
融合上下文依赖和句子语义的事件线索检测研究*
2018-03-12 08:38邱盈盈姚建民周国栋
计算机与生活 2018年3期
王 凯,洪 宇,邱盈盈,姚建民,周国栋
苏州大学 计算机科学与技术学院,江苏 苏州 215006
1 引言
事件线索检测(event nugget detection)作为信息抽取(information extraction)的一个任务,旨在从非结构化的文本中提取触发事件的文本片段,并辨别所抽取事件的真伪性。根据KBP 2015(knowledge base population)事件线索检测任务的定义,事件线索检测由两个子任务组成:(1)事件线索词识别(event nugget recognition),需要抽取出触发事件的词或短语,并识别出事件的类型;(2)事件真伪性识别(event realis recognition),在事件线索词识别的基础上,进一步辨别出事件发生的真伪性。为更好地理解KBP评测事件线索检查任务,下面给出一个完整的事件线索的结构表述。例句1中,事件线索词为“sends”(译为运送),所触发的事件类型为Transport-Person,其事件真伪性为Actual(表示事件真实发生)。本文研究将只专注于事件线索词识别部分,即找出事件线索词并判定其事件类型。
例句1France sends soldiers to Haiti Feb29.
译文:“法国于2月29日将士兵运送到海地。”
事件线索词:sends
事件类型:Transport-Person
事件真伪性:Actual
事件线索检测的研究还在起步阶段,现有的方法主要沿用 ACE 2005(automatic content extraction)事件抽取的方法。大部分前人工作将事件检测看成一个分类问题,人工精心设计了很多的词汇级和句法级的特征(特征工程),并使用已有的自然语言处理工具进行获取(如词性标注、句法分析、命名实体识别等工具)。这些方法尽管取得很好的性能,但是一方面会耗费大量的时间,另一方面会有特征稀疏和错误传递的问题(无法利用远距离的依赖信息和句子的语义信息)。
最近,深度学习已经在很多自然语言处理任务上被使用,并被证明是有效的,例如机器翻译、分词和情感分析。深度学习模型以词向量作为输入,自动学习特征,解决特征稀疏的问题,极小化对特征提取工具的依赖,减少错误传递,提高模型性能。
前人的很多研究会提取上下文特征,如句法特征,这样可以利用更大范围的信息提高识别准确度。如图1,在S1中,当判定候选事件线索词“release”的事件类型时,句子前面的词“court”可以帮助将“release”事件类型识别为“Release-Parole”。然而“court”和“release”之间没有直接的依存路径,很难使用依存句法特征建立两个词之间的联系。而常用的上下文词窗口方法可以简单增加窗口大小,将二者连接起来,但这样会加剧特征稀疏的问题,同时过大的窗口会引入大量噪音。因此,有必要在不增大词窗口和不使用依存特征的情况下,能够有效抓取远距离的依赖关系。

Fig.1 An example of event nugget detection图1 事件线索检测示例
对于一些常用词,如S2中的“loss”,由于其词义很多,仅仅依靠词的局部特征很难判定其事件类型。如果能获取S2句子的语义信息(“gambl”),会有助于推理出“loss”触发“Transfer-Money”事件而不是“Die”事件。获取句子的语义信息,将有助于提高事件线索词识别的准确性。
本文提出一种神经网络方法,能有效抓取上下文依赖,并学习句子的语义表示,用于事件线索检测。本文该方法主要由两部分组成:(1)利用双向长短时记忆网络(bidirectional long short-term memory,Bi-LSTM)获取待测词前面和后面的上下文依赖关系;(2)通过门控循环神经网络(gated recurrent neural network,GRNN)自动地从句子所有的词表示中学习句子的语义表示。这些有用的信息自然地被用来判定待测词是否是事件线索词以及是什么事件类型。在KBP 2015 Event Nugget评测提供的数据集上的实验证明,与baseline相比,本文方法取得了明显的提升。
