
一种运用显著性检测的行为识别方法
2018-02-27 10:57王晓芳齐春
西安交通大学学报 2018年2期
王晓芳,齐春
(1.西安交通大学电子与信息工程学院,710049,西安;2.齐鲁工业大学(山东省科学院)电气工程与自动化学院,250353,济南)
行为识别即利用计算机自动提取视频中的行为特征并判别行为类别,在视频监控、人机交互、虚拟现实等领域具有广阔的应用前景。稠密轨迹法[1]是近年来一种比较成功的行为识别方法,该方法通过提取视频稠密采样点的轨迹来获取行为的长时段特征。然而,传统的稠密轨迹法在提取轨迹时不能很好地区分行为区域和背景,对包含相机运动的视频,除行为区域之外背景区域也会产生大量的轨迹,这种背景轨迹和感兴趣的行为关系不大,其存在限制了行为识别性能。
为了改进传统的稠密轨迹法,许多文献提出只获取行为区域内的稠密轨迹用于描述行为特征,这类方法目前主要存在2种思路。鉴于背景轨迹通常由相机运动产生,第一种思路先通过估计相机运动校正视频的光流,再利用校正后的光流消除背景轨迹[2-3]。考虑到行为区域通常比背景区域显著,另一种思路先通过检测视频显著性获取行为区域,再提取行为区域内轨迹[4-5],这种思路的关键在于显著性检测。文献[4]将低秩矩阵恢复应用于运动信息检测视频的显著性,但是不能解决行为区域内部运动一致性的问题;文献[5]能够确定视频中的真实显著图,但依赖于观察者的眼部运动数据;文献[6]利用字典学习和稀疏编码获取视频显著性,但是没有充分利用运动信息;此外,现有文献中也存在许多其他显著性检测方法[7-9],但大多不是面向行为区域获取而设计。获取视频中行为区域的关键在于如何区分行为区域和背景,而不能只考虑一般意义上的显著性。无论视频是在静态或者动态场景中获取,运动信息都是区分行为区域和背景的重要依据。对于包含相机运动的视频,从总体上看,其背景运动的空域分布具有较高的一致性,而行为运动的空域分布具有一定的不规则性,所以行为区域相对于背景通常具有较高的运动显著性,可以通过运动显著性检测方法将其从背景中分离。然而,一些大的行为区域内部也存在局部一致运动,而有些背景区域也包含局部不规则运动,此时一般的运动显著性检测方法难以将它们很好地区分。
