
推荐算法在移动订餐系统中的应用研究
2018-09-13 07:40刘婷
无线互联科技 2018年11期
刘婷


摘要:随着移动端设备的快速发展,手机应用呈爆炸式增长,如何在众多饮食中将用户喜爱的餐饮准确推荐给用户显得尤为重要。针对传统推荐算法中存在的数据稀疏性问题、冷启动问题以及用户评分尺度不同导致的近邻用户寻找不准确的问题,文章提出基于内容的推荐与基于协同过滤的综合推荐算法,摆脱了对显式项目评分的依赖,弱化了数据稀疏问题,可以即时地、精准地为用户推荐符合其喜好的产品。最后能够在移动订餐系统实现商家对用户的个性化推荐。
关键词:推荐算法;协同过滤;移动订餐系统
随着移动互联网的发展,手机点餐、微信点餐等手机订餐软件已成为其最新的发展趋势。餐饮行业现有的大多数管理系统落后于用户和管理人员的需要,一种行之有效的方法是将推荐系统应用于餐饮管理,分析用户的历史数据,向用户提供更符合消费者喜好的服务,也能方便消费者使用,具有极大的现实意义和经济效益。
推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西,利用推荐算法从海量数据中挖掘出用户感兴趣的项目(如信息、服务、物品等),并将结果以个性化列表的形式推荐给用户。目前,推荐系统在很多领域得到了成功应用,包括电子商务(如Amazon,eBay,Netflix,阿里巴巴等)、信息检索(如iGoogle,MyYahoo,百度等)、社交网络(Facebook,Twitter,腾讯等)、位置服务(如Foursquare,Yelp,大众点评等)、新闻推送(如Google News,GroupLens,今日头条等)等各个领域。本文对现有的推荐方法进行分析,为移动订餐系统的设计提供参考和启发。
1 传统推荐算法
目前广泛使用的推荐方法主要包括基于内容的推荐方法和协同过滤推荐算法。基于内容的推荐则是根据用户自身选择的物品的内容相似性进行推荐,即推荐给用户与他喜欢的东西相似的东西。基于协同过滤的推荐则是通过分析相似用户的兴趣,根据相似用户的评价来进行推荐。其中,最经典的协同过滤算法是矩阵因子分解,利用用户与项目之间的交互信息为用户产生推荐,协同过滤是目前应用最为广泛的推荐算法,但是在应用中遇到了致命的问题——数据稀疏和冷启动问题。此外,经典的协同过滤方法采用浅层模型无法学习到用户和项目的深层次特征。基于内容的推荐方法利用用户已选择的项目来寻找其他类似属性的项目进行推荐,但是这种方法需要有效的特征提取,传统的浅层模型依赖于人工设计特征,其有效性及可扩展性非常有限,制约了基于内容的推荐方法的性能。
1.1 基于内容的推荐
基于内容的推荐主要根据用户已经选择或者评分的项目,挖掘其他内容上相似的项目作为推荐,基于内容的推荐算法的主要优势在于无冷启动问题,只要用户产生了初始的历史数据,就可以开始进行推荐的计算。而且随着用户的历史记录数据的增加,这种推荐一般也会越来越准确。
1.2 基于协同过滤的推荐
协同过滤算法是一种仅仅基于用户行为数据设计的推荐算法。随着互联网空间的迅猛发展,数据规模的爆炸式增长,协同过滤算法已经成为学术界和工业界的关注热点并得到了广泛应用,形成了众多相关研究成果。为了实现大数据环境下高效、精准的商品推荐,将协同过滤思想与信息检索理论有机融合,提出基于学习排序(Learning To Rank,LTR)的并行协同过滤推荐算法。针对推荐系统中的冷启动问题,提出基于消费者行为的点餐推荐算法,设计出频度统计、关联规则和Markov链3个推荐引擎的加权组合推荐系统。针对传统的基于用户的协同推荐算法存在的数据稀疏以及对用户评分的强依赖问题,提出基于社交信任机制的在线学习协同推荐算法。在传统二部图推荐算法的基础上提出一种针对电商平台快速消费品的图推荐算法。对近几年基于深度学习的推荐系统研究进展进行综述,分析其与传统推荐系统的区别以及优势,并对其主要的研究方向、应用进展等进行概括、比较和分析。