综上所述,本文的贡献如下:
(1)提出一种新的神经网络模型,并应用到事件线索检测任务中,避免了特征工程方法带来的特征稀疏和错误传递的问题。
(2)在KBP 2015 Event Nugget评测数据集上的实验结果显示,本文网络方法比传统特征工程方法和最近提出的神经网络方法性能都要好。
2 相关工作
事件线索检测是信息抽取和自然语言处理的一个基础任务,旨在检测出文本中的事件线索词并判断事件类型。事件线索词识别方面的研究才刚刚起步,主要方法还是沿用事件抽取的方法。
现有事件抽取的方法大多数把该问题看成一个分类任务,使用词汇、句法和知识库、词典等人工设计的特征构造分类器[1-4]。尽管基于特征的方法很有效,但是实际应用时会遇到两个问题:(1)特征的选择是一个人工过程,需要领域的专业知识。这意味着在应用到新的领域时,需要做额外的研究,这样会限制快速适应新领域的能力。(2)用于提取特征的自然语言处理的工具和资源可能会出现错误,并把这些错误传递到最后的事件分类。
神经网络具有很强的特征和语义学习能力,能从数据中自动学习文本表示,而且在很多自然语言处理任务上取得了很好的性能。在事件抽取任务中,最近有两个工作[5-6]探索了神经网络在事件抽取任务上的效果,二者都利用神经网络自动学习特征,并用来判断待测词是否是触发词。其中,Chen等人[5]提出DMCNN(dynamic multi-pooling convolutional neural network)模型提取句子层次的特征和语义信息,忽略了待测词上下文信息;而Nguyen等人[6]提出了一种融合实体类别特征和词位置特征的卷积神经网络,然而该方法把上下文限制在固定的窗口下,导致长句子中词义表示的丢失。
3 任务描述
事件线索检测是KBP的一个任务,旨在从非结构化的文本中自动抽取出触发事件的词或短语,并对事件的真伪性进行识别。为了理解任务,如下给出事件线索检测中涉及的相关术语定义。
(1)事件线索词(Event Nugget):触发词或短语(通常为名词性或动词性的词或短语)。
(2)事件类型(Event Type):描述事件线索的类别,根据KBP 2015 Event Nugget评测的定义,共包含8种事件类别和38种子类别(本文针对38种事件的子类别进行研究,不考虑类别之间的层次关系)。
(3)事件真伪性(Event Realis):描述事件线索发生的真伪性,包括Actual、General和Other共3种类别。其中Actual表示根据事件线索在特定时间和地点确实发生的事件;Generic表示泛化事件,即不要求在特定时间和地点发生,例如“Use of the death penalty is rare in Indonesia.”(译文:印度尼西亚的死刑很少),事件线索词“death”表示Die事件,即为泛化事件;Other表示没有发生的事件、未来事件和条件事件等。
(4)事件线索描述(event mention):包含事件触发词的短语或句子。
本文专注于事件线索词的识别及事件类型判定。下面采用例句2进行说明:
例句2Two policemen were killed in a bomb attack in Palmanova yesterday.
译文:“昨天在帕尔马洛城,两名警察在炸弹袭击中丧生。”
事件线索检测应该正确地识别出句子中单词“killed”触发了事件,并判定触发的事件类型是“Die”事件。
4 融合上下文依赖和句子语义的事件线索检测方法
本文利用双向LSTM抓取句子中长距离依赖关系,并借助GRNN学习句子的语义表示,合并两个模型的输出,进而用来判定待测词是否为事件线索词并判断其事件类型。下面将详细介绍双向LSTM模型和GRNN模型。
本文利用word2vec工具并且选用skip-gram模型[7],在英文新闻语料上训练词向量(word embedding)来表示每个词。每个词表示成低维连续实数向量,即词向量。所有词向量存放在词向量矩阵Lw∈Rd×|V|中,d是词向量的维度,|V|是词典的大小。
