
多维空间中基于模式的移动对象轨迹预测①
2018-02-07 03:23章梦杰邵培南于铭华
计算机系统应用 2018年1期
章梦杰,邵培南,于铭华
(中国电子科技集团公司第三十二研究所,上海 201800)
近些年来,随着机器学习等相关技术的广泛使用,人们对不确定性事件的预测也变得更加精确.现代战争中,能否准确地预测敌方目标的活动从而快速定位敌方目标是取得战争胜利的关键.
在对移动对象轨迹的研究中,移动对象大致可以分为两种类型:运动道路非受限的移动对象(如飞机、舰船)和运动道路受限的移动对象(如城市道路中的车辆或人)[1-3].一般来说,对移动对象的轨迹进行预测主要包括三个方面:重现历史轨迹、实时轨迹和未来轨迹的预测,其中移动对象未来轨迹预测方法主要分为基于欧式空间的轨迹预测和基于路网受限的轨迹预测.目前,对移动目标轨迹预测的研究方法主要有以下几种:文献[4]提出了基于曲线拟合技术对目标轨迹预测,此方法首先由人工圈出要跟踪的移动目标,然后利用其历史轨迹点数据对其以后目标位置进行预测,该方法每进行一个目标位置的预测就要进行曲线拟合,运算量很大,而且拟合函数的多项式次数难以确定;文献[5]提出了利用卡尔曼滤波预测船舶航行轨迹,卡尔曼滤波是以最小均方误差估计的最佳准则,来寻求一套递推估计的算法,但该方法只考虑到当前目标位置对预测目标位置的影响,所以得到的预测位置不够精确;文献[6]提出了基于神经网络的预测方法,该方法利用遗传算法对BP神经网络的参数进行优化,在此基础上进行的目标轨迹预测,该算法同样存在网络训练频繁和运算时间长等问题.基于此,本文提出了一种新的轨迹预测方法来对道路非受限的移动对象轨迹进行预测.
现如今,研究人员主要通过挖掘移动对象轨迹的频繁模式,然后通过各频繁模式组合来进行移动对象轨迹的预测[7-9].然而现有的相关研究大都是基于路网受限的轨迹预测[10],而对非受限空间的轨迹预测的相关研究还比较少.本文所采用的方法就是对非受限空间中移动对象轨迹的预测,通过对轨迹的相关属性预测来实现对轨迹的预测.具体来说,主要对以下三个方面进行研究分析:首先对移动对象历史轨迹进行聚类分析[11],分类出不同的轨迹训练集;然后根据聚类后的轨迹训练集采用多核并行技术建立移动对象加速度和轨迹偏转角的频繁模式;最后通过对移动对象加速度和轨迹偏转角的预测来实现移动对象轨迹的预测.
1 基本概念及模型框架
本节首先对所使用的轨迹数据结构进行简要说明,然后介绍本文所提出模型的框架及工作原理.
描述移动对象时空轨迹的数据库D,该数据库中存放着移动对象不同时间序列的位置信息,其中位置点信息由来表示,位置点在一定时间的有序集合构成了一条完整的目标轨迹,由来表示.
下面对本研究中所使用的移动对象的轨迹数据集作如下说明.
说明2.轨迹数据集.在多维空间进行建模,轨迹数据集表示为:其中tr1代表其中一条轨迹.
说明3.加速度计算.本文中由于移动对象轨迹上的位置点的时间间隔较小,高速巡航的移动目标的速度基本保持不变,为了方便计算,我们假设相邻位置点之间移动对象的运动为匀加速运动.由于位置点信息中已经包括了移动对象的当前速度,所以计算两点之间的加速度可以用相邻位置点之间的速度差和时间差的比值表示.加速度A的计算公式如下所示:

