
基于Doc2vec和深度神经网络的中文文本情感倾向研究
2018-07-16 12:04王晨超刘洋
电子技术与软件工程 2018年10期
文/王晨超 刘洋
1 引言
随着互联网尤其是智能手机的普及,越来越多的人会在网络上发表自己的看法。因为网络空间的相对隐蔽性,使得人们比在现实生活中更有可能地发表一些负面或者消极的言论,让网络上充满着负面情绪。特别是一些网络热点事件的爆发时,网友会站在不同的观点对峙。同时,公众对于网络热点的态度和倾向,也往往会影响到政府相关机构的决定和行为。所以了解主流论坛、微博、博客等平台的网民总体情感倾向,对于政府而言,为政府同社会公众之间的沟通提供指导,使政府可以主动引导网络舆情朝着健康正确的方向发展,促进网络文化和社会环境的健康发展;对于商家而言,可以为他们投放广告宣传自己提供指导,到底哪些话题才是人们关注的热点,而人们对这些热点又持什么态度;对于个人而言,可以为寻找和他志同道合的论坛或是平台提供指导。而要掌握网民的情感倾向,就要使用到文本情感倾向分析的技术。文本情感分析是指对包含用户表示的观点、喜好、情感等的主观性文本进行检测、分析以及挖掘。
2 传统的情感分析技术

图1:Doc2vec原理图
目前,文本的情感分析研究内容主要分为3个方面:文本内容的主客观分类、文本的情感倾向性分类和文本的情感强度计算。本文所研究的是文本的情感倾向性分类。文本的情感倾向分析主要是通过一定的技术手段,将文本的情感分为正向或是负向两类。而较为传统的技术手段是:
2.1 基于情感词典的方法
构建一个情感词典,其中蕴含一个个感情强烈和感情倾向鲜明的词语和其对应分值,再建立相应的程度副词和否定词典等。通过抽取出一段文本中的情感词、否定词和程度副词等,结合已经建立的情感词典库,根据一定的公式计算出该文本的分数,依据分数,将文本判断为正向或是负向文本。
但基于情感词典的方法往往会有以下问题:无法准确的将长文本分类;无法准确的判断文本中有褒词贬用或贬词褒用的这类文本;还有用特定的情感词典和公式计算情感得分,会忽略了很多其他的否定词、程度副词和情感词,以及这些词的搭配情况,导致分类效果不佳。
2.2 基于传统机器学习的方法
基于传统机器学习的方法,常用的分类方法有:支持向量机分类法、中心向量分类法、K近邻算法分类法、感知器分类法、贝叶斯分类法和最大熵分类法等,通过此类分类器识别出该文本的倾向性。
相对于基于情感词典的方法,该方法更加客观,不单单只考虑了情感词等特定词语,综合考虑了文本中出现的大部分词语,所以对长文本也有较好的分类效果,故情感倾向分类准确率显著提高。
图2:最简单的MLP的结构
但该方法,仍有其弊端。机器学习的分类方法,一般有三种:有监督型、无监督型和半监督型。三者中,基于有监督学习的分类方法都有不错的分类效果,但是由于有监督学习依赖于大量人工标注的数据,使得基于有监督学习的系统需要付出很高的标注代价。而无监督学习和半监督学习虽然标注代价很低,但是由于中文文本的复杂性,所以分类效果都并不是很好。
3 基于深度神经网络的中文情感分析
神经网络是机器学习的一个子集,而深度神经网络是一类特殊的神经网络,相比于一般的神经网络,它往往不止一个隐藏层。2006年,加拿大多伦多大学教授、机器学习领域的泰斗GeoffreyHinton等在《Science》上发表了一篇文章点燃了深度学习在学术和工业界的星星之火。而基于深度神经网络的AlphaGo算法在2016年3月击败了前世界围棋冠军李世石,自此深度学习成为全社会的焦点,一些非计算机领域的专家学者也纷纷关注起了深度学习和人工智能。随着深度学习在在业界的发展,在很多领域之中,刷新了其记录,例如很多分类问题的准确率。
