
量子k-means算法
2018-03-01 05:24刘雪娟袁家斌段博佳
吉林大学学报(工学版) 2018年2期
刘雪娟,袁家斌,许 娟,段博佳
(南京航空航天大学 计算机科学与技术学院,南京210016)
0 引 言
近年来,越多越多的学者将量子计算应用于数据挖掘领域[1]。Anguita等[2]提出利用Grover量子搜索算法[3]优化支持向量机SVM的训练过程用于解决SVM的训练效率问题。Rebentrost等[4]提出量子SVM,利用量子计算解决训练数据的内积计算,即利用量子计算求解矩阵的偏迹得到训练数据的归一化核矩阵。Lu等[5]提出量子决策树算法,利用量子态之间的保真度作为训练数据之间相似度的度量,依此将训练集划分成子类,并引入量子信息熵作为选择决策节点的依据建立量子决策树。阮越等[6]提出了量子PCA算法并用于人脸识别中,用量子态表示人脸特征,将Grover量子搜索算法用于人脸识别的过程达到二次加速的效果。徐永振等[7]提出基于一维三态离散量子游走的聚类算法,将数据点看作游走粒子,执行三态量子游走,根据粒子的测量结果更新数据点的属性值并依此进行聚类。Elhaddad等[8]从并行计算和优化计算两个方面分别分析了量子计算对人工智能和数据挖掘领域所带来的影响。
聚类作为一种无监督的机器学习技术,其依据给定的相似性度量将数据划分成若干个类,使得同一类内的数据相似度较高,而不同类间的数据相似度较低[9]。聚类算法被广泛应用于图像识别、社交网络、商业智能等领域中[10,11]。k-means是一种经典的聚类算法,被誉为数据挖掘领域的十大算法之一,自提出以来就得到了广泛的应用[12-14]。然而大数据时代,巨大的数据量为kmeans聚类的速度带来了巨大的挑战,利用基于云计算的大规模集群进行并行聚类成了较为普遍的应对策略;但是大规模集群所产生的巨大的能量消耗问题又带来新的挑战[15,16]。而量子计算不但具有超强的并行计算能力,又因计算的可逆性使其不会面临能量消耗的问题,故已有学者研究利用量子计算的相关理论对k-means算法进行聚类加速。因量子态之间的信息保真度与传统相似度度量中的余弦相似度相似,Aïmeur等[17]提出利用量子信息保真度代替k-means算法中数据之间的相似度量,并利用受控交换门Control-Swap计算量子信息保真度,但k-means算法的其他步骤并没有引入量子计算。随后Aïmeur等[18,19]又提出了利用Grover算法的扩展算法量子最小值查找算法作为一个量子子程序去加速经典k-means算法中的一个步骤,但算法的计算复杂度并没有降低。k-means算法对初始聚类中心的选择比较敏感,不同的聚类中心其聚类效果可能不同,故Lloyd等[20]提出利用量子绝热算法选择合适的初始聚类中心点后,再利用kmeans算法进行聚类,聚类的计算过程中并未引入量子计算。
综上所述,有关量子计算与k-means算法相结合的工作中,大多是利用量子计算对算法中的某一个步骤进行了加速,但是算法整体的计算复杂度并未降低。本文给出的量子k-means算法将对聚类的主要步骤进行加速,使算法整体计算复杂度得到降低。
1 经典k-means算法
给定数据集X={x1,x2,…,x n},n为数据集的规模,x i为第i个数据点,每个数据点的特征维度为d,x ir表示第i个数据点的第r个特征值;数据集被划分为k个类别,聚类中心为c={c1,c2,…,c k}。k-means算法的聚类过程如下:
(1)随机从数据集X中选取k条记录作为初始聚类中心c。
(2)对每一数据点x i,计算其到k个聚类中心的相似度。
(3)将数据点x i归于相似度最大的那个聚类中心所属的类。
(4)数据集中的所有数据经过步骤(2)(3)计算后,根据数据集的类别标号重新计算新的聚类中心。
(5)判断是否达到聚类结束的条件,若达到,聚类结束;否则回到步骤(1)。
k-means算法的主要聚类步骤和计算量集中在第(2)(3)步,即对每个数据点计算其到k个聚类中心的相似度,并将其归于相似度最大的聚类中心所属的类别。
2 本文算法
量子k-means算法将量子计算的相关理论引入到聚类的主要步骤,主要分成3个阶段完成该步骤的任务:第一,先将待聚类的数据点和k个聚类中心点制备成量子态;第二,利用受控交换门Control-Swap计算任一数据点x i和k个聚类中心c={c1,c2,…,c k}的相似度,并利用相位估计算法将相似度存储在量子比特上;第三,对所求出的k个相似度利用最小值查找量子搜索算法求出最相似的聚类中心点c j。
2.1 量子态制备
k-means算法中需要计算每一个数据点与k个聚类中心的相似度,所以需要将其制备成量子态。量子态制备之前先将所有的数据进行归一化处理。假设任一聚类数据点x i用具有d个特征值的向量来表示,以待聚类的数据点x0为例,将数据点x0制备成如式(1)所示的量子态:

式中:x0j为第0个数据点的第j个特征值。
将k个聚类中心c={c1,c2,…,c k}制备成如式(2)所示的量子态:

式中:c ij表示第i个聚类中心点的第j个特征值。
设2m=k,2n=d,量子态|c〉的制备过程如下:
(1)初始输入为|0〉⊗m|0〉⊗n|1〉|0〉,利用H门得到量子态:

(2)将量子黑箱Oracle作用到式(3)上得到:

量子黑箱Oracle定义为:

(3)利用一个绕Y轴旋转的酉操作作用到式(4)中的最后一个量子比特上得到:

(4)利用第(2)步的量子黑箱Oracle的逆操作清除式(5)中的|c ij〉,得到如式(2)所示的量子态|c〉。
利用同样的方法制备如式(1)所示的量子态|x0〉。由上述量子态的制备过程可以得到,制备量子态|c〉需要3次Oracle操作,制备|x0〉与|c0〉则需要6次Oracle操作。
2.2 相似性计算
计算量子态|x0〉与|c〉的相似度,并利用相位估计算法将相似度存储在量子比特中。对于相似度的计算,仍然采用文献[17]中的方法:即采用控制交换门Control-Swap计算量子态之间的保真度用于估计相似度。
用于计算量子态|x0〉与|c〉相似度的控制交换门Control-Swap如图1所示,输入的第1个量子比特位经过一个H门后用作控制位,当其为1时实现交换操作。计算的过程如下:
(1)|0〉|x0〉|c〉 ∥ 初态。

图1 控制交换门Fig.1 Control-Swap gate
由此得到控制交换门的输出结果为:

设测量算子M1=|1〉〈1|,并且有,则:

由p(m)可以得到第一位量子比特为1的概率为,由于量子态c是k个聚类中心点量子态c i的叠加,则〈x0|c〉为x0与c i的余弦值,这里定义为s(x0,c i),用于描述x0与c i的相似度,当s(x0,c i)值越小,其x0与c i的余弦值〈x0|c〉就越大,两者就越相似。由此,控制交换门的输出可以表示为:


接下来将相位估计算法作用在φ上,使相似度信息存储在量子比特上[21]。相位估计算法用于求解给定向量的相位,其实现原理主要是基于量子Fourier变换技术。量子Fourier主要是实现如下形式的变换:

将量子态φ作为相位估计算法的输入,可以得到:

由此可将c i与x0之间的相似度存储于量子比特上,即越小,两者之间的相似度越大;同理越大,两者的相似度越小。由于相位估计的过程主要是Grover迭代的过程,即需要相应的Oracle操作,其计算量与估计的精度有关;当精度值确定后,其计算量则为常数,这里假设其需要的Oracle操作的次数为R′。
2.3 相似度最大值查找
量子态α中保存的k个值,可以看作是一个规模为k的无序数据库的叠加态,其中使达到最小的c i便是与x0最为相似的聚类中心,即两者之间的相似度最大。如果利用经典查找算法查找与x0最相似的c i,需要的时间复杂度为O(k)。而最小值查找量子算法作为Grover算法的一个扩展算法,其可以的时间复杂度从无序数据库中查找出最小值[22]。
利用量子最小值查找算法从量子态α中查找最小值的步骤如下:首先随机选取一个聚类中心c j作为初始值,然后重复以下步骤次:
(1)制备初始值c j的量子态为β。
(2)α、β作为输入,b作为控制输入,利用Grover算法查找到。
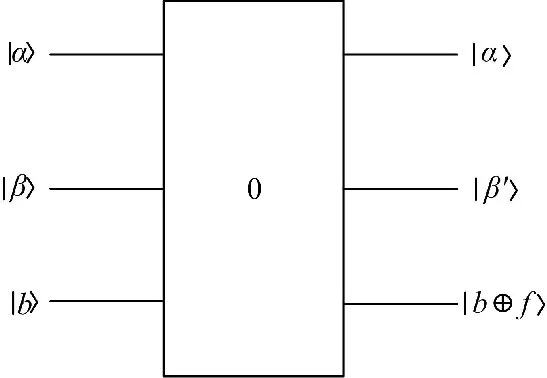
图2 查找最相似的聚类中心Fig.2 Find the maximum of similarity to cluster center
相应的量子搜索算法模型如图2所示。此时找到的c j为与x0最近的聚类中心点,将x0归于c j所属的类别。
3 算法复杂度分析
两种算法的时间复杂度和空间复杂度对比结果如表1所示。