4.1 LSTM模型
长短时记忆网络(long short-term memory,LSTM)[8]是循环神经网络的一个变种。普通RNN(recurrent neural network)模型在当前时刻隐藏层的状态依赖于前一个时刻。给定一个序列X=(x1,x2,…,xt,…,xn),RNN计算当前隐藏状态方法如下:

其中,f是非线性激活函数(sigmoid函数或tanh函数)。尽管RNN在很多任务上取得了很好的效果,如语音识别、语言建模和文本分类,但是由于RNN在反向传播算法(back propagation through time,BPTT)训练时会出现梯度消失和梯度爆炸的问题,很难训练学习长距离的依赖信息。
如图2,LSTM模型通过设计3个门和记忆细胞,使网络能学习何时遗忘以前的信息,何时用新的信息更新记忆细胞,从而解决普通RNN的固有问题。LSTM已经成功应用到很多NLP(natural language processing)任务中,如分词[9]、文本分类[10]和机器翻译[11]。因此,可以应用LSTM模型从数据中学习长距离的依赖信息。
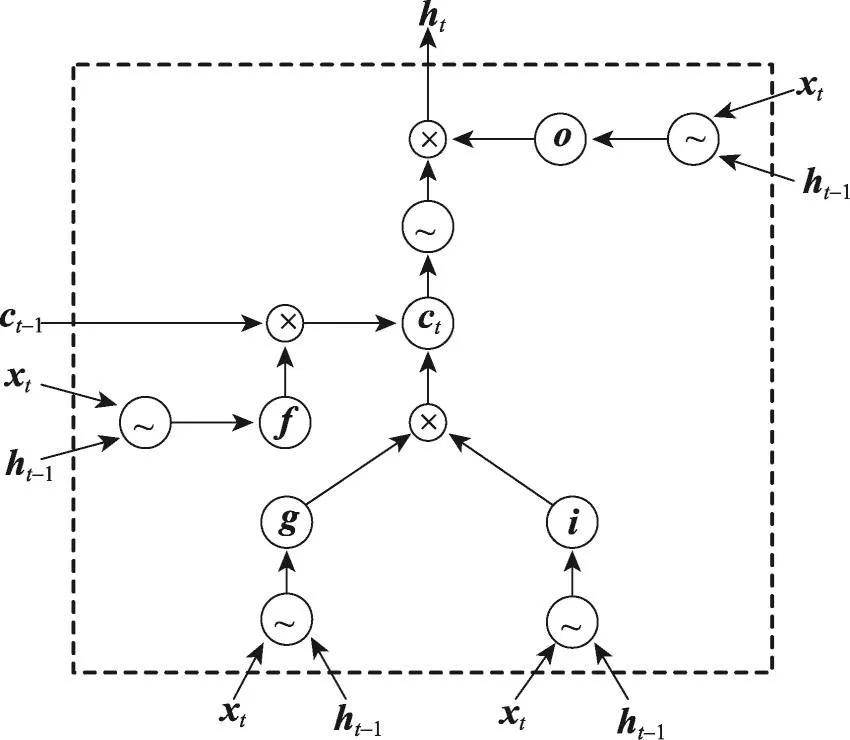
Fig.2 Structure of LSTM图2LSTM网络结构
LSTM模型的核心是记忆细胞(memory cell),用于保存历史信息。记忆单元的读写操作由输入门、输出门和遗忘门控制。门的定义和记忆细胞的更新和输出定义如下:

其中,σ表示sigmoid函数;⊙表示向量对应元素的乘积(element-wise multiplication);W、U是权重矩阵;b表示偏置;it、ft、ot分别表示t时刻的输入门、遗忘门和输出门;ct存储细胞的状态;ht是当前时刻的LSTM单元的输出。需要注意的是本文LSTM模型不包含窥视孔连接(peephole connection)。
LSTM模型构造了一个能存储历史信息的记忆细胞,从而能更好地利用长距离的依赖信息。LSTM模型在很多NLP任务中取得了比普通RNN更好的性能提升。
4.2 双向LSTM模型
单向的LSTM模型只能利用待测词之前的上下文,而无法利用待测词之后的上下文信息。在事件线索词识别任务中,人们希望对于某个待测词进行判定时既可以利用之前的上下文依赖关系,也可以利用之后的。双向LSTM模型提供了一个解决方案,通过包含两个独立的正反方向的LSTM层,融合待测词之前和之后的上下文。
对于给定的句子x1,x2,…,xt,…,xn包含n个词,每个词被表示成d维向量,一个LSTM计算待测词xt及其左边句子上下文x1:xt的表示-→ht(从左到右计算),另一个LSTM从右到左计算待测词xt及其右边的上下文xt:xn的表示←-本文将前者称为前向LSTM(forward LSTM),将后者称为后向LSTM(backward LSTM)。这两个网络使用不同的参数,组合起来称之为双向LSTM网络,如图3所示。
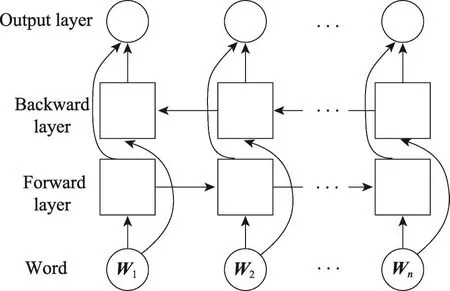
Fig.3 Bidirectional LSTM network图3 双向LSTM网络

4.3 学习句子表示
下一步将是从输入的句子学习包含语义信息的分布式向量表示(distributed vector representation)。
前人工作使用卷积神经网络(convolutional neural network,CNN)和长短时记忆网络(LSTM)计算句子的连续表示[12-13]。LSTM是当前最好的句子语义建模的方法,能从不定长的句子中学习固定长度的向量,能抓取句子中的词序信息而不依赖于句法分析。
本文使用一个经过修改的LSTM模型,将其命名为GRNN,形式化定义如下:
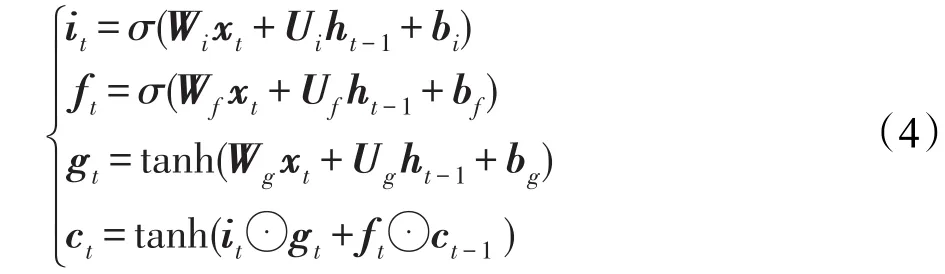