鉴于此,本文提出一种采用两阶段显著性检测获取视频中的行为区域的方法,并将其应用于轨迹法行为识别。本文方法主要包括2个阶段:第1阶段,将低秩矩阵恢复算法[10]应用于运动信息计算子视频内每个块的初始显著性,并借此将子视频所有块划分为候选前景集合和绝对背景集合;第2阶段,利用绝对背景集合中所有块的运动向量构建字典,通过稀疏表示算法[11]获取候选前景集合中所有块的细化显著性。在此基础上,对显著性进行阈值化得到二值显著图用于指示行为区域,最后将其融入稠密跟踪过程以提取行为区域轨迹用于行为识别。与其他显著性检测方法相比,上述两阶段方法能够更充分地考虑行为区域和背景区域的运动特点,从而以更高的对比度突出视频中的行为区域。
1 显著性和行为区域检测
设长度为T的视频V=[I1,I2,…,IT],It表示第t帧,在时域将V分割成长度均为w的K个互不重叠的子视频,即V=[V1,V2,…,VK],第k个子视频为Vk=[I(k-1)w+1,I(k-1)w+2,…,Ikw]。在空域将每个子视频划分成M×N个大小相等且互不重叠的时空块,划分后的Vk可用一个3D分块矩阵表示
(1)
式中:Pn为第n个时空块,大小为s×s×w,其中s为空域大小,w为实域长度。下面以Vk为例,利用两阶段显著性检测方法获取子视频中的行为区域,其总体流程如图1所示。
1.1 初始显著性检测及候选前景和绝对背景划分
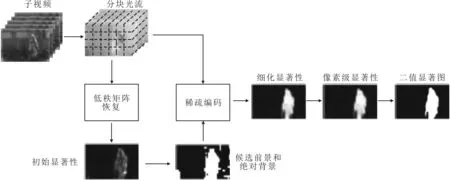
图1 本文行为区域检测流程
本文采用文献[4]中的方法计算子视频的初始显著性。一般来说,由运动相机拍摄的视频,背景运动空域分布具有一致性,相关性较强,可以认为处于一个低秩的子空间,行为运动空运分布具有随意性,相关性较弱,可以看作稀疏误差。基于上述特点,通过低秩矩阵恢复算法将子视频的运动信息分解成低秩部分和稀疏误差部分,利用后者计算视频块的初始显著性,并据此划分子视频的候选前景和绝对背景。
为了检测Vk的初始显著性,需构建其运动矩阵。为此,先获取每个块的运动向量,以块Pn为例,先将其每一帧内所有像素点的光流按照空域位置顺序排列得到对应帧的运动向量,其内第l帧的运动向量为
(2)
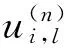
X=[x1,x2,…,xMN]
(3)
通过求解如下低秩矩阵恢复优化问题,可将X分解为一个低秩矩阵B和一个稀疏矩阵F
s.t.X=B+F
(4)