表1 两种算法的复杂度比较Table 1 Comparison of complexity of two algorithms
3.1 时间复杂度
经典k-means算法中的主要计算步骤为第(2)(3)步。其中第(2)步,即对于每一个具有d个特征值的数据点x i,都要计算其与k个聚类中心的相似度,该步计算的时间复杂度为O(kd)。算法第(3)步是从k个相似度中查找最大值,其时间复杂度为O(k),文献[23,24]主要是对该步骤利用量子搜索算法对其加速,使该步骤的时间复杂度降到,但是该步骤的加速并不会使整个算法的时间复杂度提高。对于数据规模为n需要迭代t次的聚类过程,经典k-means算法的时间复杂度为O(tnkd)。
本文提出的量子k-means算法,将被聚类的每一个数据点x i与k个聚类中心制备成相应的量子叠加态,需要的Oracle操作次数为6次。由于量子计算其内生的计算并行性,则对于每一个数据点x i,利用控制交换门计算其与k个聚类中心的相似度,只需要一步计算即可得到。得到的相似度只是作为一个中间值,并不会对其直接测量,而是利用相位估计算法将其存储于量子比特中,该步的结果被直接用于查找与x i相似度最大的聚类中心点。相位估计算法需要的Oracle操作次数为常数R′,查找最相似的聚类中心需要的时间复杂度为。设6+R′=R,则量子k-means算法主要步骤的计算复杂度为,整个量子k-means算法的时间复杂度为。对比两种算法的时间复杂度,可以得到:当时,即时,量子k-means算法的计算速度快,且k和d越大,这种效果就越明显,量子k-means算法的时间复杂度就越低。
3.2 空间复杂度
在经典k-means算法中,对于任意数据点x i,假设一个特征值需要占据一个字节的内存空间,则x i需要的内存空间为d字节;由于要计算其与k个聚类中心的距离,那么其需要的内存应该为(k+1)d字节=8(k+1)d比特。而对于量子k-means算法,任一数据点x i的量子态所需要的内存为(2+log2d)比特,k个聚类中心的量子态所需要的内存为(2+log2d+log2k)比特,即第一步总共需要的最大内存为(4+2 log2d+log2k) 比特。对比8(k+1)d和(4+2 log2d+log2k)可以看到,量子算法的空间复杂度达到指数级降低。
4 结束语
本文在k-means算法的主要步骤中引入量子计算相关理论,得到k-means算法的量子化版本。首先给出了任一聚类数据x i和k个聚类中心的量子态制备过程,然后给出了x i和这k个聚类中心距离的相似度计算过程,并利用相位估计算法将相似度转换成量子比特,最后,利用最小值查找量子算法查找出最相似的聚类中心点并将其归于所属的类别。对两种算法的时间复杂度进行理论分析和比较可以得到,在k和d比较大的情况下,量子k-means算法相对经典算法的时间复杂度得到降低,且k和d越大,这种效果越明显;而量子k-means的空间复杂度相对经典算法则可以达到指数级降低。
[1]王书浩,龙桂鲁.大数据与量子计算[J].科学通报,2015,60(5):499-508.Wang Shu-hao,Long Gui-lu.Big data and quantum computation[J].Chin Sci Bull,2015,60(5):499-508.
[2]Anguita D,Ridella S,Rivieccio F,et al.Quantum optimization for training support vector machines[J].Neural Networks,2003,16(5/6):763-770.
[3]Grover L K.A fast quantum mechanical algorithm for database search[C]∥Proc 28th Ann ACM Symp Theory of Computing,New York,USA,1996:212-219.
[4]Rebentrost P,Mohseni M,Lloyd S.Quantum support vector machine for big data classification[J].Physical Review Letters,2014,113(13):130503.
[5]Lu S,Braunstein S L.Quantum decision tree classifier[J].Quantum Information Processing,2014,13(3):757-770.
[6]阮越,陈汉武,刘志昊,等.量子主成分分析算法[J].计算机学报,2014,37(3):666-676.Ruan Yue,Chen Han-wu,Liu Zhi-hao,et al.Quantum principal component analysis algorithm[J].Chinese Journal of Computers,2014,37(3):666-676.
[7]徐永振,郭躬德,蔡彬彬,等.基于一维三态量子游走的量子聚类算法[J].计算机科学,2016,43(3):80-83.Xu Yong-zhen,Guo Gong-de,Cai Bin-bin,et al.Quantum clustering algorithm based on one-dimensional three-state quantum walk[J].Computer Science,2016,43(3):80-83.
[8]Elhaddad M E,Mohammed S A O.Analysing the impact of quantum computing using system dynamics[C]∥Engineering&MIS(ICEMIS),IEEE,2016:1-5.
[9]Jain A K,Murty M N,Flynn P J.Data clustering:a review[J].ACM Computing Surveys(CSUR),1999,31(3):264-323.
[10]许美慧,尹建芹,张玲,等.可处理暗腔的日冕物质抛射检测新方法[J].光学精密工程,2016,24(10s):591-599.Xu Mei-hui,Yin Jian-qin,Zhang Ling,et al.New detection method for coronal mass ejection capable of dark cavity processing[J].Optics and Precision Engineering,2016,24(10s):591-599.
