
高层次综合特征检测算法的FPGA实现
2018-04-11 03:41谢晓燕张玉婷刘镇弢
实验室研究与探索 2018年1期
谢晓燕, 张玉婷, 刘镇弢
(西安邮电大学 计算机学院, 西安 710061)
0 引 言
在机器视觉领域中,特征检测算法被广泛应用于虚拟场景重建、运动估计、映像配准等视觉处理任务[1]。随着视觉应用的实时性要求越来越高,近年来基于GPU和FPGA的视觉应用加速器成为机器视觉领域研究的重要内容。GPU具有高度的并行计算能力,可以较好地解决计算速度的问题,然而基于GPU的视觉系统往往存在功耗较高、体积较大的缺点[2]。而嵌入式系统发展要求系统具有小型化、可靠性、高速度、低功耗等特点[3],FPGA作为一种高性能的可编程逻辑器件,可以通过编程修改其内部的逻辑功能,从而实现高速的硬件计算,是高性能嵌入式视觉系统的一种更加方便的解决方案[4]。目前已有一些工作研究了基于FPGA的特征检测系统[5-7],但大都是采用硬件描述语言完成设计,其缺点是描述层次低、开发调试困难,如果更换平台往往需要大范围修改逻辑,导致开发周期较长。
面对嵌入式系统性能及功能需求的增长,Xilinx推出的全可编程片上系统(All Programmable System on Chip)Zynq-7000[8]提供了“ARM+FPGA”的单片解决方案。借助Xilinx为Zynq-7000推出的HLS、SDSoC高层次设计工具,能够利用计算机视觉库快速开发算法原型,针对特定问题探索最佳的解决方案[9]。为了使特征检测算法在嵌入式领域达到实时处理并且拥有较高的开发效率,本文选择Sobel边缘检测、Harris角点检测等两种经典特征检测算法作为加速对象,在SDSoC环境下采用流水线优化、循环展开、软硬件并行等优化方法实现了算法的硬件加速。
1 算法描述
1.1 Sobel算法
Sobel算子是一个主要用于边缘检测的离散微分算子,它结合了高斯平滑和微分求导,用来计算图像灰度函数的近似梯度。该算子包含两组3×3的矩阵,将它与图像作平面卷积,即可得出横向及纵向的亮度差分近似值。如果以A代表原始图像,横向及纵向边缘检测的图像灰度值Gx及Gy分别为[10-11]:
图像每一点的梯度值的大小通过下式来计算,如果某点的梯度G大于给定阈值,则认为该点是边缘点。
|G|=|Gx|+|Gy|
(3)
1.2 Harris算法
Harris角点检测是一种直接基于灰度图像的角点提取算法,稳定性高,尤其对L型角点检测精度高。计算角点的过程基于下列2×2的矩阵M[12]:
(4)
式中:Ix、Iy分别为图像在x方向和y方向的导数,在得到矩阵M之后通过M的响应函数来判断当前点是否为角点。在响应函数中,det(M)代表矩阵M的行列式,trace(M)代表矩阵M的迹,k是一个可调整的参数,取值范围一般在0.04~0.06内,本文中k的取值为0.04。
