
两阶段RDD方法无回答的影响及其改进
2018-09-21 05:42李锋
统计与决策 2018年16期
李 锋
(首都经济贸易大学 统计学院,北京 100070)
0 引言
调查的最终目的是获取真实的数据。为了掌握社会经济方面的信息,政府及其他部门组织的以居民及住户为调查对象的调查日渐增多,比如消费者信心指数调查等,但是一直没有建立起完整的居民及住户抽样框。常用的住户抽样框主要有两种,一种是以户籍为标准的户口抽样框,户口抽样框在人户分离问题严重的背景下失去现实基础,抽样框误差较为严重;另一种是以住宅为标准的抽样框,具体又可以采用入户派员面访、(固定)电话调查和邮寄调查,此外,还有以手机、邮箱等为抽样框的居民调查框。
1 Mitofsky-Waksberg两阶段RDD方法
1.1 计算机辅助调查的一般抽样设计:计算机随机拨号
电话访问与入户访问是仅有的两种可以实施住户随机抽样的方法。随着电话普及率不断增高,而且也迫于大都市入户访问成功率越来越低的现状,面访已经被计算机辅助电话调查CATI(Computer Assisted Telephone Interviewing System)所取代,传统的固定电话簿技术已经被计算机随机拨号RDD(random digit dialing)技术所取代。将区号和电话号码的前四位(八位号码)或者前三位(七位号码)的组合号段作为初级单元,将电话号码的后四位作为次级单元,每个初级单元包含的次级单元均相等为10000。传统的计算机随机拨号设计分两步:首先随机抽取一定数量的初级单元,在抽中的号段中再随机抽取后四位号码得到完整的电话号码,最终,在每个抽中的号段中抽取一定数量的住户为样本。这种拨号方法实际上是每阶段抽样都是简单随机抽样的二阶抽样,估计量及方差的计算都有现成的公式,但是这种方法有两个问题,一是样本中的住户太少,有很多空号和单位电话;二是无回答在各个号段并不是等比例分布,因此,抽样过程较为复杂,估计还可能有偏。
1.2 随机拨号的改进
Mitofsky和Waksberg提出了一种方法对计算机随机拨号进行改进,称为Mitofsky-Waksberg两阶段抽样法,设计分两步:第一步首先随机抽取初级单元,在抽中的号段中再随机抽取一个后四位号码得到一个(或多个)电话号码,如果这个号码是住宅号码,则定为一类初级单元PSU,如果这个号码不是住宅号码,则放弃这个初级单元(号段)。第二步在每个一类初级单元(号段)中,再抽取k-1个号码。最终,在每个一类号段中抽取相同数量的住户为样本。这种拨号方法实际上是第一阶为PPS抽样(与初级单元规模成比例的不等概率抽样),第二阶为抽取等量单元的简单随机抽样的二阶抽样设计,设总体初级单元(号段)有N个,第i个单元中住户数为Mi,总的住户数为M0,从N个单元中抽取n个单元进行调查,在每个抽中的初级单元共抽取m个单元,则总体中第j基本单元(住户)入样概率均为P(ij)=P(j|i)P(i)=(m/Mi)(Mi/M0)=m/M0。
因此,Mitofsky-Waksberg两阶段RDD方法理论上估计量及方差都是自加权的,有现成的公式,也可以根据一家多部电话等进行调整。这种方法可以大大提高抽样单元中的住户的数量。
2 计算机辅助调查实施中存在的无回答率问题
2.1 无回答率较高,且不同初级抽样单元内无回答率不同,不处理偏倚较大
调查过程中,合格受访者因各种因素无法接受访问,即为无回答,对于任何一种访问方式,当其目标被访者的无回答率超过40%①以上时,其随机样本的代表性就存在问题。而由于电话诈骗较为猖獗,当前我国计算机随机拨号访问的无回答率常常能达到80%左右。直接应用全部样本数据,对无回答不作任何处理,当成自加权样本实施推断,估计量只能代表回答者的情况,估计量很可能出现较大偏倚。
令Yij为总体第i个初级单元中的第j个次级单元的指标值,i=1,2,…,N;j=1,2,…,Mi。yij为样本中第i个初级单元中第 j个次级单元的指标值,i=1,2,…,n;j=1,2,…,mi。是总体(样本)初级单元的指标和,是总体(样本)第i个初级单元指标按次级单元的平均数总体(样本)按次级单元的平均数;在上述自加权的设计下,假定所有抽中的单元均回答,第i个初级单元内调查单元mi等于回答单元m,则总体总量的估计量:

如果考虑无回答率,假设第i个初级单元中回答率为r1i,无回答率为r0i,则被调查单元回答单元的均值为回答单元的均值为总体总量的估计量:

如果仍然按自加权设计估计,偏差为:

可见,估计的偏倚既受到初级单元的回答率影响,也受到回答者与回答者之间的差异影响,同时差异的结构也影响偏倚的大小。本文简单地忽略回答者和无回答者的差异,同时也忽略了初级单元回答率的高低和差异。
2.2 采用初级单元内加权方法处理总的估计量不再是自加权的,方差估计很困难
如果有大量的无回答,就需要调整无回答,常规的处理方法是对每个初级单元内的无回答群体实施调查,然后加权得到每个初级单元内的估计量,即用二重抽样法进行估计。由于无回答在各个号段之间并不是等比例分布,加权之后各个号段(初级单元)中的调查单元不是相同的,这样Mitofsky-Waksberg两阶段RDD方法得到的估计量实际上不再是自加权的。由于第一阶抽样是PPS抽样,第二阶是二重分层抽样,抽样过程较为复杂,方差估计需要在每一个初级单元内部根据二重分层抽样的方法计算方差,再计算二阶抽样的方差估计,十分复杂。
3 无回答误差的抽样设计改进
3.1 随机组法
随机组法就是从总体中抽取k个(k≥2)的样本(通常每个样本是一样的抽样设计),对每一个样本分别构造所感兴趣的总体参数θ(如总体均值)的一个估计量,α=1,2,…,k。如果这些估计量互不相关而且有共同的数学期望μ,这样总体参数θ的全样本估计量θ定义为:

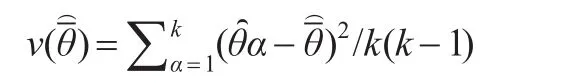
如果数学期望μ=总体参数θ,则估计量是无偏估计。
3.2 基于随机组法的抽样设计
实际操作中,通常是将全部样本划分成R组,每一组都遵循同样的设计,这种伪随机在总体单元远大于样本量时,可以视为独立复制。如果直接在初级单元内设计随机组,容易破坏群结构,为了不破坏群结构,并且能够通过尽量多地保留原始数据的信息,本文建议采取分层抽样的方式随机拨号基础上的随机组法。具体方式如下:
一是将全部号段分层,如将号段分为直辖市城市住户、直辖市农村住户、东部住户、中部住户、西部住户等。
二是在每层内实施Mitofsky-Waksberg两阶段抽样法,在每个层内抽取k个一类初级单元PSU(号段),在每个号段内抽取到同等数量的回答者。
三是对每个号段内的无回答者实施简单随机抽样,在每个号段内抽取到同等数量的无回答者。
四是在各个层内采取随机组号分配的方式,构造k个随机组。在第一层中,第一个号段分派一个1到k之间的随机数,例如分派数为k-1,就分到第k-1个随机组,则第二个号段分配数为k,第三个号段分配数为1,以此类推。
五是用随机组法得到整体的估计量及方差,也可以得到每一层的估计量。
通过这种方法能够构造出抽样设计完全相同的k个随机组,得到的总体参数(均值、总量等)的估计量以及估计量方差的无偏估计量。
两阶段RDD方法电话调查模拟数据随机组构造如表1所示。

表1 两阶段RDD方法电话调查模拟数据随机组构造
4 结束语
计算机辅助电话调查已经成为我国对住户实施抽样调查的主要方式,Mitofsky-Waksberg两阶段抽样法虽然提高了拨到住户的比例,但在无回答广泛存在的情形下,估计量不再是自加权的,而且可能有偏。本文认为应该对无回答者实施抽样,加权得到每一个初级单元的估计量,通过结合分层技术,可以得到随机组下的无偏估计量,并且能够得到方差估计。此外,我国移动电话普及率逐年上升,在解决随机拨号电话调查无回答的问题之后,应该大力发展移动电话调查。
猜你喜欢
西南师范大学学报(自然科学版)(2022年7期)2022-07-09
哈尔滨商业大学学报(自然科学版)(2021年6期)2021-12-20
温州大学学报(自然科学版)(2021年1期)2021-06-08
中国诗歌(2019年6期)2019-11-15
计算机与网络(2019年3期)2019-09-10
发明与创新·大科技(2017年8期)2017-08-17
现代营销·学苑版(2016年12期)2017-01-23
中国信息技术教育(2016年14期)2016-09-10
美文(2009年12期)2009-07-14
美文(2009年6期)2009-05-13
