
基于耦合相关度的空间数据查询结果自动分类方法
2018-03-20 00:43毕崇春孟祥福张霄雁唐延欢唐晓亮梁海波
计算机应用 2018年1期
毕崇春,孟祥福,张霄雁,唐延欢,唐晓亮,梁海波
(1.辽宁工程技术大学 电子与信息工程院,辽宁 葫芦岛 125105; 2.辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)(*通信作者电子邮箱marxi@126.com)
0 引言
随着移动网络的普遍应用,对于兴趣点(Point Of Interests, POI),如饭店、宾馆、旅游景点等的空间Web对象(简称空间对象)的查询已成为当前空间数据库和信息检索领域的研究热点。空间对象一般包含两类信息:空间信息(Spatial Information,如经纬度)和描述信息(Descriptive Information,如对象名称、特征等信息)。空间查询条件的基本形式为:{位置,〈关键字1,关键字2,…,关键字m〉},其中“位置”代表空间信息查询条件(通常用一对经纬度或一个地理范围表示);关键字代表文本查询条件[1]。研究发现,目前大约有五分之一的Web查询都与空间位置相关[2],并且这种类型查询的比例还在不断增长。然而,由于空间数据库通常蕴含海量数据且空间查询又通常是试探性的,因此一个普通查询往往会返回大量结果,这种情况被称为“信息过载”问题。例如,当用户向Yahoo房地产网站提交了一个寻找“位于西雅图市中心(位置查询)、价格较低(关键字查询)”的房屋查询条件后,系统会返回数以千计的房产信息。为了找到真正感兴趣的信息,用户需要逐条检查每个结果对象的相关性,这将浪费大量时间和精力。
为了解决信息过载问题,一些研究工作提出根据空间对象与查询条件的位置相近度和文本相关度对查询结果进行top-k排序[3-7]。然而,这种方法返回的空间对象的排序次序固定,不能为用户提供多样选择,而不同用户的需求可能是不同的。文献[10]指出,分类与排序是解决多查询结果问题的两个互补手段。本文提出一种空间对象查询结果分类方法,该方法能够在查询结果集上动态产生一棵分层的分类树,树的每个叶节点包含一类在位置和语义上都相近的空间对象,用户通过检查分类树中间节点的标签,可以逐步定位到其感兴趣的信息。下面用一个简单例子来说明本文分类方法的基本思想。
例1 对于Yahoo房地产搜索网站,图1给出了利用本文方法在查询条件“位于西雅图市中心且价格≤250 000”的查询结果上生成的一棵分类树。该树的每个节点上都带有一个描述房产特征信息的标签,用户可根据树各节点标签进行导航,进而找到他们所感兴趣的房子。
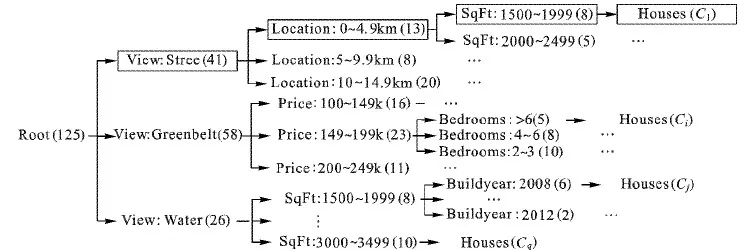
图1 Yahoo房产网站上的空间查询结果分类树实例
本文的分类方法由两个步骤构成:第一步是在离线阶段分析空间对象之间的耦合关系(本文的耦合关系是指空间对象之间在位置信息和描述信息上存在的显式/隐式关联关系),并据此对空间对象进行聚类。现实中,如果用户对某个空间对象感兴趣,那么他通常也会对与该对象位置和语义相近的一类对象感兴趣,因此每个空间对象聚类都对应一种类型的用户需求。第二步,对于一个用户查询,根据在离线阶段产生的空间对象聚类,在查询结果集上利用改进的C4.5决策树算法自动生成一棵分类树,用户通过检查分类树标签最终导航到其感兴趣的结果对象。
1 相关工作
近年来,随着Web上的空间对象日益增多和移动网络的普遍应用,空间关键字的top-k查询和排序方法受到了广泛关注。根据文献[8-9],这些空间查询方法可分为三类。1)布尔kNN(kNearest Neighbor)查询[5]:该类方法用于检索那些距离查询位置最近且文本描述包含所有查询关键字的前k个空间对象。2)top-k范围查询[6]:用于检索那些与查询关键字具有最高文本相关度且位于查询区域内的前k个空间对象。3)top-kkNN查询[7]:该类方法根据空间对象的位置相近性和文本相关性进行top-k检索和排序,排序分数根据对象到查询位置的距离和空间对象的文本描述与查询关键字的文本相关度的权重进行评估。
就我们所知,目前还没有对空间数据查询结果分类方法的研究工作。在关系数据库查询领域,文献[10]和[11]分别提出了基于贪心算法(Greedy Algorithm)和基于决策树分类算法的查询结果分类方法。Chakrabarti等[10]提出了一种利用贪心算法构建查询结果分类树的方法,该方法利用系统中的历史查询数据推断大多数用户的偏好,据此作为当前用户对每个分类属性感兴趣的概率。文献[11]利用了C4.5决策树算法,提出了一种两步解决方法:第一步对用户的历史查询数据聚类;第二步构建一棵搜索树来实现用户的个性化查询。然而,使用该方法构建分类树存在以下两个缺点:1)元组聚类仅依赖于用户历史查询数据,若历史查询数据不充分或不准确,就会导致算法失效;2)数值属性值域的划分采用二元划分,然而这种划分在实际应用中通常会导致不合适(过大或过小)的数值区间分割。本文方法借鉴了上述在关系数据库查询领域对查询结果进行分类的思想来对空间查询结果进行分类。需要指出的是,空间数据所包含的信息比关系数据更为复杂(包含位置和描述信息),对象聚类和结果分类需要同时考察空间对象在位置和描述信息方面的相关性。
