
谷歌发布2017年度AI报告
2018-05-14 10:55JeffDean
机器人产业 2018年2期
Jeff Dean


谷歌大脑负责人Jeff Dean近日撰文回顾了2017年的工作,内容包括基础研究工作,机器学習的开源软件、数据集和新硬件。本文重点介绍机器学习在医疗、机器人等不同科学领域的应用与创造性,以及对谷歌自身工作带来的影响。
谷歌大脑团队(Google Brain team)致力于通过科研和系统工程来提升人工智能的先进水平,这也是整个谷歌团队AI工作的一部分。2017年,我们盘点了2016年的工作,从那时起,我们在机械智能化的长期研究方面不断取得进展,并与Google和Alphabet的许多团队展开合作,利用研究成果改善人们的生活。这篇文章将重点介绍我们在2017年的工作,包括我们的一些基础研究工作,以及开源软件、数据集和机器学习新硬件方面的新成果。后续,我们将对某些特殊领域(对于这些领域而言,机器学习可能会对其产生重大影响,如医疗保健、机器人和一些基础科学领域)展开深入研究,并介绍我们开展的创造性、公平性、包容性的工作,以帮助大家更好地了解我们。
核心研究
我们团队关注的重点在于科研,并以此来提高我们的理解能力以及解决机器学习领域新问题的能力。以下是我们2017年研究的几大主题。
AutoML
自动化机器学习的目标是推动技术发展,从而让计算机能够自动解决机器学习方面的新问题,而不需要人类机器学习专家来解决每个新问题。如果我们想拥有真正的智能系统,那么这将是我们需要具备的一项基本技术能力。我们提出了利用强化学习(reinforcement learning)和进化算法(evolutionary algorithms)来设计神经网络结构的新方法,并将这项工作推广到了ImageNet图像分类和检测领域的最新成果,展示了如何自动学习新的优化算法(optimization algorithms)和有效的激活函数(activation functions)。我们正与谷歌Cloud AI团队(Google Cloud AI team)展开积极合作,将此项技术提供给Google客户,同时不断向多个方面推进这项研究。
语言理解与生成
另一项主要工作是开发新技术,以此来提高我们计算机系统理解和生成人类语音的能力,其中包括我们与谷歌语音团队(Google Speech team)的合作,为端到端的语音识别技术进行了一系列改进,从而将谷歌语音识别系统产生的相对词错率降低了16%。这项研究的一个益处是,它需要将许多不同的研究思路整合到一起。
我们还与谷歌的机器感知团队( Machine Perception team)的研究同事合作,开发了一种新的文本到语音(text-to-speech)生成方法(Tacotron 2),极大地提高了生成语音的质量。该模型的平均意见得分(MOS)为4.53,相比之下,专业录音的MOS值为4.58(你或许在有声读物中看到过),过去最好的计算机生成语音系统(computer-generated speech system)的MOS值为4.34。你可以在这里试听:https://google.github.io/tacotron/publications/tacotron2/index.html
机器学习的新算法和新方法
我们不断开发机器学习的新算法和新方法,包括Hinton提出的capsules的工作(在执行视觉任务时,明确寻找激活特征中的一致性,作为评估许多不同噪声假设的方法)、稀疏门控专家混合层(sparsely-gated mixtures of experts)(这使得超大模型仍然具有高计算效率)、超网络(hypernetworks)(用一个模型的权值生成另一个模型的权值)、新的multi-modal模型(在同一个模型上执行音频、视觉和文本输入的多个学习任务)、基于attention的机制(作为卷积模型和递归模型的替代)、symbolic和non-symbolic学习优化方法、通过离散变量进行反向传播的技术以及新型强化学习算法改进的研究。
