
结合句法特征和卷积神经网络的多意图识别模型
2018-08-27 10:42杨春妮冯朝胜
计算机应用 2018年7期
杨春妮,冯朝胜,2
(1.四川师范大学 计算机科学学院,成都 610101; 2.电子科技大学 信息与软件工程学院,成都 610054)(*通信作者电子邮箱csfenggy@126.com)
0 引言
深度学习最近在语音识别领域取得了显著成就,人机交互的方式已从最初的文本信息交互方式发展到语音交互方式,苹果的Siri、亚马逊的Alexa等语音交互助手的广泛应用宣告着语音交互时代已经到来。语音交互的总体流程大致可分为自动语音识别(Automatic Speech Recognition, ASR)、口语理解(Spoken Language Understanding, SLU)、对话管理(Dialogue Management, DM)和语音合成(Text-To-Speech, TTS)四个步骤。ASR是将用户说出的话转化为文本,SLU是理解用户的意图并抽取文本中的关键信息,DM是对机器和用户的对话进行管理,TTS是将机器生成的文本用语音返回给用户。机器对于语义理解的准确率依赖于ASR的准确率,但最重要的还是依赖于SLU的准确率。
而多意图(Multi-Intention, MI)识别是SLU中的难题,与多标签(Multi-Label, ML)分类类似,多意图识别难于如何准确地确定用户有多少个意图,用户的这些意图分别属于什么类别。现有的研究方法主要分为两种:一种是将问题转化为传统的分类问题;二是调整现有的算法来适应多意图的分类,但都不能更好地解决计算量大、准确率低的问题。
本文针对如何发现句子包含多意图、如何确定具体有几个意图、如何准确提取用户多个意图这三个问题,提出了一种结合句法特征和CNN的多意图识别模型。该模型采用现有的智能客服系统的真实数据进行实验,实验结果表明,该模型在多意图识别上具有较高的精准率和召回率,且具有较好的鲁棒性和可扩展性。
1 相关工作
1.1 意图分类算法
意图分类,就是对短文本进行分类。文本分类除了是语义理解的核心部分,也是信息检索、信息过滤、情感分析等自然语言处理(Natural Language Processing, NLP)领域各个任务的重要组成部分[1]。
对于英文短文本分类问题的方法,主要分为基于规则的方法、基于传统机器学习的方法和基于深度学习的方法。基于规则的方法首先需要人工进行规则制定,即什么关键词对应什么类别。这种方式大多使用词袋模型,从词袋中选取句子特征;但该方法无法脱离人工制定规则的部分,且这种方式不易扩展。基于机器学习的方法通常使用分类器,如逻辑回归、朴素贝叶斯、支持向量机等,但基于机器学习的方法都无法解决矩阵稀疏的问题,且依赖大量的标注性语料,同样无法降低人工成本。随着深度学习在机器视觉和语音识别上取得的显著成效,研究者们也将其运用在文本分类任务中。文献[2]提出的单层textCNN模型,利用文献[3]中训练的词向量替换原本的句子进行CNN训练,该模型在多个基准数据集上测试都取得了较好的效果,证明了其可以运用在多个领域的文本分类中。文献[4]提出了一个针对短句子的循环神经网络(Recurrent Neural Network, RNN)模型和针对长句子的长短期记忆(Long Short-Term Memory, LSTM)网络模型,但是记忆单元深受未登录词(Out-Of-Vocabulary, OOV)问题的影响,所以还提出了一个基于n-gram的算法解决OOV问题,该模型比前馈神经网络和增强型分类器有更好的效果。