在文本分类[12-14]和Web查询结果分类[15-16]方面,研究者也进行了大量研究,但是分类对象与本文的分类对象不同:本文是对空间对象进行分类,空间对象同时包含了空间位置信息和文本描述信息,而文本分类方法仅能对文本信息进行分类。本文提出的分类树构建方法目的在于搜索代价最小化,而现存的文本分类方法仅考虑如何准确划分数据。
2 相关定义和解决方案
本章首先给出分类树及其搜索代价定义,然后描述解决方案。
2.1 查询结果分类树
空间对象包含位置信息和描述信息,本文将描述信息转换成〈属性,值〉的形式,这样每个空间对象的描述信息将构成一个关系元组。例如,在例1的Yahoo房产信息中,一个房屋的描述信息将由〈Price,14 999〉,〈View,water〉,〈Bedrooms,5〉,〈SqFt,2 000〉等数据单元构成。
用D表示一个包含n个空间对象的数据集,A表示D中空间对象描述信息的属性集{A1,A2,…,Am}。在此基础上定义查询结果分类树和预计搜索代价。
定义1 分类树。一个分类树T(V,E,L)是由一个节点集合V、一个边集合E和一个标签集合L三部分构成。每个节点v∈V都有一个描述该节点特征的标签lab(v)∈L,它需要满足如下条件:1)该标签是指定在某个属性上的等值或范围查询条件(如Price<100 000或Price between 100 000 and 150 000);2)节点v中包含的一组空间对象N(v)必须满足它所有前驱(包括它自身)上的标签;3)一个中间节点的所有孩子节点上的标签都指定在同一属性上(该属性被称为分类属性),这些标签构成了对节点v中所有N(v)个对象的不相交划分。
2.2 预计搜索代价
给定一个空间查询结果分类树T,用v表示一个叶节点,该节点包含了T中一组空间对象N(v),Cj是集合C中的一个聚类(该聚类中包含了一组位置相近和语义相关的空间对象集合),Cj∩v≠∅表示叶节点v中包含了聚类Cj中的空间对象,Anc(v)表示节点v的前驱集合(包括v本身在内),但不包含根节点;Sib(v)表示节点v的兄弟集合(包含v本身在内)。令K1和K2分别表示访问叶节点中一个空间对象以及访问一个中间节点标签的代价,Pj表示用户对于聚类Cj感兴趣的概率。
定义2 预计搜索代价。用户使用分类树找到所有相关对象的预计搜索代价为:
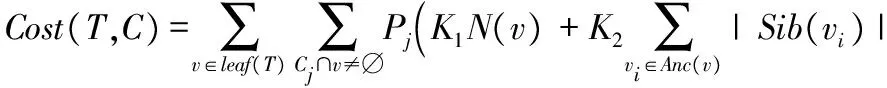
(1)
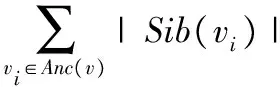
例如,假设某用户对图1所示的分类树最上面的叶节点(“SqFt:1 500~1 999”)感兴趣的概率是100%,再假设K1=K2=1,则用户访问叶节点“SqFt:1 500~1 999”的搜索代价为:3(检查根下3个子节点标签的代价)+3(检查中间节点“View: Street”下3个孩子标签的代价)+2(检查中间节点“Location: 0~4.9 km”下2个孩子标签的代价)+8(检查叶节点“SqFt: 1 500~1 999”下8个空间对象的代价)=16。
2.3 解决方案
分类树构建的解决方案如下:
1)空间对象耦合相关度评估与聚类。
首先利用欧氏距离计算两个空间对象在空间位置上的距离;然后利用语义相关度评估方法计算空间对象在描述信息上的语义相关度;最后,用式(2)将位置关系和语义关系相融合得到两个空间对象oi和oj之间的耦合相关度:
Sim(oi,oj)=α·E_sim(oi,oj)+(1-α)·S_sim(oi,oj)
(2)
其中:α∈[0,1]是一个调节参数,E_sim()和S_sim()分别代表oi和oj之间的位置相近度和语义相关度。
根据空间对象之间的耦合关系,利用基于概率密度估计的聚类方法把空间对象划分为q个类别{C1,C2,…,Cq},使得每个类别中包含的空间对象在位置和语义上都比其他类中的对象更为接近。
2)分类树构建。
对于一个空间数据库D、一个聚类集合C和一个空间查询Q,本文目的是构建一棵分类树T(V,E,L),使得:①该树中的叶节点包含了D中满足查询Q的所有空间对象;②不存在另外一棵树T′既满足条件1)又使得搜索代价Cost(T′,C) 算法1 查询结果分类树生成过程。 输入:空间数据库D,聚类集合C和空间查询条件Q。 输出:分类树T。 1)离线阶段。计算空间数据库D中所有空间对象之间的耦合相关度,在此基础上对D中的空间对象进行聚类,得到一个不相交的空间对象聚类集合C={C1,C2,…,Cq},其中每个聚类Cj{1≤j≤q}都关联一个用户对其感兴趣的概率Pj。 2)在线阶段。在查询Q返回的结果集T上,使用C1,C2,…,Cq作为类标签,利用改进的C4.5算法构建一棵具有最小预计搜索代价Cost(T,C)的分类树。 