说明4.偏转角计算.偏转角表示移动对象在当前位置点向下一位置点运动的方向角.
如图1所示,已知点p1,p2,p3表示移动对象的三个连续的位置点,直线p1p2与直线p2p3所构成的夹角称为开放角,它的补角称为偏转角,即为位置点p2的偏转角.可以利用三个连续位置点来计算出相应子轨迹的偏转角α.求取偏转角α的公式如下所示:
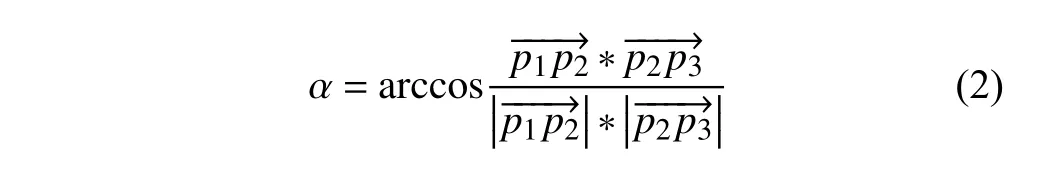
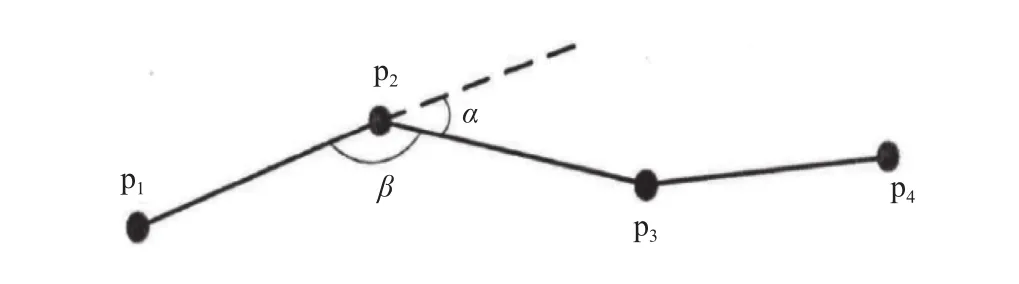
图1 轨迹的偏向角和开放角
说明5.特征点提取.如果移动对象在某一位置点的偏转角大于一定阈值则该位置点就是轨迹的特征点.移动对象轨迹数据是通过相隔固定时间采集得到的时间序列位置点,所以一条轨迹是由大量的时间序列的位置信息点.其中有很多冗余的位置点,例如一条直线子轨迹上的多个点都是冗余的.所以在训练模式之前需要对特征点进行提取.
说明6.轨迹聚类.聚类是数据挖掘过程中最常用和最重要的技术手段之一,该技术能从海量的轨迹数据中挖掘出精简而有用的信息.本文中的原始数据的轨迹形状多种多样,例如圆形轨迹,抛物线轨迹,直线轨迹等等,聚类的任务就是根据数据之间的相似性将相似数据组合在一起.其中相似的对象构成的组被称为簇(Cluster),同一个簇中的对象彼此相似,不同的簇中的对象彼此相异.轨迹聚类可以去除噪声数据,提高算法的准确性,提高算法的时间性能.本研究在度量轨迹相似性时只考虑轨迹的空间属性.
本文所提出模型的具体流程如图2所示,其工作原理如下.
利用转向角筛选算法和最小描述长度算法对轨迹集进行特征点筛选.
利用轨迹聚类算法对轨迹集进行轨迹聚类,分类出若干个轨迹训练集.
采用多核并行技术根据得出的轨迹训练集进行加速度和偏向角的模型训练,分别建立基于轨迹的加速度和转向角的频繁模式的预测模型.
利用相似度比较,结合历史轨迹以及移动对象加速度和轨迹偏转角的预测模型进行目标移动对象轨迹预测.
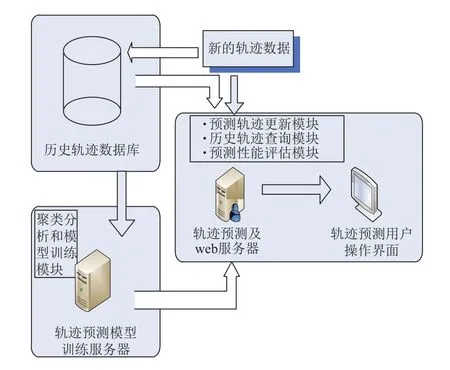
图2 系统模型框架图
历史轨迹数据库:过去采集到的历史轨迹数据作为结构化数据存放在Mysql数据库.实时的新到移动对象轨迹数据,经过清洗后也将存入历史轨迹数据库中.
轨迹预测模型训练服务器:该节点会从历史轨迹数据库中获取轨迹数据,对不同运动模式轨迹数据进行初步聚类分析.在此基础上,采用多核并行迭代训练生成加速度和偏转角的频繁模式的预测模型.
轨迹预测及web服务器:新的轨迹数据进来(仍然是通过结构化数据接口),经过清洗后流入该节点的轨迹预测模块,它使用训练好的预测模型,预测未来连续一段时间的轨迹点,并计算每步的预测误差.同时该节点还提供web服务功能,使得用户可以通过互联网在浏览器端进行多活动目标的轨迹管理与轨迹监察.
2 生成训练集
2.1 轨迹特征点选取
在采集目标轨迹的过程中,有许多冗余的位置点,在对轨迹进行聚类之前需要对轨迹进行轨迹特征点的选取.我们需要在进行轨迹特征点选取的过程中同时考虑轨迹的精确性和简洁性.本文采用文献[12]提供的特征点选取算法进行特征点选取,其中轨迹特征点选取分为两个过程,第一步:计算每个轨迹位置点上的偏转角,计算方法见公式(2)所示,并设置转向角阈值,其中大于阈值的位置点将成为候选特征点,小于阈值的位置点将直接被删除;第二步:采用最小描述长度算法对轨迹做进一步处理,筛选出来的轨迹点即为轨迹特征点.
2.1.1 最小描述长度
显然仅仅通过偏转角筛选得到的特征点集还不够简洁,还需要进一步处理.为了在轨迹划分中得到精确性和简洁性之间的最优的解,本研究采用信息论中的最小描述长度(Minimum Description Length,MDL)理论对候选集进一步筛选.MDL的基本原理是对于一组给定的实例数据D,如果要对其进行保存,为了节省存储空间,一般采用某种模型对其进行编码压缩,然后再保存压缩后的数据.同时也要保存所用模型来进行数据的恢复.所以需要保存的数据有两部分构成,我们将总的数据长度成为总描述长度.最小描述长度原理就是使得总描述长度最小的模型.
本文中的实例数据为位置点信息,我们可以通过面积来压缩位置点信息.则总描述长度由两部分组成:L(H)和L(D|H).D是要描述的数据,H是面积信息.L(H)是面积信息的开销,L(D|H)是在H这种假设下描述数据D的开销.最终采用局部最优替代全局最优的轨迹划分方法来寻找一个最好的H来描述D使得L(H)和L(D|H)总开销最小.假设原始轨迹如图3所示,首先通过偏转角筛选,
得到的特征点为p1,p3,p4,p5,p6,p7,p8,p10,p12.然后通过MDL方法进一步筛选得到最终的轨迹特征点集p1,p4,p6,p9,p12.