R(M)=det(M)-k×trace(M)2
(5)
2 算法加速器设计
基于上节分析,Sobel边缘检测算法在一个3×3邻域中完成每个像素的卷积运算,这就需要对图像的局部数据进行多次访问。Harris角点检测算法不仅要完成卷积运算,在计算角点的过程中还需要较多的乘除计算。对图像局部数据的多次访问和较多的计算造成了软件实现算法时性能不佳。虽然这些算法底层处理的数据量较大,但运算过程相对简单,并且图像中的所有像素点均可施以同样的运算,这些运算可以进行并行操作[13]。因此,使用SDSoC提供的循环流水线优化、循环展开、数据传输优化、软硬件函数并行[14]等方法,通过对指令的合理运用,可以改善系统性能,提高系统效率。
2.1 Sobel算法加速器设计
2.1.1Sobel算法优化
本文描述的Sobel算法是从标准图像处理库获得的软件实现代码[15],其伪代码为:
voidSobel( IplImage* img, IplImage* dst){
for (inti=1; i〈img-〉height-1; i++){
for (int j=1; j 〈img-〉width-1; j++){
for(int m=-1; m〈=1; m++){
for(int n=-1; n〈=1; n++){
//calculate X direction gradient
}}
for(int m=-1; m〈=1; m++){
for(int n=-1; n〈=1; n++){
//calculate Y direction gradient
}}}}}
以上代码使用IplImage结构体描述图像,而SDSoC在综合时不支持该结构体。因此,本文通过用固定大小的数组替换IplImage指针,并使用sds_lib库中提供的sds_alloc()[14]函数,确保数组被分配到一个连续的物理地址空间中。由于图像数据在DDR中存储,FPGA访问DDR存储所花费的时间远大于CPU对DDR的访问时间,若每次操作FPGA 都要访问DDR,将会产生大量的时间开销。基于此,本文根据文献[16]的思想,在FPGA端使用3×IMG_WIDTH的行缓冲区和一个3×3的窗口缓冲区来存储图像数据。如图1所示,行缓冲区用来存储读入的图像数据,当行缓冲区中数据满足卷积操作所需数据时,把这些数据存放在窗口缓冲区中以便进行下一步操作。每完成一次卷积运算,窗口缓冲区右移,然后用行缓冲区中的数据更新窗口缓冲区。通过行缓冲区和窗口缓冲区的协同处理,可以访问数据流中的局部数据,降低访问内存的时间开销,提高系统性能。

图1缓冲结构及相应操作
在获取到图像的局部数据之后,需要进行卷积运算求出X、Y两个方向的梯度值。原始代码中分别利用两个嵌套for循环计算梯度值,由于这两个循环有相同的界限,并且循环之间不存在数据相关性,本文通过合并循环对该过程进行简化,减少计算的时延。其伪代码为:
voidsobel(unsigned char* img_in, unsigned char* img_out, int width, int height){
for(row = 0; row 〈 height; row++){
for(col = 0; col 〈 width; col++){
//load data to win_buf and line_buf
for(i=0; i〈 3; i++){
for(j = 0; j 〈 3; j++){
//calculate X direction gradient
//calculate Y direction gradient
}}}}}
2.1.2软硬件协同实现
在SDSoC中使用上述中行缓冲和窗口缓冲协同处理的方法获取像素数据后,用不同的卷积模板求出水平和垂直方向梯度的值并对其绝对值求和得到梯度值,然后对梯度进行阈值处理,最后输出像素点的值。算法的实现流程如图2所示,在PS(Processing System)端完成像素数据的读写和灰度转换,在PL(Programmable Logic)端完成Sobel算法的卷积运算和阈值处理。
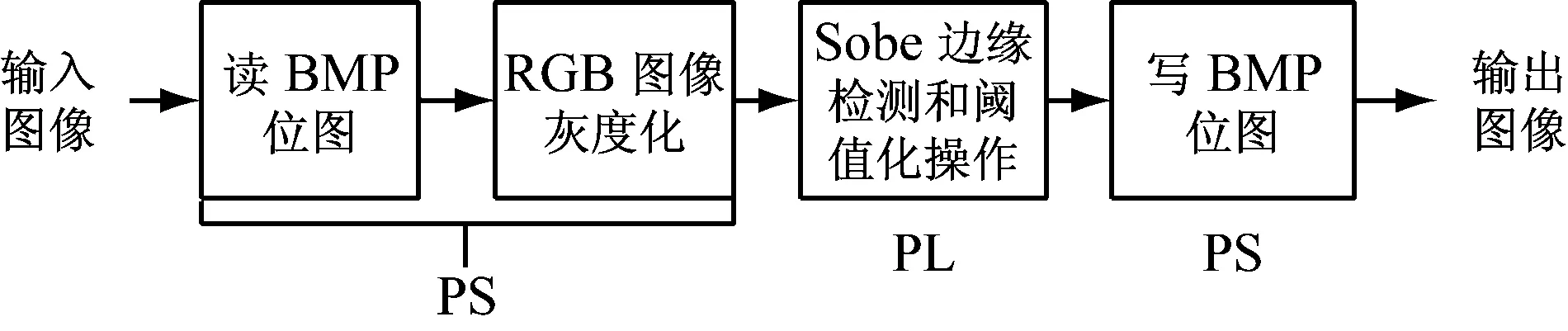
图2Sobel算法加速器流程
Sobel边缘检测算法需要循环处理图像的局部像素,在没有使用循环优化指令的情况下,每次迭代都会使用相同的硬件状态和资源。由于相邻像素点的梯度计算不存在数据相关性,为更进一步优化性能,在主循环中使用了SDSoC中提供的AP PIPELINE循环优化指令让操作进行流水线处理。在计算卷积的过程中,卷积模板与窗口缓冲区内的数据需要进行9次乘法运算。在该循环中使用循环优化指令AP UNROLL,可以对循环内的操作进行展开,同时使用HLS INLINE指令将计算卷积的函数内联到Sobel顶层函数中。通过这些优化指令的使用,优化了卷积的计算速度,有效地减少了时延。在主循环中使用循环优化指令的伪代码如下:
for(row = 0; row 〈 height; row++){
for(col = 0; col 〈 width; col++){
pragma AP PIPELINE II = 1
//processing code
}}
2.2 Harris算法加速器设计
2.2.1Harris算法的并行性分析
Harris角点检测算法由梯度计算、矩阵乘、高斯滤波、计算角点量和阈值化五部分组成,为了充分利用硬件的加速性能,以下对该算法的并行性进行分析。
(1) 流水并行。在处理梯度计算、矩阵乘以及高斯滤波、响应值计算等不同阶段时,后一阶段无需等待前一阶段处理完整幅图片即可开始,从而构成流水并行方式。各阶段可同时处理一帧图像的不同部分,并且其内部运算结构也可以进一步划分成更细的流水段。