算法1的复杂度分析 在离线阶段(步骤1))需要计算出D中任意一对空间对象之间的耦合相关度,如果D中有n个空间对象,则离线阶段的计算复杂度为O(n2)。为了降低离线计算的工作量,可以以固定时间间隔计算耦合相关度或当数据更新程度较大时再计算耦合相关度。对于在线阶段(步骤2))的计算复杂度,本文将在第3章的算法3中进行分析。 本章首先描述空间对象之间的耦合相关度评估方法,然后提出如何根据空间对象的耦合相关度对其进行聚类。 空间对象之间的耦合相关度是由空间对象在位置上的相近度和描述信息上的语义相关度构成。 1)空间对象的位置相近度。 欧氏距离是现有研究工作中最常用的评估空间对象之间距离的方法[3,6,9],本文也采用欧氏距离评估空间对象之间的位置距离,空间对象oi和oj的距离定义如下: (3) 其中,n表示空间对象的空间维度。基于式(3),空间对象oi和oj之间在距离上的相近度定义如下: E_Sim(oi,oj)=1-Dist(oi,oj)/Maxdist (4) 式(4)是对位置相近度的归一化处理,其中Maxdist代表空间数据库中所有空间对象之间的最大距离。 2)空间对象的语义相关度。 现有方法通常采用VSM(Vector Space Model)及其改进方法评估两个文本之间的相关度,但现实中空间对象的描述之间通常存在复杂的语义关系。本文提出一种语义相关度评估方法。该方法是对文献[18]中提出方法的一种改进,其基本思想是:对于同一属性下的两个值,如果它们在同一属性值域中出现的次数(或者发生频率)类似,则表示这两个值具有相关性,这反映了一个属性中不同属性值之间的内耦合关系(intra-coupling relationship)。如前文所述,空间对象的描述信息将首先被转换成〈属性,值〉形式的关系元组,因此可使用属性值的出现频率来计算同一属性下不同值之间的内耦合相关度。具体来讲,对于包含n个空间对象的空间数据集D,首先将所有空间对象的描述信息转换成一个具有m个属性{A1,A2,…,Am}和n条元组{t1,t2,…,tn}的关系表。在此基础上,属性Aj中的一对属性值x和y的内耦合度相关度(Intra-similarity)计算方法如下: (5) 其中,NAj(x)和NAj(y)分别表示属性Aj中包含属性值x和y的元组个数。从式(5)可以看出,如果两个属性值在同一值域中的出现频率越高,则它们之间的内耦合相关度越大。 同一属性上的两个属性值之间除了具有内耦合关系外,它们的相关度还受到其他属性的影响,这里称之为间耦合相关度。属性值之间的间耦合相关度评估的基本思想是:对于属性Aj中的两个属性值x和y,假设U是x和y在其他属性Ak上共同出现的属性值的交集。如果U非空,则称x和y在属性Ak上相关。 基于上述思想,属性值x和y在属性Ak上的间耦合相关度定义为: (6) 其中:U是x和y在属性Ak上的交集,u是U的一个元素(即,u与x和y在相同元组中共同出现过),PAk |Aj(u|x)(以及PAk |Aj(u|y))是u关于x(和y)的信息条件概率(Information Conditional Probability, ICP),计算方法如下: PAk |Aj(u|x)=|TAk(u)∩TAj(x)|/|TAj(x)| (7) 其中:TAj(x)表示D中包含Aj=x的元组集合,TAk(u)表示D中包含Ak=u的元组集合。也就是说,u对于x的ICP指的是当x在关系表中出现时,u与x共同出现的概率。可以看出,对于同一个属性的两个值,如果它们在其他属性上的ICP越高,那么这两个值的间耦合相关度就越高。 式(8)给出了属性值〈x,y〉在所有其他属性上的间耦合相关度计算方法: (8) 接下来,把属性值x和y之间的内耦合和间耦合相关度进行结合就可得到它们之间的语义相关度,即: S_SimAj(x,y)=β*IaSAj(x,y)+(1-β)*IeSAj(x,y) (9) 其中,β(β∈[0,1])是一个调节参数,用来调整内耦合和间耦合相关度在最终的语义相关度中的作用。 最后,空间对象oi和oj在描述信息上的语义相关度可定义为它们在所有属性上的内耦合和间耦合相关度的结合: (10) 其中,wk代表Ak的属性权重,m是属性个数。 3)空间对象的耦合相关度。 给定空间对象oi和oj在位置上的相近度和在描述信息上的语义相关度,它们之间的耦合相关度可以用式(2)来计算。接下来,本文将论述如何利用空间对象之间的耦合相关度对它们进行聚类。 本文提出的空间对象聚类的基本思想是:首先利用概率密度估计方法评估空间对象的典型程度,然后提取前k个最具有代表性的空间对象,最后把其他对象按其对代表性对象的耦合相关度分配到不同聚类中。 1)概率密度估计方法。 高斯核函数是概率密度估算中的常用方法,当仅知道空间对象的耦合关系距离矩阵时,可以使用该方法找出空间对象集合中的代表性对象[19]。对于一个空间对象集合D=(o1,o2,…,on),对象o的概率密度f(o)可以表示为: (11) 根据空间对象的典型程度,可以选出前k个典型程度最高的对象作为代表,其他对象按其对代表对象的耦合相关度进行聚类,这样可将空间对象划分成k个类别。 