
DDN前景提取结合映射模型学习的行人再识别
2018-08-20 06:16胡正平张敏姣李淑芳
信号处理 2018年5期
胡正平 张敏姣 李淑芳
(燕山大学信息科学与工程学院,河北秦皇岛 066004)
1 引言
随着视频监控设备的广泛应用,行人再识别[1]已成为智能视频监控中的关键技术,对行人再识别技术进行深入研究,有助于实现公共场所安全监控的智能化,在社会公共安全方面具有重要的现实意义。
目前已有的行人再识别算法大致可分为基于图像描述和基于距离度量学习两大类。图像描述中常用颜色直方图或者融合特征[2]进行行人特征描述,由Zhao等人提出32维LAB颜色直方图和128维SIFT描述符,以5个像素为步长在样本中密集采样获得10×10结构块,之后在每个结构块内进行特征提取[3]。
而在行人再识别研究中,行人图像大多包含背景信息,这些背景信息对行人的正确匹配会造成影响,因此准确地进行前景提取后再提取特征对提高行人再识别算法的性能有重要作用。随着深度学习的广泛研究,现有深度模型具有高效的特征表达能力,从像素级数据到抽象语义概念逐层提取信息,这使其在提取图像的全局特征方面具有突出的优势。以行人图像分割为例,为预测每个像素属于哪个身体部位(头部、上身、下身),利用局部区域提供的有限信息量往往产生错误分类,因此全局信息对于局部判断非常重要。理想情况下,模型应该将整幅图像作为输入,直接预测整幅分割图,如此不但利用了上下文信息,在高维数据转换过程中还隐式地加入了形状先验。但由于整幅图像内容过于复杂,浅层模型很难有效捕捉全局特征,深度学习的出现使这一思路成为可能,在人脸分割[4]、人体分割[5]、人脸图像配准[6]和人体姿态估计[7]等方面都取得了成功。例如在行人图像语义分割研究领域,文献[5]提出利用深度分解网络(Deep Decompositional Network, DDN)对行人图像进行语义分割,获得行人的头部、上身、下身等区域的标签图。
提取鲁棒性特征的同时,距离度量方法对行人匹配能否成功也至关重要,因为在高维视觉特征中难以捕获不变因子,所以在行人再识别中可应用有监督全局距离度量学习来捕获不变因子。最常用的方式是通过线性缩放和特征空间的旋转覆盖欧式距离,基于此,经典度量学习方法结合最近邻域分类,Florin等人提出LMNN (Large Margin Nearest Neighbor)分类算法,该算法给邻近目标(匹配对)设定阈值,并且惩罚不同类之间的近距离,其属于有监督的局部距离度量学习模型[8]。另外一些研究把注意力放在学习具有区分性的子空间上。Liao等提出通过交叉视图数据,投影到一个低维的子空间w上,以相同的方式解决线性判别分析(Linear Discriminant Analysis, LDA)[9],在学习而得的子空间中,通过使用KISSME算法学习一个距离函数。为达到降维目的,Pedagadi等结合无监督的PCA和有监督的局部Fisher判别分析,保留局部邻域结构[10]。KISSME之前要对高维特征进行降维,文献[11]中,提出PCCA (Pairwise Constrained Component Analysis, PCCA),用以学习一个线性映射函数,进而能够直接在高维数据上操作,这些工作说明了学习特征子空间可以成功克服视域差异带来的特征差异。因此本文对于行人样本进行特征提取后,提出学习一个特征映射模型从而进一步对提取的视觉特征进行变换,用以解决两个摄像机视域差异问题。
综上,本文首先利用DDN模型对行人图像的前景进行准确有效的提取,然后提取前景图像的颜色直方图特征和原图像的Gabor纹理特征,利用行人特征通过研究映射模型学习对提取的视觉特征进行变换,最后通过学习的映射模型将查寻集和候选集中的行人特征变换到一个特征分布较为一致的空间中,进行距离度量和排序,从而成功克服了背景干扰以及摄像机视域差异和行人自身差异等问题。
2 DDN前景提取结合映射模型学习的行人再识别
2.1 深度分解网络的前景分割
该行人再识别算法的整体框图如图1所示。由图可见其中基于深度分解网络(Deep Decompositional Network, DDN)的前景分割是第一步,深度分解网络利用语义分割对行人图像进行前景提取,语义区域包括头部、上身、下身等,该方法直接将底层视觉特征映射成身体部件标签图。DDN通过三种连接的隐藏层估计被遮挡区域和分割身体区域,这三种隐藏层包括:遮挡估计层(Occlusion Estimation Layers)、实现层(Completion Layers)、分解层(Decomposition Layers)。遮挡估计层是一个二值掩模,将行人分割出来,如果存在遮挡那同时标明遮挡部分;实现层利用原始特征和遮挡掩模合成不可见部分的底层特征;分解层直接将合成的视觉特征变换成标签图,标签图对应行人身体的各个部件。训练这些隐藏层时,通过随机梯度下降法调整整个网络,通过估计一组权重矩阵和相应的偏置对DDN网络进行训练。
如图2所示为DDN的网络结构,行人特征向量x作为输入,一组身体部件标签图{y1,y2,…,yM}作为输出。每一层与下一层都是完全连接,该网络中有一个下采样层,两个遮挡估计层,两个实现层和两个分解层,此网络结构适用于行人部件分割和行人前景提取。