2 混合推荐算法
2.1 核心思想
基于内容的推荐与基于协同过滤的推荐是目前主流的推荐算法。考虑到单一推荐方法都存在各自的不足,通过组合不同的推荐算法进行混合推荐,往往能够产生更好的推荐性能。为了进一步提高推荐算法的推荐质量,针对推荐算法中存在的一些缺陷,比如新用户问题、新项目问题以及数据的稀疏问题,众多学者提出了一些新的方法来对推荐算法进行改进,比如融合争议度特征的协同过滤推荐算法,可以缓解传统算法在稀疏数据情况下相似度计算不准确的问题;基于内存的传播式协同过滤推荐算法,对数据稀疏性问题进行了有益的探索和研究。
然而一些传统的推荐算法以及上述所提出的改进算法都忽略了一个重要的现实问题:这些算法都依赖于用户对项目的评分,而现实中能对项目进行的评分的用户则少之又少,这些用户可认为是死忠用户,大部分用户都不会去评分,用户没有评分则无法推荐,用户较少评分则大幅影响推荐的准确性。其可能造成的结果是死忠用户越来越死忠,而不评分用户的推荐准确度无论算法如何提高都得不到质的飞跃。
针对上述问题,本文提出了一种推荐算法结合了基于内容的推荐与基于协同过滤的混合推荐算法(Contentand Collaborative Filtering Hybrid Recommendation,CCF-HR)。该算法可以根据用户的非评分行为计算出用户的喜好模型,利用这一模型和相似用户可以对产品进行评分预测,摆脱了对显式评分的依赖,弱化了数据稀疏问题。
2.2 推荐算法中的概念
2.2.1 餐饮产品特征
本文中餐饮产品有价格特征和产品分类特征两个特征。价格特征有8个特征值,分别是8个价格区间,分别用f1~f8表示。产品分类特征有5个特征值,中式快餐、西式快餐、饮品、甜品、小吃,分别用f9~f13表示。
2.2.2 用戶对餐饮产品特征值的评分
根据用户的购买记录和收藏列表,计算其对产品特征值的喜爱程度,这一喜爱程度可视为用户对该特征值的评分。
评分的定义如下:对用户的购买记录和收藏列表进行统计,该用户对特征值fi的评分si为他购买的产品中含特征值fi的数量与某一特征特征值总数(即产品的总数)的比值。即:
其中mi为用户购买的产品中特征值fi出现的次数,
。如果用户的收藏表的一个产品该用户从未购买过,说明该用户想尝试一下该产品。在该算法中将提高该产品所具有的特征值的评分。
2.2.3 餐饮产品特征的偏爱度
在本文中,产品的两个特征的特征值取值都可视为离散型随机变量,随机变量的标准差代表着特征值的离散程度,标准差越小,意味着用户的购买倾向越趋近于某一特征值,用户在购买时就越重视该特征。标准差与平均数的比值称为变异系数,变异系数可以消除单位和(或)平均数不同对两个资料变异程度比较的影响。所以两个特征偏爱度之比是两个特征变异系数的反比。
设用户所购买过的产品的价格特征取值是离散型随机变量X(X的取值是产品的价格),设其标准差为σ1,其均值为E(X)。设用户所购买过的产品的分类特征值是离散型随机变量的取值是1,2, 3, 4, 5,分别代表5个分类),设其标准差为σ2,其均值为E(Y)。X的变异系数为
,
Y的变异系数为