式中:λ是用于平衡低秩和稀疏的参数,其值设置为λ=1.1/[max(2s2w,MN)]1/2。式(4)优化问题可通过增广拉格朗日乘子法(ALM)[12]求解。
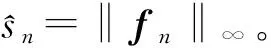
按照这种方法,行为区域块因包含行为运动可以获得较高的显著性值,而背景块因不包含行为运动获得较低的显著性值。然而,对于一些大的行为区域,其内部某些行为运动因具有局部一致性被沉积到低秩矩阵B中,而对于一些背景区域,其内部运动因具有局部不规则性而被包含到稀疏矩阵F中,由此导致行为区域和背景的显著性差异较小,所以利用初始显著性很难将所有行为区域和背景很好地分离。这里通过选定一个较小的阈值Ts,将所有可能行为区域块(显著性大等于Ts)都划分到一个候选前景集合Sf中,而将剩余绝对背景块(显著性小于Ts)划分到一个绝对背景集合Sb中。
1.2 候选前景显著性细化
利用初始显著性进行集合划分时,由于Ts较小,一些背景块也被划分到集合Sf中。为了将Sf中真正的行为区域块分离出来,需要计算其中的每一个块的细化显著性,以增加行为区域和背景的显著性对比度。一般情况下,对于Sf中真正的行为区域块,其运动信息即使和邻近块具有相似性,但都明显不同于绝对背景块;对于Sf中的背景块,其运动信息即使含有一定的变化,也和绝对背景块具有较高的相似性。基于此,本节利用Sb中所有块的运动向量构建字典,对Sf中每一个块的运动向量进行稀疏表示,再利用重构误差计算块的细化显著性。这样,行为区域块因为较难重构而容易获得较高的显著性值;相反,背景块因较易重构而容易获得较低的显著性值。
为了计算Sf中每一个块的细化显著性,将Sb中所有块的运动向量按列堆叠,得到Vk的绝对背景运动矩阵Xb,再将Xb作为字典,对Sf中的每个块的运动向量进行稀疏表示。以Sf中第r个块为例,可通过求解以下的优化问题得到其运动向量xfr的稀疏表示
(5)
式中:αr为稀疏表示系数向量。
考虑到背景块一般与它的邻近背景块相关性更强,为了使Sf中的背景块获得更低的重构误差,利用Sb中的每个块和当前被重构块的空域距离作为Xb中对应原子的权重。Xb中第i个原子xbi的权重为
(6)
式中:cr和ci分别为当前被重构块和Sb中第i个块的中心;dist(cr,ci)为cr,ci之间的归一化欧式距离;σ为调节参数。Xb中所有原子的权重组成一个权重向量wr,将其引入式(5),可以得到加权稀疏表示的目标函数