3.1 基于LSTM的中文情感倾向分析原理
LSTM(Long Short-Term Memory)即长短期记忆网络,是一种改进的循环神经网络(RNN)模型,也是一种深度学习的基本框架。LSTM把RNN隐藏层中的模块用带细胞的记忆单元来替代,同时信息选择地通过输入门和输出门。1999年,Gers等在改进了LSTM,引入了遗忘门。这细胞状态和三个门的设计,使得LSTM能够更新、记忆上下文的信息,从而具有对长距离信息的处理的效果。而LSTM的这些特性,是其能进行情感分析并有不错效果的关键。
通过Word2vec算法,将大量词语映射为高维向量表。而文本根据自身蕴含的词语,用多个高维向量来表示文本。向量化后的文本,就可以被机器所使用,可以用来训练LSTM模型。因为LSTM模型,不仅可以学习到文本中蕴含的词语的信息,还能学习到上下文词语之间的联系,所以导致模型有很强大的学习能力,有很好的分类效果。
相比于基于情感词典和传统机器学习的中文情感倾向分析,准确率大大提高。所以这是现有的中文情感倾向分析方法中,准确率较高的一种实现方法,往往有95%以上的准确率。
3.2 基于LSTM的中文情感倾向分析的不足
基于LSTM的方法,虽然有较高的准确率,但是相对应的其训练成本也巨大。而训练成本巨大的一个原因就是一个文本向量化后,它的向量数据太大。若一个词语映射为400维的向量,一个文本中蕴含了50个词,那么,这个文本向量化后,是一个50*400的矩阵,而往往一些文本可能蕴含超过50个词语。文本向量化后的向量数据过大以及LSTM模型训练时记忆上下文词语之间的关系,导致LSTM模型的训练成本急剧上升。相比于传统的机器学习方法,同样的语料库,基于LSTM的方法的训练时间是他们的几十倍甚至几百倍。虽然越大的数据代表了蕴含的信息更多,但是一个可以实际使用的模型或是工具,必须要考虑效率和成本之间的平衡。中文情感分倾向析也要平衡训练成本和准确率。一个既有较高准确率并且训练成本相对较小的模型,更具有普遍的适用性。
4 基于Doc2vec和深度神经网络的中文文本情感分析
LSTM训练成本较大的原因:一是文本向量化后的向量过大,二是进行的是时序分类,考虑了文本中各词语之间的联系。那么针对这两个原因,提出了基于Doc2vec和深度神经网络的方法,用Doc2vec训练出来的是文本向量而不是词语向量,这将大大简化文本向量化后的矩阵。并且采用非LSTM的另一种深度学习框架,这将降低原有的在训练神经网络时记忆的成本。

图3:实验流程
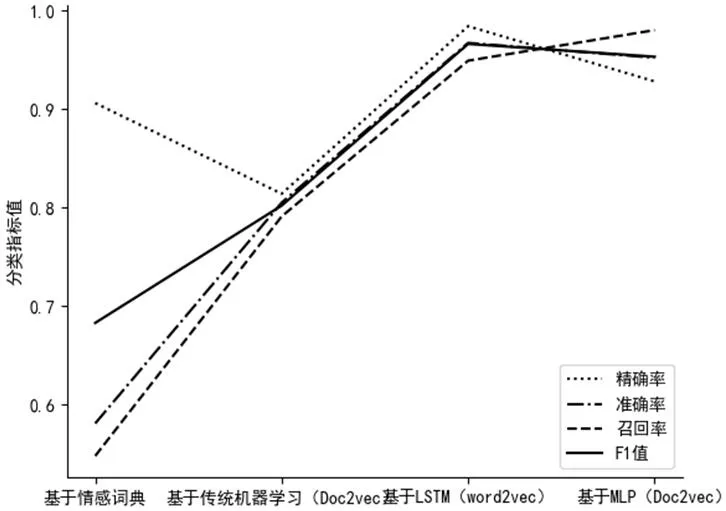
图4:经实验各模型分类效果图
4.1 使用Doc2vec来将文本向量化
Mikolov等人在2013年提出了Word2vec模型用于计算词向量。Word2vec模型利用词的上下文信息将一个词转化成一个高维实数向量,词如果越相似则在向量空间中越接近。基于LSTM的方法中,构建文本向量是将该文本中所有的词语通过Word2vec向量化,以此构建文本向量矩阵。基于Word2vec,Mikolov等人又给出了Doc2vec的训练方法。Doc2vec是在Word2vec的基础之上,不仅训练出词向量,并且还考虑了训练样本的上下文和单词顺序。在训练前,每一个文本都会首先初始化为一个N维的向量,训练过程中,会对输入向量进行及时反馈更新,在进行大量语料的训练之后,便可得到每一个文本相应的训练向量。用来表征文本的向量拥有一定的特性,即相近意义的文本在向量空间上它们的距离也是相近的。原理见图1。