图1 算法整体框图Fig.1 Flow chart of the algorithm

图2 DDN网络结构Fig.2 DDN network structure
在DDN的底层中,输入特征为x,x经过下采样得到xd。x通过两个权重矩阵Wo1和Wo2映射成一个二值掩模xo∈[0,1]n,为了降低网络中训练的参数,设置xo与xd为相同的维数。xo表示为:
xo=τ(Wo2ρ(Wo1x+bo1)+bo2)
(1)
其中遮挡估计层第一层的激活函数为:
ρ(x)=max(0,x)
(2)
第二层激活函数为sigmoid函数为:
(3)
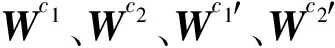
z=ρ(Wc2ρ(Wc1(xo·xd)+bc1)+bc2)
(4)
(5)
其中z为紧凑表示,而·表示矩阵的点乘。
(6)
其中yi=0表示像素属于背景,yi=1表示像素点属于行人身体部件。
2.1.1 遮挡估计层训练

(7)

(8)
(9)

2.1.2 实现层训练
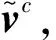
(10)
其中σ表示噪声的标准差,Wc、bc、uc为权重矩阵和偏置。常用的DAE利用随机噪声腐蚀每一个训练样本,本文算法使用结构化噪声腐蚀样本,图3所示为结构化噪声腐蚀模板,对于每个标准的干净样本,在图3中通过计算特征和40个噪声模板的点积生成40个腐蚀样本。

图3 结构化噪声模板Fig.3 Structured noise template
2.1.3 分解层训练

(11)
其中ht1表示第一个分解层的输出,两个分解层的训练可以按照遮挡估计层中的策略进行学习。
2.1.4 网络调整
对DDN网络所有参数的调整,通过最小化下边的损失函数:

(12)

(13)
其中diag(·)表示对角矩阵。例如第l下一层的激活函数是Sigmoid函数,反向传播误差el表示为:
(14)
其中Wl+1为权重矩阵,el+1表示下一层的误差,hl表示第l层的输出。对于具有修正线性函数较低的一层,反向传播误差通过下式计算:
(15)


图4 行人图像前景提取效果示例Fig.4 Example of pedestrian imagesforeground extraction

图5 前景提取图Fig.5 Foreground extraction
2.2 特征提取
首先利用DDN网络训练得到的模型对行人图像进行如图5所示的前景提取过程,其中(a)图为经过DDN网络提取得到的行人部件标签图,(b)为前景区域图,(c)为行人原图,(d)为行人的前景提取图。然后将前景图像和原图像平均分成18个水平条,行人图像特征提取过程如图6所示,首先对每个水平条提取RGB、HS、CIE Lab、NTSC和YCbCr颜色直方图,同时在其相应的原图上提取Gabor纹理特征,对每一种特征进行L1范数归一化后将这些特征进行级联,构成一个行人的特征。

图6 行人图像特征提取示意图Fig.6 Feature extraction
2.3 映射模型学习2.3.1 不同视域的特征差异

(16)
其中p和q表示两个不同摄像机拍摄的视域,通常情况下Up≠Uq。本质上,构建的模型是通过学习矩阵Up和Uq得到的,该模型既交叉视图映射模型。
2.3.2 视图特性变换降低差异