(7)
利用文献[13]中的优化工具箱可以求解式(7)获得稀疏表示系数向量αr,由此计算重构误差sr,将其作为当前被重构块(Sf中第r个块)的细化显著性
sr=‖xfr-Xbαr‖2
(8)
重复上述过程,可以获取候选前景集合Sf中所有块的细化显著性,将其和绝对背景集合Sb中所有块的初始显著性按照块的空域位置进行组合,可以得到子视频Vk的显著性矩阵Sk。Sk是一个块级的显著性矩阵,利用空域插值法将其调整为视频帧的原始大小,即获得Vk的像素级显著性矩阵,再进行阈值化可以得到Vk的二值显著图Mk。Mk中位置为(x,y)的元素mxy用于指示子视频Vk任意一帧内的点(x,y)是否属于行为区域,如果mxy=1,属于行为区域,否则属于背景。
按照上述两阶段法可以计算视频中所有子视频的二值显著图,从而获取视频行为区域。
2 轨迹提取和行为识别
和文献[5]类似,将检测得到的二值显著图和稠密跟踪相结合来提取行为区域轨迹。具体来说,在稠密采样点跟踪过程中,先通过光流获取下一帧上的候选轨迹点,再利用二值显著图判断其是否处于行为区域,如果是则认为是有效轨迹点,否则判其无效并终止当前轨迹。计算识别率时,对每一条轨迹计算4种特征形状(Shape)、梯度方向直方图(HOG)、光流方向直方图(HOF)和运动边界直方图(MBH),并利用FV(Fisher vector)对每一种特征进行独立编码以获取视频级行为特征,最后将4种视频级行为特征输入多核学习支撑向量机(SVM)判别行为类别。
3 实验结果和分析
3.1 实验设置
为了验证本文方法的有效性,在Hollywood2[14]和YouTube[15]2个实际场景视频数据集上进行实验测试。Hollywood2共包含1 707个视频,分为12个行为类别;YouTube共包含1 168个视频,分为11个行为类别,每个类别的视频又分为25组。检测显著性和行为区域时,设置子视频长度为5帧,块的空域大小为5×5像素,第1、第2阶段的显著性阈值分别设置为10和50。提取行为区域轨迹时,设置空域采样间隔为5像素。计算行为识别率时,对于Hollywood2数据集,将其中823个视频用作训练样本,剩余884个视频用作测试样本;对于YouTube数据集,每次利用一组作为测试样本,其余各组用作训练样本,最终识别率是25组识别率的均值。
