
面向微博博主的评论质量评估
2018-03-28 06:51刘利军冯旭鹏黄青松
小型微型计算机系统 2018年1期
栾 杰,刘利军,冯旭鹏,黄青松,3
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 教育技术与网络中心,昆明 650500) 3(云南省计算机技术应用重点实验室,昆明 650500)
1 引 言
随着微博的流行,使用微博的人也越来越多,大量的评论数据也随之产生.然而,由于新浪微博的信息发布门栏较低、平台管理松散,使得这些评论的质量良莠不齐,既影响了通过评论对博主进行需求挖掘的准确性和可信性[1],也加大博主获取高质量评论信息的难度.由此可见对微博评论进行质量评估找出博主关注的高质量评论至关重要.
目前国内外对于评论质量评估的研究主要集中在商品评论上,Mudambi等[2]使用回归分析对商品评论进行质量评估.使用评论所获得的投票的归一化值作为商品评论质量的固有值.吴等[3]则使用分类的方法将商品评论分为“有用”和“无用”两类,以人工标注的数据来验证分类的准确性,将分类的结果作为评论质量的评估.而李等[4,5]则在此基础上加入了评论者的社交网络信息,以此来提高评估的准确度.
然而上述研究忽略了两个重要的问题.
1)在评论质量评估过程中未考虑到个体的差异性.因为评论质量是一个主观的概念,不同的人对评论质量高低的衡量标准也不一样[6].(有的人认为饱含情感的评论是高质量的评论[7,8],而有的人则更注重评论的语法特征[9,10])所以在对评论进行质量评估时应该定量的分析.选取某一个人作为评估人,以评估人的角度的来考虑其对评论质量的衡量标准,而不是简单的以全局的角度考虑所有人对评论质量的衡量标准.
2)以投票作为参照物(无论是将投票的归一化值作为回归参照物还是将投票按高低划分作为分类的参照物)存在误差性.因为不同的评论所获得的投票不仅仅只受评论质量的影响,还受一些其他因素影响.例如研究表明,得到投票多的评论更容易得到更多的投票,发布早的评论容易得到更多的投票[6].所以在选取参照物时应尽量避免这种误差[11].
综上所述,考虑微博评论.对于问题1,每条微博只可能有一个博主,但是其评论者却可以有很多,而且不同的微博可能有相同的评论者.因此选取评论者作为评估人可能会导致重复工作.另一方面由于本文是为了找出博主关注的评论,所以本文选取博主作为评论质量的评估人.对于问题2,评估人确定之后,参照物的选取应尽量避免误差.一方面,在微博中如果一个评论获得了博主的回复,那么无论这个评论的字数还是情感极性,这个评论在博主眼中必定是值得回复的.与那些没有被回复的评论相比,这个评论在博主眼中是更重要的,是其更为关注的评论.另一方面,回复行为与博主直接相关,是博主关于评论质量衡量标准的一个直接体现,能有效避免误差.所以本文选取被博主回复的评论作为高质量评论的参照物.
基于上述分析,本文提出了一种基于最大熵的评论质量评估模型.首先对博主进行分析和研究定义特征,使用爬虫和词向量抽取评论特征,以被博主回复的评论作为高质量评论的参照物.采用监督学习的方式训练出符合博主衡量标准的最大熵分类模型(通过不同博主的不同回复习惯训练出不一样的特征组合)并通过测试数据验证所提模型分类的准确性,最后将分类概率值(这里该文选取分类为回复评论的概率值)作为微博评论的质量评估值.
2 相关技术
为提高提取性能[12-14],尽可能降低隐藏特征(特征定义中未发现的分类特征)对分类模型效果的影响,该文使用最大熵模型对微博评论进行分类,将微博评论分为回复评论类和未回复评论类.最大熵模型的主要思想是在给定约束条件下,对未知情况不做任何假设.在这种情况下,概率分布越均匀,概率模型的熵越大,预测的风险也越小[15].
最大熵模型的计算公式如下:
(1)
(2)
其中y为分类结果,x为评论特征,Zw(x)称为规范化因子,wi是特征的权重,f(x,y)是特征函数,其定义为:
(3)
式中x0表示某一评论特征值,y0表示某一分类值.