该模型可以看作是去掉输出门的LSTM模型,这样模型会倾向于不丢弃句子中任何部分的语义信息,从而能得到更好的句子语义表示。图4左边的网络结构展示了使用最后一个隐藏状态作为句子的语义表示,这是基本的表示方法。除此之外,本文将池化(pooling)应用到所有的隐藏状态c1,c2,…,cn,获取句子的语义信息。池化可从变长句子中抽取固定维度的向量。常见的池化方法有最小池、最大池和平均池,在本文提出的模型中将使用最大池。图5为本文模型的图示说明,其中h包含双向LSTM获取的上下文依赖,s表示GRNN学习得到语义表示,h与s串接后输出到包含softmax的输出层。
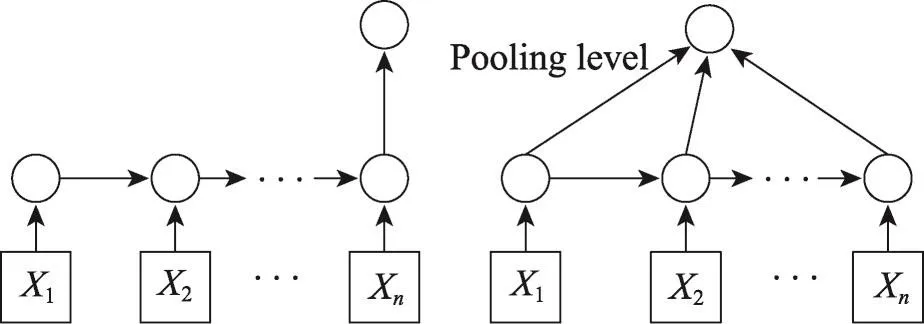
Fig.4 Learning semantic representation of sentence with GRNN图4 使用GRNN学习句子的语义表示
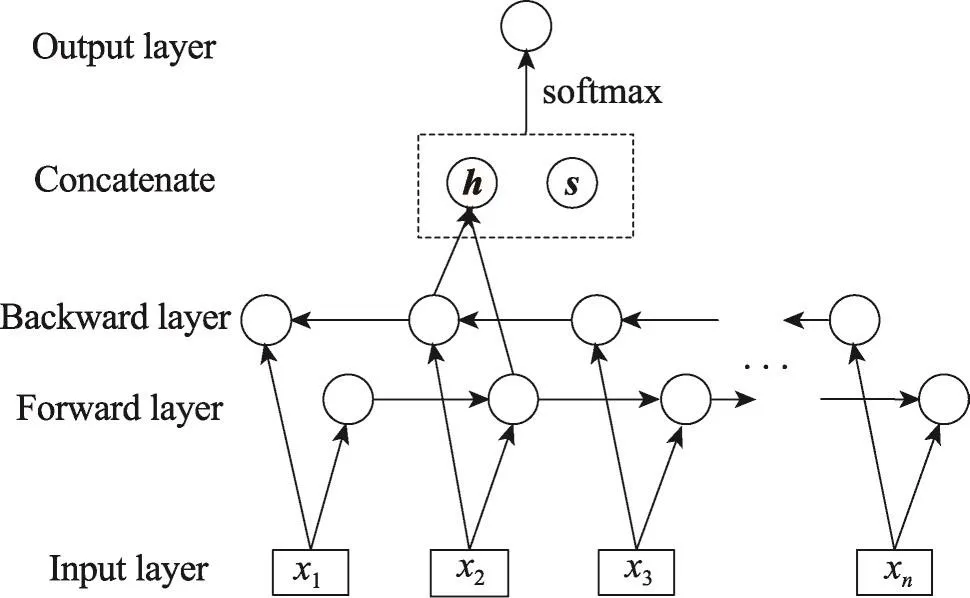
Fig.5 Illustration of this paper model图5 本文模型的图示说明
4.4 输出
将双向LSTM输出ht与学习到的句子语义表示连接起来,得到一个包含待测词上下文依赖关系和句子的语义向量F=[ht;s]。为了对待测词事件类型进行分类,首先增加一个线性层将向量F变换成长度等于类别数量C的实数向量,然后增加softmax层使实数向量转换成条件概率分布,计算过程如下:

其中,W为转移矩阵;O是网络的输出结果,O的维度C等于事件类型加上“Null”(表示待测词不是事件线索词)的个数。为了防止过拟合,在输出层之前(倒数第二层)增加dropout层[14]。
4.5 训练
在模型训练部分,本文使用事件线索的正确分布Pgold(x)和模型预测分布P(x)之间的交叉熵(cross entropy)加上L2范式作为损失函数,定义如下:
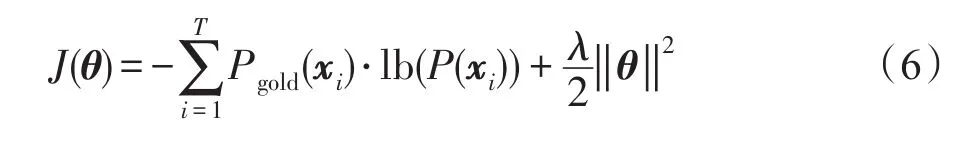
其中,T表示训练集数量;C是事件类型加上“Null”(表示待测词不是事件线索词)的个数;xi表示待测词;θ表示整个模型所使用到的参数;Pgold(xi)采用one-hot表示,维度与类别数目一致,但是只有正确的事件类型对应的那一维是1,其他维度都为0。
为了计算模型的参数θ,本文使用带有Adadelta更新规则[15]的随机梯度下降法来极小化损失函数。
5 实验
5.1 实验数据和评价方法
本文针对事件线索检测中的事件线索词识别的任务,使用KBP 2015 Event Nugget评测提供的训练数据和测试数据,训练数据包含158篇文档,测试数据包含202篇文档。为了便于调节模型参数,本文随机从训练数据中选取15篇作为开发集,其余143篇作为训练集。测试数据中的全部202篇文档作为测试集。
实验采用准确率(Precision)、召回率(Recall)和F1值作为评价标准,并使用KBP 2015官方提供的评价工具进行计算。为了便于说明,后面将本文提出的模型简写成CSNN(context dependency and semantic representation based neural network)。
5.2 参数设置
神经网络的超参数对模型的性能有显著的影响,本文在开发集上调节模型的超参数。词向量的维度设置为200维,LSTM和GRNN的隐藏层维度均为100。使用带mini-batch的随机梯度下降法训练,并使用AdaDelta更新规则。AdaDelta包含两个参数ρ和ε,实验中ρ设定为0.9,ε设定为1E-6。对dropout层,dropout rate设定为0.5。使用-0.2到0.2之间均匀分布随机初始化模型中的矩阵参数。
实验选用的词向量是利用word2vec工具在英文新闻语料上使用skip-gram算法训练得到的。
5.3 对比系统
本文使用以下系统与本文提出的模型进行对比。
(1)ME(maximum entropy model):使用 Li[1]在ACE事件抽取任务中所用的词汇层面和句法层面的特征。
(2)CRF(conditional random field):特征与 ME一致。