2)空间对象的聚类算法。 给定一个空间数据库D,选取前k个代表性对象的准确方法是利用式(11)逐个计算每个空间对象的典型程度。然而,在数据规模很大的情况下,逐个计算空间对象的典型程度具有很高复杂度,因此需要考虑一种近似算法。本文提出一种基于淘汰思想的聚类方法,该方法的优点是简便且具有较高准确性,其聚类过程为: a)将空间数据库D随机划分成若干个小组,每个小组都包含u个对象,即将D划分成了「n/u⎤个小组,接着在每个小组内计算所有对象的典型程度,选取每个小组中典型程度最高的对象构成一个新的集合,然后从D中去除其他对象。 b)对于新得到的集合,重复上述过程,直到D中只剩下一个对象,将该对象放入top-k候选对象集合中(上述过程记为一次选取过程)。 c)为了保证选取对象的准确性,需要将上述选取过程重复执行v次(记为一轮),这样top-k候选对象集合中最多会包含v个对象,接着在最初的空间数据库D上计算这v个对象的典型程度,最后将具有最高典型程度的对象作为当前轮次的选取结果,并从D中将该对象去除。 上述a)~c)过程重复k轮,这样就能得到k个近似于准确解的对象。 d)将D中剩余对象依次与这k个代表性对象分别比较耦合关系距离,各自划分到与代表性空间对象最相近的类别中。 算法2 top-k代表性对象近似选取和聚类算法。 输入:空间数据库D,验证次数v,正整数k,小组大小u。 输出:top-k个代表性对象及其对应的聚类。 fori=1 tokdo fori=1 tovdo repeat 划分D成为若干小组g,每个小组有u个对象 for each小组gdo 计算g中每个对象在g中的典型程度 从g中选出典型程度最高的对象,将g中其他对象从D中移除 end for untilD中仅有一个对象 把得到的典型程度最高的对象放入候选集合中 end for 在D上计算候选集合中每个对象的典型程度,输出一个典型程度最高的对象作为第i次选出的代表性空间对象 end for 将其他对象按其与代表性对象的距离进行聚类 本文借助查询历史评估用户对空间对象聚类感兴趣的概率,其直觉是如果某个聚类中的空间对象被用户查询的次数越多,说明用户对该聚类感兴趣的概率就越大。 给定一个空间对象聚类Cj,先统计查询历史H中能够返回Cj中任意一个对象的查询,这些查询构成一个集合Sj,即Sj={QCj|∃Qi∈H,使得oi(oi∈Cj)能够由Qi返回}。这样,对于每一个聚类Cj,可通过计算Sj中包含的查询个数与查询总数之比得到用户对该聚类感兴趣的概率,即Pj=Sj中包含的查询个数/H中的查询总数。 本章首先提出空间对象查询结果分类树的构建算法;然后描述对于文本信息中的分类型属性和数值型属性的划分标准;最后给出分类树构建算法描述。 本文提出了基于C4.5决策树算法的查询结果分类树构建方法。由于C4.5算法需要对属性进行划分,空间对象的描述信息主要包含文本属性和数值属性,因此下面分别描述文本和数值属性的划分标准。 1)文本属性的划分。 对于每一个不同的文本值,在查询结果分类树上产生一个新的子树,并且在该子树上计算信息增益。 2)数值属性的划分。 本文借助用户的查询历史划分数值属性值域。对于数值属性Ai,用vmin和vmax分别表示Dom(Ai)的最小值和最大值。首先考虑简单划分的情况,假设仅将Dom(Ai)划分成两个互不相交的数值区间,即[vmin,v]和(v,vmax]。如果在查询历史中,大多数查询范围是以点v开始或结束,则点v是一个最佳分割点。因为通过查询历史可知,大多数用户是对以点v划分的两个数值区间其中之一感兴趣。 对于查询历史中指定在属性Ai上的范围查询,令Nv-start和Nv-end分别代表这些查询中以点v开始或结束的查询个数,然后用Nv-start和Nv-end之和代表点v的“分割能力”。很明显,如果查询历史中以点v开始或结束的范围查询数量越多,说明认为点v是一个好的分割点的用户越多,那么点v的分割能力就越强。假设要将Dom(Ai)划分为k个数值区间,采用上述方法,那么需要选取具有最高分割能力的(k-1)个点。需要指出的是,数值属性的候选分割点是通过在该属性值域区间内以固定数值间隔获得的。 基于上述思想,算法3给出了基于改进决策树算法的查询结果分类树构建过程。 算法3 查询结果分类树构建算法。 函数:BuildTree(A,R,C,λ) 输入:空间对象描述信息的属性集A,结果对象集合R,C是R中每个对象在聚类中对应的标签,终止阈值λ。 输出:查询结果分类树T。 创建一个根节点r ifR中所有对象有同样的类标签,终止算法 for每个属性Aj∈A ifAj是一个文本属性then forAj的每个属性值vdo 在当前根节点下创建一个分支,将满足条件“Aj=v”的那些对象加入到该分支中 计算gaing(Aj,Tj),Tj是由划分属性Aj而产生的子树 else forAj的每个范围[lowi,upi] do 在当前根节点下创建一个分支,将满足条件“lowi≤Ai 计算gaing(Aj,Tj),Tj是由划分属性Aj的值域产生的子树 end if end for 选择具有最大g(Aj,Tj)的属性Aj,从A中移除Aj ifg(Aj,Tj)>λthen 用子树Tj代替r,对于Tj(用Rk表示leafk中的对象集合)中每个叶节点leafk,递归执行BuildTree(A,Rk,C,λ) end if 利用算法3,可在查询结果集上动态地生成一个查询结果分类树,用户可通过检查标签的方式自左至右或自上而下访问该树,并最终定位到其感兴趣的叶子节点。 