(2) 任务并行。在角点计算过程中,梯度计算、矩阵乘和高斯滤波每个阶段内部的计算是独立的,没有相关性,可构成任务级并行。
2.2.2软硬件协同实现
根据1.2、2.1.1中的算法分析和并行性分析,在SDSoC中角点检测算法的实现可分为以下几个步骤来完成,整个算法的实现流程如图3所示。
(1) 对图像进行Sobel卷积操作,求出每个像素点所在位置x方向和y方向的梯度值Ix和Iy。Sobel算法的原理和优化见1.1、2.1节。
(2) 对Ix、Iy进行乘法操作,分别得出dxx、dxy和dyy。
(3) 将dxx、dxy和dyy矩阵分别进行高斯滤波得到Ixx、Ixy和Iyy。
高斯滤波是角点检测中的步骤之一,它是一种线性平滑滤波,主要用来消除高斯噪声。本文中高斯滤波的实现原理与Sobel边缘检测类似,通过使用行缓冲区和窗口缓冲区完成对局部数据的处理。
(4) 根据滤波后Ixx、Ixy和Iyy得到矩阵M,并计算当前点的响应函数R(M)。选取合适的阈值,根据阈值判断当前点是否为角点。
(5) 根据角点位置在原图上将其像素值置为255,即用白色点标记出来。
在SDSoC中,如果硬件函数的输入输出包含数据
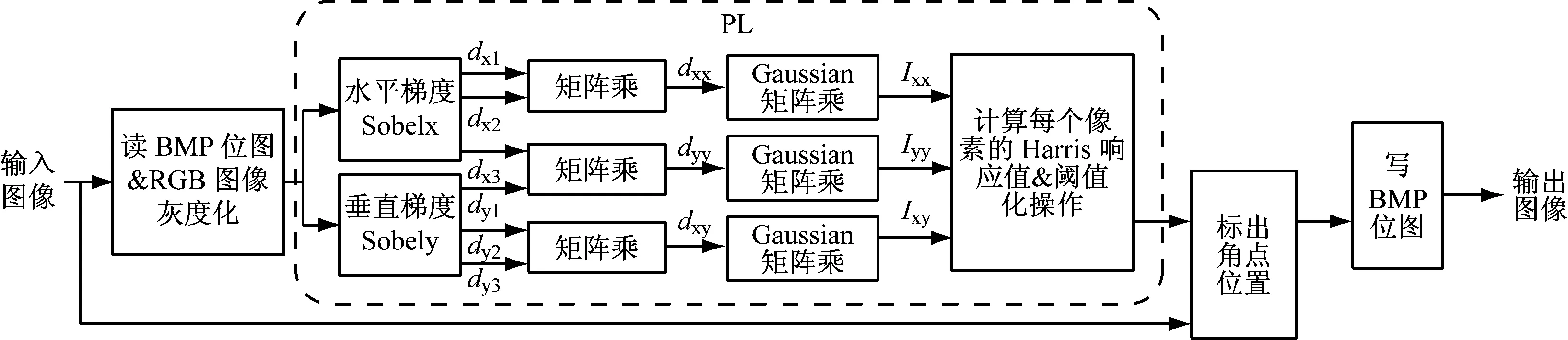
图3Harris算法加速器流程
流,可以直接把一个硬件函数的输出流当作另一个硬件函数的输入流。这样该硬件函数的数据处理完后无需传给ARM端处理,而是会按照流水线的方式,从这个函数直接传入后续的硬件函数继续被处理。如图3所示,实现Harris算法需要经过梯度求值、矩阵乘法、高斯滤波和响应函数计算等步骤。将这些函数一起放在FPGA中加速,sdscc工具链会自动连接这些硬件函数,在它们之间形成数据流,最后一个硬件函数处理完后通过数据移动器将数据回传到ARM中。硬件函数直连可以减少数据在传输时间上的浪费,从而提高了系统效率。
3 实验结果及分析
3.1 实验环境
本文分别使用不同分辨率的bmp格式的图像对算法结果进行验证,添加相应的支持库实现对bmp图像的读写操作。为了更加直观地验证算法检测边缘和角点的效果,将处理后的图像二值化,并将二值图像与OpenCV GPU库的实验结果作对比,以此来验证本文算法的正确性。实验环境如下:
GPU:NVIDIA GTX650 1 059 MHz,1 024 MB global memory
软硬件协同(ZC706)[8]:XC7Z045 FFG900-2,ARM Cortex-A9 800 MHz,FPGA 200 MHz,DDR3 1GB
3.2 实验结果
实验结果如图4、5所示。通过对比可以看出本文加速器对算法的实现结果与CUDA库基本一致,即该设计有良好的边缘和角点检测效果。