图3 经过特征点提取之后的轨迹
2.2 轨迹聚类
采集的大量轨迹经过特征点提取之后,还需要对轨迹数据进行适当的聚类分析,分类出若干个训练集.对目标轨迹进行聚类就是将大量的轨迹数据进行分类处理,从而形成一个相对简单可用的知识,继而对目标轨迹进行准确地轨迹分类、预测.轨迹聚类一般分为轨迹的相似性度量和相似性度量基础上的轨迹聚类.本研究在度量轨迹相似性时只考虑轨迹的空间属性.通过轨迹之间的空间相似度来进行轨迹聚类以获得可靠的模型参数.通过对轨迹进行聚类来分类出若干的训练集.下面我们首先介绍算法的相关概念,然后介绍算法的主要思想.
算法的相关概念:本文中ε表示轨迹的密度半径,Mintrs表示轨迹的密度阈值,即核心轨迹区域内轨迹的最少条数.定义如下所示.
定义1.如图4所示,在移动对象时空轨迹的数据空间中,任意轨迹的领域是由与该轨迹的空间距离不超过ε的所有轨迹构成的区域.

图4 核心轨迹搜索区域
定义2.在移动对象时空轨迹的数据空间中,任意轨迹的领域中轨迹的个数大于等于Mintrs,则轨迹称为核心轨迹.
算法的主要思想如下:首先将所有的轨迹标记为未聚类,然后顺序读取未聚类的轨迹,通过参数ε和MinTrs判断该轨迹是否是核心轨迹.如果该轨迹是核心轨迹,则该核心轨迹的ε邻域的所有轨迹形成一个新簇并用该核心轨迹标记.如果不是核心轨迹则进行下一条轨迹的操作.然后这个簇通过ε邻域内的核心轨迹不断向外扩展,直到簇不再增长为止,最后所有未标记的轨迹作为一个新的簇存在.以上过程迭代执行直到所有的轨迹都被标记到簇中为止.

