
基于RDF的学科数据库扩充方法研究
2018-06-02 08:50徐雄峰张非凡
电脑知识与技术 2018年10期
徐雄峰 张非凡


摘要:为了完善知识图谱的覆盖率,扩充学科知识库的知识量,使得基于知识图谱的学科问答检索更加精准,基于RDF的学科数据库扩充方法弥补了半自动语义标注的数据的效率慢和代价高的缺点.本文设计并实现了一种在领域学科本体库的基础之上,通过PYTHON 语言编写出基于本体的自动语义生成技术。以基础教育学科政治学科为例,对百度百科数据进行文本获取并生成RDF数据的扩充方法。实验结果证明,基于RDF的学科数据库扩充方法在应用于领域学科知识数据库扩充上具有较高的可行性和实用性。
关键词:知识图谱;本体;RDF;概念;属性
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)10-0242-03
Abstract: In order to improve the knowledge graph of the coverage, expand the amount of knowledge of the knowledge database, and make the subject question and answer retrieval more accurate based on the knowledge graph. The method of extending the subject database based on RDF makes up for the shortcomings of the slow and high cost of the semi-automatic semantic annotation. In this paper, an automatic semantic generation technology based on ontology is designed and implemented on the basis of the domain subject ontology library in the PYTHON language. Taking the political subject of basic education as an example, the method of expanding the text of Baidu encyclopedia data and generating RDF data. The experimental results show that the extension method of subject database based on RDF is more feasible and practical in the application of domain knowledge database expansion.
Key words: knowledge graph; ontology; RDF; concept; attribute
隨着知识图谱的发展,将知识图谱应用在中文领域已成为目前国内最新最热的研究方向之一,知识图谱对于构建知识间的逻辑关联性有着很大的帮助,同时使用知识图谱进行知识问答,相比较传统搜索问答,可以更加精准的获取答案[1]。对于构建基于知识图谱的知识库而言,知识图谱的标准数据通常是由资源描述框架RDF(Resource Description Framework)三元组数据存储形式构成[2]。对于学科领域的问答而言,知识库的大小,关乎知识图谱的丰富程度以及搜索问答的正确率。对于教育学科来说,通过人工语义标注和自动语义标注生成RDF数据的方法,在准确率上较高,但是在效率和成本上则太大,所以有必要研究如何在短时间内、低成本、准确地获取大量RDF数据有着很大的必要和研究意义。本文以基础教育学科政治为例来扩充数据库知识。政治学科是一门重要的基础教育学科,它既包含了中文语义多样化的特点,同时又是一门对其领域语言表达正误要求高的学科。而且对政治学科扩充采用依据本体的自动语义生成技术可以很好的应用到基础教育的其他学科。本文设计并实现了政治知识库的数据扩充方法,通过使用爬虫技术,对百科数据进行爬取,并生成RDF数据。经过对扩充数据的实验比较测试分析,基于RDF的学科数据库扩充方法在应用于领域学科知识数据库扩充上具有较高的可行性和实用性。
1 本体的构建
知识图谱从某种程度上来说是一张领域内的巨大语义网络图,它的本质是将领域内知识进行重组的一个过程,它在知识点之间建立一种逻辑关联,进而来描述真实世界里实体或概念及它们之间的关系[3]。知识图谱的架构包括逻辑架构和体系架构,逻辑架构包括知识图谱里最核心的模式层和数据层。对于知识图谱来说,本体库是用来管理知识图谱的模式层,它是知识图谱的核心[4]。本体对于构建领域知识图谱是很重要的一个环节,是一个建模的过程。本文在斯坦福大学Noy与McGuinness[5]提出的领域本体构建七步法之上,以政治学科为例,根据其学科特点,在政治学科领域专家的帮助指导下,通过人工的方式来构建政治学科本体。学科的本体构建不同于其他本体构建方式,人工构建政治学科领域本体可以保证其适用性和准确性。本文构建政治学科本体总共分为六个模块:领域范围、构建知识分类体系、构建知识概念体系、定义对象关系、本体修改以及本体审核。