3.3 算法性能与分析
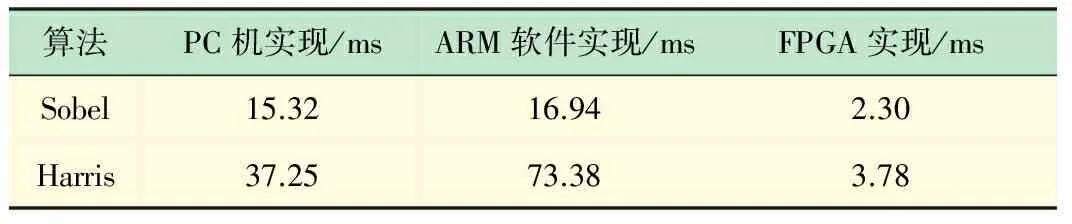
本文算法的软件实现在ARM端完成,软硬件协同同时使用了ARM和FPGA端。为了比较本文提出的算法加速器的加速效果,使用SDSoC提供的sds_clock_counter()函数来对CPU时钟进行统计。表1为OpenCV视觉库中两种特征检测算法在PC机上的实现、本文ARM软件实现与FPGA实现处理一幅512×512大小的图像的时间性能对比。
从表1的数据可以看出FPGA加速器对Sobel、Harris算法的加速性能可以达到2.30 ms、3.78 ms,相比在ARM平台上的软件实现方式,加速比分别达到了7.37、19.41。由于Sobel边缘检测算法将图像流数据存储在行缓冲区和窗口缓冲区之后,分别计算X方向和Y方向的梯度并将其绝对值求和,最后进行阈值运算得到二值图像。在这个过程中使用的是3×3的卷积核进行卷积运算,因此得到每个像素的输出值都要经过18个乘加运算。而Harris角点检测算法由梯度计算、矩阵乘、高斯滤波、计算角点量和阈值化五部分组成,在这个过程中需要较多的乘除运算,因此造成算法在PC和ARM端运行性能不佳。



算法PC机实现/msARM软件实现/msFPGA实现/msSobel15.3216.942.30Harris37.2573.383.78
使用SDSoC提供的流水线优化指令对算法中计算密集的部分进行优化处理之后可以大幅缩短算法的执行时间,改善算法性能。假设每个卷积操作需要20个时钟周期,在512×512分辨率下如果没有使用优化指令则需要5 242 880个时钟周期,使用流水线优化指令之后仅需要262 164个时钟,性能提升接近20倍。本文使用sds_clock_counter()函数获得加速器的执行时间,得到的时间包括数据从DDR传递到FPGA端的时间,因此实际加速比小于理论最大值。
本文使用ZC706开发板作为硬件环境,其板载XC7Z045 FFG900-2芯片提供了可编程逻辑阵列单元。在生成的工程报告文件中查看算法加速器的资源占用信息,对一幅512×512大小的图像进行特征检测的具体硬件资源使用量和FPGA端资源总量如表2所示。
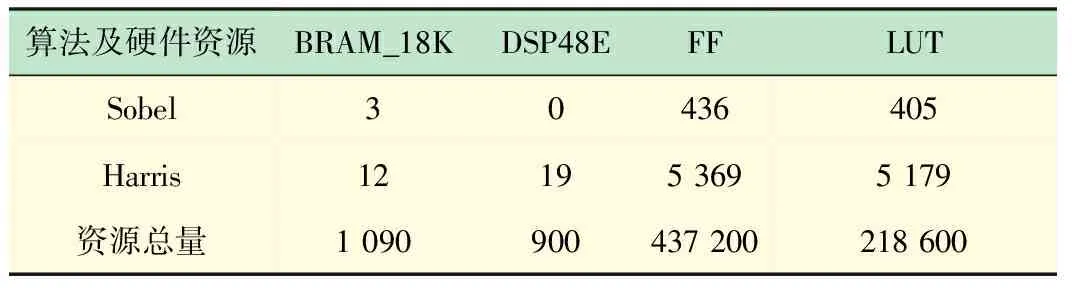
表2 算法资源占用
从表2中可以看出本文在占用少量FPGA资源的前提下实现了算法的硬件加速。算法加速器对BRAM_18K器件的使用率较低,可见行缓冲区和窗口缓冲区的协同处理对FPGA端存储资源的节省起到了很大的作用。与Sobel算法相比,Harris算法需要更多的乘除运算,造成DSP48E器件的一些消耗,该器件的使用基本上反应了算法的计算量。
