特征提取的优劣间接影响到分类模型的分类效果,为了最终训练一个性能好的SVM模型,本文选提取文本特征包括bigram、情感词、POS、否定词、程度副词以及特殊标点符号。
特征选择就是从原始特征项中选出可以用尽量少数目、能最大化的表示文本信息而且尽可能区别于其他类别文本的特征项。本文选择卡方检验(CHI)表征特征与类别的相关度。
2.4 支持向量机(SVM)分类算法
Mullen和Collier[3]基于短语语义倾向性信息、形容词、文本主题知识等多种信息源,采用支持向量机模型对电影评论进行情感分类。Gamon[4]利用对数似然比进行特征选择,使用支持向量机模型对顾客反馈数据进行情感分析。
支持向量机算法(Support Vector Machines, SVM)是一种二类分类模型。支持向量机的学习策略就是最大间隔化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。为了描述的便利,本部分只考虑二分类问题,如图1所示,存在分类面(H1、H2)可将两类数据分开,距离训练数据最远的分类面被SVM认为是最优分类面(H),该最远距离称为几何间隔(Margin),支持向量就是距离最优分类面最近的点(图1中颜色较深的点)。
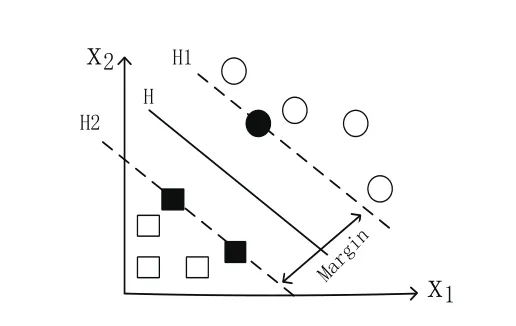
图1 支持向量机原理图
3 实验与结果分析
3.1 评价指标
本次实验使用信息检索领域的准确率P[5]作为为评价指标,针对分类问题中的各类分别计算,从而来验证实验效果。计算公式如下:

其中a表示正确判断为积极评论的数量,b表示将消极评论误判为积极评论的数量。
3.2 实验数据准备
本文利用网络爬虫从来自VOA(VoiceOfAmerican)、BB C(BritishBroadcastingCorporation)网站抓取新闻文本评论经过清洗后作为实验数据,干净的新闻文本评论数据共计24000条,其中积极评论数量和消极评论数量各占一半。本文从两万多条数据中选取20000条评论数据作为训练集,4000条评论数据作为测试集。
本文积极评论和消极评论的样本数量相等,训练数据样本是均衡的,这样训练出来的模型比较有说服力。当输入的积极和消极样本数量不平衡,容易导致模型分类到其中一个类别的概率较大,如此模型的分类性能指标偏差。
3.3 实验结果分析
由于程度副词、否定词和标点符号单独作为分类模型的特征没有实际的意义,所以需要和情感词搭配起来使用。
说明:特征1:词性
特征2:情感词
特征3:POS+情感词
特征4:POS+情感词+bigram
特征5:POS+情感词+bigram+否定词
特征6:POS+情感词+bigram+否定词+程度副词
特征7:POS+情感词+bigram+否定词+标点符号
作为对比试验,该实验测试SVM(SVC、LinearSVC、NuSVC)、朴素贝叶斯 NB(BernoulliNB、MultinomiaNB)和逻辑斯蒂回归(LogisticRegression)三类五种经典机器学习方法对文本情感分类性能的影响,使用CHI特征选择方法。实验如表1所示。
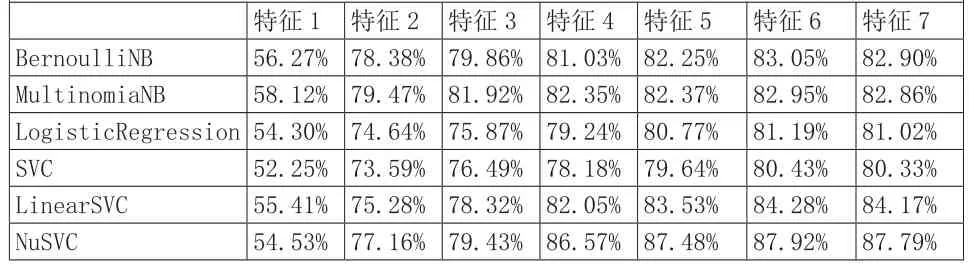
表1 不同分类器在不同特征组合下的分类准确率
由表1可知,特征6即词性、情感词、bigram、否定词和程度副词的组合特征作为分类的特征时,分类效果最好,其中NuSVC的分类准确率达到87.92。分析7个特征可知,其中情感词的作用最大,对于NuSVC基于特征1分类准确率提高了22.63%,其次,词性特征使得准确率提高了2.27%,bigram特征使准确率提高了7.14%,否定词对分类效果也起到一定的作用,使分类准确率提高了0.91%,程度副词同样有一定效果,分类准确率提高了0.42%,然而作为特征的特殊符号,使得分类准确率稍微有些下降,说明特殊符号不适合作为SVM分类模型的特征。
4 总结
本文提出的基于机器学习算法SVM结合扩充情感词典,多特征的组合包括POS、情感词、bigram、否定词、程度副词等语言学知识,使用VOA、BBC新闻评论语料,通过组合特征训练文本情感分类模型,进行新闻评论文本情感分类模型的性能评估,从而验证组合特征分类性能。试验表明组合特征6使SVM分类较其他算法在分类准确率上有一定的优势,准确率达到87.92%。
[1]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[C].Proceedings of Workshop at International Conference on Learning Representations, 2013.
[2]Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26: 3111-3119.
[3]Mullen, T., and Collier, N. Sentiment analysis using support vector machines with diverse information sources.In Proceedings of EMNLP. 2004, 4: 412-418.
[4]Gamon, M. Sentiment classification on customer feedback data: noisy data, large feature vectors, and the role of linguistic analysis. In Proceedings of the 20th international conference on Computational Linguistics. Association for Computational Linguistics, 2004.
[5]Kumar S, Gupta P. Comparative analysis of intersection algorithms on queries using precision, recall and f-score[J].International Journal of Computer Applications, 2015,130(7): 28-36.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
娃娃画报(2019年8期)2019-08-05
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
高中生学习·高三版(2014年3期)2014-04-29