算法3的复杂度分析 假设结果集中有n个空间对象,m是分类属性个数,k为类别数;在计算某个属性的信息增益时,可以采用一些优化算法。本文先按该属性的属性值对结果中的所有对象进行排序,然后对该属性上的所有不同属性值进行一次性的信息增益计算,这样该属性上的信息增益计算时间复杂度为O(k)。对于一个树节点,由于每次计算信息增益的复杂度为O(k),并且最多有m个候选分类属性以及n种可能的划分(最坏情况就是该属性下有n个不同的属性值),因此对一个节点的所有可能划分进行信息增益计算的复杂度为O(mnk)。根据文献[11]对决策树的分析,生成的查询结果分类树的深度为logn,则算法3总的时间复杂度为O(mnklogn)。 所有实验在Windows 2007操作系统,Intel P4 3.2 GHz CPU和8 GB内存的PC机上运行,使用下列真实数据来评估算法效果和性能。 数据集 测试数据是从Yahoo房地产网站提取的包含100 000个房屋信息的房地产数据集。每个房屋都包含位置信息和描述信息,位置信息用经度和纬度表示,描述信息由{Price,City,SqFt,Bedrooms,Livingarea,Schooldistrict,View,Neighborhood,Pool,Garage,Boatdock,Buildyear}属性来描述,其中Price,SqFt,Bedrooms和Buildyear是数值属性,剩余是文本属性。 查询历史 邀请50名本科生作为测试者,他们作为不同类型的用户向房地产数据集提交空间查询,利用这种方式收集了500条查询作为查询历史,用于数值属性值域的划分和用户对空间对象聚类感兴趣概率的估计。 所有算法采用Java编写,使用R-tree[21]建立空间对象索引,空间对象数据表增加一列用于存放每条房屋记录的类标签,查询结果分类树构建算法(算法3)的终止阈值λ设为0.005。 对比方法 不同聚类方法得到的聚类结果不同,进而影响到查询结果分类树的搜索代价,本文选取了两种聚类方法:最远距离优先的聚类方法和基于淘汰的聚类方法(本文方法),然后对基于不同聚类方法构建的查询结果分类树的实际搜索代价进行对比。 最远距离优先聚类方法的基本思想是:首先从空间对象集合中随机抽出1个对象,然后从剩余对象中选取与该对象耦合关系距离最大的对象,并将其从集合中移除,下一步再从剩余对象中选出与上一个选出对象耦合关系距离最大的对象,重复上述步骤,直到k个对象被选出为止。最后,把剩余对象按其与这k个对象的耦合关系距离分别划归到相应类别中。 该实验目标是评估空间对象文本值语义相关度评估方法的合理性。表1分别给出了在不同大小的数据集下与给定文本值最相关的前三个文本值。注意,在该实验中式(9)的参数β设为0.5,也就是说在评估文本值的语义相关度时内耦合度和间耦合度起到同等重要的作用。 表1 不同大小数据集下对于给定属性值的top-3个相关文本值 从表1中可以看出,与给定值最为相关的前三个文本值之间的语义相关度是合理的。还可以看出,从10 000,20 000个房屋数据集中获取的相关度值低于从50 000个房屋数据集中获取的相关度值,但相关度值的变化程度不大,并且相关度值大小的相对顺序没有发生改变。由此可见,本文提出的文本值之间的语义相关度评估方法是合理稳定的。 该实验目的是测试本文提出的查询结果分类方法的实际搜索代价,同时也对基于不同聚类方法构建的查询结果分类树的实际搜索代价进行对比。实际搜索代价定义如下: (12) 与定义2中的预计搜索代价不同,实际搜索代价是用户通过使用查询结果分类树找到感兴趣对象而真正访问过的中间节点数和叶节点中的对象数。假设访问中间节点标签和访问叶节点中对象的代价是相等的,即K1=K2=1,实际搜索代价越低,表明查询结果分类方法的效果就越好。 为了评估实际搜索代价,首先邀请10名测试者,每一名测试者提出1个测试查询条件(比如,包含区域位置和价格区间),然后在对应的结果集中标出他们认为最满足其需求和偏好的5个对象。最后,利用查询结果分类树构建算法(算法3)根据不同聚类标准在查询结果集上生成分类树,用户通过使用分类树找出他们标注的对象。在这一过程中,记录用户通过使用分类树上找出所有标注对象的实际搜索代价。表2分别给出了不同空间查询条件下基于不同聚类方法生成的查询结果分类树的实际搜索代价。 表2 不同查询条件的查询结果分类树实际搜索代价对比 从表2可以看出,对于测试者提出的10条测试查询(指定了位置范围和/或价格区间),每个查询返回的查询结果总数都在500个以上,如果逐个检查结果的相关性是非常耗时的。