
基于大规模不平衡数据集的糖尿病诊断研究①
2018-02-07 02:41魏勋,蒋凡
计算机系统应用 2018年1期
魏 勋,蒋 凡
(中国科学技术大学 计算机学院,合肥 230022)
糖尿病是一种慢性非传染性疾病,主要包括1型糖尿病,2型糖尿病和妊娠型糖尿病.其中超过90%的患者为2型糖尿病.如果缺乏良好的干预和治疗,糖尿病患者有一定风险患上一系列并发症,进而影响健康甚至危及生命.并发症主要有致盲,肾衰竭,心脑血管疾病,中风以及截肢等.正是由于这些严重的并发症,糖尿病已经成为全球第四大致死疾病.
在过去几十年中,糖尿病发病率逐渐上升[1].根据WHO估计,2014年全球约有4.22亿糖尿病患者,而在1980年这个数字仅为1.08亿.在过去十年中,相比高收入国家,糖尿病在低收入和中等收入国家的发病率上升更加迅速.例如,在2015年中国拥有全世界最庞大的糖尿病患者群体,高达1.1亿人之多.绝大多数患者是2型糖尿病,主要是由肥胖(特别是腹部肥胖),缺乏锻炼以及不健康饮食导致[2].在某些国家,大约50%到80%的糖尿病患者从不关心他们的身体状况,除非出现严重的并发症.考虑到这种情况,早期的诊断显得十分必要且有意义[3].
最近研究指出,通过及时的筛查诊断,大约80%的2型糖尿病并发症能够避免或者延缓[2,3].然而单一的临床指标,如空腹血糖检查,不具备较高的敏感度,接近30%的糖尿病患者不会被查出[4].因此,智能的数据分析方法,比如数据挖掘和机器学习技术,对于精准地诊断糖尿病患者无疑具有很高的价值.近些年,已有研究人员应用了一些数据挖掘和机器学习的方法用于糖尿病诊断并取得较好的效果[5-13].
在过去,收集真实的医疗数据是比较困难的而且相当耗时.因此,之前的很多研究中用的数据集主要是来源于规模较小的公开数据集和调查问卷.随着信息技术的发展和大数据时代的来临,目前医疗数据的规模变得十分庞大,能够更好地反映真实情况.然而,真实的医疗数据往往存在类别不平衡的问题.在糖尿病诊断过程中,由于较低的发病率,数据集通常是不平衡的,即健康人群占据大多数,而糖尿病患者通常只占据很小的比例.在这种不平衡数据集中,传统的分类算法往往倾向于忽略少数类样本,难以有效地诊断出糖尿病患者.
本文提出一种集成模型:xEnsemble,能够解决类别不平衡问题并精准地诊断糖尿病患者.该方法基于EasyEnsemble[14]和 XGBoost[15],相比其他类似技术,能够取得更高的敏感度(Sensitivity),F值和G-mean值.本文后续内容如下:首先,简单介绍类别不平衡问题和常用的解决方法;然后,介绍xEnsemble方法的基本原理;接着详细阐述实验过程,包括数据集介绍、数据预处理过程、性能评估标准、实验设置、实验结果与讨论;最后,总结本文并指出进一步的研究方向.
1 类别不平衡问题
类别不平衡,也就是某些类的样本数量大于其他类别.在实际生活中,尤其是在医疗领域,类别不平衡问题十分常见.这种情形通常是由较低的发病率导致的.在某些情况下,不平衡比例(多数类样本数量与少数类样本数量之比)甚至高达106.在诊断过程中,如果不平衡数据没有经过适当的处理,分类器的性能将会受到严重的影响.例如:在一个不平衡比例为99的数据集中,即使分类器将所有样本都分类成多数类,分类器的准确率也能高达99%,然而所有少数类样本都被错分.特别地,在糖尿病诊断过程中,类别不平衡会使传统分类算法将大多数的糖尿病患者错误分类成健康人群,很可能会贻误良好的治疗机会.
目前存在许多方法解决类别不平衡问题.本文主要集中于两类方法:代价敏感学习方法与采样方法.代价敏感学习的一种常用实现方法是权重缩放法(rescaling),即通过提高少数类样本的权重来增加少数类被错分的代价.采样方法是一系列重构样本空间的方法.采样法有两种基本的实现方法:欠采样(undersampling)和过采样(over-sampling).欠采样通过减少多数类样本来创造一个规模更小的训练集;过采样则是增加少数类样本,形成一个规模更大的训练集.很明显,这两种方法都能降低不平衡比例,构建一个更加平衡的训练集.这两种方式都被证明能够有效地解决类别不平衡问题[16,17].欠采样能够缩短训练时间,然而会忽略潜在有用的信息;过采样通常需要更长的训练时间,并且有过拟合的风险[18,19].基于欠采样和过采样,研究者还提出了混合采样[20]和集成采样[14]的方法.混合采样即同时应用欠采样和过采样的方法;集成采样则是通过重复的欠采样,构建若干个平衡训练子集.
本文使用的数据集包含了数百万条记录,相对于常用的Pima公开数据集(768条记录),规模可以算是十分庞大.考虑到庞大的规模和有限的计算资源,本文主要关注基于代价敏感学习和欠采样的方法.
2 xEnsemble方法
为了构建一个高效的糖尿病诊断系统,首先需要采取适当的措施来解决类别不平衡问题.欠采样是一种有效的方法,然而这种方法会丢失大量潜在的有用数据.而且一次随机选取小规模的多数类样本将会增加样本方差.众所周知,一个优秀的分类模型需要同时具备较低的方差和较低的偏差.所以采样之后,我们需要一个强力的分类器去尽量拟合新样本来减少偏差.为了同时满足这两个要求,我们提出了一种集成模型:xEnsemble.此方法基于EasyEnsemble[14]和XGBoost[15],伪代码如算法1所示.为方便表示,本文将少数类样本视为正例,多数类样本视为负例.