图7 交叉映射模型示意图Fig.7 Cross-view mapping model
(17)
fcross和fintra由等式(12)和(13)决定,η表示控制内部视图模型fintra的权重,其为正整数,
(18)
(19)
(20)

为了避免平凡解,即Uk=0,其k=1,2,...,N,加上约束条件并制定以下优化问题:
s.t.UkTMkUk=I,k=1,2,...,N
(21)
其中Mk=XkXkT+μI,I表示单位矩阵,从而可以避免协方差矩阵的奇异性,这些约束确保每一个区域的映射特征有单位幅值,不会缩小为零。
2.3.3 核扩展

(22)
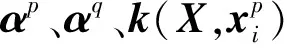
s.t.αkTM′kαk=I;k=1,2,...,N
(23)
2.3.4 优化求解
线性情况和非线性情况的优化求解过程是相似的,以线性情况为例进行优化求解。待优化的目标函数可以写成:
(24)

将目标函数进一步简化为:
f=tr(UTRU)
(25)
U=[U1;U2;...;UN]∈RNd×C
(26)
(27)
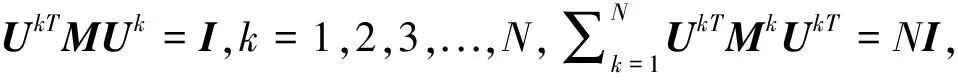
s.t.UTMU=NI
(28)
上式中M=diag(M1,M2,...,MN)。式(28)表示的优化问题可以通过计算相应的最小特征值的特征向量解决:
Ru=νMu
(29)
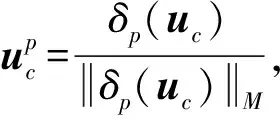
经过以上步骤,学习视域p和q的两个映射矩阵Up和Uq从而得到映射模型,这个模型可以寻找到一个潜在的公共空间,在这个空间中,不同摄像机视域下的同一行人的特征更加相似,而不同行人的特征差异更大。该模型应用在不相交的摄像机视域下的行人图像匹配中,能够保留更多判别性特征表示。
3 实验仿真研究
本实验在VIPeR、PRID450S和CUHK01三个数据库上进行,三个数据库的行人示例如图8所示,且在所有数据集上采用CMC(Cumulative Match Characteristic)曲线及其匹配率排名对包括本算法在内的9种算法进行对比评估,其他8种算法分别为:成对约束成分分析(Pairwise Constrained Component Analysis, PCCA)[11]、局部费舍尔判别分析(Local Fisher Discriminant Analysis, LFDA)[10]、支持向量机距离度量(Support Vector Machine Metric Learning, SVMML)[12]、简单直接的度量学习(Keep It Simple and Straightforward Metric Learning, KISSME)[13]、正则化成对约束成分分析(regularization Pairwise Constrained Component Analysis, rPCCA[11]、核心局部费舍尔判别分析(krernel Local Fisher Discriminant Classifier, kLFDA)[10]、边界费舍尔分析(Marginal Fisher Analysis, MFA)[14]、内核交叉视图判别成分分析(Kernel Cross-View Discriminant Component Analysis, KCVDCA)[15]。实验表格中rank=1、rank=5、rank=10、rank=20对应实验结果的实际意义为,分别取行人再识别距离度量后排序阶段中排序前1、5、10、20位行人时恰好存在被查询行人的概率,本文中以百分比的形式给出结果。实验平台为处理器AMD Athlon(tm)ⅡX2 255 Processor 3.10 GHz,内存10.0G以及Windows7、64位操作系统。