通过构建查询结果分类树,用户可以根据分类树上的分支标签检查各分支的相关性,进而快速定位到感兴趣的信息。从表2可以看出,与基于最远距离优先的聚类方法相比,在基于淘汰思想的聚类算法上生成的查询结果分类树具有明显较低的搜索代价。由此可见,本文的空间聚类方法具有较高准确性。图2(a)和图2(b)分别给出了10条测试查询在不同聚类标准下的实际搜索代价和平均搜索代价对比。平均搜索代价是指找到每个相关对象的平均实际搜索代价。 图2 10条测试查询下基于不同聚类方法生成的 对于一个给定的空间查询,通常会返回多个查询结果,而查询结果分类树又是在在线阶段动态生成的,因此需要能够快速生成。该实验目的是测试在不同规模的查询结果下分类树的生成时间。图3给出了房地产数据集上不同查询结果个数下的分类树生成时间。 图3 不同查询结果数下的分类树生成时间 从图3可以看出,在查询结果数为100 000条的情况下,分类树的构建时间也不超过1.1 s,因此能够适用于大规模数据情况下的查询分类。 本文提出了一种用于处理空间数据库查询信息过载问题的分类方法,该方法在离线阶段评估空间对象之间的耦合关系,使用基于概率密度估计方法对空间对象进行聚类。在在线阶段,对于一个空间查询条件,采用改进决策树算法在查询结果上构建一棵分类树,用户通过检查分类树中间节点标签的方式逐步定位到其感兴趣的叶节点信息。 本文方法与现有方法有两方面不同:一是空间聚类方法同时考虑了空间对象之间的位置相近性和语义相关度;二是查询结果分类树构建算法同时考虑了访问中间节点的代价和访问叶节点中对象的代价。如何将将查询结果排序方法融入到分类方法之中是进一步的研究工作。 References) [1] 刘喜平,万常选,刘德喜,等.空间关键词搜索研究综述[J].软件学报,2016,27(2):329-347.(LIU X P, WAN C X, LIU D X, et al. Survey on spatial keyword search [J]. Journal of Software, 2016, 27(2): 329-347.) [2] 张金增,孟小峰.移动Web搜索研究[J].软件学报,2012,23(1):46-64.(ZHANG J Z, MENG X F. Research on mobile Web search [J]. Journal of Software, 2012, 23(1): 46-64.) [3] ZHENG K, SU H, ZHENG B L. Interactive top-kspatial keyword queries [C]// Proceedings of the 2015 IEEE 31st International Conference on Data Engineering. Piscataway, NJ: IEEE, 2015: 423-434. [4] CARY A, WOLFSON O, RISHE N. Efficient and scalable method for processing top-kspatial boolean queries [C]// Proceedings of the 2010 International Conference on Scientific and Statistical Database Management. Berlin: Springer, 2010: 87-95. [5] LU Y, LU J H, SHAHABI C. Efficient algorithms and cost models for reverse spatial-keywordk-nearest neighbor search [J]. ACM Transactions on Database Systems, 2014, 39(2): 573-598. [6] LU J H, LU Y, CONG G. Reverse spatial and textualknearest neighbor search [C]// Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2011: 349-360. [7] HU H Q, LI G L. Top-kspatio-textual similarity join [J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(2): 551-565. [8] 周傲英,杨彬,金澈清,等.基于位置的服务:架构与进展[J].计算机学报,2011,34(7):1155-1171.