领域范围:本体是一个特定领域的抽象,它是知识库的一个模型,在构建本体需要确定本体的范围。政治学科的本体构建领域范围是在政治学科老师的帮助指导下,确定了本体库的构建需要以初高中政治知识清单为参考目标,并且覆盖初高中政治学科知识点、中高考考纲考点,服务于初、高中学生学习,以及教师教学辅导。
构建知识分类体系:知识分类体系是对对学科教育教学的一个分类。本文以政治学科为例,对初、高中政治知识进行统一的划分。通过知识分类体系,可以很好地将政治知识间的上下位关系进行表示,对知识点之间的层次关系进一步明细结构化,如图1所示政治知识分类体系的部分内容。
构建知识概念体系:领域内的本体通常是由一定数量的术语以及术语之间的关系所构成的,术语(term)指的是领域内的重要概念[6-7]。在本文中,扩充数据针对的是政治学科,则本体是用来表示政治学科中知识点和知识点之间的关系,也就是政治重要概念。对于学科中出现的核心知识点、关键词语、关键概念,结合领域专家的意见,我们认为这些就是政治学科领域中的term,也就是本体中的类(owl:Class)。知识概念体系中的分层结构体现了分类概念之间的一种继承关系,建立政治知识概念体系统筹的将领域概念进行分类组织,可以更好地描述领域概念之间结构关系,使本体中的概念模块化。图2是知识分类体系中的部分内容,其中“货币”、“价格”、“法律”等,这些都是政治学科领域内的重要概念。
定义对象关系:定义对象关系其实是对属性的挖掘,包括对象属性以及常用属性挖掘,它们主要是对主语和宾语之间关系的进行挖掘。在知识图谱中,实体(即概念)和实例之间、实例和实例之间、实例和属性值之间需要通过一定的关系进行映射。本文中,以政治学科为例,我们通过LDA模型进行训练,用 “类型”这一对象属性来映射知识点实例所对应的知识概念模型。在知识点实例与知识分类体系上的关系映射上,使用“分类”来描述知识点实例与教育分类节点之间的关系。在实例之间的关系映射上,使用“强相关”于来进行描述。对于实例值和属性值之间的关系,我们根据统计学的原理,通过迭代的方式,在领域专家的指导下,在构建政治本体知识库的过程中,统计构建了政治学科关系属性表。除了三个基本的对象属性“类型”、“分类”、“强相关于”之外,政治学科共有122个常用属性。
本体修改:政治学科本体的构建是一个不断修改、丰富的过程。在语义标注的过程中,随着标注的进行,本体也在进行一定的修改完善。
本体审核:本体审核是人工构建本体的一个核实阶段,这也是目前手工构建本体的一个共识步骤。尤其对政治学科而言,通过政治学科领域专家对本体的检查以及提出的修改意见,可以更好的保证本体的完善性以及正确性。
2 基于本体的自动语义生成
在本文中,我们RDF三元组用<主语-谓语-宾语>来进行表达,主语也就是实例,谓语是关系,宾语则是属性值。实例对本体库中的实体而言,它是一个具体化的对象。基于本体来进行自动语义生成可以很好地完成实例和实体之间的映射,大大减少知识库与外部数据库融合时的困难,同时也可以更好地体现出知识图谱的完整。
以政治学科为例,基于本体的自动语义生成技术是根据已经构建好的政治本体库,构建政治实例表,在短时间内,使用网络爬虫的手段,对网络数据进行一系列的处理,最后生成可用的RDF数据。本文主要从数据来源和爬取方法两个方面对自动语义生成技术进行描述。
1)数据来源:百度百科有关政治学科资源数据。在对政治学科网站资源分析的对比中,我们发现百度百科中搜罗了大量的政治学科资源,其中包含了许多政治本体知识库中没有的政治知识点。同时百科内容结构化强,可以通过Python爬虫,对不同的实例进行同时分析爬取,在短时间内,获得大量的三元组数据。
2)挖掘对象:属性挖掘、属性值挖掘。在基于本体的自动语义生成技术中,我们需要根据已经构建的政治实例对百科词条页面内进行属性挖掘和属性值挖掘,也就是三元组中谓语和宾语的挖掘。
以百科中政治知识文本“文化基本定义是广泛的知识面与根植于内心的修养。”为例,依据本体库中的属性关系,我们可以构建下面一条正则表达式:
[基本定义\S{0,}?[,。]] (1)
式1正则表达式是通过“基本定义”属性所创建的,属性值提取“基本定义”后到最近的标点符号之间的文本,得到三元组“文化—基本定义—是广泛的知识面与根植于内心的修养”。
4)爬取流程:基于本体的自动语义生成 RDF数据的获取程序是使用python语言编写的,通过一些具体的正则表达式来进行三元组提取。根据政治学科本体,通过导入学科实例表,对获取的百科词条页面进行结构分析,通过正则语句生成RDF三元组,然后对获取的数据进行二次检索,最后生成并导出RDF数据。其中流程里的二次检索是针对政治学科而言的,在政治学科中有着一些特殊的敏感性词汇,用词不准确、不恰当,它不适用于基础教育教学领域,超出了初、高中政治学科的内容要求。通过二次检索中敏感词过滤的手段,可以将这些不适的内容剔除掉,从而保证获取数据的正确性,也避免了后期需要进行复杂的数据清洗(图3 RDF数据获取流程图)。