因CNN无记忆单元,RNN和LSTM不能局部提取文本特征,一些文献将这两种类型的网络结合[5-6]。因神经网络训练速度缓慢,文献[7]提出的Fasttext模型,该模型类似于文献[3]中连续词袋(Continuous Bag-Of-Words, CBOW)结构,以树形结构快速训练词向量和文本分类,该模型的特点就是快,但采用词袋的方式,忽略了词语的顺序。
由于中文存在句子分词不准、词汇量大、语义复杂、语境繁杂等问题,英文的短文本分类法不能直接使用。目前中文的短文本分类法主要分为特征扩展的方法和基于深度学习的方法。特征扩展有基于词向量的和基于文档主题生成——潜在狄利克雷分析(Latent Dirichlet Allocation, LDA)模型的方法。文献[8]基于词向量提出一种短文本特征扩展方法——WEF(Word Embedding Feature),使用多个数据库训练词向量,再对词向量进行聚类,然后用推理的方法扩展短文本的特征。文献[9]提出了一种利用LDA的主题词和特征分类权重相结合的特征扩展方法,并利用不同类别词汇之间的信息差异的特征权重分布来克服LDA模型进行特征扩展的不足。基于深度学习的方式主要是利用CNN进行短文本分类。文献[10]提出了一种结合字符和词(Char and Phrase, CP)的双输入CNN模型——CP-CNN,该方法使用拼音序列的文本表征方式来替换以往的词向量表征方式,并利用k-max降采样策略来增强模型的特征表达能力。文献[11]提出一种结合语义扩展和CNN的方法,对新闻数据集进行分类,首先提取标题中的信息,然后利用CNN进行语义扩展。
虽然现已提出很多方法来解决新闻数据等短文本分类问题,但是上述方法不能很好地解决对话系统中的意图分类问题,因为对话系统中的口语句子随意性更大,特征更难提取。
1.2 多意图分类算法
多意图分类的研究工作类似于多标签(ML)分类的研究。两者的相同点是:
1)类别数量不确定,有的样本只属于一类,而有的样本属于多类;
2)类别之间有相关性、依赖性,这一问题是多标签分类的一大难点。
两者也有不同点,多标签分类常用于图书、文章等长文本,且标签之前存在关联性;而本文的多意图分类用于口语短文本,意图之间大多不具有关联性。
目前有很多多标签分类算法,根据解决问题的角度可分为两类:一是转化问题的方法;二是算法适应的方法。转化问题是增加类别,把多个类别合成一个新的类别,再使用现有的多分类算法来解决,这是从数据的角度来解决;算法适应是针对某一多分类算法进行改进和扩展,使其可以进行处理多标签的数据,这是从算法的角度来解决。转化问题的代表性算法有Label power-set method[12]、Binary Relevance[13]、Calibrated Label Ranking[14]、Randomk-labelsets[15],但是这类方法必然会增加标签个数,且需要更大的数据量,增加了算法复杂度。