3.2 显著性和行为区域检测结果

图2 采用本文方法进行行为区域检测的各阶段结果
采用本文方法对2个数据集中5个行为视频投篮、骑马、走出汽车、奔跑和站起的行为区域进行检测,各阶段的检测结果如图2所示。除最后一个外,其余视频都包含了不同程度、不同类型的相机运动。由图2可以看出:第1阶段检测到的初始显著性整体对比度较低,尤其是行为区域的中间部分,由于运动存在局部一致性,导致其显著性值更小;第2阶段得到的细化显著性能够突出大部分行为区域(包括中间部分),较好地抑制了背景区域。以上结果表明,本文两阶段检测方法能够充分考虑行为区域和背景区域的运动的特点,无论视频是否包含相机运动,都能获得较好的检测结果。
为了进一步验证本文行为区域检测方法的优越性,图3将本文检测结果和现有文献最新方法进行对比。其中,文献[8]是一种基于超像素图和时空生长的一般视频显著性检测方法,文献[16]采用一种基于加权稀疏表示的显著性检测方法获取视频中的行为区域。由图3可以看出:本文方法检测的显著性具有较高的对比度,能够明显地区分行为区域和背景区域;文献[8]方法的显著性虽然也能够突出视频中的行为区域,但其对比度低于本文方法;文献[16]方法的显著性在行为区域内部较低。

图3 本文方法和文献[8,16]方法的检测结果对比
3.3 行为区域轨迹提取结果
采用本文方法和传统稠密跟踪方法对5个视频的行为区域轨迹进行检测,结果如图4所示。由图4可以看出:本文方法提取的轨迹不仅具有较好的连续性,而且绝大部分位于行为区域;当视频中存在相机运动时,传统的稠密跟踪方法不仅在行为区域,而且在背景区域也会产生大量轨迹。

图4 本文方法和传统稠密方法的行为区域轨迹比较
3.4 行为识别结果
为了验证本文方法的识别性能,分别在2个数据集Hollywood2和YouTuber计算本文方法(SDT)、传统稠密轨迹方法(DT)以及两者视频级特征级联方法(SDT+DT)的总体识别结果,如表1所示。由表1可见,在2个数据集上,SDT的识别结果都明显优于DT,而二者级联能够进一步提高识别率。图5比较了本文方法(SDT)和传统稠密轨迹跟踪方法(DT)对2个数据集上的4个特征的识别结果。由图5不难看出,在2个数据集上,SDT各个特征的识别率都优于DT。
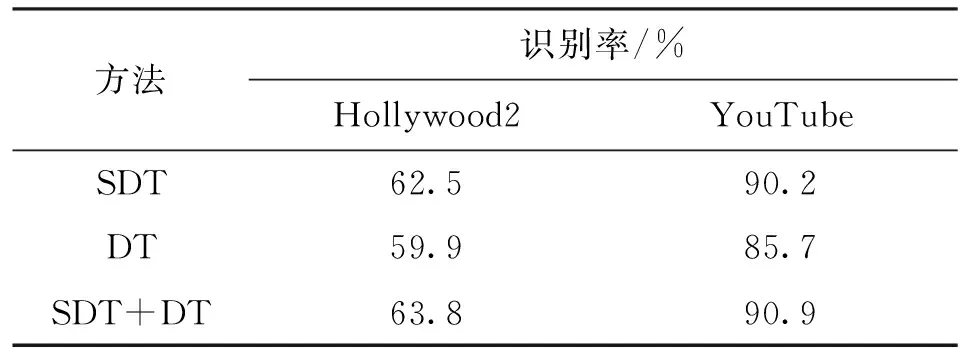