[11]王丽.融合底层和中层字典特征的行人重识别[J].中国光学,2016,9(5):540-546.Wang Li.Pedestrian re-identification based on fusing low-level and mid-level features[J].Chinese Optics,2016,9(5):540-546.
[12]Wu X,Kumar V,Quinlan J R,et al.Top 10 algorithms in data mining[J].Knowledge and Information Systems,2008,14(1):1-37.
[13]秦大同,詹森,漆正刚,等.基于K-均值聚类算法的行驶工况构建方法[J].吉林大学学报:工学版,2016,46(2):383-389.Qin Da-tong,Zhan Sen,Qi Zheng-gang,et al.Driving cycle construction using K-means clustering method[J].Journal of Jilin University(Engineering and Technology Edition),2016,46(2):383-389.
[14]赵文昌,李忠木.融合改进人工蜂群和K均值聚类的图像分割[J].液晶与显示,2017,32(9):726-735.Zhao Wen-chang,Li Zhong-mu.Image segmentation algorithm based on improved artificial bee colony and K-mean clustering[J].Chinese Journal of Liquid Crystals and Displays,2017,32(9):726-735.
[15]丁有伟,秦小麟,刘亮,等.一种异构集群中能量高效的大数据处理算法[J].计算机研究与发展,2015,52(2):377-390.Ding You-wei,Qin Xiao-lin,Liu Liang,et al.An energy efficient algorithm for big data processing in heterogeneous cluster[J].Journal of Computer Research and Development,2015,52(2):377-390.
[16]Forrest W.How to cut datacentre carbon emissions?[EB/OL].[2014-12-08].http∥www.computerweekly.com/Articles/2008/12/05/233748/how-tocut-data-centre carbon-emissions.htm
[17]Aïmeur E,Brassard G,Gambs S.Machine learning in a quantum world[J].Advances in Artificial Intelligence,2006,4013:431-442.
[18]Aïmeur E,Brassard G,Gambs S.Quantum clustering algorithms[C]∥Proceedings of the 24th International Conference on Machine Learning,2007:1-8.[19]Aïmeur E,Brassard G,Gambs S.Quantum speed-up for unsupervised learning[J].Machine Learning,2013,90(2):261-287.
[20]Lloyd S,Mohseni M,Rebentrost P.Quantum algorithms for supervised and unsupervised machine learning[J].ar Xiv,2013:1307.0411.
[21]Brassard G,Hoyer P,Mosca M,et al.Quantum amplitude amplification and estimation[J].Contemporary Mathematics,2002,305:53-74.
[22]Durr C,Hoyer P.A quantum algorithm for finding the minimum[J/OL].[2016-07-11].https:∥arxiv.org/abs/quant-ph/9607014.
[23]李强,蒋静坪.量子K最近邻算法[J].系统工程与电子技术,2008,30(5):940-943.Li Qiang,Jiang Jing-ping.Quantum K nearest neighbor algorithm[J].Systems Engineering and Electronics,2008,30(5):940-943.
[24]陈汉武,高越,张军.量子K-近邻算法[J].东南大学学报:自然科学版,2015,45(4):647-651.Chen Han-wu,Gao Yue,Zhang Jun.Quantum K-nearest neighbor algorithm[J].Journal of Southeast University(Natural Science Edition),2015,45(4):647-651.
猜你喜欢
延边大学学报(自然科学版)(2021年2期)2021-07-29
湖北大学学报(自然科学版)(2020年1期)2020-01-07
中国惯性技术学报(2019年6期)2019-03-04
海峡姐妹(2017年10期)2017-12-19
三联生活周刊(2017年33期)2017-08-11
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
银行家(2017年1期)2017-02-15
火控雷达技术(2016年3期)2016-02-06
中山大学学报(自然科学版)(中英文)(2015年1期)2015-06-13
中北大学学报(自然科学版)(2015年3期)2015-03-11