算法适应的代表算法有基于K最近邻(K-Nearest Neighbors,KNN)的方法——ML-KNN(Multi-LabelK-Nearest Neighbors)[16]、基于支持向量机(Support Vector Machine, SVM)的方法——Rank-SVM(Rank Support Vector Machine)[17]和扩展标签依赖的方法——LEAD(multi-label Learning by Exploiting lAbel Dependency)[18],这类方法是针对问题本身进行研究,更加适应多标签的分类。随着深度学习的快速发展,基于此的多标签分类算法也层出不穷,如结合弱监督学习和CNN来解决图片的多标签分类问题[19]、结合CNN和RNN解决文本的多标签分类问题[20]等。在国内的研究中,文献[21]提出一种结合旋转森林和AdaBoost分类器的多标签文本分类法,首先利用旋转森林来分割样本,通过特征扩展形成新的样本集;然后基于AdaBoost对样本分类。文献[22]提出一种基于随机子空间的多标签类属特征提取算法——LIFT_RSM(Multi-label learning with Label specific FeaTures based on Random Subspace)算法,该方法通过综合利用随机子空间模型和降维方法来提取特征,从而提高分类效果。文献[23]提出一个针对微博句子的多标签情感分类系统,首先将语料表示为词向量,再采用CNN模型将词向量合为句子向量,最后将这些句子向量作为特征来训练多标签分类器。
上述方法解决了部分多标签分类问题,但不能直接用来解决语义理解中的多意图识别问题。多意图识别问题中各个意图只属于一个类别,因此需要对文本进行句法分析,此外还需要对用户进行否定情绪判断。
2 多意图识别模型
本文的多意图识别模型结合了依存句法分析、语义依存分析、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)算法、词向量、标准欧氏距离计算和卷积神经网络等。该模型在下文中简称“模型”。
2.1 模型总体框架
模型总体框架如图1所示。模型由4个部分组成,分别是多意图发现模块(Multi-intention Discovery Module, MDM)、多意图个数识别模块(Size of Multi-intention Finding Module, SMFM)、意图分类模块(Multi-intention Classification Module, MCM)、情感极性判断模块(Emotional Polarity Judgment Module, EPJM)。
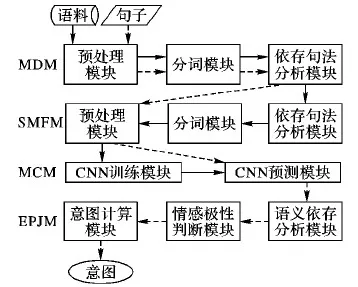
图1 模型总体框架
MDM的任务是利用依存句法分析(Dependency Parsing, DP)提取句子的句法特征,根据并列关系发现句子是否包含多意图。这一模块可以发现句子中显式的多意图,且根据并列关系的个数可初步确定意图的个数。
SMFM的任务是识别句子中多意图的个数,即可以对MDM中显示的多意图个数进行判别,也可以发现隐式的意图,主要通过计算句子中的词语与意图类别的关键词之间的距离,距离越小,词语与该意图越相关。
MCM的任务是利用改进的CNN模型对处理后的句子进行意图分类,对MCM中发现的意图分别进行分类。用SMFM中计算的距离矩阵作为CNN模型的输入,替换一般textCNN的输入,突出意图类别的特征。
EPJM的任务是正确理解用户的意图情感极性,过滤否定极性的意图。前面的模块仅仅识别了句子中包含的意图,未进行情感判断,EPJM通过对句子的语义依存分析,提取存在的否定极性,计算出用户的真实意图。