图8 各数据库中的行人示例Fig.8 Person examples
3.1 VIPeR数据库
在行人再识别研究领域VIPeR数据库是最早被公开、应用比较广泛的行人再识别数据集。该数据集行人目标是从户外拍摄的原始视频序列中手动准确地裁剪出来的,共包含632个行人目标,每个行人目标包含两张图像,整个数据集共有1264张图像,其中每张图像的大小归一化为128×48。实验时,将数据集分成训练集和测试集两组,其中测试集包括:查寻集和候选集,为了与已有算法作公正对比,制定有效的评价框架,将数据集随机平均分成两部分,其中一部分作为实验的训练集,另一部分作为测试集。在VIPeR数据库中利用CMC曲线对9种算法进行性能比较,其评估结果分别如图9和表1所示。由实验结果可以看出在VIPeR数据库中本文提出的方法与KCVDCA方法的实验结果比较接近,因为该数据库的背景较为简单,且摄像设备的参数设置相近,只是角度发生较大变化,因此在特征提取前进行前景提取的效果发挥受到局限。而KCVDCA方法与本文学习映射模型的方法思路类似,均是学习一个新的特征空间然后进行距离度量,也可以较好的克服视域角度差异的问题,因此针对VIPeR数据库的实验效果接近,但是对比代表真正识别率的rank1可以发现,本文提出的方法较于KCVDCA方法的性能超出1.17%,证明了本文算法在实际应用中的效果优于KCVDCA。实验证明本算法能够解决背景干扰的问题,从而提高了算法的鲁棒性。
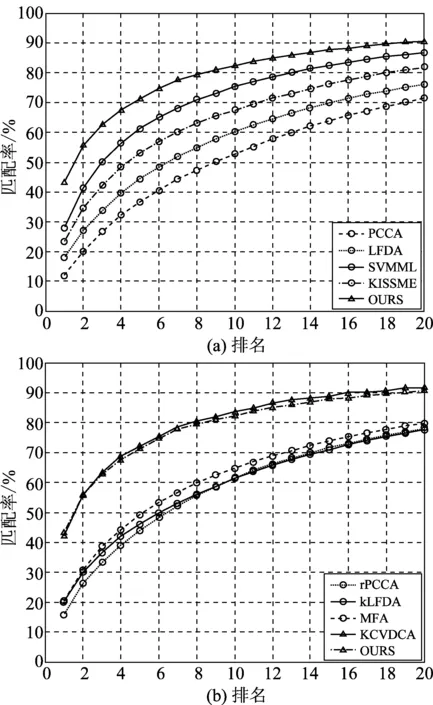
图9 VIPeR数据库上的CMC曲线比较Fig.9 CMC Curves on VIPeR database

算法rank=1rank=5rank=10rank=20PCCA[11]11.98%36.71%52.10%71.41%LFDA[10]17.96%44.38%60.09%76.17%SVMML[12]28.03%61.20%75.16%86.65%KISSME[13]23.35%52.95%67.51%81.78%rPCCA[11]16.05%44.09%61.67%78.24%KLFDA[10]20.24%46.18%61.16%77.58%MFA[14]20.63%49.36%64.79%79.79%KCVDCA[15]41.99%72.15%83.58%91.78%OURS43.16%71.20%82.28%90.44%
3.2 PRID450S数据库
PRID450S数据库由公路旁的两个不同摄像机捕获地450个行人目标组成,同一个行人目标包含两张光照强烈变化的图像,每个图像尺寸不相同,本文在进行实验时,将行人图像归一化为160×60,同样将数据库集随机平均分成两部分,一部分作为训练集,另一部分作为测试集,其中测试集的一半作为查找集,另一半作为候选集,在PRID450S数据库中利用CMC曲线对9种算法进行性能比较,其评估结果如图10和表2所示。由实验结果知本算法第一匹配率最高,本文算法因为克服背景干扰的问题,对提取鲁棒性特征具有良好表现。

表2 PRID450S数据库上几种算法匹配率比较

图10 PRID450S数据库上的CMC曲线比较Fig.10 CMC Curves on PRID450S database
3.3 CUHK01数据库
CUHK01数据库中的行人图像来源于大学校园,是从两个视域不相交的摄像机拍摄的视频中裁剪下来的,其中含有971个行人。该数据集每个摄像机视域中包含同一行人的两张图像,共有3884张图像,图像归一化为的160×60。由于本文研究的是单发情况下的行人再识别,所以在每个摄像机视域下仅选取同一行人的一张图像来进行实验,即本实验随机选取了1942张行人图像。在本文实验中,随机将选取数据集平均分成一半,一半作为训练集,另一半作为测试集。
在CUHK01数据库中利用CMC曲线对9种算法进行性能比较,其评估结果分别如图11和表3所示。CHUK01数据库在大学校园拍摄采集过程中背景变化单一,但是背景同样会对提取判别性特征造成影响,由图11和表3可知本算法可提高匹配率,消除背景干扰的问题。