以百科词条中的“货币”为例:
? 首先将词条“货币”添加到实例文本中,从程序中导入实例文本。
? 正则匹配该词条实例所对的百科URL,正则语句:re.compile(r”(http://baike.baidu.com/.+?)\””)。
? 分析实例“货币”所在百科页面结构,获取正文内容。
? 从正文文本中筛选信息,进行正则匹配,提取实例“货币”中可用的三元组。
? 进行二次检索,在领域专家的指导下构建敏感词汇表,进行判定,进一步筛选,将数据信息中出现敏感词汇的三元组删除掉。判定语句:
for each_mingan in minganci:
if each_mingan in res_data[‘summary]:
flag=0#存在敏感詞则标记为0
break
? 导出Excel文件并生成RDF数据,其中Excel文件是为了方便进行人工核查,图4 是生成Turtle格式的RDF数据,表1是生成Excel格式的RDF数据,Turtle格式的RDF数据用于知识库存储和问答检索,Excel格式的RDF数据方便人工进行审核。
依据图4和表1的RDF数据分析,对于“货币”这一实例来说,在百科中的词条内容中,我们通过基于本体的自动语义生成技术共获得了6条三元组。
在本体知识库中,政治学科知识库一共有7065条三元组,这是由6位标注人员在一周的时间内进行半自动语义标注所生成的。而通过使用依据本体的自动语义生成技术,在6分钟内,对政治学科790个实例进行爬取,共获得4091条三元组。
3 实验与分析
3.1数据测试实验
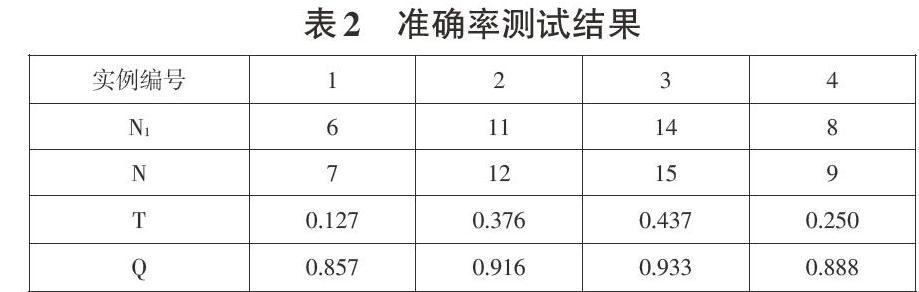
本文采用外部数据扩充准确率的方法对爬取数据生成的Excel进行检查实验。准确率判定公式是:
式(2)中N1是该实例对当前百科页面通过爬虫所获取的三元组数目,N是当前页面应获取的三元组数目,另外我们用时间T(单位s)来表示程序运行时间。
实验随机抽取4个实例进行了准确率测试(表2准确率测试结果)。
我们对表2中的数据进行分析,其中准确率测试均在0.857以上,其中在该实验中4个实例准确率的平均值为0.898。我们对4个实例所在的百科词条页面进行结构分析,发现主要原因是我们的正则表达式编写问题,正则匹配得到三元组过粗。通过对属性值进一步的挖掘,还可以获取更多条三元组。同时在敏感词的过滤上,由于是程序检索,会错误的删除一些有用的三元组。针对以上原因,我们认为通过正则去提取三元组,还需要经过大量的训练,同时在针对敏感词表过滤后的三元组数据,还需要经过再次处理。总体来说,通过随机数据测试实验的结果分析,依据政治本体的自动语义生成技术可以很大程度的增加政治知识图谱的规模,获得大量的RDF三元组。
4 总结
本文根据基础教育学科的特点来设计实现基于RDF的学科数据库扩充方法。根据上述实验分析以及自动生成的数据结果来看,通过本文的自动语义生成技术对政治数据的扩充是可行的。在自动语义标注的质量上有着一定的保证,可以很大程度上完善知识图谱的知识覆盖。另外应用于政治学科的自动语义生成技术在短时间内生成大量的RDF三元组,可以大大地减少物力人力,缩减时间,这将对中文知识图谱其他领域数据扩充有着很好的参照价值。
参考文献:
[1] 杜泽宇,杨燕,贺樑.基于中文知识图谱的电商领域问答系统[J].计算机应用与软件,2017(5):153-159.
[2] 张德政,谢永红,李曼,等.基于本体的中医知识图谱构建[J].情报工程,2017,3(1):35-42.
[3] 李涓子,侯磊.知识图谱研究综述[J].山西大学学报:自然科学版,2017(3):454-459.
[4] 许德山,张智雄,赵妍.中文问句与RDF三元组映射方法研究[J].图书情报工作,2011,55(6):45-48.
[5] Noy N F,Mcguinness D L.Ontology development 101:A guide to creating your first ontology,2001.
[6] 曹倩,赵一鸣.知识图谱的技术实现流程及相关应用[J].情報理论实践,2015,38(12):127-132.
[7] Shapiro S C.Knowledge Representation: Logical,Philosophical,and Computational Foundations by John F.Sowa[J].Computational Linguistics,2001,77(3):695-696.
猜你喜欢
哲学分析(2023年4期)2023-12-21
中国音乐学(2020年4期)2020-12-25
青春岁月(2016年22期)2016-12-23
中国教育信息化·基础教育(2016年9期)2016-10-18
文学教育(2016年27期)2016-02-28
