
融合双重BP神经网络组合模型的Python解析计算机网络上传数据算法
2018-09-04 11:11施艳昭
西安文理学院学报(自然科学版) 2018年4期
施艳昭
(安徽电子信息职业技术学院 经济管理系,安徽 蚌埠 233000)
近年来,社会各界对于BP神经网络组合模型十分关注,对此开展了很多研究和分析[1].为了能够更好地挖掘与分析BP神经网络组合模型,对于解析计算机网络上传数据算法有了更高的要求[2].针对有限空间的环境下,结合分治思想构建了STREAM算法.这种算法并未对数据变化进行充分的反映[3].构建的CLUSTREAM算法可以利用BP神经网络组合模型,在计算机网络上传数据划分为两个阶段:第一个阶段是微计算机网络上传数据,第二阶段为自适应宏计算机网络上传数据,以实现计算机网络上传数据[4].针对BP神经网络组合模型的双重特征,提出了可以通过投影计算机网络上传数据实现有效的解决[5].在上述几种算法中,其依据的根本思想都是k-means计算机网络上传数据思想,这种思想的主要不足是无法实现对任意形式分布的计算机网络上传数据[6].
本文提出一种融合双重BP神经网络组合模型的Python解析计算机网络上传数据算法.整个算法的主要构成部分为:在线网格单元数据统计部分和自适应聚类演化部分.将数据空间进行网络化处理,随后对于在线部分对应的网格单元信息可通过近似技术来进行合理的统计与分析.而且,能够依据改进之后的金字塔时间结构将潜在密集网格单元进行存储,采取的是快照形式.进入到Python解析阶段,则是利用深度优先搜索方式来实施计算机网络上传数据,而且借助实验对算法可行性进行了有效的分析.
1 Python解析计算机网络上传数据算法
以A={A1,A2,…,Ak}代表欧氏空间下对应的属性集合,可将其k维数据空间表示为S=A1×A2×…×Ak,那么此时在某时刻t,在S上的BP神经网络组合即可表示为X=
定义1 给定一个BP神经网络组合模型X上的时间段[t-h,t],称density(u)=count(u)/(|N|)为单元u的密度.其中:|N|为BP神经网络组合总量,count(u)代表的则是在单元u中具有的数据点个数.
定义2 假定[t-h,t]表示的是在X上的某个时间段,其密度阈值为τ,ε表示其误差因子,假如满足density(u)≥τ-ε,那么可以证明此时该单元u为密集的;若density(u)>ε,则网格单元u是潜在密集的;若density(u)≤ε,则网格单元u是非密集的.
假如从开始至今所经过的总时间表示为Tc,那么此时在第0层具有的最小时间粒度则可表示为Tmin.如下所述即为改进金字塔的时间结构定义:①其最大层数表示为logα(Tc/Tmin),α一般的取值为2,4,8;②如果满足条件((Tc/Tmin)modαi)=0and((Tc/Tmin)modαi+1)≠0,那此时将取i为时刻Tc时,对应的存储快照层次;③在每层所可存储的快照仅为最近的β个,其中β取值为大于α的正整数;④Tminαi表示的则是第i层对应的时间跨度.
对比未改进之前的金字塔时间结构,将其进行改进之后,对于参数存储快照是可以结合用户的精度需求来进行设置的,包括Tmin等参数,而且使得快照是不会出现冗余问题的,也不用进行删除处理.
性质1 在改进后的金字塔时间结构下,假如将当前时间点以Tc表示,用户指定时间跨度则以h表示,那么要求在Ts时刻,存在快照满足Tc-Ts≤2h.

依据改进金字塔结构,能够得到在第r个时刻产生的时间序列可表示为tr,t0代表的则是起始时刻点,那么X=Nt1∪Nt2∪…∪Nti∪…,表示的是BP神经网络组合模型,其中:Nti为从时刻ti-1到ti的BP神经网络分段.
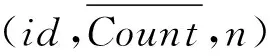
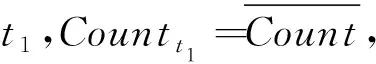
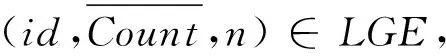
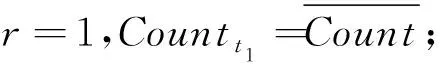
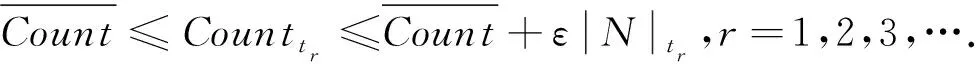