(3)DMCNN:Chen等人[5]利用DMCNN模型在ACE 2005事件抽取任务上取得很好的效果,本文实现了该模型并应用到事件线索任务上。
(4)CNN:Nguyen等人[6]利用卷积神经网络,并结合实体和位置信息,学习到有效的特征表示。
(5)BLENDER:KBP 2015事件线索检测任务中取得最好性能的系统,利用标签传播算法扩大数据集,并使用最大熵分类器对候选词进行分类。
系统ME和CRF是传统的基于特征工程的方法,而系统DMCNN和CNN使用神经网络模型,能自动学习特征。因为BELNDER系统利用标签传播算法扩大数据集,所以后面的实验结果分析中没有与其进行详细对比。
5.4 实验结果
表1给出了所有方法在KBP 2015测试集上的实验结果。从表1中可以看出:在事件线索词识别上,本文方法CSNN相比ME和CRF的准确率虽然有所降低,但召回率提升很多,最终F1值分别提升5.70%和4.90%;在事件线索词分类上,CSNN的F1值相比ME和CRF分别提升1.58%和2.95%。CSNN能取得这样的性能结果,说明本文方法是有效的。ME和CRF是传统方法,使用了丰富的人工设计的特征。而CSNN只使用了词向量,不需要其他特征。CSNN避免了传统方法非常耗时的特征选取过程,节省人力和时间。除此之外,CSNN没有使用复杂的特征提取工具来抽取特征,避免了错误传递。

Table 1 Overall performance of different methods on test data表1 各方法在测试集上的性能
Nguyen提出的CNN模型是通过设置多个上下文词窗口,利用卷积神经网络抓取待测词周围的上下文特征。但是这样一方面无法利用远距离的上下文,另一方面上下文窗口增大后会引入大量噪音。本文提出的CSNN模型通过双向LSTM能有效抓取远距离的上下文依赖信息,并且LSTM中的遗忘门能过滤掉很多噪音。CNN没有利用句子的语义信息,因此从表1可以看出,CSNN在事件线索识别和分类上的性能(F1值)都比CNN要好很多。
DMCNN使用神经网络模型,能从文本中自动抽取词层面和句子层面的特征。从表1中可以看出,DMCNN比ME和CRF在事件线索词识别和分类上的性能都有所提升。然后,DMCNN忽略了上下文的词依赖,而这对线索词识别是很有帮助的。本文提出的CSNN利用双向LSTM抓取句子中上下文词依赖信息,提升时间线索词识别和分类的性能。从表1中可以看出,在事件线索词识别和分类上,CSNN较DMCNN的F1值分别提高3.29%、1.05%。
5.5 CSNN学习语义表示的效果
本节将验证CSNN学习得到的语义表示是有效的。设计了两个方法作为baseline系统与CSNN进行对比:Bi-LSTM和Bi-LSTM+CNN。Bi-LSTM可以看作是CSNN去掉GRNN剩下的部分(CSNN-GRNN),不学习句子的语义表示,只考虑句子的上下文依赖;Bi-LSTM+CNN是将CSNN中的GRNN和pooling替换成CNN,通过CNN学习句子的表示。
表2展示了Bi-LSTM、Bi-LSTM+CNN和CSNN的结果。从表2中可以看出,Bi-LSTM(CSNN-GRNN)相对CSNN在事件线索词识别和事件线索词分类上的F1值分别下降了4.20%和1.74%。这说明CSNN学习得到的语义表示是有效的,能提高事件线索词的识别性能。Bi-LSTM+CNN在事件线索词识别和事件线索词分类上的F1值比要Bi-LSTM(CSNNGRNN)高,但比CSNN分别低3.51%和0.85%,证明了GRNN比CNN能更好地学习句子的语义表示。

Table 2 Performance of CSNN without semantic learning and replaced by CNN表2 CSNN去掉语义学习以及换成CNN后在测试集上的性能对比
5.6 CSNN过滤上下文噪音的效果
CSNN通过使用双向LSTM,不仅可以抓取远距离的上下文依赖,还能通过LSTM的遗忘门过滤掉待测词上下文中的噪音。为了便于比较,本文将CSNN中的双向LSTM的遗忘门去掉,这样就会一直记录历史信息,即上下文词信息。这样的模型命名为CSNN-f,与CSNN相比只是去掉了双向LSTM中的遗忘门,其他都一样。