算法1.xEnsemble 1.输入:2.P:正例样本集3.N:负例样本集4.n:采样子集数量5.si:每次训练XGBoost模型Hi的迭代次数6.步骤:7.for i=1 to n do 8. 随机从N中采样一个子集Ni,且|Ni|=|P|9. 使用Ni和P训练Hi,迭代si次10.end for 11.输出:∑12.
xEnsemble的主要思想为:通过重复有放回地对负例样本集采样,然后与正例样本集合并,生成n个平衡的训练子集;在每个训练子集上使用XGBoost算法拟合得到一个基分类器Hi,这样能够尽量学习负例样本集N的各个方面;最后将所有的基分类器集成起来,使用投票平均法构成最终的集成分类器H(x).明显可以看出,xEnsemble在上层使用了Bagging策略,此策略被证明能够有效地降低模型方差[21];在下层,xEnsemble使用了基于Boosting的方法来尽量拟合训练集,能够有效地减少偏差.与EasyEnsemble不同的是,xEnsemble使用投票法来决定类别,算法1中的表示集成模型的阈值,即需要多少票数可以判定某样本为正例.一般地,本文将设置为n/2.还有一点明显不同,xEnsemble采用XGBoost代替EasyEnsemble中的AdaBoost作为集成模型的基分类器.XGBoost可以并行操作,而AdaBoost只能串行处理,时间开销相对较大,不适合用来训练本文规模较庞大的数据集.
XGBoost是最近非常流行的一种基于树提升(tree boosting)的高效机器学习模型.它的算法实现是基于梯度提升框架(Gradient Boosting Framework).它提供了一种在特征粒度上的并行方法,能够迅速准确地解决许多数据科学问题[1].正是由于XGBoost的种种优点,我们将它作为xEnsemble的基分类器.xEnsemble的流程图如图1所示.
3 实验
3.1 数据集
本文使用的数据集来源于中国某省的卫生部门,包含了数百万人从2009年到2015的医疗信息.原始数据包含三张表:个人基本信息表,体检信息表和糖尿病管理信息表.个人信息表包含了个体的一些基本信息,比如性别,出生年月,家族病史等;体检信息表包含了个体的一系列医学临床指标,如身高体重,血常规,尿常规,肾功能检查,肝功能检查等;糖尿病管理信息表包含了糖尿病患者每次的随访记录.其中体检信息表是本文主要使用的数据.根据医学知识,我们初步从体检信息表中摘选了24项与糖尿病有关的属性.这24项属性的详细信息参见表1.而糖尿病管理信息表此处只用来标记某个个体是否患有糖尿病.
3.2 数据预处理
如表1所示,体检信息表中存在很多“脏数据”,而且有些属性有较高的缺失率.在训练模型之前,我们必须对这些数据进行预处理.
首先,清洗异常值.通过查阅相关资料,确定某个属性的参考范围,比如收缩压的参考范围为:90~180,此后通过两种途径来确定最后的合理范围:

图1 xEnsemble示意图

表1 体检信息表中24个属性的详细信息
(1)某些临床指标理论上符合正态分布,因此在统计意义上,[–3σ,3σ]区间能覆盖超过 99.7% 的值,即此区间外的值均视为异常值;
(2)将初始合理范围外的数据进行分箱操作,根据每个区域的占比情况确定合理范围.
然后,对缺失值进行处理.如表1所示,24个属性均有不同程度的缺失.针对这种情况,缺失率超过90%的属性直接忽略,小于20%的属性直接用均值填充,20%~90%之间的属性用SPSS分析其缺失类型,发现其缺失相关性很小,可以认为是完全随机缺失.一般地,我们用所有非缺失样本的均值进行填充.
经过预处理之后,我们最后保留了24个特征,其中6个特征来自个人信息表,分别为:性别,年龄,家族病史(父亲,母亲,兄弟姐妹,子女);另外18个特征来自体检信息表,分别为:心率,舒张压,收缩压,呼吸频率,腰围,BMI,吸烟量,饮酒量,空腹血糖,谷丙转氨酶,谷草转氨酶,总胆红素,血清肌酐,血尿素氮,总胆固醇,甘油三酯,低密度脂蛋白,高密度脂蛋白.考虑到疾病之间复杂的联系,对于家族病史这方面,我们从简处理:比如只有当父亲曾经患过糖尿病,父亲病史才被标记为1.
我们最初从体检信息表中检索某个个体时间最近的体检记录,再加上个人基本信息表的6个特征,总共24个特征构成样本.考虑到某些个体在2009~2015年之间具有多条体检记录,如果只是提取其最近的一条体检记录,无疑会损失大量的信息.尤其是某些临床指标通常具有较大的波动性,比如空腹血糖.因此,我们针对某个特征额外提取了3个相应的新特征:最大值,最小值和平均值.最终我们对12个临床指标采用这个操作:舒张压,收缩压,空腹血糖,谷丙转氨酶,谷草转氨酶,总胆红素,血清肌酐,血尿素氮,总胆固醇,甘油三酯,低密度脂蛋白,高密度脂蛋白.这新增的3×12=36个特征,缺失值也用所有非缺失样本的均值填充.最后特征数量为:6+18+36=60.
我们使用70%的样本作为训练集,剩下的30%作为测试集.在所有样本中,正例只有56 444个,占比2.9%,其余为负例.明显可以看出,样本存在严重的类别不平衡问题,不平衡比例为34.5.详细情况参见表2.
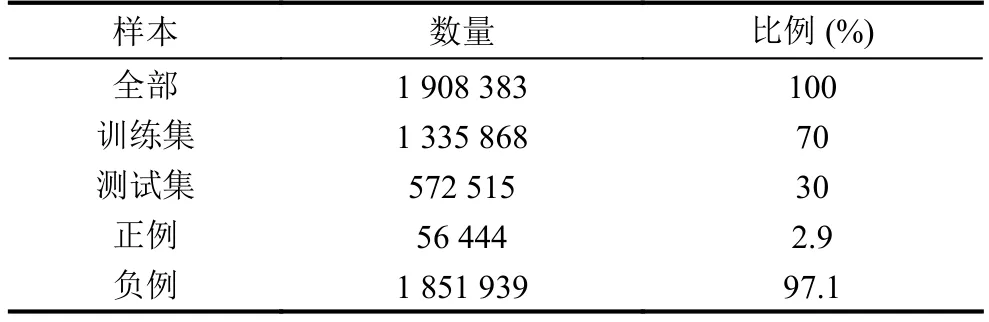
表2 样本情况
3.3 评价标准
如前所述,当数据存在类别不平衡问题或者错分代价不一致的时候,对分类器而言,错误率并非一个合适的评价标准.因此,本文使用F值和G-mean值作为分类器性能的评价标准.F值和G-mean值的计算均基于表3所示的混淆矩阵.

表3 混淆矩阵
考虑到本文中召回率(recall)相对精确率(precision)更加重要,我们进一步使用Fβ来评估性能.其中β值用来衡量召回率相对精确率的重要度.当β=1时,Fβ退化成标准的F1值;当β>1时,召回率影响更大;当β<1时,精确率影响更大.为了尽可能的降低FN的值,本文将β设置为3.Fβ和G-mean的定义如下所示:

3.4 实验设置
我们在训练集上使用5-折交叉验证和网格寻优方法来获得最佳参数.然后在测试集上运行,得到最终的Sensitivity,Fβ和G-mean值.实验主要分成两个步骤,第一步解决类别不平衡问题,第二步为分类.第一步使用5种策略,第二步使用6种分类器,总共30种模型.5种用于解决类别不平衡问题的策略如下所述.
1)Original:原始情况,不对负例样本进行任何操作,直接用来训练.此策略用来作为实验对比.
2)Cost-Sensitive(简称Cost):假设不平衡比例为|N|/|P|,那么负例与正例的权重比值为|P|/|N|.通过此设置,能够显著地提高正例错分代价.
3)Random Under-Sampling(简称 Random):随机无放回地从负例样本集中采样一个子集,子集大小和正例样本集大小相同.
4)Edited Nearest Neighbours(简称 ENN):如果一个样本的标记同它的K个邻居相异,则将这个样本删除.
5)Ensemble Sampling(简称 Ensemble):类似Random Under-Sampling,此方法随机有放回地从负例样本集中采样M次,生成M个和正例样本集大小相同的子集.考虑到本文所用数据集的不平衡比例为34.5,特将M设置为30.
对于第二个步骤,我们使用3个单分类器和3个集成分类器.3个单分类器分别为:LR,CART,Linear SVC(简称LSVC);3个集成分类器分别为:Adaboost(简称 Ada),Random Forest(简称 RF),XGBoost(简称XGB).Ada,RF和XGB都是基于CART并且弱分类器的数量都设置成500个.在这6个分类器中,LR,RF,XGB能够并行操作而另外3个只能串行操作.除了XGB之外,我们使用scikit-learn API[22]实现这些分类器.另外,Ada和XGB不支持设置类别权重,因此这两个分类器无法在Cost策略下运行,后面用-表示缺失的结果.在Ensemble策略下,EasyEnsemble使用Ada作为基分类器并采用线性加权求和的方法,而xEnsemble使用XGB作为基分类器并使用简单的投票法,另外4个分类器也同样使用投票.
我们的实验运行在一台有24核CPU,主频为3.0GHz,内存为64GB的服务器上.整个实验的流程图如图2所示.

图2 实验示意图
3.5 实验结果与讨论
表4、表5、表6分别表示这30个模型在测试集上的Sensitivity,F3和G-mean值.如表4所示,在Original策略下,所有分类器的Sensitivity指标都有大幅退化.其中,XGB取得最高的分数,证明了其卓越的性能.由于减少了一些边界上的负例样本,ENN策略相比Original有了一些提高.更进一步,Cost、Random和Ensemble策略都有大幅度的提高.Random比Cost表现稍强,尤其是在LSVC分类器上.如前所述,Ada和XGB在Cost策略上结果是缺失的因为它们不支持Cost策略.另外,相比Random策略,Ada、RF和XGB在Ensemble下表现稍好,而LR和LSVC则反之.从分类器层面来看,RF和XGB的性能几乎是并驾齐驱,均取得优异的表现.