2.2 基于句法特征的多意图发现
对于意图的发现采用DP来提取句法特征。DP通过分析句子组成部分间的依存关系揭示其句法结构特征。直观地说,DP就是识别句子中的“主谓宾”“定状补”等语法成分,并分析各部分之间的关系。例如,“我想领优惠券,还想查询快递到哪儿了!”(例1)该句子的DP结构如图2所示,该结构中包含的关系如表1所示。
在多意图发现任务中,需要关注句子是否含有并列关系(COOrdinate, COO)。COO可以是相互关联的不同事物,也可以是同一事物的不同方面,还可以是同一主体的不同动作。如果句子的DP结构中存在COO时,说明句子中含有多个事物或动作,也就是多个意图。

表1 例1中包含的语义依存关系
用SDP={dpi}(i=1,2,…)表示句子s的依存关系集合,ms表示句子是否为多意图,计算公式如式(1)所示:
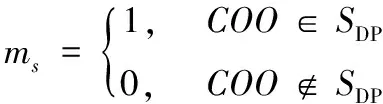
(1)

图2 例1的依存语义分析结构
2.3 基于TF-IDF和词向量的意图个数识别
2.3.1 TF-IDF提取关键词
TF-IDF是一种基于统计的常用加权技术,该值的大小取决于一个词在文档或语料中重要度,因此常用来提取一篇文档的关键词或区别文档的类别。其中,TF是词频(Term Frequency),指一个词在一篇文档中出现的频率;IDF是反文档频率(Inverse Document Frequency),指文档总数与包含该词语的文档数之商的对数。TF和IDF的公式如下:
(2)
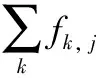

(3)

TFIDF=TF*IDF
(4)
式(4)是TF-IDF的计算方法,在同一类文档中出现的高频词,但又在所有文档中属低频,产生了高权重的TF-IDF值,因此,TF-IDF高的词语在特定一类文本中权重大且预测文本分类的能力强。在模型中,首先抽取出每一类意图中TF-IDF值最高的词语作为该意图的关键词。
2.3.2 基于词向量的意图个数识别
常用的词向量技术是one-hot,但是该技术形成的是稀疏矩阵,且无法表示词语和词语之间的关系。模型中采用文献[3]提出的方法来训练词向量,该模型是通过神经网络构建的语言模型,利用上下文信息将词语表示为低维向量,向量中的每一维都表示词语语义,可根据向量间的距离来表示词语的相关性。Rdim表示词向量空间,dim表示向量空间的维度,词语向量之间的距离就是词语的距离,距离越小,两个词语就越相关。模型用加权欧氏距离(Weighted Euclidean Distance, WED)表示意图类别中TF-IDF值高的词和待识别句子中各个词语的距离。WED是简单欧氏距离的改进算法,目的是规避词向量各维分布不均匀的情况,标准化向量各维数据的公式如下:
x*=(x-m)/a
(5)
其中:x和x*表示原始值和标准化后的值;m和a表示向量的均值和标准差。
假设有两个n维词向量A={x1,1,x1,2,…,x1,n}与B={y2,1,y2,2,…,y2,n},用普通的欧氏距离公式计算为:
(6)
将标准化公式代入式(6)中可得:
(7)
用类卷积操作对待识别意图的句子进行距离计算。具体计算方式如图3所示。
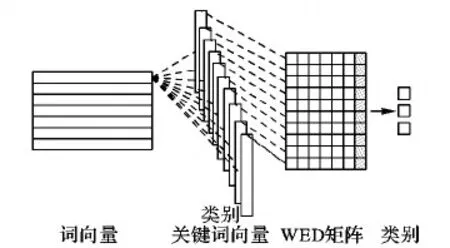
图3 距离计算框架
假设有nword个词语的句子表示为词向量:
有nclass个意图,这些意图的关键词词向量表示为:
两者作类卷积的操作计算距离disti,k=distance(wi,wk)。
距离矩阵DIST表示为:
计算分为两个向量和两个操作。两个向量是指待识别句子的词向量拼接矩阵(Word Embedding)和每个意图中TF-IDF值最高的关键词的词向量。两个操作是指类似于卷积操作和最大池化操作,首先计算待识别句子中的每一个词与每一个类别的距离,也就是相关度,得到WED矩阵;然后通过最大池化操作提取每个词最相关的类别,并设置一个相关度阈值,过滤掉小于该值的类别。经过计算可以识别出句子所含意图的个数。
2.4 基于CNN的意图分类
目前流行的意图分类算法中fasttext速度最快,但是实验表明fasttext模型的准确率依然不及textCNN模型。而横向比较深度学习解决意图分类问题的模型中,textCNN模型效果最好,本文的模型就是在该textCNN模型上进行改进。改进的CNN模型框架如图4所示。对多意图的识别,需突出句子的特征,因此用前面计算的距离矩阵DIST作为输入层来替换textCNN模型[8]中的输入,在通过一个卷积层和池化层,并经过全连接层和softmax层输出意图集合T。
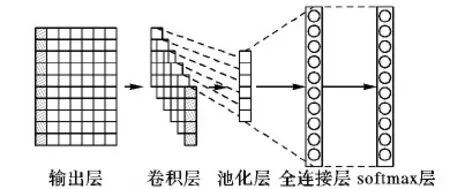
图4 改进的CNN模型框架
2.4.1 输入数据的构造过程
用DIST替换原来模型中的词向量拼接矩阵。对于单意图分类,直接把DIST作为CNN模型的输入;对于多意图识别,需依次用DIST的均值替换句子中几个和意图分类最相关的词,也就是对句子中的意图进行一个一个识别,图中灰色部分表示被均值向量替换后的向量。
2.4.2 模型训练过程
模型训练分为4步。
1)卷积层。设置卷积核FLT(filter)的尺寸为n*nclass,目的是提取n个上下文词语组合的特征,共有m个FLT,所以计算后会有m个feature map,如式(8)所示:
c=Relu(∑DIST⊗FLT+B)
(8)
其中:B是偏置量,c是卷积层计算结果。
2)池化层。对每个尺寸的feature采用max-pooling最大池化进行采样,然后flatten所有特征值得到全连接层的输入。
3)全连接层、softmax层。将特征元素进行全连接操作后,通过softmax输出10个任务类型的概率。为了防止过拟合,在全连接层使用了dropout策略,就是在计算时随机丢掉一定比率训练好的参数,根据Srivastava等[24]交叉验证实验,确定dropout为0.5的时候效果最好。反向传播采用随机梯度下降(Stochastic Gradient Descent, SGD)法[25]。
4)对输出向量进行分数评判,设定分数阈值,若某个类型出现的概率最大,且超过阈值,则判定句子包含该意图。
2.5 基于情感极性判断的意图确定
通常的意图识别缺少这一环节,却是最关键的环节。例如“我想查话费,不想查快递”,模型前面的环节只能判断用户有查话费和查快递的意图,却忽略了用户的否定意图,因此进行用户情感极性判断是必要的。模型采用语义依存分析提取句法特征进行极性判断,判断用户的肯定情感和否定情感。主要是判断分析结果中是否有否定标记mNeg(Negation marker)。上例中的语义分析提取结果如图5所示,图中所有标记如表2所示。
情感极性判断后,利用式(9)计算用户最终意图:
Y=∑sp·class