实验结果如表3所示。CSNN去掉遗忘门后,事件线索词识别和分类的性能都有所下降,尤其是线索词识别中F1值下降了2.23%。这是因为去掉遗忘门后,CSNN-f将会保存所有的历史信息,而部分历史信息包含噪音数据,是有害的。CSNN可以通过遗忘门的开关将这些噪音过滤掉。

Table 3 Performance of CSNN and CSNN without forgetgate表3 CSNN去掉遗忘门后性能对比
6 总结
本文提出了一种新的事件线索词检测方法,抓取上下文依赖并学习句子的语义表示。本文方法利用双向LSTM模型获取待测词前后的上下文依赖信息,使用GRNN学习待测词所在句子的语义表示。从实验结果可以看出,本文方法在事件线索词识别和分类上的性能均比其他baseline方法高,证明了本文方法是有效的。较传统方法,本文方法不使用任何自然语言处理工具,避免了错误传递;与现有的神经网络方法相比,本文方法能有效利用上下文依赖和句子的语义信息,提高了事件线索检测的性能。
[1]Li Qi,Ji Heng,Huang Liang.Joint event extraction via structured prediction with global features[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics,Sofia,Aug 4-9,2013.Stroudsburg:ACL,2013:73-82.
[2]Liao Shasha,Grishman R.Using document level cross-event inferent to improve event extraction[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics,Uppsala,Jul 11-16,2010.Stroudsburg:ACL,2010:789-797.
[3]Ji Heng,Grishman R.Refining event extraction through crossdocument inferent[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics,Columbus,Jun 15-20,2008.Stroudsburg:ACL,2008:254-262.
[4]Hong Yu,Zhang Jianfeng,Ma Bin,et al.Using cross-entity inference to improve event extraction[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies,Portland,Jun 19-24,2011.Stroudsburg:ACL,2011:1127-1136.
[5]Chen Yubo,Xu Liheng,Liu Kang,et al.Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing,Beijing,Jul 26-31,2015.Stroudsburg:ACL,2015:167-176.
[6]Nguyen T H,Grishman R.Event detection and domain adaptation with convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics,and the 7th International Joint Conference on Natural Language Processing,Beijing,Jul 27-29,2015.Stroudsburg:ACL,2015:365-371.