表4 所有模型的Sensitivity值

表5 所有模型的F3值

表6 所有模型的G-mean值
在表5中,Ensemble在F3上的表现优于Random除了CART分类器.另外Cost的性能也比Random要强,和Ensemble不相上下.在分类器层面,尽管RF对于Sensitivity在Random和Ensemble策略上比XGB表现要好,此处XGB对于F3却比RF表现更佳.
表6的情况更加简洁明了.很明显,Ensemble相比其他策略表现更加优秀,XGB在所有分类器中取得最高的分数.值得一提的是,xEnsemble对于Sensitivity,F3和G-mean均比EasyEnsemble效果要好.
总之,集成分类器,特别是XGB,相比单分类器,性能表现更好.同时,Ensemble策略相比其他策略,取得更优秀的结果.因此,本文提出的方法:xEnsemble,相比其他方法表现出更良好的性能.
4 结语
本文主要将研究重点放在应用不平衡学习方法来解决数据集中的类别不平衡问题,然后对糖尿病进行分类诊断.由于数据集的高度不平衡性,相比之前的研究,我们面临一个更加严峻的挑战.本文提出的xEnsemble 方法类似于“bagging of boosting”,能够同时降低模型的方差和偏差.通过采用该方法,我们获得了一个较优的结果,这将协助医务工作人员更高效便捷地对糖尿病诊断做出决策.
提取影响糖尿病发病的关键因素将是本文进一步的研究方向.明确这些关键发病因素能够起到很好的预警作用,做到“未雨绸缪”,帮助那些潜在风险的糖尿病人群更好地管理健康和预防糖尿病的发生.
1 World Health Organization.Global report on diabetes.Geneva:World Health Organization,2016.
2 Tuomilehto J,Lindström J,Eriksson JG,et al.Prevention of type 2 diabetes mellitus by changes in lifestyle among subjects with impaired glucose tolerance.New England Journal of Medicine,2001,344(18):1343–1350.[doi:10.1056/NEJM200105033441801]
3 Franciosi M,De Berardis G,Rossi MCE,et al.Use of the diabetes risk score for opportunistic screening of undiagnosed diabetes and impaired glucose tolerance.Diabetes Care,2005,28(5):1187–1194.[doi:10.2337/diacare.28.5.1187]
4 World Health Organization.Definition and diagnosis of diabetes mellitus and intermediate hyperglycaemia:Report of a WHO/IDF consultation.Geneva:World Health Organization,2006.
5 Huang Y,McCullagh P,Black N,et al.Feature selection and classification model construction on type 2 diabetic patients’data.Artificial Intelligence in Medicine,2007,41(3):251–262.[doi:10.1016/j.artmed.2007.07.002]
6 Goel R,Misra A,Kondal D,et al.Identification of insulin resistance in Asian Indian adolescents:Classification and regression tree (CART)and logistic regression based classification rules.Clinical Endocrinology,2009,70(5):717–724.[doi:10.1111/cen.2009.70.issue-5]
7 Heikes KE,Eddy DM,Arondekar B,et al.Diabetes risk calculator:A simple tool for detecting undiagnosed diabetes and pre-diabetes.Diabetes Care,2008,31(5):1040–1045.[doi:10.2337/dc07-1150]
8 Li L.Diagnosis of diabetes using a weight-adjusted voting approach.Proceedings of 2014 IEEE International Conference on Bioinformatics and Bioengineering.Boca Raton,FL,USA.2014.320–324.
9 Dogantekin E,Dogantekin A,Avci D,et al.An intelligent diagnosis system for diabetes on linear discriminant analysis and adaptive network based fuzzy inference system:LDAANFIS.Digital Signal Processing,2010,20(4):1248–1255.[doi:10.1016/j.dsp.2009.10.021]
10 Barakat N,Bradley AP,Barakat MNH.Intelligible support vector machines for diagnosis of diabetes mellitus.IEEE Transactions on Information Technology in Biomedicine,2010,14(4):1114–1120.[doi:10.1109/TITB.2009.2039485]
11 罗森林,成华,顾毓清,等.数据挖掘在2型糖尿病数据处理中的应用.计算机工程与设计,2004,25(11):1888–1892.[doi:10.3969/j.issn.1000-7024.2004.11.007]
12 罗森林,郭伟东,张笈,等,陈松景.基于Markov的Ⅱ型糖尿病预测技术研究.北京理工大学学报,2011,31(12):1414–1418.
13 蒋琳,彭黎.基于支持向量机的Ⅱ型糖尿病判别与特征筛选.科学技术与工程,2007,7(5):721–726.
14 Liu XY,Wu JX,Zhou ZH.Exploratory undersampling for class-imbalance learning.IEEE Transactions on Systems,Man,and Cybernetics,Part B (Cybernetics),2009,39(2):539–550.[doi:10.1109/TSMCB.2008.2007853]
15 Chen TQ,Guestrin C.Xgboost:A scalable tree boosting system.Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.San Francisco,CA,USA.2016.785–794.
16 Weiss GM.Mining with rarity:A unifying framework.ACM SIGKDD Explorations Newsletter,2004,6(1):7–19.[doi:10.1145/1007730]
17 Zhou ZH,Liu XY.Training cost-sensitive neural networks with methods addressing the class imbalance problem.IEEE Transactions on Knowledge and Data Engineering,2006,18(1):63–77.[doi:10.1109/TKDE.2006.17]
18 Chawla NV,Bowyer KW,Hall LO,et al.SMOTE:Synthetic minority over-sampling technique.Journal of Artificial Intelligence Research,2002,16(1):321–357.
19 Drummond C,Holte RC.C4.5,class imbalance,and cost sensitivity:Why under-sampling beats over-sampling.Workshop on Learning from Imbalanced Datasets II.Washington,DC,USA.2003.
20 Batista GEAPA,Prati RC,Monard MC.A study of the behavior of several methods for balancing machine learning training data.ACM Sigkdd Explorations Newsletter,2004,6(1):20–29.[doi:10.1145/1007730]
21 Breiman L.Bagging predictors.Machine Learning,1996,24(2):123–140.
22 Buitinck L,Louppe G,Blondel M,et al.API design for machine learning software:Experiences from the scikit-learn project.arXiv:1309.0238,2013.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
陶瓷学报(2021年4期)2021-10-14
中学生数理化·高一版(2021年2期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
电子技术与软件工程(2019年18期)2019-11-18
领导决策信息(2018年16期)2018-09-27
电子技术与软件工程(2017年14期)2017-09-08
数学学习与研究(2017年3期)2017-03-09
西南学林(2011年0期)2011-11-12