(ZHOU A Y, YANG B, JIN C Q, et al. Location-based services: architecture and progress [J]. Chinese Journal of Computers, 2011, 34(7): 1155-1171.) [9] CHEN L, CONG G, JENSEN C S, et al. Spatial keyword query processing: an experimental evaluation [J]. Proceedings of the VLDB Endowment, 2013, 6(3): 217-228. [10] CHAKRABARTI K, CHAUDHURI S, HWANG S. Automatic categorization of query results [C]// Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2004: 755-766 [11] CHEN Z Y, LI T. Addressing diverse user preferences in SQL-query-result navigation [C]// Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2007: 641-652. [12] AL-MUBAID H, UMAIR S A. A new text categorization technique using distributional clustering and learning logic [J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(9): 1156-1165. [13] ROUSSEAU F, KIAGIAS E, VAZIRGIANNIS M. Text categorization as a graph classification problem [C]// Proceedings of the 2015 Annual Meeting of the Association for Computational Linguistics. Beijing: [s.n.], 2015: 1702-1712. [14] ZHENG W B, TANG H, QIAN Y T. Collaborative work with linear classifier and extreme learning machine for fast text categorization [J]. Journal of World Wide Web, 2013, 18(2): 1-18. [15] ZENG H J, HE Q C, CHEN Z. Learning to cluster Web search results [C]// SIGIR ’04: Proceedings of the 27th Annual International ACM SIGIR Conference On Research and Development in Information Retrieval. New York: ACM, 2004: 210-217. [16] GRBOVIC M, DJURIC N, RADOSAVLJEVIC V. QueryCatego-rizr: a large-scale semi-supervised system for categorization of Web search queries [C]// WWW 2015: Proceedings of the 24th International Conference on World Wide Web Companion. New York: ACM, 2015: 199-202. [17] TWEEDIE L, SPENCE R, WILLIAMS D, et al. The attribute explorer [C]// CHI ’94: Proceedings of the 1994 Conference Companion on Human Factors in Computing Systems. New York: ACM, 1994: 435-436. [18] WANG C, CAO L B, WANG M C. Coupled nominal similarity in unsupervised learning [C]// CIKM ’11: Proceedings of the 20th ACM International Conference on Information and Knowledge Management. New York: ACM, 2011: 973-978. [19] 王秀红,鞠时光.用于文本相似度计算的新核函数[J].通信学报,2012,33(12):43-48.