3 特征定义与抽取
特征定义是分类的关键步骤,不同的博主其关注的评论特征点(在博主眼中认为哪些评论特征是重要的)也不同,所以在定义特征时应尽可能全的考虑所有博主可能会关注的评论特征,然后再通过监督学习的方式训练出不同博主对应的特征组合.对此该文依据自然人的两面性(共性和个性)定义两类特征,将博主作为自然人集体中的一员考虑,他具有集体共有特性即与集体有着共有的评论特征关注点定义其为共性特征.将博主作为一个单独的自然人考虑,他相比于集体中的其他自然人有一些私有特性即一些个性的评论特征关注点定义其为个性特征.
3.1 共性特征
先前的研究结果表明,表1中的评论特征在评论质量评估时是重要的即都是集体的评论特征关注点.因此本文将这些特征归入共性特征.
表1 共性特征汇总
Table 1 Summary of common features

特 征描 述研究论文相似特征评论与产品描述之间的相似度.(在微博中为评论与博文的相似度)Lin[6]情感特征评论的正负情感倾向.或者是通过评论正负情感词的数量来表示评论的情感强度.Hao[7]元数据特征评论所获得的投票数,评论发布的时间.Lin[6]统计特征评论的句子长度,词数量等.Lu[16,17]评论者特征评论者是否是活跃用户(即活跃度).Lin[6]
3.2 个性特征
个性特征的提出是基于一系列的假设,具体假设的成立与否要通过实验来验证,见表2.
表2 个性特征汇总
Table 2 Summary of specific characteristics

特 征描 述假 设关系特征博主与评论者的关系(关注,无).博主关注的人中可能有博主的同学朋友等,相比于一些其他的评论者,亲朋好友的评论更有可能引起博主的关注.提醒特征评论者在评论中是否@了博主.微博中,当评论者在评论中@博主时,该评论会在博主登陆微博时以一个醒目的方式提醒博主.与其他评论相比,该评论获得博主关注的概率更大.回复特征评论是否是回复博主的评论.回复博主的评论表明评论者很有可能是在与博主进行对话.此类评论获得博主关注的概率更大.
3.3 特征抽取
有些特征的抽取可直接通过爬虫或统计量化完成,有些则需要经过一系列模型运算.在此对于能直接量化的特征以表格的方式汇总如表3.
表3 量化特征表
Table 3 Quantitative characteristic table

特 征描 述表 示元数据特征投票数F1评论发布时间与博文发布时间的差值F2统计特征单词数F4句子长度F5提醒特征是否@博主,是:1,否:0F6回复特征是否是回复博主的评论,是:1,否:0F7关系特征互关注:2,粉丝:1,无:0F8
对于不能直接量化的特征描述如下:
1)相似特征
相似度计算一直以来都是学术界研究的热点,但是微博的评论动辄上万以上,考虑到评估模型的实用性.该文的相似度特征(F3)抽取使用简单高效的word2vec[18-20]进行计算,计算方法.公式如下:
(4)
(5)
F3=cos(v(blog),v(review))
(6)
其中word2vec表示词向量,i为该词标记,n为博文或评论的词数,v(blog)表示博文所对应的句向量,v(review)表示评论所对应的句向量.
2)情感特征
情感特征(F9)使用评论的情感倾向来表示,正面:1,负面:0.通过工具包构建情感分析模型,将模型分析出来的值作为评论的情感特征值.
3)评论者特征
评论者特征中评论者的活跃度(F10)的计算方法使用孙[21]的研究中表现良好的AHP层次分析法,通过观察研究评论者在微博上的信息.构建活跃度评分指标体系,其结构如图1.

图1 活跃度评分指标体系结构Fig.1 Index system structure of active degree
依据上述结构,得出其活跃度计算公式如下:
(7)
其中wi,vi分别表示第i个评分指标(如图1所示i为1表示的是微博数这个评分指标)的组合权重(通过AHP计算出来的组合权重)和归一化值.
4 实 验
4.1 实验数据
实验数据主要包括两个数据集(DA,DB),DA是通过对COAE2013中倾向性分析评测数据文本进行预处理获得的数据,DB是在新浪微博上随机抽取三个博主进行爬虫获得的数据.(为使实验简洁明了,现将博主作如下标记博主1:iG电子竞技俱乐部、博主2:安徽省教育厅、博主3:乐蜂网)详情如表4所示.
表4 数据详情表
Table 4 Data details

数据集类别数目DA正面1000负面1000数据集博主抓取微博抓取评论回复评论未回复评论DB博主1博主2博主3397313275278811129317221360498854275211079516367
其中回复评论即是获得博主回复的评论,反之则是未回复评论.