(9)
其中,意图class包含否定标记mNeg时,则sp为0;反之sp为1。在例2“我想查话费,不想查快递”中,包含意图查话费class1和查快递class2,经过语义分析可知class2含有mNeg关系,因此用户的最终意图计算为:
class1*1+class2*0=class1
则上个例子中用户的意图为查话费。如果包含3个及以上意图,也用同样的方法计算。

图5 例2的语义依存分析结构
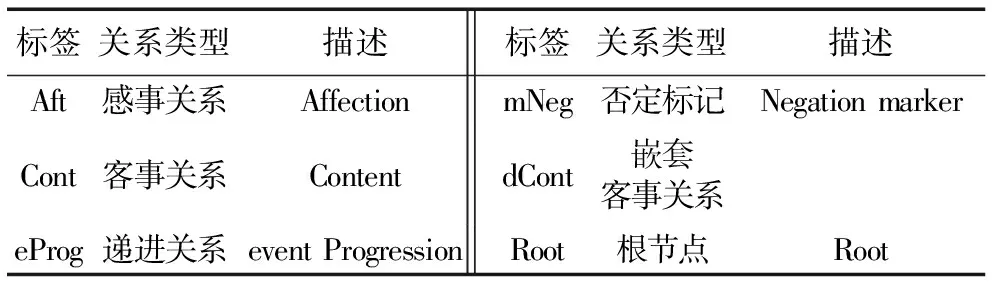
Tab. 2 Semantic relationship in No. 2 example
3 实验结果及分析
3.1 实验数据
实验数据来自正在使用的千行集团智能电商客服平台,共选取了10个类别,语料共有59 664条,词数总计940 716个,平均句子长度为15.77。每个类别的语料分布情况如表3所示。其中,随机划分70%作为训练集,剩下的30%作为测试集。
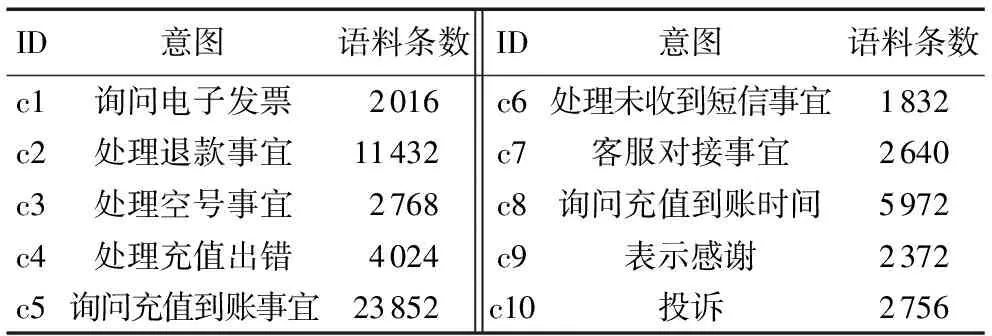
表3 分类语料分布
3.2 实验评价方法
本实验中评价方法分为单意图分类和多意图识别两种评价指标。
3.2.1 单意图分类的评价指标
单意图分类的评价指标是精准率(Precision)、召回率(Recall)和F值,具体把每个分类看成分类正确和不正确这样的二分类问题,假设用A表示模型识别的正样本个数,B表示真正的正样本个数,则三个指标的计算方式如下:
Precision(A,B)=(A∩B)/A
(10)
Recall(A,B)=(A∩B)/B
(11)
F=(2·Precision·Recall)/(Precision+Recall)
(12)
3.2.2 多意图识别的评价指标
由于多意图识别的特殊性,一个句子包含多个意图,评估效率时需要对这些意图预测的类别正误都进行判断,因此单意图分类的评价指标不再适用于此。本实验采用文献[21]的评价指标,有:准确率(Multi-Intention Accuracy, MIA)、精准率(Multi-Intention Precision, MIP)、召回率(Multi-Intention Recall, MIR)。假设有|D|个多意图样本(xi,Yi),0≤i≤|D|。Zi=H(xi)表示多意图分类器对待测样本集的预测结果集合,则具体计算方法如下:
(13)
(14)
(15)
3.3 关键词提取
根据TF-IDF算法提取的每一类的关键词如表4所示。从表4结果可以看出,提取的关键词都贴近各自的类别,说明该算法的效果好,准确率高。

表4 关键词提取结果
3.4 单意图分类实验
在单意图分类实验中,把改进的CNN模型与文献[2]的textCNN模型和文献[7]的fasttext模型进行对比,分别对比了3种模型对实验数据中的10个类别的分类效果,实验结果如图6所示。
从图6(a)可以看出,fasttext模型的对c1、c3、c5、c6、c7、c10分类的精准率都低于另外两种模型,且在10个类别上的分类效果不稳定,c8和c10的精准率差距达25个百分点。说明fasttext模型对口语意图的分类不具有普遍适应性,即难以用这一种模型适应有多种意图且特征隐藏又复杂的情况。textCNN模型分类的精准率相对于fasttext模型更稳定,但是整体精准效果低于本文模型。