
基于进化算法的船舶避碰轨迹建模
2018-09-04 11:11刘超
西安文理学院学报(自然科学版) 2018年4期
刘 超
(安徽交通职业技术学院 航海系,合肥 230001)
目前,许多国内外研究学者对船舶自动舵与自动避碰算法展开了深入的研究.文献[1]将航迹遵循、航向调控和船舶避碰定义为航行自动控制领域内的3个重要组成部分.航迹遵循和航向调控的难题已基本得到解决.船舶避碰一直是船舶航行领域研究的热点,因为船舶发生意外碰撞导致船毁的事件频频发生.文献[2]将遗传算法应用到船舶航路规划以实现安全避碰,但对航海《规则》和船员的技术水平没有考虑周全,造成在设计最优航海路线时经常会违反避碰规则和航海最基本的规定条文;文献[3]将群体智能理论的算法引入到船舶避碰中,此算法具有运算简单、依赖参数小、易于操作等优点,但该算法比较容易受局部极值点的影响、避碰精度较差;文献[4]提出了一种模糊神经网络推理方法,在对船舶避碰最佳路径运算时,可迅速规划出一条最佳路径,但在外界干扰的不利情况下,精确度将会下降.
本文提出了一种基于进化算法的船舶避碰轨迹建模方法,对船舶避碰轨迹模型进行深入分析,通过引入进化算法,将本船和干扰船的航向、航速、位置信息等主要输入参数,规划出避碰路径,完成了该目标下的船舶避碰算法设计.
1 船舶轨迹数据的重要进化算法
1.1 进化算法
本算法主要使用了Map/Reduce编程算法进行的,船舶的停留时间和情况联系很密切,船舶一般在晚上停留,在白天行驶.为了获得数据,需要给船舶提供重要的时间范围[begin,end],这种算法Map和Reduce的函数程序如下:

map(key,value)value主要是指船舶号、船舶ID和行驶时间3个字段的字符串1.从value中可以得到phoneID,baseID,timeStamp这3个属性;2.{if(timeStamp>=begin‖timeStamp<=end){3.output(phoneID,

reduce(key,values)‖key为船舶号,ualues为船舶的所有夜间行驶记录1.regionList=null;2.values记录要通过时间开展记录和排序工作,然后要给定范围的轨迹数据进行分析;3.每个轨迹和船舶之间进行联系,调用获得一种新的模块,即状态序列;4.开展对深层的状态模块进行调用,获得正确的调用效果;5.做好轨迹数据的处理工作,对相关的状态根据区域进行分组.;6.分析各个区域,如果区域g的状态数高于阀值freq则此区域处于重要的位置;7.要对regionList调用相关的聚类模块,找到船舶的重要位置以及有效时间.
Map函数的主要功能:第一步是让船舶可以将轨迹点输送给Reduce函数;第二步是记录船舶的轨迹;第三步是要对调用状态的算法进行计算;第四步主要是对调用状态的模块要删除数据的状态;第五步是要对停留次数很少的区域,由于这些位置的船舶形成的状态时间不短,但是因为时间不够长和频率不够高,所以需要删除位置的对应状态;第六步是要对找到的区域使用聚类算法,然后从获得的结果中得出有效时间和位置.
1.2 聚类分析模块
聚类分析模块通过对出现的区域要进行搜索,找到重要的区域位置.由于船舶的位置不同,本文通过聚类方法DBSCAN对聚类结果进行分析,找出重要位置和有效的时间.
聚类分析算法:
输入:状态列表regionList;
输出:重要位置和有效的位置时间.
1)让regionList区域中心点作为输入情况,通过DBSCAN算法做好点的聚类;
2)聚类之后可以得到很多簇,而且簇和簇之间的对应状态可能会出现重合,如果出现重合,则需要慢慢地删除船舶的行驶次数比较少的簇;
3)要不断地分析每个簇,然后才能找到船舶的重要位置;
4)要对位置的有效范围进行分析.
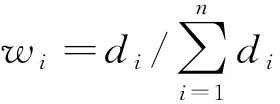
1.3 夜间行驶船舶的位置修正策略
前述算法能够较准确地获得船舶的重要位置,但是会出现夜间行驶而白天休息的船舶,所以本文通过对船舶行驶的日志进行分析,这种船舶工作时候的船舶频率比一般的船舶频率要高,而且在船舶停留的时候,船舶的频率很低,如果能够分析船舶的行驶频率就可以推断船舶的时间段,然后得出船舶的行驶时间段.
使用如下模型来分析时间因素对船舶所处状态的影响:
当前船舶的位置意味着船舶处于“工作”状态并且表示船舶的状态.“时间”处的位置,通过文中描述的算法计算的船舶与工作位置之间的距离以及和工作场所平均值之间的距离的协方差矩阵相同,最终使用以下形式来确定船舶在某个时间点的状态:
在l(x)≥1时,证明船舶在该时间点处于“在家”状态;否则,船舶处于“工作”状态.