4.2 特征抽取实验
特征抽取实验主要分为三个部分,针对的是不能直接量化的特征,通过实验验证抽取方法的有效性.实验结果如表5所示.
表5 相似度特征抽取实验
Table 5 Similarity feature extraction experiment

博 主博 文 内 容 评论内容相似度博主1#i⁃趣事#小轩在不在,我是态妹啊[doge][doge]rookie在不在,我是zz态.对对对对我是态妹.0.9264好可爱⁃0.1427博主2#2016高考#【普通文理科本科第二批次投档分数及名次公布】理工:ht⁃tp://t.cn/RtbFZtA;文史:http://t.cn/Rtbem3l.7月26⁃28日,本科第二批次高校平行志愿录取.7月30日10:00⁃16:00,符合条件的考生填报征集志愿和降分征集志愿.7月31日,本科第二批次高校征集志愿及降分录取.[傻眼]坐等征集志愿出来!!!0.7231嘿嘿,发现你对这方面好了解啊-0.59博主3#高蜂论谈#来说说你都被哪些广告台词洗过脑[哈哈][doge](转发+评论@乐蜂网既有机会获得精美礼物一份哦!)#高蜂论谈#杯装奶茶开创者,连续六年销量领先.一年卖出七亿多杯,连起来可绕地球两圈!@乐蜂网0.7921么么哒-0.1066
表5的内容为相似度特征抽取实验的示例(即随机抽取每个博主的一条微博,并找出与该微博相似度最高和最低的评论展示出来),从示例中可以看出使用词向量对评论与博文的相似度进行计算是有效可行的.
表6 情感特征抽取实验
Table 6 Sentiment feature extraction experiment

数据训练测试比分类结果PRFDA1:1正面86.06%93.8%89.76%1:1负面93.17%84.8%88.79%
从上页表6中实验结果可以看出情感分析的准确率在86%以上,召回率在84%以上,达到了实验要求的标准.
表7 评论者特征抽取实验
Table 7 Reviewer feature extraction experiment
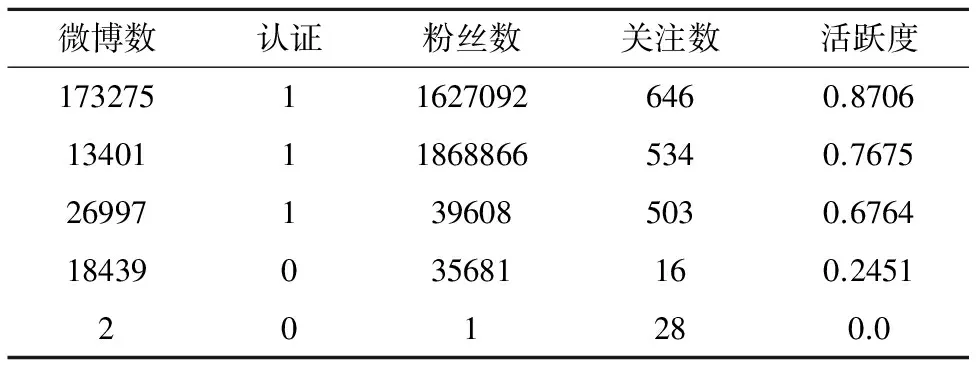
微博数认证粉丝数关注数活跃度173275116270926460.870613401118688665340.7675269971396085030.676418439035681160.2451201280.0
表7展示的是数据集DB中部分评论者的信息,可以看出活跃度的计算符合基本的客观认知.
4.3 分类实验设置
考虑到方法的应用,最大熵模型的参数训练使用LBFGS.分类的实验数据包括两部分,训练数据和测试数据.从1类和2类评论(将数据集DB中回复评论作为1类评论,未回复的评论作为2类评论)中各选出100条作为测试数据,将余下的评论放在一起作为训练数据.由于训练数据中样本不平衡(1类评论和2类评论的数目存在量级上的差距),对此,实验采用权重调整的方式解决样本不平衡问题.后续实验不作特殊说明所使用的数据皆通过上述方法处理得到.实验中为了评估模型的效果,采用准确率,召回率,F值(P,R,F)三个指标进行评判.由于该文是通过分类将1类评论的概率值作为评论的质量评估值,因此仅展示1类评论即博主关注的评论的P,R,F.