[7]Le Q,Mikolov T.Distributed representations of sentences and documents[C]//Proceedings of the 31st International Conference on Machine Learning,Beijing,Jun 21-26,2014:1188-1196.
[8]Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[9]Chen Xinchi,Qiu Xipenng,Zhu Chenxi,et al.Long shortterm memory neural networks for Chinese word segmentation[C]//Proceeding of the 2015 Conference on Empirical Methods in Natural Language Processing,Lisbon,Sep 17-21,2015.Stroudsburg:ACL,2015:1197-1206.
[10]Sutskever I,Vinyals O,Le Q.Sequence to sequence learning with neural networks[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems,Montreal,Dec 8-13,2014.Cambridge:MIT Press,2014:3104-3112.
[11]Liu Pengfei,Qiu Xipeng,Chen Xinchi,et al.Multi-timescale long short-term memory neural network for modelling sentences and documents[C]//Proceeding of the 2015 Conference on Empirical Methods on Natural Language Processing,Lisbon,Sep 17-21,2015.Stroudsburg:ACL,2015:2326-2335.
[12]Johnson R,Zhang Tong.Effective use of word order for text categorization with convolutional neural networks[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Denver,May 31-Jun 5,2015.Stroudsburg:ACL,2015:103-112.
[13]Kim Y.Convolutional neural networks for sentence classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing,Doha,Oct 25-29,2014.Stroudsburg:ACL,2014:1746-1751.
[14]Hinton G E,Srivastava N,Krizhevsky A,et al.Improving neural networks by preventing co-adaptation of feature detectors[J].Computer Science,2012,3(4):212-223.
[15]Zhang Rui,Gong Weiguo,Grzeda V,et al.An adaptive learning rate method for improving adaptability of background models[J].IEEE Signal Processing Letters,2013,20(12):1266-1269.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
人间(2015年21期)2015-03-11