算法 1.聚类相关算法输入:(1)经过特征点提取后的轨迹数据(2)密度半径参数ε和最小轨迹阈值Mintrs输出:若干轨迹簇步骤:Input trajectory List:D=;a)For tri in D b)lable tri as uncluster//首先将所有轨迹标记的未标记c)END FOR d)ClusterID = 0 e)For tri in D f)IF tri is unclustered THEN g)Compute t = N(tri)h)IF t >= Mintrs i)assign ClusterID to all trj//如果该轨迹是核心轨迹,则标记该区域内 所有轨迹j)ExpandCluster()//扩展该区域内的其他轨迹,执行同样操作k)ClusterID ++l)ELSE m)tri put D0//如果轨迹既不是核心轨迹也未标记则单独保存在D0簇中n)END IF o)END
3 频繁模式搭建
在搭建模型的过程中,模式的选取是搭建模型的关键.本文采用区间的形式来进行模式的表示.加速度我们选择[0~2]为单位1,转向角我们将方向角划分为九等份,即[0~40]为单位 1.
3.1 加速度模式搭建
本文规定轨迹当前点和轨迹预测点的时间差为1秒钟,短时间内高速巡航的移动目标加速度保持不变或者变化较小,所以可以假定两点之间目标的运动状态是匀速或者匀加速运动,则轨迹中两个连续位置点之间速度差和时间差的比值就是两点间的加速度.经过反复试验,加速度模式选择三阶的加速度模式能得到很好的效果,model=[A1-A2-A3],其中model是加速度模型中的一个模式,A1,A2,A3是三个连续子轨迹上的加速度.对加速度模式的划分如表1所示.

表1 加速度频繁模式表
3.2 转向角模式搭建
对移动目标轨迹的预测不仅要考虑目标的速度,同时还需要对目标进行转弯预测.通过转向角的筛选之后,每一个位置点都会有一定的转向角,如图5所示.同样,偏转角模式选择三阶的偏转角模式能得到很好的效果,model = [α1-α2-α3],其中 model是偏转角模型中的一个模式,α1,α2,α3是三个连续位置点上的偏转角.偏转角的计算公式见第2节公式(2).本文通过预测转向角的大小来进行转弯预测,对转向角模式的划分如表2.

表2 转向角频繁模式表

图5 转向角预测

算法3.模型训练相关算法输入:根据目标内码得到的单个目标的所有轨迹D=输出:关于加速度的模式angleModel步骤:Input trajectory List:D=;a)For tri in D b)getAngleModel(tri);c)End for;d)/*************************/e)getAccModel(tri);f);//输入一条轨迹序列g)Key1=getKey();//五个点确定一个长度为3的Key h)Model=putIntoModel(key);//将模式写出模型i)重复f、g;j)end
4 轨迹预测模型及算法实现
4.1 工作原理
在上节中,我们通过训练分别得到了加速度和转向角的模型.根据目标移动对象已经产生的实时轨迹,基于各训练集聚类对目标移动对象的轨迹数据进行轨迹相似度并行计算,找出最大相似度的轨迹数据并记录该轨迹所在的子训练集.基于此,我们就可以利用该子训练集训练的加速度和偏转角模型结合传来的目标移动对象轨迹分别预测出目标移动对象的加速度和转向角.然后结合最大相似度的历史轨迹以及移动对象加速度和轨迹偏转角的预测模型得出目标移动对象的加速度和转向角.最后通过加速度和偏转角求出目标移动对象预测点的位置信息.
4.2 算法实现

算法4.轨迹预测算法输入:训练轨迹数据集D1=测试轨迹数据集D2=输出:未来轨迹的位置点信息1.for tri in D1 2.trj=angleTurning(tri,angle)//经过偏转角算法进行特征点提取3.trk=DML(tri);//经过MDL算法进一步筛选4.D.add(trk)5.end for 6.set = Julei(D);//聚类分析产生若干的训练集7.Model=train(set);//模型训练,分别得到相应模型8.For i=0 to k 9.Point=Predict(model);//连续预测K步10.e[i]=mis(point,point0);//误差分析11.end
由于在本方法中两预测点的时间间隔很短,所以可以假定目标到下一个轨迹点是以一定的加速度a匀加速运动,这样可以通过加速度a求出目标移动对象在下一轨迹点的速度v,然后根据求出的转向角ɑ,求出速度在各个方向上的分矢量vx,vy,vz.最后根据如下公式求出下一时刻轨迹点坐标:

5 实验与性能分析
为了测试本文所提出的算法效果和性能,我们通过模拟移动对象轨迹数据进行了实验,来验证算法对轨迹的聚类效果和算法对轨迹的预测效果.同时采用普遍应用的回归算——卡尔曼滤波的预测算法,来进行实验.其中硬件的实验环境如下所示:
处理器:Intel(R)Core(TM)i5-4570 CPU@3.20GHz
内存:4.00 GB
软件环境:Eclipse+mysql.实验中进行的参数设置如表3所示.