计算机系统的机器学习
在计算机系统中,利用机器学习取代传统的启发方法,也是我们非常感兴趣的。我们展示了如何使用强化学习来做出布局决策(placement decision),以便将计算图形映射到一组比人类专家更优秀的计算机设备上。与谷歌科研(Google Research)的其他同事一样,我们在“学习索引结构的案例”一文中证明了神经网络比传统数据结构如B-tress、哈希表和布隆过滤器(Bloom filter)速度更快、规模更小。我们相信,正如在NIPS的Machine Learning for Systems and Systems for Machine Learning研讨会上所述,对于在核心计算机系统中使用机器学习而言,我们还停留在表面。
隐私与安全
机器学习及其与安全和隐私的交叉领域,仍然是我们主要研究的重点。在一篇获得ICLR 2017最佳论文奖的论文中,我们展示了机器学习技术可以以一种提供不同隐私保证的方式应用。我们还在持续研究对抗样本的性质,包括在物理世界中展示对抗样本,以及如何在训练过程中大规模利用对抗样本,进而使模型相对于对抗样本而言具有更强的鲁棒性。
了解机器学习系统
虽然我们在深度学习领域取得了许多令人印象深刻的成果,但重要的是弄清楚它的工作原理,以及它在何种状态下会停止工作。在另一篇获得ICLR 2017最佳论文奖的论文中,我们发现,目前的机器学习理论框架无法解释深度学习方法中,那些令人印象深刻的成果。我们还发现,通过最优方法寻找最小的“平坦度”(flatness),并不像最初预想的那样,与良好的泛化紧密相关。为了更好地理解在深层构架下,训练是如何进行的,我们发表了一系列分析随机矩阵的论文,因为这是大多数训练方法的出发点。了解深度学习的另一个重要方法是更好地衡量它们的表现。在最近的一项研究中,我们证明了良好的实验设计以及严谨统计的重要性,比较了许多GAN方法,发现许多流行的生成模型增强并没有提高性能。我们希望这项研究,能够在其他研究人员进行相关实验时,提供一个可靠范例。
我们正在研发能够更好地解释机器学习系统的方法。并且在2017年3月,我们与OpenAI、DeepMind、YC Research合作,宣布推出Distill,这是一本致力于帮助人类更好地理解机器学习的在线开放性科学期刊。其清楚地阐释了机器学习的概念,提供了优秀的交互式可视化工具,并获得了良好反响。在刊物发行的第一年,Distill发表了许多有启发性的文章,旨在了解各种机器学习技术的内部工作原理,我们期待在2018年可以取得更多进展。
用于机器学习研究的开放式数据集
像MNIST、CIFAR-10、mageNet、SVHN和WMT这样的开放数据集,极大地推动了机器学习领域的发展。作为一个集体,我们团队与谷歌科研(Google Research)在过去一年左右的时间里,一直通过提供更大的标记数据集,积极地为开放式机器学习提供开放、有趣的新数据集,包括:
·YouTube-8M: 使用4716个不同类别注释的700万个YouTube视频;
·YouTube-Bounding Boxes: 来自21万个YouTube视频的500万个bounding boxes;
·Speech Commands数据集:包含数千个说话者说的短指令词;
·AudioSet:200万个10秒的YouTube视频剪辑,标记有527个不同的声音事件;
·Atomic Visual Actions(AVA):57000个视频剪辑中的21万个动作标签;
·Open Images:使用6000个类别标记的900万个创作共用许可的图像;
·Open Images with Boundign Boxes:600个类别的120万个bounding boxes。
TensorFlow和开源软件