表1 采用SDT、DT方法及两者特征级联SDT+ DT方法在2个数据集上的总体识别结果
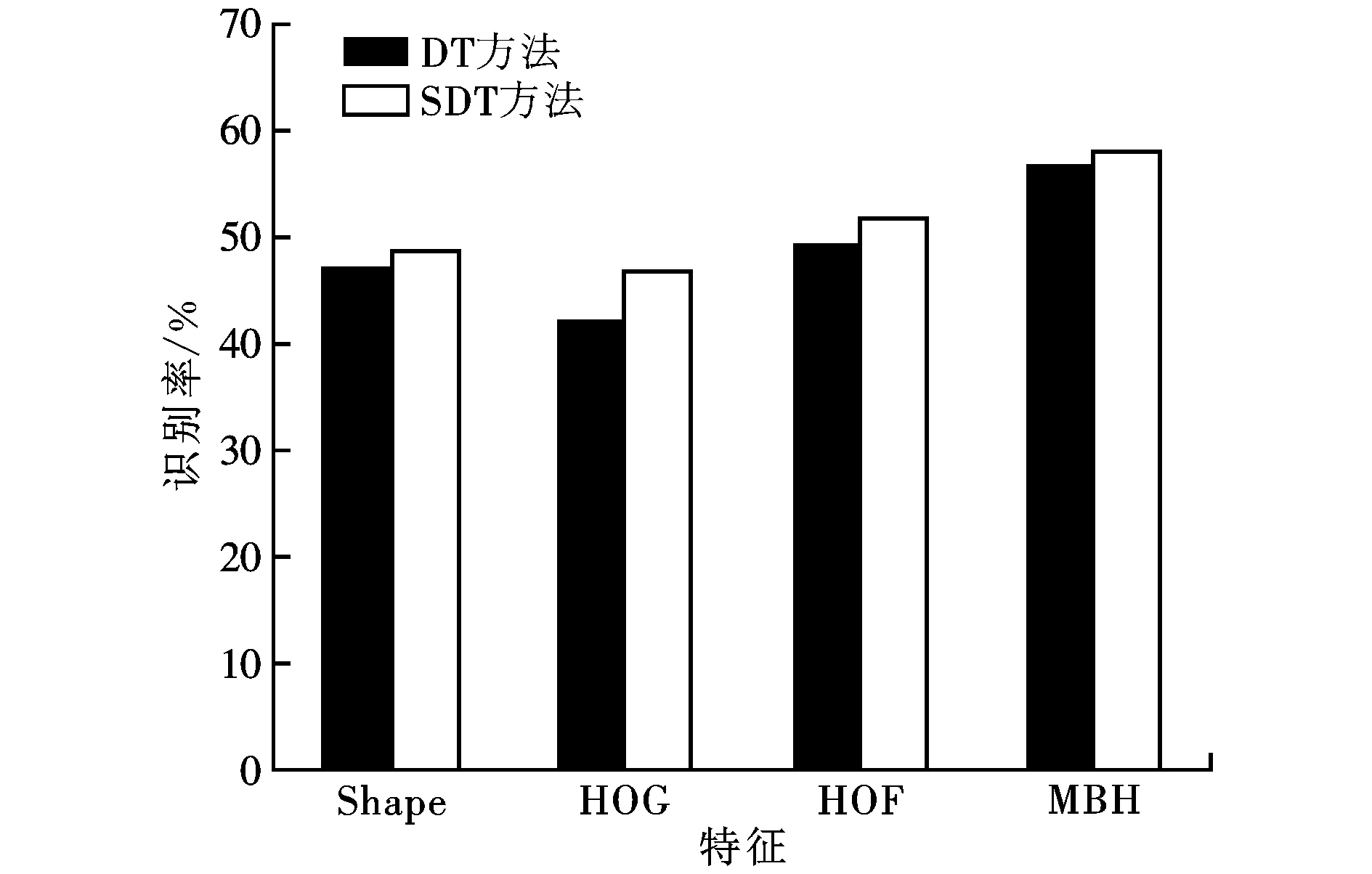
(a)Hollywood2
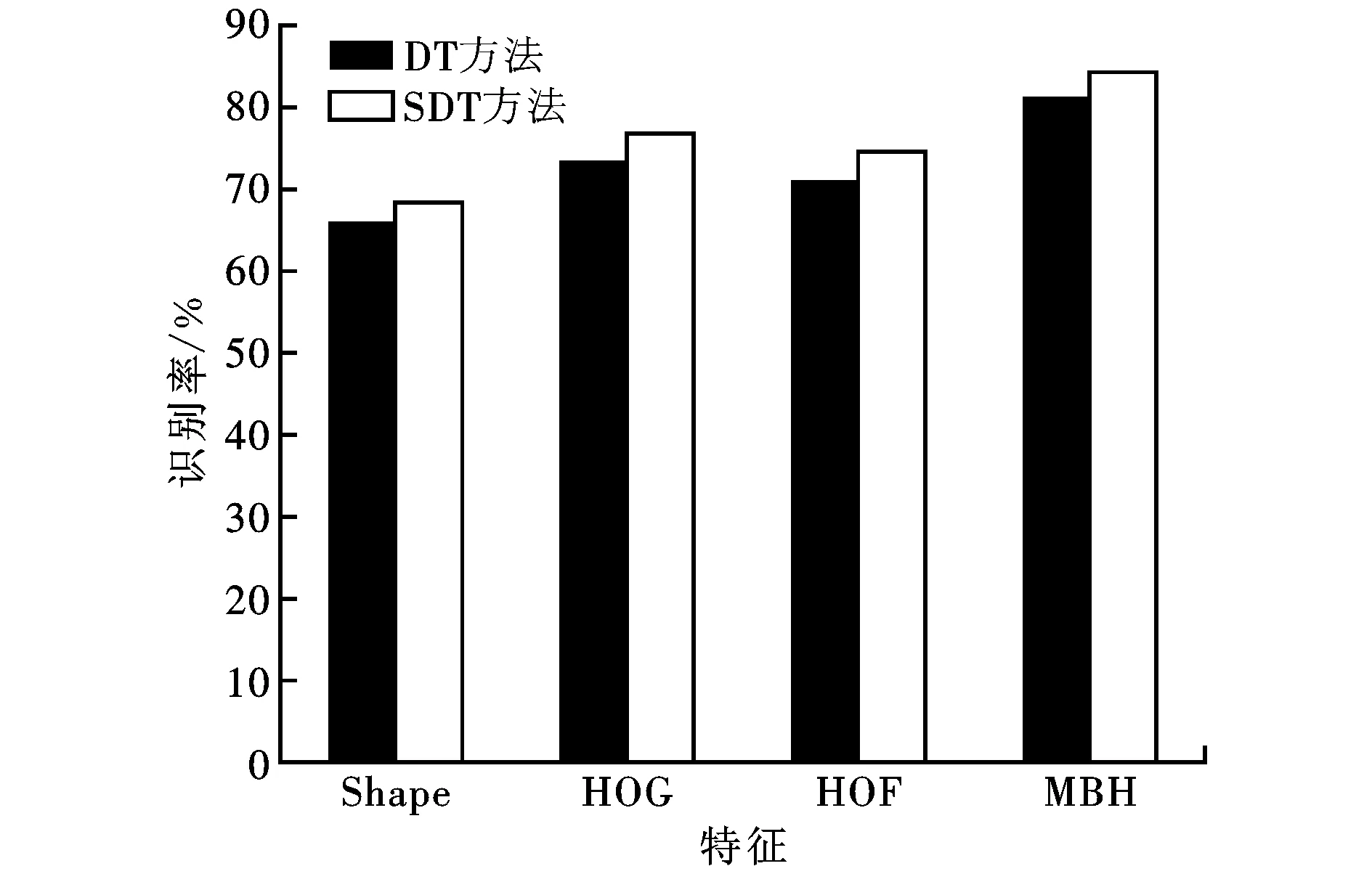
(b)YouTube图5 本文方法和传统稠密轨迹跟踪方法对2个数据集上的4个特征的识别率比较
为了进一步验证本文行为识别方法的有效性,将其和现有文献中的稠密轨迹跟踪法[1]及其他改进方法[2,3,5,17-19]进行比较。表2列出了本文与文献[1-3,5,17]在Hollywood2数据集上的最优识别结果,通过比较可以看出,本文方法的识别率虽然稍低于文献[2]中的方法,但明显高于其他文献中的方法。本文方法与文献[1,17-19]方法在YouTube数据集上的最优识别结果如表3所示,显然本文方法获得了最高的识别率。

表2 本文方法与5种现有文献方法在Hollywood2 数据集上的识别率比较
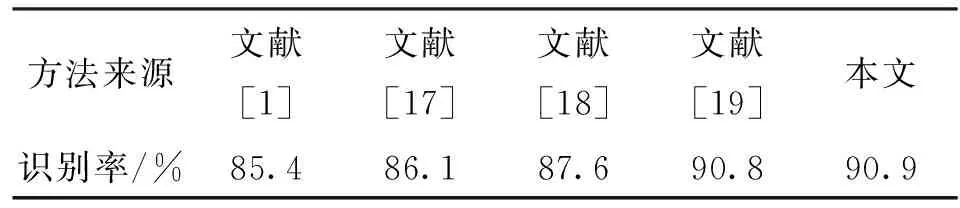
表3 本文方法与4种现有文献方法在YouTube 数据集上的识别率比较
4 结 论
本文针对稠密轨迹行为识别法存在的问题,采用一种两阶段显著性检测方法获取视频中的行为区域,并提取行为区域轨迹用于行为识别。第1阶段通过低秩矩阵恢复算法检测初始显著性,并据此将子视频划分为候选前景和绝对背景;第2阶段利用稀疏表示算法获取候选前景的细化显著性。这种检测方法能够以更高的对比度突出行为区域,抑制背景区域。此外,以子视频和块为基础,考虑了显著性时空相关性,增强了检测到的行为区域的时空连续性,有利于提高轨迹的连续性和完整性。实验结果表明,无论视频是否包含相机运动,本文方法都能较好地检测其中的行为区域,获取的行为识别结果优于传统稠密轨迹法和大部分改进方法。
[1] WANG H, KLASER A, SCHMID C, et al. Dense trajectories and motion boundary descriptors for action recognition [J]. International Journal of Computer Vision, 2013, 103: 60-79.