。则产品价格特征和分类特征对于用户偏爱度分别为:
其中 w1+w2=l。
2.2.4 用户特征向量
用户特征向量是一个13维的向量V=(s1, s2, s3, s4, s5, s6, s7, s8, s9, s10, s11, s12, s13,)其中的si是用户对特征值fi的评分。该向量表示用户的喜好。
2.2.5 用户之间的相似度
用户集U={u1,u2,…,un},特征值F={f1,f2,…,fn},在本系统中目前m=13,即总共有13个特征值,则用户对各特征值的评分如矩阵R(见表1)。
利用余弦相似性计算用户之间的相似度。每个特征值的所有评分记录可以视为m维用户空间特征向量,用户i与用户j的特征向量分别为i和j,其相似度记为r(i,j)。则:
其中分子为两个用户特征向量的内积,分母为两个用户特征向量模的乘积。在本系统中,如果0.618≤r(i,j)<1(向量中的值都是正数,所以相似度取值范围是[0,1],0.618则是该范围的黄金分割点),用户j才能被视为用户/的相似用户。2.2.6 用户对餐饮产品的评分
当计算出当前用户的相似用户后,会对相似用户所购买的产品进行评分。评分公式如下:
其中,Ti,j,k是当前用户ui对其相似用户uj购买的产品pk的评分,s(i,j)是用户ui与用户uj之间的相似度,w1,w2是用户ui的产品特征偏爱度,sa,sb是当前用户ui对产品pk的两个特征所取特征值的评分。
2.2.7 推荐产品候选集合
在计算用户相似度时,一边计算用户相似度,一边按相似度从大到小进行排序。之后,对相似用户所购买过的产品进行评分的同时按评分从大到小进行排序,加入推荐产品候选集合。
2.28 推荐产品集合
在本文中,为用户所推荐的产品的数目是不定的,是个参数〃。用户的相似用户数目是不定的,用户所购买过的产品与相似用户所购买过的产品也是充满变数的,到底推荐哪些产品是一个很复杂的问题。在该算法中将采用集合运算来获取最终的推荐产品集合。
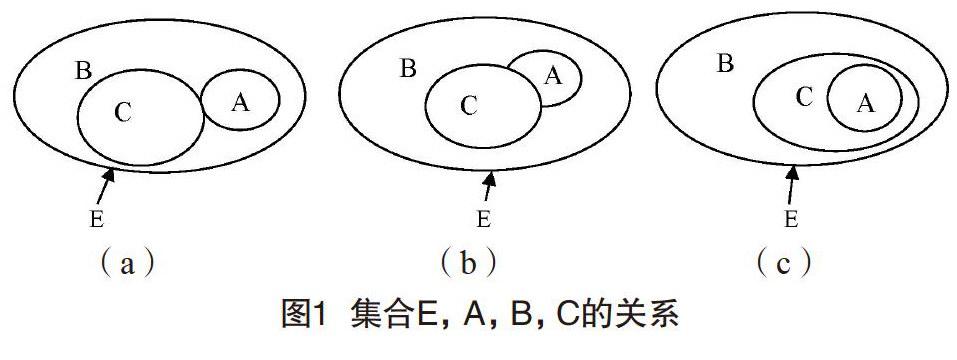
设系统中的所用产品为全集集合E,推荐产品候选集合为A,用户未购买过的产品集合为集合B,用户购买过的产品集合为集合C。集合E,A,B,C之间将会有3种关系,如图1所示。
图1(a)中A,B,C 3个集合互相是没有相交部分的。图1(b)中集合A、C有相交部分,即推荐产品候选集合中的部分产品已经购买过。图1(c)中集合A包含于C,即推荐产品候选集合中的产品已经全部购买过。
在本文的推荐算法中,算法将优先推荐优先级高的产品,当高优先级的产品的数量加上已经推荐的产品数量小于n(推荐的产品的数目)时,将推荐下一个优先级的产品,直到所推荐的产品数量达到n。设3个优先级别的集合PA,PB,PC,最终的推荐产品集合为PF。其中PA的优先级最高,为推荐产品候选集合中没有购买过的产品。PC的优先级最低,为已购买过的产品。PB的优先级介于两者之间,为未购买过的产品。3个集合通过以下集合运算获得。
2.3 算法的详细流程
算法的详细流程如图2所示。
3 结语
本文提出了一种推荐算法结合了基于内容的推荐与基于协同过滤的混合推荐算法。该算法可以根据用户的非评分行为计算出用户的喜好模型,利用这一模型和相似用户可以对产品进行评分预测,摆脱了对显式评分的依赖,弱化了数据稀疏问题,为移动订餐系统的设计提供参考和启发。在今后的工作中可以进一步研究用户的背景信息(如性别、年龄、职业等)对推荐的影响,进一步改进算法,充分发挥推荐算法在移動订餐中的作用。