纵观我们团队的历史,我们已经开发了一些工具,帮助我们进行机器学习研究,并在谷歌的许多产品中部署了机器学习系统。2015年11月,我们开放了第二代机器学习框架TensorFlow,希望机器学习社区能够从机器学习软件工具的投资中获益。2017年2月,我们发布了TensorFlow 1.0,2017年11月,我们发布了v1.4版本,增加了以下重要功能:用于交互式命令式编程的Eager execution,用于TensorFlow程序的优化编译器XLA,以及用于移动设备和嵌入式设备的轻量级解决方案TensorFlow Lite。預编译的TensorFlow二进制文件现在已经在180多个国家被下载超过1000万次,GitHub上的源代码现在已经有超过1200个贡献者。
2017年2月,我们举办了首届TensorFlow开发者峰会,超过450多人参加了在美国加州山景城的活动,超过6500人观看了直播,包括在全球超过35多个国家和地区举办了超过85场的本地观看活动。所有的会谈都被记录下来,主题包括TensorFlow的新功能、使用TensorFlow的技巧和低层TensorFlow抽象的细节。我们将于2018年3月30日在美国旧金山湾区举办第二届TensorFlow开发者峰会。
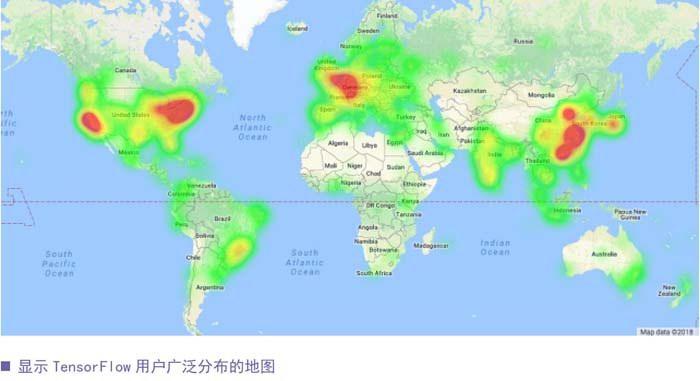
2017年11月,TensorFlow为开放源代码项目两周年举办了庆祝活动。 能够看到一个充满活力的TensorFlow开发者和用户群体的出现,无疑是对我们最好的回报。TensorFlow是GitHub上排名第一的机器学习平台,也是GitHub上五大软件库之一,被许多不同规模的公司和机构所使用,Git Hub上有超过24500个与Tensor Flowl相关的独立软件库。现在,许多研究论文都与开放源代码的TensorFlow实现一起出版,以配合研究结果,使社区能够更容易地理解每篇论文描述的使用方法,并重现或扩展工作。
TensorFlow也受益于其他Google研究团队的相关开源工作,其中,包括TensorFlow中生成对抗模型的轻量级库TF-GAN、TensorFlow Lattice、一组基于网格模型的估计器,以及TensorFlow Object Detection API。TensorFlow模型库随着模型的增多而持续扩张。
除了TensorFlow之外,我们还发布了deeplearn.js,这是一个在浏览器中快速实现深度学习的API开源硬件(无需下载或安装任何东西)。deeplearn.js的主页有许多很好的例子,包括Teachable Machine和Performance RNN。我们将在2018年继续努力,以便将TensorFlow模型直接部署到deeplearn.js环境中。
TPUs
大约五年前,我们认识到,深度学习将极大地改变我们所需的硬件类型。深度学习的计算量非常大,但是它们有两个特殊的性质:它们主要由密集的线性代数运算(矩阵倍数,向量运算等)组成,它们对精度的降低具有非常好的包容性。我们意识到可以利用这两个属性,来构建能够非常有效地运行神经网络计算的专用硬件。我们向谷歌平台(Google Platforms)团队提供了设计输入,他们设计并生产了第一代Tensor Processing Unit(TPU): 一种帮助深度学习模型进行加速推理的单芯片ASIC(推理使用已训练的神经网络,并且训练方式不同)。第一代TPU已经在我们的数据中心部署了三年,它被用于为谷歌搜索(Google Search)、谷歌翻译(Google Translate)、谷歌图片(Google Photos),李世石、柯洁与Alphago的比赛,以及许多其他研究和产品用途。2017年6月,我们在ISCA 2017上发表了一篇论文,证实第一代TPU比与其同时期的GPU或CPU同类产品,处理速度快15-30倍,性能/功耗节优化30–80倍。