图6所示为本文FPGA加速器与OpenCV的GPU库相关函数(即CUDA实现)的加速性能对比,由图6可知,特征检测算法的FPGA加速器相比CUDA实现有良好的加速效果,并且NVIDIA GTX650的最大功耗为64 W,而FPGA对一幅512×512大小的图像进行边缘检测和角点检测仅需0.098 W和0.334 W的功耗,在显著降低功耗的前提下提高了系统性能。

图6 FPGA加速与CUDA库性能对比
Chaple等[5-7]使用硬件描述语言完成了Sobel和Harris算法的FPGA加速器,Monson等[17]使用Vivado HLS将C代码实现的Sobel算法转化成RTL实现。表3、4为本文算法加速器处理640×480大小的图像与文献[5-7,17]的性能对比。
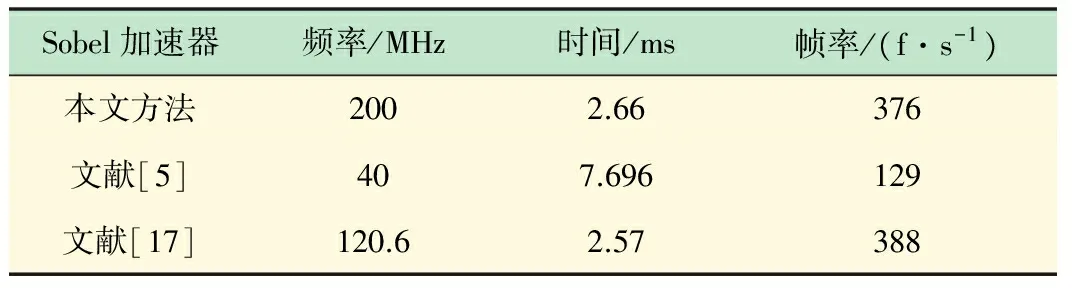
表3 Sobel算法FPGA加速器性能对比
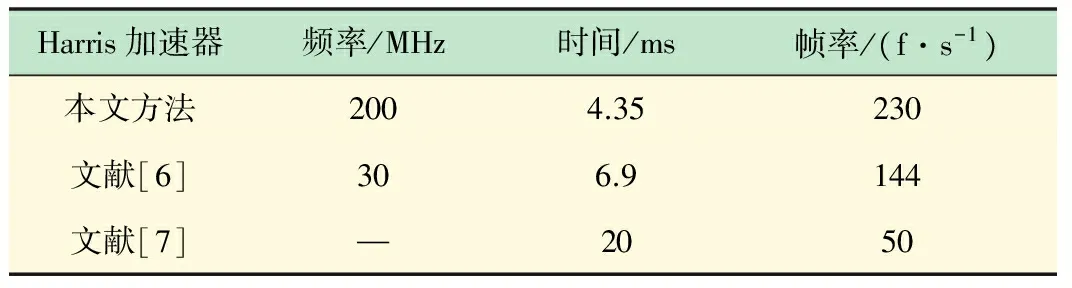
表4 Harris算法FPGA加速器性能对比
实验数据表明,本文设计的FPGA加速器在200 MHz的综合频率下对Sobel、Harris算法的加速达到了376 f/s和230 f/s,基本可以达到与文献[5-7,17]中加速器相近的性能。文献[17]根据HLS综合报告得出的时间不包括数据传输时间,而本文统计的时间性能包括数据从DDR里传输到FPGA的时间,因此时间略高。本文与文献[17]都是基于高层次综合完成加速器的设计,但是其使用Vivado HLS工具的最终输出为IP核,如果要实现一个完整的嵌入式系统,还需在Vivado中完成硬件设计,并且要对不同的IP核开发相应的驱动和设备等。而SDSoC环境集成了整套的开发步骤,可以通过对应的软件算法直接生成在硬件平台上运行的文件,拥有较高的开发效率。文献[5-7]中使用硬件描述语言实现算法加速器,需要对硬件执行细节有深入的理解。本文通过高层次综合工具在更高层次的抽象环境下加速算法,根据应用的不同需求选择算法运行的平台,对数据进行简单运算且需要大量随机访问的函数在ARM端实现,若需要进行较多的数值计算则在FPGA端实现,并且通过优化指令控制综合过程,实现了一个高性能、低功耗的硬件加速器。
4 结 语
本文实现了基于高层次综合的边缘检测和角点检测的FPGA加速器,并利用SDSoC开发环境提供的优 化指令对算法进行优化。与软件实现的算法相比,使
用软硬件协同处理对算法的加速效果很明显。与CUDA实现方式相比,在降低功耗的同时提高了系统性能。与硬件描述语言实现的加速器相比,拥有较高的开发效率,缩短了开发周期,满足了机器视觉领域的实时性需求。
参考文献(References):
[1]肖汉,周清雷,张祖勋. 基于多GPU的Harris角点检测并行算法[J]. 武汉大学学报(信息科学版),2012(7):876-881.