4.4 特征选择实验
先前的研究表明分类的特征并不是越多越好[22],因此需要对文中定义的特征进行选择实验,找出分类效果最好的特征组合.考虑到模型分类的效果,本文使用Wrapper方式进行特征选择.首先定义一个基于文本特征的基础分类系统,随后在文本特征的基础上依次引入其他特征,依据分类结果筛选特征,再对筛选出来的特征进行组合加入到文本特征分类中,选出分类效果最好的特征组合.
基础分类系统使用的文本特征为特征F4和F5[16].为了验证本文提出的个性特征的有效性,将特征选择实验分为两部进行,共性特征选择实验和个性特征选择实验.共性特征引入实验结果如表8所示.
表8 共性特征引入实验
Table 8 Common characteristics of the introduction of the experiment
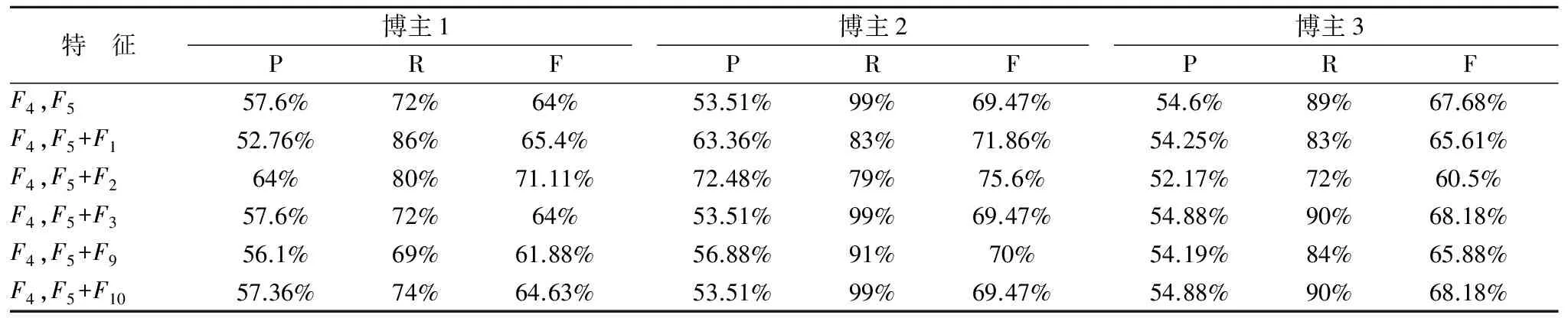
特 征博主1博主2博主3PRFPRFPRFF4,F557.6%72%64%53.51%99%69.47%54.6%89%67.68%F4,F5+F152.76%86%65.4%63.36%83%71.86%54.25%83%65.61%F4,F5+F264%80%71.11%72.48%79%75.6%52.17%72%60.5%F4,F5+F357.6%72%64%53.51%99%69.47%54.88%90%68.18%F4,F5+F956.1%69%61.88%56.88%91%70%54.19%84%65.88%F4,F5+F1057.36%74%64.63%53.51%99%69.47%54.88%90%68.18%
对于博主1,从实验结果可以看出:对模型有提升效果(根据F值判断)的特征有F1,F2和F10,没有提升效果的有F3,对模型产生反效果的有F9.因此将F9去除,对F1,F2,F3,F10进行组合加入文本特征分类中进行特征选择实验(虽然F3在当前环境中没有产生提升效果,但也没有产生反效果,不确定其在后续实验中是否有作用.因此暂时保留).依次类推对于博主2,共性特征选择实验是将F1,F2,F3,F9,F10进行组合加入文本特征分类中进行实验.对于博主3,共性特征选择实验是将F3,F10进行组合加入文本特征分类中进行实验.共性特征选择实验的实验结果如表9所示.
由于博主2的组合数过多不便展示,只展示效果最好的组合.从实验结果可以看出,对于博主1,效果最好的特征组合为F4,F5,F1,F2和F4,F5,F1,F2,F3.模型的F值为71.62.对于博主1,对比表8和表9可以发现任何特征组合在引入F3之后效果都是没有提升(对比F4,F5,F1和F4,F5,F1,F3等),甚至有些特征组合会有所下降(对比F4,F5,F10和F4,F5,F3,F10).同样对于博主2,也是如此(对比F4,F5,F1,F2和F4,F5,F1,F2,F3).因此后续的实验中当出现引入特征之后效果没有提升则将该特征筛选出去.对于博主1其共性特征组合为{F4,F5,F1,F2}.对于博主2其共性特征组合为{F4,F5,F1,F2}.博主3共性特征组合为{F4,F5,F3,F10}.对每个博主进行个性特征引入实验.实验结果如表10所示.