推论是很重要的,但是加速训练过程是一个更重要的问题,也是一个更困难的问题。研究人员越快地尝试新想法,我们就能取得更多的突破。2017年5月我们在Google I / O上宣布的第二代TPU,是一个旨在加速训练和推理过程的一体化系统(定制ASIC芯片、电路板和互连),我们展示了一个设备配置:TPU Pod。我们宣布这些第二代设备将在谷歌云平台(Google Cloud Platform)上作为Cloud TPUs提供。我们还公布了TensorFlow研究云计划(TFRC),该计划旨在为顶级机器学习研究人员提供方案,这些人致力于與世界分享他们的工作,以便免费访问1000个Cloud TPUs集群。在2017年12月,我们展示了一项研究,证实可以在22分钟内,从TPU Pod上训练一个ResNet-50 ImageNet模型,而在一个典型的工作站上,这需要几天或更长时间,在相同时间里,TPU Pod上训练的模型准确度要高。我们认为以这种方式缩短研发周期,将极大地提高谷歌的机器学习团队和所有使用Could TPUs的组织的工作效率。
谷歌大脑AI应用研究
过去一年,谷歌大脑在多个特定领域深入研究,例如如何将机器学习等技术应用于医疗、机器人、创意、公平等多个领域。这在某种程度上,也代表了2017年人工智能具体应用的最高水平研究。
医疗
我们认为,机器学习技术在医疗行业的应用潜力巨大。我们正在解决各种各样的问题,包括协助病理学家检测癌症,理解各种对话来为医生和病人提供帮助,使用机器学习解决基因组学中的各种问题,其中包括一个名叫DeepVariant的开源工具,用深度神经网络来从DNA测序数据中快速精确识别碱基变异位点。
我们还致力于尽早发现糖尿病视网膜病变(DR)和黄斑水肿,并于2016年12月在《美国医学协会杂志》(JAMA)上发表论文。
2017年,我们将这个项目从研究阶段过渡到实际的临床影响阶段。我们与Verily(Alphabet旗下的一家生命科学公司)合作,通过严格的流程来引导这项工作,我们还一起将这项技术整合到尼康的Optos系列眼科相机中。
此外,我们在印度努力部署这套系统,因为印度的眼科医生缺口多达12.7万人,因此,几乎一半的患者确诊时间过晚,并因为这种疾病而导致视力下降。作为试点的一部分,我们启动了这个系统,帮助Aravind Eye Hospitals眼科医院的学生更好地诊断糖尿病x性眼疾病。
我们还与合作伙伴共同了解影响糖尿病性眼睛护理的人类因素,从患者和医疗服务提供者的人种学研究,到研究眼科医生如何与人工智能系统之间的互动方式。
我们也与领先的医疗组织和医疗中心的研究人员(包括美国斯坦福大学、美国加州大学旧金山分校和美国芝加哥大学),共同演示机器学习利用匿名病历来预测医疗结果所能达到的具体效果(例如,考虑到病人的现状,我们相信可以用针对其他数百万病人的病程进行的研究来预测这个病人的未来,以此帮助医疗专业人士做出更好的决策)。
机器人
我们在机器人领域的长期目标是设计各种学习算法,让机器人在混乱的现实环境中运行,并通过学习快速获得新的技能和能力。而不是让它们身处精心控制的环境中,处理当今机器人所从事的那些为数不多的手工编程任务。
我们研究的一个重点是开发物理机器人的技术,利用他们自己的经验和其他机器人的经验来建立新的技能和能力,分享经验,共同学习。我们还在探索如何将基于计算机的机器人任务模拟与物理机器人的经验结合起来,从而更快地学习新任务。
虽然模拟器的物理效果并不完全与现实世界相匹配,但我们观察到,对于机器人来说,模拟的经验加上少量的真实世界经验,比大量的实际经验更能带来好的结果。
除了真实世界的机器人经验和模拟的机器人环境,我们还开发了机器人学习算法,可以学习通过观察人类的演示进行学习。我们相信,这种模仿学习模式是一种非常有前途的方法,可以让机器人快速掌握新的能力,不需要明确编程或明确规定一个活动的具体目标。
2017年11月我们组织召开了第一届Conference on Robot Learning (CoRL),大会汇集了在机器学习和机器人技术的交叉领域工作的研究人员。
基础科学
我们也很看好机器学习技术解决重要科学问题的长期潜力。去年,我们利用神经网络预测了量子化学中的分子性质。
通过分析天文数据发现了新的系外行星。
对地震的余震进行预测,并利用深度学习来指导自动证明系统。
创意