图11 CUHK01数据库上的CMC曲线比较Fig.11 CMC Curves on CUHK01 database

算法rank=1rank=5rank=10rank=20PCCA10.99%30.87%43.49%57.93%LFDA13.11%29.83%39.96%51.86%SVMML19.66%45.77%59.69%73.42%KISSME15.49%35.84%47.90%60.48%rPCCA14.71%38.69%52.34%66.65%kLFDA13.07%31.87%43.29%56.44%MFA14.00%33.07%44.61%57.48%KCVDCA38.43%66.05%75.37%83.68%OURS45.47%68.52%76.95%84.16%
4 结论
针对行人背景干扰的问题,本文设计DDN网络结合映射模型学习的行人再识别算法,在解决不同摄像机下视域差异造成的同一行人特征分布不一致问题的基础上,设计DDN模型进而准确有效地进行前景提取,然后提取行人图像视觉特征,得到鲁棒性特征表示,从而解决背景干扰问题,最后进行映射模型学习,行人再识别匹配率得到提升。值得注意的是:学习映射模型时,需要针对特定摄像机配对来进行学习,随着智能监控网络的广泛应用,需要对大量摄像机进行配对处理,从而处理数据大大增加,如何学习一个具有良好推广能力的映射模型方法同时又能克服不同摄像机下行人特征分布不一致问题还需进一步研究。
[1] Wang Xiaogang. Intelligent multi-camera video surveillance: A review[J]. Pattern Recognition Letters, 2013, 34(1): 3-19.
[2] 冯星辰,阮秋琦.行人跟踪的多特征融合算法研究[J].信号处理, 2016, 32(11): 1308-1317.
Feng Xingchen, Ruan Qiuqi.Research on Multi-feature Fusion Algorithm for Pedestrian Tracking[J]. Journal of Signal Processing, 2016, 32(11): 1308-1317.(in Chinese)
[3] Zhao Rui, Ouyang Wanli, Wang Xiaogang. Learning mid-level filters for person re-identification[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA: CVPR, 2014: 144-151.
[4] Luo Ping, Wang Xiaogang, Tang Xiaoou. Hierarchical face parsing via deep learning[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA: CVPR, 2012:2480-2487.
[5] Luo Ping, Wang Xiaogang, Tang Xiaoou. Pedestrian parsing via deep decompositional network[C]∥IEEE International Conference on Computer Vision, Sydney, Australia: ICCV, 2013: 2648-2655.
[6] Sun Yi, Wang Xiaogang, Tang Xiaoou. Deep Convolutional Network Cascade for Facial Point Detection[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA: CVPR, 2013: 3476-3483.
[7] Toshev A, Szegedy C.DeepPose: Human pose estimation via deep neural networks[C]∥IEEE Computer Vision and Pattern Recognition, Columbus, OH, USA: CVPR, 2014: 1653-1660.
[8] Florin L, Silvia C. Large margin nearest neighbour regression using different optimization techniques[J]. Journal of Intelligent & Fuzzy Systems, 2017, 32(2): 1321-1332.
[9] Liao Shengcai, Hu Yang, Zhu Xiangyu, et al. Person re-identification by local maximal occurrence representation and metric learning[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA: CVPR, 2015: 2197-2206.
[10] Pedagadi S, Orwell J, Velastin S, et al. Local FISHER discriminant analysis for pedestrian re-identification[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA: CVPR, 2013: 3318-3325.
[11] Mignon A, Jurie F. PCCA: a new approach for distance learning from sparse pairwise constraints[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island, USA: CVPR, 2012: 2666-2672.
[12] Li Zhen, Chang Shiyu, Liang Feng, et al. Learning locally-adaptive decision functions for person verification[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA: CVPR, 2013: 3610-3617.
[13] Armagan A, Hirzer M, Lepetit V. Semantic segmentation for 3D localization in urban environments[C]∥IEEE Urban Remote Sensing Event(JURSE), Dubai, United Arab Emirates: JURSE, 2017: 1- 4.
[14] Chen Yingcong, Zhu Xiatian, Zheng Weishi, et al. Person re-identification by camera correlation aware feature augmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, PP(99): 12-24.
[15] Chen Yingcong, Zheng Weishi, Lai Jianhuang, et al. An asymmetric distance model for cross-view feature mapping in person re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017: 1661-1675.
猜你喜欢
社会科学战线(2022年8期)2022-10-25
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
冰雪运动(2020年1期)2020-08-24
武术研究(2020年2期)2020-04-21
中国外汇(2019年11期)2019-08-27
中国公共安全(2017年11期)2017-02-06
办公自动化(2016年18期)2016-12-17
太空探索(2016年10期)2016-07-10
新闻前哨(2015年2期)2015-03-11