表9 共性特征选择实验
Table 9 Common feature selection experiment

特 征PRF博主1F4,F5+F1,F263.56%82%71.62%F4,F5+F1,F352.76%86%65.4%F4,F5+F1,F1053.37%87%66.16%F4,F5+F2,F364%80%71.11%F4,F5+F2,F1060.87%84%70.59%F4,F5+F3,F1057.03%73%64.04%F4,F5+F1,F2,F363.57%82%71.62%F4,F5+F1,F2,F1058.82%90%71.14%F4,F5+F1,F3,F1053.37%87%66.16%F4,F5+F2,F3,F1060.87%84%70.59%F4,F5+F1,F2,F3,F1058.82%90%71.15%博主2F4,F5+F1,F269.92%86%77.13%F4,F5+F1,F2,F366.92%86%77.13%博主3F4,F5+F3,F1055.15%91%68.68%
表10 个性特征引入实验
Table 10 Specific characteristics of the introduction of the experiment
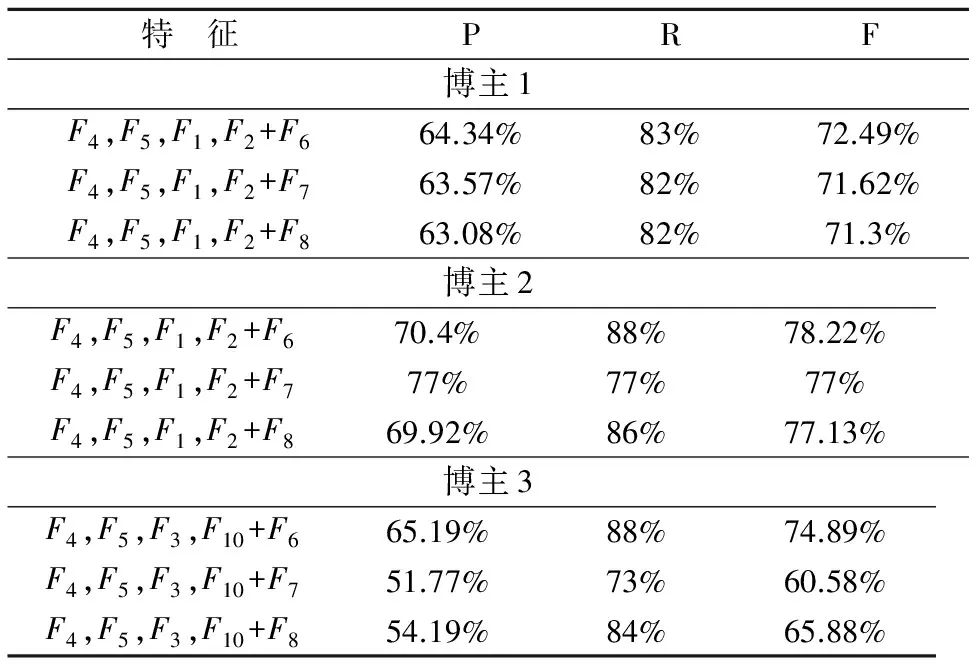
特 征PRF博主1F4,F5,F1,F2+F664.34%83%72.49%F4,F5,F1,F2+F763.57%82%71.62%F4,F5,F1,F2+F863.08%82%71.3%博主2F4,F5,F1,F2+F670.4%88%78.22%F4,F5,F1,F2+F777%77%77%F4,F5,F1,F2+F869.92%86%77.13%博主3F4,F5,F3,F10+F665.19%88%74.89%F4,F5,F3,F10+F751.77%73%60.58%F4,F5,F3,F10+F854.19%84%65.88%
与表9对比可发现引入F7,F8之后三个博主的模型的F值都没有提升.只有F6的引入对模型产生了提升效果.因此将F7和F8筛选出去.得到博主1的特征组合为{F4,F5,F1,F2,F6}、博主2的特征组合为{F4,F5,F1,F2,F6}、博主3的特征组合为{F4,F5,F3,F10,F6}.特征组合确定之后分类的实验结果也可确定即该特征组合对应的实验结果.