因为使用了Doc2vec将文本向量化,而不是通过将词语向量化后再构建文本向量矩阵,实现了训练样本的精简。若原有一个文本中有100个词,词向量的维度为400,文本向量的维度也为400。那么原来100*400的训练样本就被简化为1*400,而训练样本的精简,之后训练分类模型的成本必将降低。
4.2 使用多层感知机来进行分类
LSTM是一种循环神经网络,在深度学习中,卷积神经网络(CNN)是除RNN外不得不提的,但我们并不使用CNN来构建中文文本情感倾向的分类器。为什么不用卷积神经网络来代替LSTM做情感分类器呢,原因是CNN仍需要花费大量训练成本在空间信息上,所以更多用于图像等蕴含空间信息的分类中。在简单的二分类问题中,CNN的训练成本仍较大,这时候,一种较为原始的深度神经网络-多层感知机发挥出更出色的作用。多层感知机(MLP)是一种前向结构的人工神经网络,映射一组输入向量到输出向量。MLP在很久以前就已被提出,但当时因为软硬件的不足,发展有着局限性,在大规模的网络中,会出现梯度消失和过度拟合。但是随着近些年深度学习的发展,MLP又重新得到了关注。
MLP的分类原理和神经网络的分类原理类似,以一个最简单的MLP为例,见图2。
在中文文本分类中,输入层是文本向量,隐藏层则对文本向量进行权重和偏置和函数激励的处理,输出层则输出逻辑回归后的结果。根据输出的结果,判断输入的文本是否属于同一类。而多个的隐藏层的神经网络就是广义上的深度神经网络。
在文本分类问题上,若训练样本更注重于自身蕴含的数据特征而不是不同数据之间蕴含的联系,那么多层感知机是一个十分优异的模型。因为Doc2vec已经考虑了文本的上下文和单词顺序,将文本直接向量化而不是通过词语的向量化后再构建的向量矩阵。这时,代表文本的向量是一个整体,并不包含单个词语的信息,也就不需要记忆上下文和词语。在这种情况下,用多层感知机来构建分类器比LSTM模型更合适。

表1:各模型训练成本(单位:s)
4.3 基于MLP和Doc2vec的方法和基于LSTM和Word2vec的异同点
基于MLP和Doc2vec的方法和基于LSTM和Word2vec的方法的相同之处是,都将数据的处理分为了两个过程,一是文本向量化的过程,而是向量化后的文本训练神经网络的过程。而两者的区别就是,前者在将文本向量化时就考虑文本中词语语序,将文本直接进行了向量化,而后者只是将词语向量化了,然后用词语的向量集合成一个矩阵来代表文本向量,这将使代表文本的数据远超前者,在训练神经网络时造成巨大的训练成本。而后者是在训练分类模型时才考虑文本中上下文信息,前者是最为基础的深度神经网络的二分类,前者的效率远超过后者。在这两个过程中前者都大大降低训练成本,因此基于MLP的Doc2vec的模型在训练成本上必定是远小于基于LSTM的Word2vec方法的。接下来,将通过实验来评估各种方法实现的模型的性能。
5 实验和结果
中文情感倾向分析,其实是分类问题。故可以用精确率,准确率、召回率和F1score来评估各个模型的分类效果。用训练所需的时间来代表训练模型所需要的成本。
5.1 数据集的准备