因此,在对LGE进行删除之前,对应的非密集单元具有的误差水平应当能够控制在ε以下,而且不会由于删除而使得密集单元输出的正确性受到影响.因此,当ε为给定的前提下,要求对潜在密集网格单元进行存储,以此来实现对空间复杂度的有效降低.
2 实验与结果分析
为了更好地验证本文算法的性能,对文中计算机网络上传数据精度进行了界定.如图1、图2所示,分别表示的是在真实数据集KDD-CUP-99,以及仿真数据集B300kC5D30S6的情况下,CMDBPNN以及CluStream具有的精度水平.由于Python解析计算机网络上传数据算法采用子空间计算机网络上传数据,面对双重数据也能够进行有效的处理,而且对于任意形式分布计算机网络上传数据的效果也是很好的.因此,对比CluStream,本文算法具有更好的精度水平,相关参数设置为τ=0.002,ε=0.05τ,h=10,l=5.
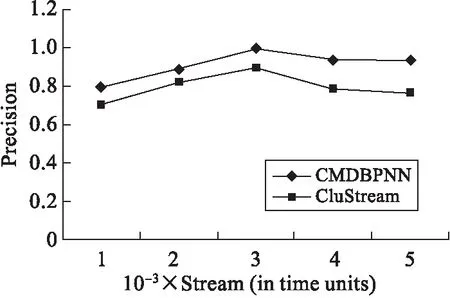
图1 基于KDD-CUP-99的精度比较(数据流100组/秒)
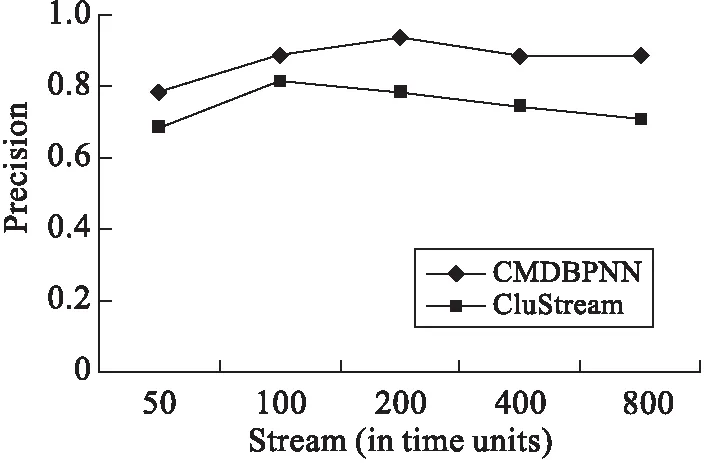
图2 基于仿真数据集的精度比较(数据流500组/秒)
利用真实数据集KDD-CUP-99,对算法具有的执行效率进行分析,将CMDBPNN算法和CluStream展开对比,而且要求进行周期性的快照存贮,进行实验时,则以快照存储于内存中.结合图3,尽管CMDBPNN算法的子空间计算机网络上传数据需要一定的时间耗费,然而,是不需要CluStream进行频繁的聚合、增删等操作的.因此,能够得出,CMDBPNN与CluStream具有基本相同的执行效率,相关参数设置为τ=0.005,ε=0.1τ,h=10,l=5.
实验中还生成了B300kC5D30S6仿真数据集,以对算法内存占用情况进行有效的分析,在内存中主要是对数据结构SET进行存储,而在硬盘中则进行快照存储.结合图4,能够得出,该算法中所需的内存空间并不大,而且如果CMDBPNN呈现出了相对稳定的分布,那么此时对应的内存状态也是比较稳定的.而且如果具有的密度阈值较大,那么此时其中的潜在密集网格也仅有少部分需要维护,因此内存占用较少,在实验中相关参数设置如下:ε=0.05τ,h=10,l=5.
将得到的B300kC5D30S6数据集分别取不同的维数,15,20,25,30,35得到对应的仿真数据集,以分析BP神经网络组合模型空间维度对算法的影响,参数设置为:τ=0.005,ε=0.1τ,h=10,l=6.
为测试CMDBPNN所含计算机网络上传数据维数的伸缩性,生成B300kC5D30S6,取其在4,5,6,7和8维数下的仿真数据集,并且分析τ=0.005,ε=0.1τ,h=10的情况下,当维数为4,5时,l=4,6,7;当维数为8时l=6的情况,结合图3及图4,能够得出不管是空间维数还是计算机网络上传数据维数都具有较好的伸缩性.
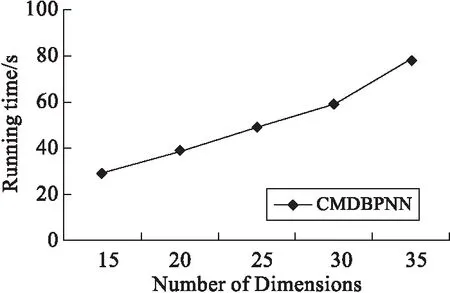
图3 对数据空间维数的伸缩性

图4 对所含计算机网络上传数据维数的伸缩性
3 结论
针对计算机网络上传数据问题,提出了融合双重BP神经网络组合模型的Python解析计算机网络上传数据算法.该算法对于双重BP神经网络组合模型的数据上传问题能够有效解决,任何形态分布的计算机网络上传数据都能够实现.而且,对优化之后的金字塔时间结构,对其中潜藏的网格单元来实施有效的存储.最终结果表明:本文算法能够使得计算机网络上传数据具有较高的实现效率.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
计算机系统应用(2022年5期)2022-06-27
天津科技(2022年5期)2022-05-31
数学物理学报(2020年3期)2020-07-27
电子制作(2019年13期)2020-01-14
电子制作(2018年16期)2018-09-26
电子制作(2018年16期)2018-09-26
电子制作(2018年12期)2018-08-01
现代计算机(2017年7期)2017-04-22
电脑爱好者(2015年4期)2015-09-10