4.5 分类对比实验
为了验证最大熵分类在微博评论分类中的有效性,该文使用其他分类方法与之对比.对比实验中由于有些分类方法在实现时难以对模型进行权重调整,因此将分类对比实验分为两步来做.对不可以进行权重调整的方法使用重采样的方式来解决数据不平衡问题.同样与之对比的最大熵也使用相同的数据进行实验,重采样的特征选择和权重调整的特征选择使用的方法一致.实验得出特征组合为博主1:{F4,F5,F2,F9,F8}、博主2:{F4,F5,F1,F2}、博主3:{F4,F5,F1,F9,F6}.对比试验结果如表11所示.
表11 分类对比实验
Table 11 Comparison experiment of classification

方 法处理方式博主1博主2博主3PRFPRFPRFF平均值最大熵权重调整64.34%83%72.49%70.4%88%78.22%65.19%88%74.89%75.2%支持向量机权重调整60.45%81%69.23%65.93%60%62.83%65.35%66%65.67%65.91%最大熵重采样68.87%73%70.87%69.3%79%73.83%68.81%75%71.77%73.88%AdaBoost重采样62.6%82%71%68.38%80%73.73%61.07%80%69.26%71.33%迭代决策树重采样64.29%72%67.92%64.71%66%65.35%69.16%74%71.5%68.26%
从F值上可以看出,无论是权重调整还是重采样,与其他分类模型相比,最大熵分类的效果都是高于其他分类方法的(当处理方式为重采样时,虽然AdaBoost方法在博主1上分类效果要高于最大熵,但在博主2和3上最大熵分类效果是高于AdaBoost的,且从F值的平均值上看,最大熵分类的平均值是高于AdaBoost的.所以总的来说,在处理该文分类问题上,最大熵分类是优于AdaBoost的).其次,观察表11可以发现.当处理方式为权重调整时,对于不同的博主,最大熵分类的F值均达到72%以上.证明了最大熵分类对于不同的博主来说都是有效的.分类的有效性获得验证之后,微博质量的评估值也可确定即分类中1类评论的概率值.
5 结 语
该文致力于站在博主角度上对微博评论进行质量评估,提出一种基于词向量与最大熵的评论质量评估方法.以被博主回复评论作为高质量评论参照物,通过监督学习的方式训练分类模型,实验证明分类模型的平均P、R、F可达到66.64%、86.33%、75.2%.最后将分类为1类评论的概率值作为博主眼中微博评论质量的评估值.计算出的评估值,一方面可以为评论的排序提供依据,将博主最关心的评论靠前展示,解决信息过载的问题.另一方面可以通过评估值将博主不关注的评论剔除出去,为基于评论的博主需求挖掘提供有用的数据.
虽然该文所提的评估模型经过实验证明是有效的,但是由于该文是以被博主回复评论作为高质量评论的参照物,针对没有回复习惯的博主,模型难免会出现冷启动的问题.所以接下来将考虑将协同过滤融合进评论质量评估模型中,解决冷启动的问题.
[1] Jiang Wei,Zhang Li,Dai Yi,et al.Analyzing helpfulness of online reviews for user requirements elicitation[J].Chinese Journal of Computers,2013,36(1):119-131.
[2] Mudambi S M,Schuff D.What makes a helpful online review? a study of customer reviews on amazon.com[J].Mis Quarterly,2010,34(1):185-200.
[3] Wu Han-qian,Zhu Yun-jie,Xie Jue.Detection model of effectiveness of Chinese online reviews based on logistic regression[J].Journal of Southeast University,2015,45(3):433-437.
[4] Li Yu-qiao,Fu Hong-guang.Fake comments recognition based on social network graph model[J].Journal of Computer Applications,2014,34(s2):151-153,158.
[5] Wu F,Shu J,Huang Y,et al.Social spammer and spam message Co-Detection in microblogging with social context regularization[C].ACM International on Conference on Information and Knowledge Management,ACM,2015:1601-1610.
[6] Lin Yu-ming,Wang Xiao-ling,Zhu Tao,et al.Survey on quality evaluation and control of online reviews[J].Journal of Software,2014,25(3):506-527.