[2] WANG H, SCHMID C. Action recognition with improved trajectories [C]∥Proceedings of IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2013: 3551-3558.
[3] JAIN M, JEGOU H, BOUTHEMY P. Better exploiting motion for better action recognition [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2013: 2555-2562.
[4] WANG X, QI C. Saliency-based dense trajectories for action recognition using low-rank matrix decomposition [J]. Journal of Visual Communication & Image Representation, 2016, 47: 361-374.
[5] VIG E, DORR M, COX D. Space-variant descriptor sampling for action recognition based on saliency and eye movements [C]∥Proceedings of 12th European Conference on Computer Vision. Berlin, Germany: Springer, 2012: 84-97.
[6] SOMASUNDARAM G, CHERIAN A, MORELLAS V, et al. Action recognition using global spatio-temporal features derived from sparse representations [J]. Computer Vision and Image Understanding, 2014, 123(7): 1-13.
[7] 方志明, 崔荣一, 金璟璇. 基于生物视觉特征和视觉心理学的视频显著性检测算法 [J]. 物理学报, 2017, 66(10): 319-332. FANG Zhiming, CUI Rongyi, JIN Jingxuan. Video saliency detection algorithm based on biological visual feature and visual psychology theory [J]. Acta Physica Sinica, 2017, 66(10): 319-332.
[8] LIU Z, LI J, YE L, et al. Saliency detection for unconstrained videos using superpixel-level graph and spatiotemporal propagation [J]. IEEE Transactions on Circuits & Systems for Video Technology, 2017, 27(12): 2527-2542.
[9] 陈昶安, 吴晓峰, 王斌, 等. 复杂扰动背景下时空特征动态融合的视频显著性检测 [J]. 计算机辅助设计与图形学学报, 2016, 28(5): 802-812. CHEN C A, WU X F, WANG B, et al. Video saliency detection using dynamic fusion of spatial-temporal features in complex background with disturbance [J]. Journal of Computer-Aided Design & Computer Graphics, 2016, 28(5): 802-812.
[10]CANDES E J, LI X, MA Y, et al. Robust principal component analysis? [J]. Journal of the ACM, 2011, 58(3): 11.
[11]WRIGHT J, YANG A Y, GANESH A, et al. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227.
[12]LIN Z, CHEN M, MA Y. The augmented Lagrange multiplier method for exact recovery of corrupted low-rank matrices [EB/OL]. (2013-10-18) [2015-12-10]. https: ∥arxiv.org/pdf/1009.5055v3.pdf.
[13]MAIRAL J. SPAMS: a sparse modeling software, v2.5 [EB/OL]. (2014-05-25) [2015-12-26]. http: ∥spams-devel. gforge.inria. fr.
[14]MARSZALEK M, LAPTEV I, SCHMID C. Actions in context [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2009: 2929-2936.
[15]LIU J, LUO J, SHAH M. Recognizing realistic actions from videos in the wild [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2009: 1996-2003.
[16]WANG Xiaofang, QI Chun. LIN Fei. Combined trajectories for action recognition based on saliency detection and motion boundary [J]. Signal Processing Image Communication, 2017, 57: 91-102.
[17]CHO J, LEE M, CHANG H J, et al. Robust action recognition using local motion and group sparsity [J]. Pattern Recognition, 2014, 47(5): 1813-1825.
[18]PENG X, QIAO Y, PENG Q. Motion boundary based sampling and 3D co-occurrence descriptors for action recognition [J]. Image and Vision Computing, 2014, 32(9): 616-628.
[19]WU J, ZHANG Y, LIN W. Towards good practices for action video encoding [C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2014: 2577-2584.
猜你喜欢
汽车工程师(2021年12期)2022-01-17
当代陕西(2020年14期)2021-01-08
读友·少年文学(清雅版)(2020年4期)2020-08-24
奥秘(创新大赛)(2020年7期)2020-07-27
读友·少年文学(清雅版)(2020年3期)2020-07-24
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