表3 参数设置
本方法中实验参数的选取非常重要,直接影响到本方法的聚类和预测效果.本节我们设置了不同的实验参数,经过多次实验之后发现当ε=30和最小轨迹数MinTrs=15时,我们提出的方法聚类效果比较理想.算法对经过筛选的历史轨迹数据进行计算,最终检测出了8个簇,也就是8个子训练集.从实验得出的结果可知,随着移动对象测试轨迹数量的增加,本文算法的预测误差比较小,一直保持在 1 km以内,如果已知的目标轨迹相对较长,则算法预测精度相对较高并且比较稳定.通过分析实验结果可知:卡尔曼滤波预测算法的误差比本文提出的方法明显高出近20%以上,而且本文方法的精确度比卡尔曼滤波预测算法更为精确.原因是因为本文提出的预测算法对于处理较为复杂运动模式轨迹预测的精度较好,而实验中我们所模拟的目标轨迹数据大都是轨迹模式较为复杂且种类繁多,基于卡尔曼滤波的轨迹预测仅仅对轨迹进行线性回归预测,没有对不同的轨迹模式进行聚类分析,因此其预测误差很大 .轨迹预测结果如图6所示,通过实验结果可以看出,误差在500 m范围内最终的预测命中率能达到90%以上,误差在1KM范围内的最终预测命中率能达到98%以上.通过进一步合理设计加速度和偏转角的模式还能进一步提高预测命中率.

图6 轨迹预测示例图
6 结束语
通过实验对模拟数据进行分析发现,实验结果表明:该方法能够达到比较理想的预测效果.同时,该方法能够实现增量挖掘,预测精度和可靠性有了进一步提高,具有较高的实用.本文在已有算法基础上提出了一种新的轨迹预测方法,即基于模式的移动目标轨迹预测.经过对测试轨迹集进行实验的结果表明,误差在500 m范围内本预测方法最终的预测命中率能达到90%以上,而且预测时间相对较短.为了进一步提高轨迹预测的实时性要求,下一步工作我们将把该系统移植到Spark平台上.
1 章逸丰.快速飞行物体的状态估计和轨迹预测[博士学位论文].杭州:浙江大学,2015.
2 徐庆飞,张新,李卫民.二维空间中目标轨迹预测算法研究与分析.航空电子技术,2012,43(1):10–14.
3 徐肖豪,杨国庆,刘建国.空管中飞行轨迹预测算法的比较研究.中国民航学院学报(综合版),2001,19(6):1–6.
4 魏赛.基于曲线拟合的目标跟踪算法研究[硕士学位论文].合肥:安徽大学,2014.
5 何静.利用卡尔曼滤波预测船舶航行轨迹异常行为.舰船科学技术,2017,39(1A):16–18.
6 马国兵,张楠.一种基于神经网络的机动目标轨迹预测方法.青岛理工大学学报,2006,27(5):108–111.
7 赵越,刘衍珩,余雪岗,等.基于模式挖掘与匹配的移动轨迹预测方法.吉林大学学报(工学版),2008,38(5):1125–1130.
8 乔少杰,沈志强.PathExplorer:基于频繁模式的不确定性轨迹预测系统.中国计算机学会.第29届中国数据库学术会议论文集(B辑)(NDBC2012).合肥,中国.2012.5.
9 陈传运.云计算环境下时空轨迹频繁模式挖掘研究[硕士学位论文].南京:南京师范大学,2015.
10 袁晶.大规模轨迹数据的检索、挖掘和应用[博士学位论文].合肥:中国科学技术大学,2012.
11 乔少杰,金琨,韩楠,等.一种基于高斯混合模型的轨迹预测算法.软件学报,2015,26(5):1048–1063.[doi:10.13328/j.cnki.jos.004796]
12 何苗.移动对象的时空轨迹聚类算法研究[硕士学术论文].兰州:兰州大学,2013.
猜你喜欢
当代水产(2022年6期)2022-06-29
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
汽车观察(2018年12期)2018-12-26
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
金桥(2018年4期)2018-09-26
劳动保护(2018年8期)2018-09-12
舰船电子对抗(2017年6期)2018-01-11