[7] Hao Yuan-yuan,Ye Qiang,Li Yi-jun.Research on online impact factors of customer reviews usefulness based on movie reviews data[J].Journal of Management Science in China,2010,13(8):78-88.
[8] Park D,Sachar S,Diakopoulos N,et al.Supporting comment moderators in identifying high quality online news comments[C].CHI Conference,2016:1114-1125.
[9] Zhang Z,Varadarajan B.Utility scoring of product reviews[C].ACM CIKM International Conference on Information and Knowledge Management,Arlington,Virginia,Usa,November,2006:51-57.
[10] Kim S,Chang H,Lee S,et al.Deep semantic frame-based deceptive opinion spam analysis[C].The ACM International on Conference on Information and Knowledge Management,2015:1131-1140.
[11] Mishra A,Rastogi R.Semi-supervised correction of biased comment ratings[C].International Conference on World Wide Web.ACM,2012:181-190.
[12] Hu M,Liu B.Mining and summarizing customer reviews[C].Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Seattle,Washington,Usa,August,2004:168-177.
[13] Popescu,AnaMaria,Etzioni,et al.Extracting product features and opinions from reviews[M].Natural Language Processing and Text Mining,Springer London,2007:9-28.
[14] Zhuang L,Jing F,Zhu X Y.Movie review mining and summarization[C].Acm International Conference on Information & Knowledge Management,2006:43-50.
[15] Li Hang.Statistical learning method[M].Beijing:Tsinghua University Press,2012.
[16] Lu Jun,Hong Yu,Lu Jian-jiang,et al.Automatic reviews quality evaluation based on global user intent[J].Journal of Chinese Information Processing,2012,26(5):79-87.
[17] Dewang R K,Singh A K.Identification of fake reviews using new set of lexical and syntactic features[J].Sixth International Conference on Computer and Communication Technology,Allahabad,India,September,2015:115-119.
[18] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].Computer Science,2013.
[19] Kusner M J,Sun Y,Kolkin N I,et al.From word embeddings to document distances[J].Journal of Machine Ceurning Research,2015,37:957-966.
[20] Zhang Jian,Qu Dan,Li Zhen.Recurrent neural network language model based on word vector features[J].Pattern Recognition and Artificial Intelligence,2015,28(4):299-305.
[21] Sun Nai-li.Design and implementation of personalized advertising system based on micro blog opinion_leader[D].Beijing:Beijing University of Posts and Telecommunications,2012.
[22] Zhang Yu-xiang,Sun Wan,Yang Jia-hai,et al.Feature importance analysis for spammer detection in SinaWeibo[J].Journal on Communications,2016,37(8):24-33.
附中文参考文献:
[1] 姜 巍,张 莉,戴 翼,等.面向用户需求获取的在线评论有用性分析[J].计算机学报,2013,36(1):119-131.
[3] 吴含前,朱云杰,谢 珏.基于逻辑回归的中文在线评论有效性检测模型[J].东南大学学报(自然科学版),2015,45(3):433-437.
[4] 李雨桥,符红光.基于社交图谱模型的虚假评论识别[J].计算机应用,2014,34(s2):151-153,158.
[6] 林煜明,王晓玲,朱 涛,等.用户评论的质量检测与控制研究综述[J].软件学报,2014,25(3):506-527.
[7] 郝媛媛,叶 强,李一军.基于影评数据的在线评论有用性影响因素研究[J].管理科学学报,2010,13(8):78-88.
[15] 李 航.统计学习方法[M].北京:清华大学出版社,2012.
[16] 陆 军,洪 宇,陆剑江,等.基于全局用户意图的评论自动估价方法研究[J].中文信息学报,2012,26(5):79-87.
[20] 张 剑,屈 丹,李 真.基于词向量特征的循环神经网络语言模型[J].模式识别与人工智能,2015,28(4):299-305.
[21] 孙乃利.基于微博意见领袖的个性化广告投放系统的设计与实现[D].北京:北京邮电大学,2012.
[22] 张宇翔,孙 菀,杨家海,等.新浪微博反垃圾中特征选择的重要性分析[J].通信学报,2016,37(8):24-33.
猜你喜欢
好日子(2022年6期)2022-08-17
小读者·阅世界(2022年4期)2022-07-07
新闻研究导刊(2021年17期)2021-11-02
金桥(2021年1期)2021-05-21
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
新媒体研究(2016年9期)2016-10-14
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
读者·校园版(2014年3期)2014-05-14