2 实验结果及分析
2.1 实验数据集
本文获得的数据来源主要是上海航海局提供的船舶数据,这个数据源有1 342艘船舶,包括了2014年8月15日到2015年3月11日的期间船舶上网的船舶记录数据以及位置信息,数据空间的总量为1.6 TB,而且随机的对98艘船舶的数据进行了算法的准确性分析,表1中对船舶的使用年数分布情况进行了分析,表2分析了工作分布状况,8.1%的船舶是报废的船舶.

表1 船舶使用年数分布

表2 船舶的航行地点数目分布
2.2 算法的准确性和精度评估
算法的准确性评估主要是使用准确率(Precision)、召回率(Recall)、值(value)进行分析,精度使用平均误差(mean_error),如果算法获得的与未知船舶距离小于2 000 m,则知船舶的分布密度不平衡,而且信号会出现跳变的情况,2 000 m的值是比较合理的,我们认为获得了一个重要的信息位置,而找到的重要位置个数是P,实际的重要位置个数为R,找到正确的位置个数是Q,于是有Precision=Q/P,Recall=Q/R,F1-measure=2×PR(P+R).假设实际重要位置为l,算法找出的位置为f,则
其中,ed一般是l与f两个位置之间的欧式距离.
表3对FQM和AXM算法优化之后的性能进行了分析与介绍,一般算法网格长度以及船舶的半径为500 m,在工作地和夜间工作的船舶变换位置后,将这两种算法对其轨迹进行修正,可找出船舶的重要位置(P)数量在不断的缩小而且找到的正确位置数量(Q)也在增加,实际的位置数量不会发生改变,准确率和召回率也在不断提升,最后会导致F1不断增加,由于船舶的位置在相邻的住宅中得到了修改,所以位置一般可以反映出实际状况,而且误差也在不断下降.通过表3可以知道AXM算法一般精确度要高于FQM算法.
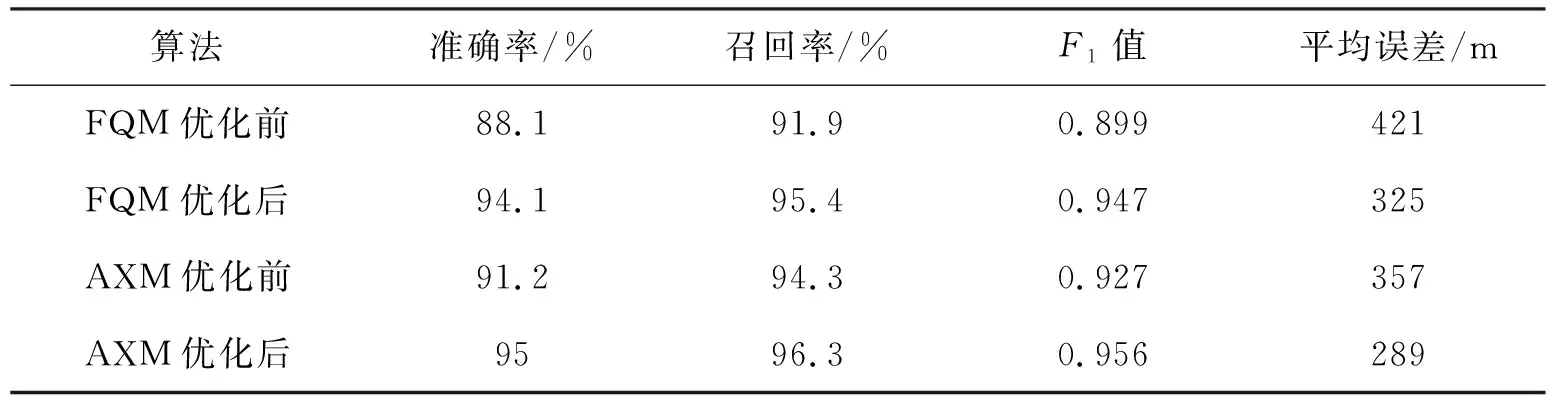
表3 优化措施的影响
表4是前述的两种算法以及文献[7]的算法在数据中的准确情况,船舶的覆盖范围一般在500 m.通过表4可知FQM与AXM两种算法在修正之后得到的实验结果一般比文献[5]与文献[6]要高,文献[7]算法和文中的算法性能差距不大,而且精度也不会超过本文算法,文献[6]的算法性能不好,主要是因为算法需要进行船舶的聚类操作,深刻地影响船舶的重要位置.