(WANG X H, JU S G. Novel kernel function for computing the similarity of text [J]. Journal of Communications, 2012, 33(12): 43-48.) [20] BORIAH S, CHANDOLA V, KUMAR V. Similarity measures for categorical data: a comparative evaluation [C]// Proceedings of the 2008 SIAM International Conference on Data Mining. Atlanta, Georgia: [s.n.], 2008: 243-254. [21] GUTTMAN A. R-trees: a dynamic index structure for spatial searching [C]// Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data. New York: ACM, 1984: 47-57. This work is partially supported by the National Natural Science Foundation of China (61401185), the General Project of Liaoning Province Education Department (LJYL018), the Natural Science Foundation of Liaoning Province (201705 40418). BIChongchun, born in 1992, M. S. candidate. His research interests include spatial data analysis and query. MENGXiangfu, born in 1981, Ph. D., associate professor. His research interests include Web database query, spatial data analysis. ZHANGXiaoyan, born in 1983, Ph. D. candidate, engineer. Her research interests include spatial data query, city calculation. TANGYanhuan, born in 1992, M. S. candidate. His research interests include spatial data mining, recommender system. TANGXiaoliang, born in 1980, Ph. D., lecturer. His research interest include machine learning. LIANGHaibo, born in 1995. His research interest include data mining, database query.3 空间对象的耦合相关度评估与聚类方法
3.1 耦合相关度评估
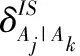
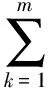
3.2 空间对象聚类
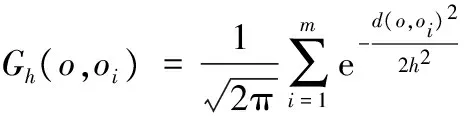
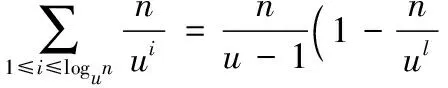
3.3 用户对聚类感兴趣的概率估计
4 查询结果分类树构建
4.1 属性划分
4.2 分类树构建算法
5 实验
5.1 实验设置
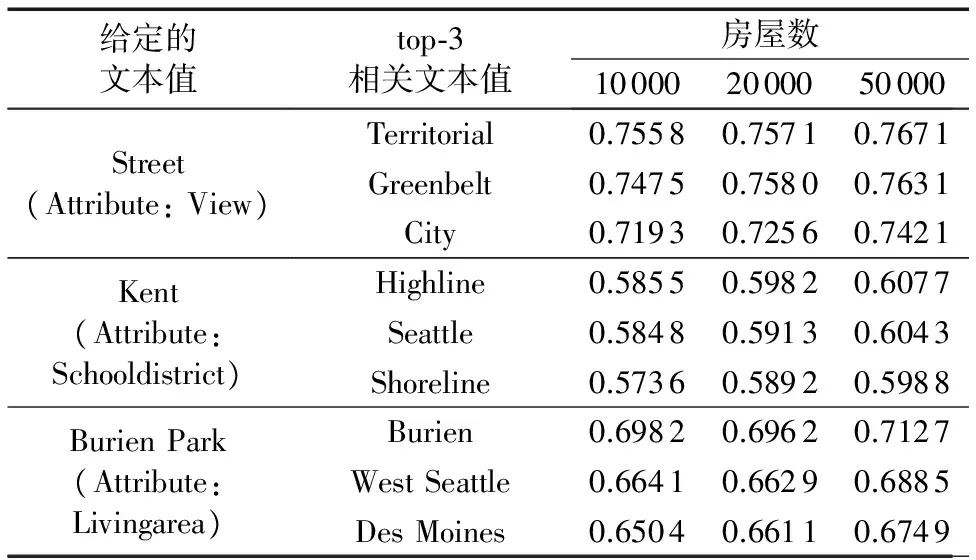
5.2 属性值相关度评估方法的合理性测试
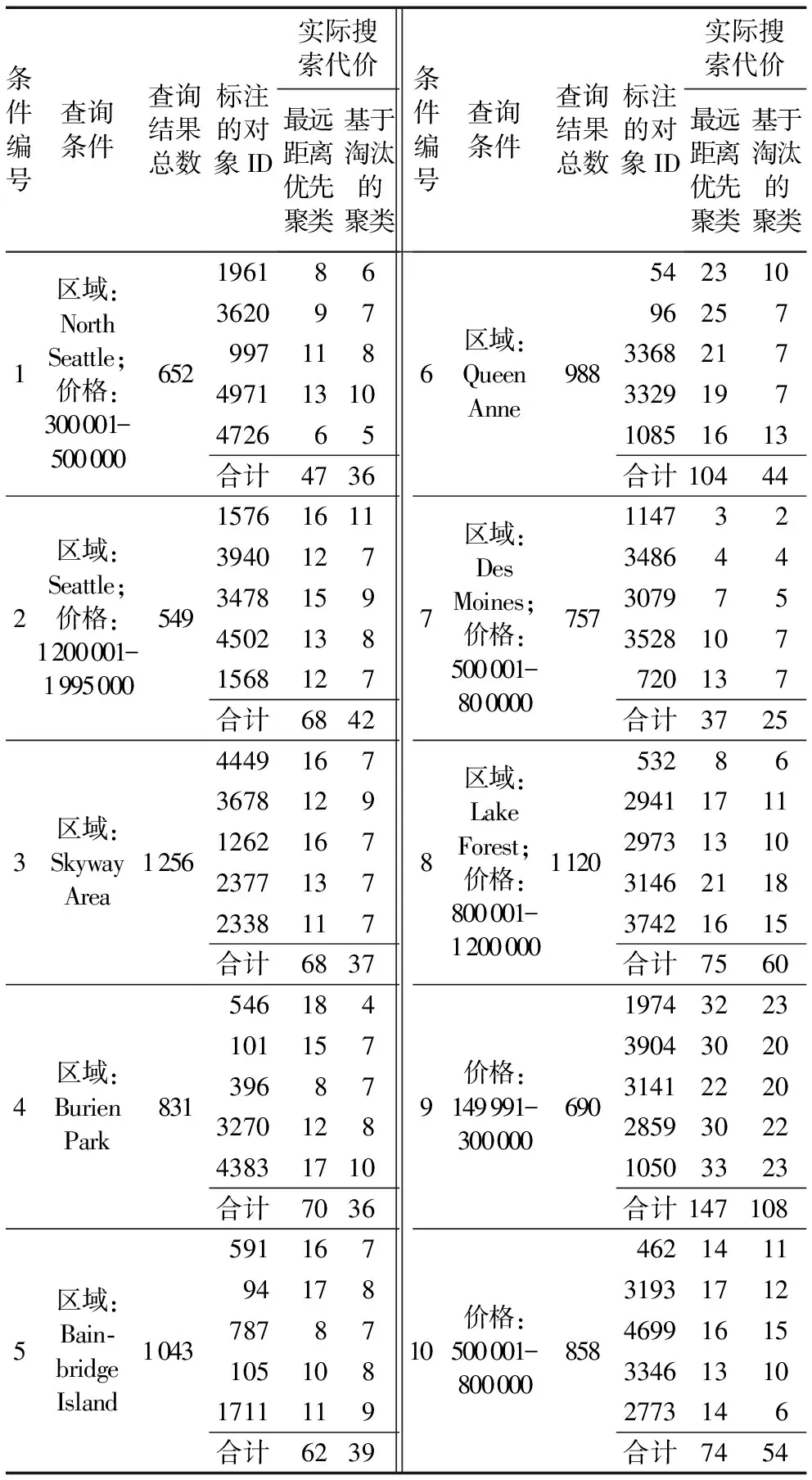
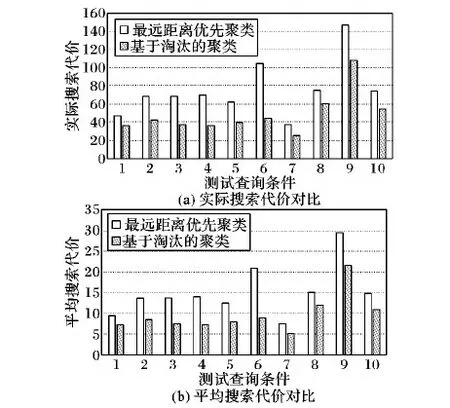
5.3 搜索代价实验
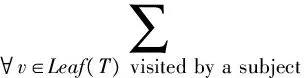
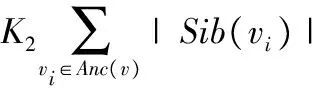
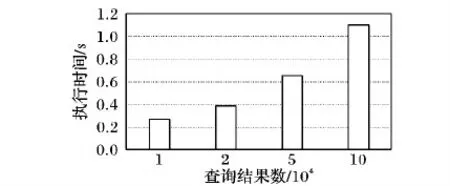
5.4 分类树的生成时间测试
6 结语
猜你喜欢
辽宁工业大学学报(自然科学版)(2022年4期)2022-09-19房地产导刊(2021年12期)2021-12-31北京航空航天大学学报(2021年9期)2021-11-02廉政瞭望·下半月(2021年5期)2021-07-20电子制作(2019年16期)2019-09-27软件导刊(2018年11期)2018-11-19现代计算机(2018年27期)2018-10-25意林(2018年3期)2018-03-02舰船电子对抗(2017年6期)2018-01-11互联网天地(2016年1期)2016-05-04