[2]Possa P R, Mahmoudi S A, Harb N, et al. A multi-resolution FPGA-based architecture for real-time edge and corner detection[J]. IEEE Transactions on Computers, 2013, 63(10):2376-2388.
[3]沈绪榜. 嵌入式计算机系统的展望[J]. 单片机与嵌入式系统应用,2001(1):5-6.
[4]Todman T J, Constantinides G A, Wilton S J E, et al. Reconfigurable computing: Architectures and design methods[J]. IEE Proceedings - Computers and Digital Techniques, 2006, 152(2):193-207.
[5]Chaple G, Daruwala R D.Design of Sobel operator based image edge detection algorithm on FPGA[C]// International Conference on Communications and Signal Processing. IEEE, 2014:788-792.
[6]Chao T I, Wong K H. An efficient FPGA implementation of the Harris corner feature detector[C]∥Machine Vision Applications (MVA).2015 14th IAPR International Conference, 2015: 89-93.
[7]Hsiao P Y, Lu C L, Fu L C. Multilayered image processing for multiscale harris corner detection in digital realization[J]. Industrial Electronics IEEE Transactions on, 2010, 57(5):1799-1805.
[8]Xilinx, ZynqArchitecture[EB/OL].[2016-1-26].https://www.xilinx.com/products/silicon-devices/soc/zynq-7000.html.
[9]Crockett L H. The Zynqbook:embedded processing with the ARM Cortex-A9 on the Xilinx Zynq-7000 all programmable SoC[M]. Strathclyde Academic Media, 2014.
[10]Qian W,Mei J.Design of video acquisition identification system based on Zynq-7000 Soc Platform[J].Proceedings of International Conference on Informationence & Computer Application,2013,92:208-213.
[12]Harris C. A combined corner and edge detector[J]. ProcAlvey Vision Conf, 1988, 1988(3):147-151.
[13]DonaldG.Bailey. 基于FPGA的嵌入式图像处理系统设计[M]. 北京:电子工业出版社, 2013.
[14]Xilinx, SDSoC Environment User Guide[EB/OL].[2016-1-26].https://www.xilinx.com/cgi-bin/docs/rdoc?v=2016.2;d=ug1027-sdsoc-user-guide.pdf.
[15]Ramirez G A. (2009, April) sobel.cpp. [EB/OL].[2017-2-24].http://www.cs.utep.edu/ofuentes/AI/sobel.cpp
[16]Abdelgawad H M, Safar M, Wahba A M. High Level Synthesis of Canny Edge Detection Algorithm on ZynqPlatform[J].2015 33rd IEEE International Conference on Computer Design (ICCD).
[17]Monson J, Wirthlin M, Hutchings B L. Optimization techniques for a high level synthesis implementation of the Sobelfilter[C]∥2013 International Conference on Reconfigurable Computing and FPGAs (ReConFig). Cancun, 2013: 1-6.
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
少先队活动(2021年6期)2021-07-22
电子技术与软件工程(2018年10期)2018-07-16
沈阳工业大学学报(2018年1期)2018-01-08
电子科技(2016年12期)2016-12-26
系统工程与电子技术(2016年4期)2016-08-24
中国工程机械学报(2016年5期)2016-03-07
项目管理技术(2015年3期)2015-04-23
时代人物(2014年10期)2015-01-28