如何利用机器学习技术去协助创意活动,这也是我们很感兴趣的领域。2017年,我们开发了一个人工智能钢琴二重奏工具,帮助YouTube音乐人Andrew Huang制作了新的音乐,并展示了如何教机器画画。
我们还演示了如何控制运行在浏览器中的深度生成模型,制作新的音乐。这项工作赢得了NIPS 2017的“最佳演示奖”,这也是谷歌大脑团队Magenta项目的成员连续第二年赢得这个奖项。
在NIPS 2016上,来自Magenta项目的互动音乐即兴创作也赢得了“最佳演示奖”。
People + AI研究项目(PAIR)
机器学习的进步为人类与计算机的交互带来了全新的可能。与此同时,同样重要的是让全社会从我们开发的技术中受益。我们将这方面的机遇和挑战视为高优先级工作,并与谷歌内部的许多团队合作,成立了PAIR项目(https://ai.google/pair)。
PAIR的目标是研究和设计人类与人工智能系统互动最高效的方式。我们发起了公共研讨会,将多个领域,包括计算机科学、设计,甚至艺术等领域的学术专家和实践者聚集在一起。PAIR关注多方面课题,其中一些我们已有所提及:尝试解释机器学习系统,帮助研究者理解机器学习,以及通过deeplearn.js扩大开发者社区。关于我们以人为中心的机器学习工程方法,另一个案例是Facets的推出。这款工具实现训练数据集的可视化,帮助人们理解训练数据集。
机器学习的公平性和包容性
随着机器学习在技术领域发挥越来越大的作用,对包容性和公平性的考量也变得更重要。谷歌大脑团队和PAIR正努力推动这些领域的进展。
我们发表的论文涉及:如何通过因果推理来避免机器学习系统的偏见,在开放数据集中地理多样性的重要性,以及对开放数据集进行分析,理解多元化和文化差异。我们也一直与跨行业项目Partnership on AI密切合作,确保公平性和包容性成为所有机器学习实践者的目标。
我们的文化
我们团队文化的一个重要方面在于,赋能研究员和工程师,帮助他们解决他们认为最重要的基本研究问题。2017年9月,我们公布了开展研究的一般方法。
在我们的研究工作中,教育和指导年轻研究员贯穿始终。2016年,我们团队吸纳了100多名实习生,2017年我们研究论文的约25%共同作者是实习生。
2016年,我们启动了“谷歌大脑入驻”项目,给有志于学习机器学习研究的人们提供指导。在项目启动第一年(2016年6月到2017年5月),27名入驻者加入我们团队。我们在项目进行到一半时,以及结束后公布了进展,列出了入驻者的研究成果。项目第一年的许多入驻者都是全职研究员和研究工程师,他们大部分人没有参加过伯克利、卡耐基·梅隆、斯坦福、纽约大学和多伦多大学等顶级机器学习研究机构的博士研究。
2017年7月,我们迎来了第二批入驻者,他们将与我们一同工作至2018年7月。他们已经完成了一些令人兴奋的研究,成果在许多研究场合发表。
现在,我们正在扩大项目范围,引入谷歌内部的许多其他研究团队,并将项目更名为“Google AI Residency program”项目。(可以通过链接g.co/airesidency/apply了解2018年的项目情况)。
2017年,我们所做的工作远远超出我们在文中介绍的内容。我们致力于在顶级研究场合发表我们的成果。2017年,我们团队发表了140篇论文,包括在ICLR、ICML和NIPS上发表的超过60篇论文。如果想要进一步了解我们的工作,你可以仔细阅读我们的研究论文。
猜你喜欢
环球时报(2022-07-13)2022-07-13
小天使·三年级语数英综合(2022年4期)2022-04-28
环球时报(2022-03-14)2022-03-14
汽车导报(2017年5期)2017-08-03
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
儿童故事画报·智力大王(2015年10期)2016-01-27
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