在实现基于情感词典的方法时,使用了大连理工情感词汇本体库、知网情感词典和台湾大学中文情感词典(NTUSD)构建自己的情感词典,使用哈工大的停用词表,使用知网的程度副词库,以及自己根据用语习惯构建的否定词库。
所用到的训练和测试语料均为SnowNLP库下的中文文本极性语料库。是关于网络购物评价方面的语料,已经标注好情感极向,有条正向评论和条负向评论,共计34946条。
将整个语料分为两部分,取出3000条正向文本和3000条负向文本做测试集,其余的语料做训练集。为了保证实验结果的可对比性,对于每一个模型所需要的训练语料相同测试语料也相同。
5.2 数据预处理
语料库的数据都是一些中文文本,各个分类模型无法直接处理,故需要进行数据的预处理。不管是基于情感词典的方法还是基于机器学习和深度神经网络的方法,都需要对文本进行分词,故使用jieba库进行分词。分别使用Word2vec和Doc2vec训练出词向量和文本向量,以供训练模型使用。Word2vec和Doc2vec是由gensim实现。
5.3 实验步骤
图3为本文实验的流程。
5.4 分类效果指标
在已训练好各个模型的基础之上,使用同样的测试集进行测试。分别测试出每一个模型的精确率,准确率、召回率和F1score。各个参数的含义:
定义:
True Positive(真正, TP):把正类预测为正类的数量.
True Negative(真负 , TN):把负类预测为负类的数量.
False Positive(假正, FP):把负类预测为正类的数量
False Negative(假负, FN):将正类预测为负类的数量

5.5 各个分类模型的性能评估
通过实验得到各模型分类效果,具体结果,见图4。
5.6 各个模型的训练成本
模型的训练成本由机器训练分类模型达到较好分类效果的时间来表示。主要的耗时时间为训练词向量和文本向量的时间以及训练分类模型所需要的时间,这两者的时间远大于其他中间过程的时间,故只用这两个时间之和表示模型的训练成本。因为基于情感词典的方法,既不需要使用词向量或文本向量也不需要分类模型,故训练成本定为0。为保证训练成本的可对比性,每一个模型的训练都由相同的电脑在只执行训练程序的情况下测得的数据,并且Word2vec和Doc2vec模型的训练次数都为50次。经实验,得到如下结果,见表1。
6 结论和展望
一个更精确以及适用性更广的中文情感倾向分析模型,是分析网络舆情、公民态度等的基础。而政府对于网络舆情等的更好地把控,也对于维护和谐社会有着巨大的作用。
通过实验数据可以表明,基于深度神经网络和Doc2vec的方法,在分类效果上是远好于基于情感词典和传统机器学习的方法的。虽然基于MLP的方法在召回率上比基于Word2vec和LSTM的方法略高,在精确率和准确率上略低,在综合评价分类模型效果的F1值也是略低。但是其训练成本是远小于基于LSTM的。准确率能达到95.5%,说明若实际使用,已有较好的效果,而远小于LSTM的训练成本,说明基于Doc2vec和深度神经网络的方法有更强的适用性。
未来可以进一步获取或者建立更有针对性的、数据量更大的样本。而这些样本有利于建立更好的模型和确定更加精确的模型参数。而用更好的模型可以建立更好的应用场景。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
大连工业大学学报(2015年4期)2015-12-11
传奇故事(破茧成蝶)(2015年7期)2015-02-28
海军航空大学学报(2015年4期)2015-02-27