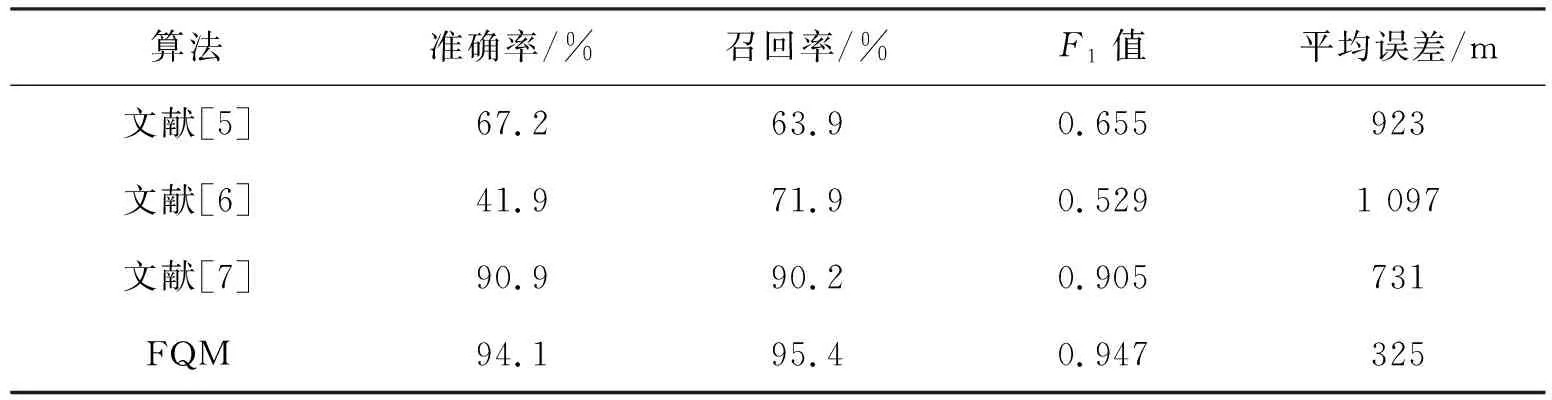
表4 算法性能比较
2.3 算法运行性能评估
为了更好地测量网格尺寸对FQM时间性能的重要作用,对许多数据开展了不同的计算机性能测试,获得结果如图1所示.根据图1可知,网格数据越小,则算法的使用时间将会延长,而且FQM算法的线性加速性也更好,在不同船舶的覆盖也会有不同的算法时间性.根据图2可知算法的半径越小那么效率就会增强,这和FQM算法获得的结果是不一样的.一般船舶的覆盖面积增加,那么船舶的数量也会增加,出现的状态也会增加,导致了聚类的输入数量也不断地增加,也会增加算法运行的时间,而FQM算法的网格边长如果增加,网格的数量也会不断减少,运行的时间也会不断地缩短.
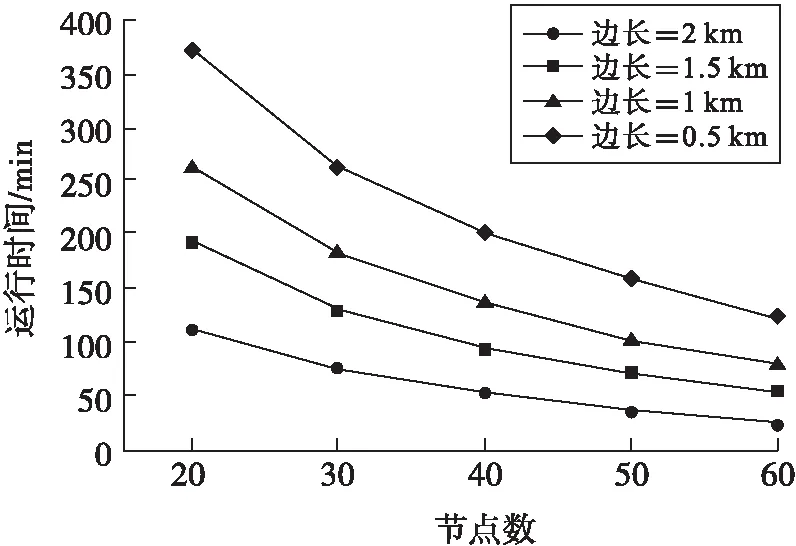
图1 不同网格粒度下的时间性能
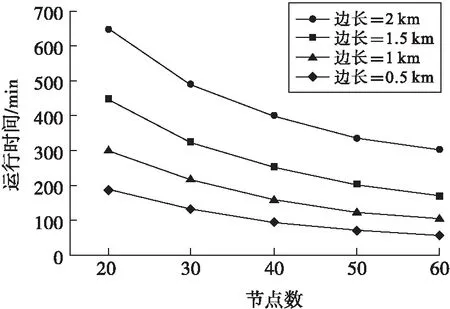
图2 不同半径下的时间性能
3 结语
本文提出了一种基于进化算法的船舶避碰轨迹建模方法.通过船舶的活动记录找到重要的区域,然后对区域开展聚类分析,通过聚类获得的结果对船舶的具体位置进行定位.选取安全避让、路径最短及准备复航为目标,采用进化算法对船舶避碰轨迹问题的系统运动方程进行求解,最终规划出避碰路径.通过实验结果可知:该算法可以有效避开其他船舶的干扰,且航迹最佳,对船舶自动避碰的研究提供了一定的理论基础.
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
数学年刊A辑(中文版)(2019年3期)2019-10-08
作文新天地(初中版)(2019年6期)2019-08-15
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2017年6期)2017-11-23
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2016年10期)2016-06-05