本文模型分类的精准率和稳定性更高,除对c3的效果稍低于textCNN模型以外,其他类别都高于另外两个模型。在对c6的分类结果中,分别高出fasttext模型和textCNN模型11个百分点和3个百分点;在对c10的分类结果中,分别高出fasttext模型和textCNN模型17个百分点和6个百分点。从图6(b)可以看出:fasttext模型的召回率普遍低于另外两个模型;textCNN模型对各个类别的召回率不稳定,高低起伏较大;而本文模型召回率普遍高于前两个模型,且稳定性更高。从图6(c)和图6(d)可以看出,虽然本文模型有极少的类别的分类效果不及另外两个模型,但是总体来看效果最好。综上所述,本文模型对处理随意性大、特征稀疏的句子效果更好。
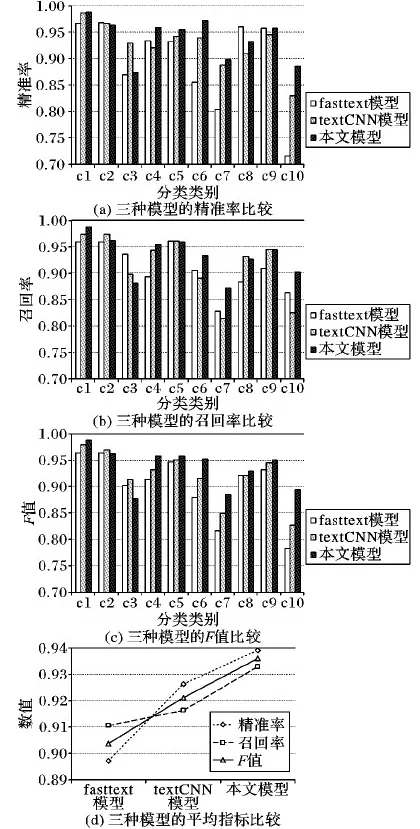
图6 3种模型的评价指标对比
3.5 多意图分类实验
多意图分类实验分别从客服平台中整理了2 000条含2个意图的句子和2 000条含3个意图的句子,随机打乱顺序后利用训练好的模型进行实验。
3.5.1 距离阈值对意图个数识别的准确率的影响
图7展现了不同的距离阈值对意图个数识别的影响。由图7可以看出,阈值在0.855之前是上升趋势,而之后呈下降趋势,说明阈值过大会导致识别的意图个数为0,从而降低准确率;过小则会增加意图的个数,同样降低准确率。最后选取0.855进行下面的实验。
3.5.2 多意图识别部分实验结果
多意图识别的部分实验结果如表5所示,实验随机对含有1~3个意图的句子进行识别。S5是含有否定情感的句子,涉及3个意图,但实际只有2个意图。
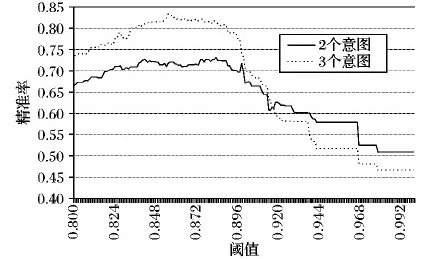
图7 距离阈值与意图个数识别准确率的关系
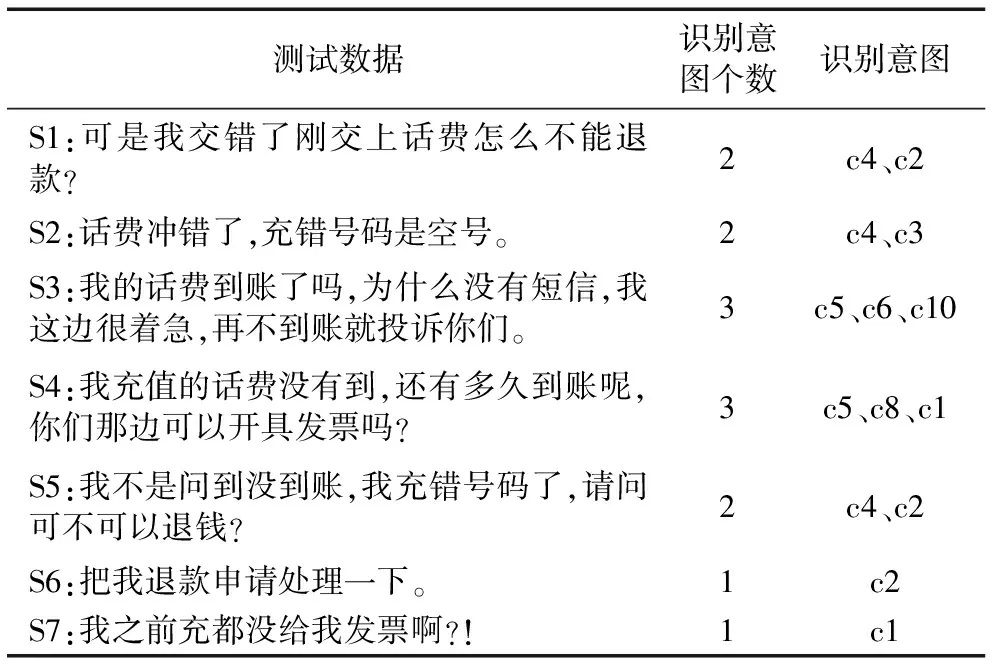
Tab. 5 Partial experimental results of multi-intention recognition
3.5.3 多意图识别模型对比实验
根据前面距离阈值与意图个数识别的关系,选择效果最好的0.855作为距离阈值进行多意图识别实验,实验结果分别取模型迭代1~15次的结果。将本文模型与文献[16]的ML-KNN模型和文献[23]的CNN特征空间模型对比,结果如图8所示。
从图8(a)可知,三个模型的MIA值在多次迭代后都趋于平稳上升趋势,但本文模型在整体迭代过程中分别比文献[23]模型和文献[16]模型平均高出10个百分点和20个百分点。从图8(b)可知本文模型对多意图识别的MIP值最高,分别比文献[23]模型和文献[16]模型平均高出25个百分点和31个百分点。从图8(c)可知3个模型的召回率非平稳变化,在迭代过程中均有抖动,其中文献[16]模型抖动更剧烈。综合3个指标来看,本文模型比另外两个模型效果更好。
4 结语
为解决多意图识别中发现意图、抽取意图和判别意图类型这几个问题,本文提出了结合句法特征和CNN的多意图识别模型,其中利用了依存句法分析、TF-IDF、CNN等技术来解决多意图识别问题。在10个类别的单意图分类和多意图识别实验中,本文模型相比其他模型都取得了较好的效果,证明了其稳定性和有效性。
由于中文的复杂性,本文依赖于句法分析的结果;此外,仅将用户意图的情感粗粒度地分成两个极性——否定和非否定,但实际上用户表达意图的情感更加细粒度。在今后的工作中,将对这两个问题开展进一步的研究。
