
用于边缘设备的AI为设备制造商营造机会
2018-09-26 03:10WernerGoertz
电子产品世界 2018年3期
Werner Goertz
摘要:在持续完善机器学习模型和训练过程中,各种个人设备(如:移动设备、汽车和物联网)发挥着不可或缺的作用。着重阐述了个人设备在优化深度学习架构中发挥的关键作用。
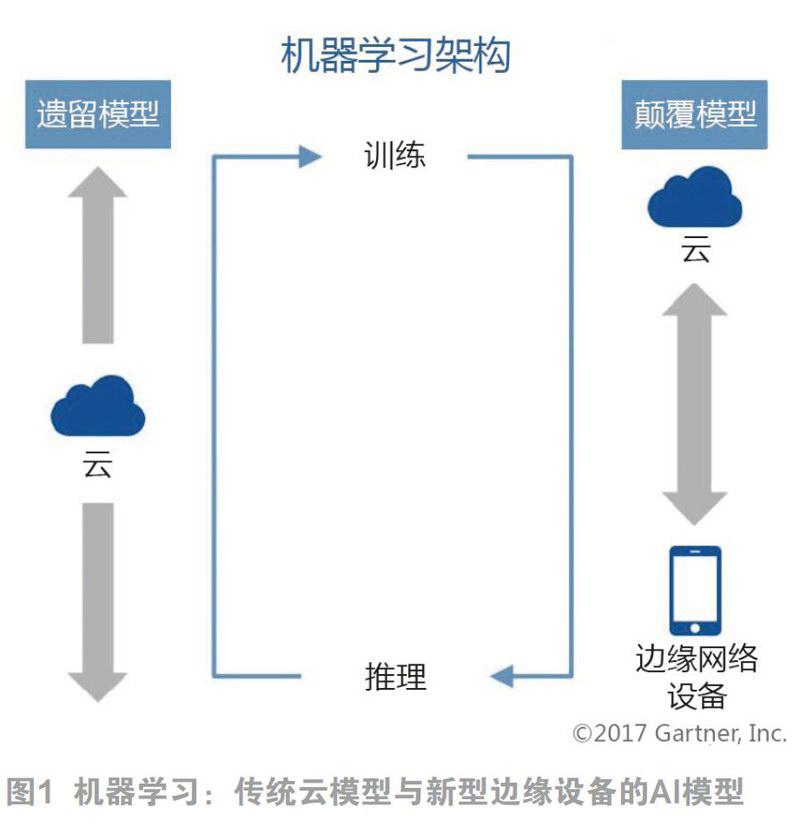
传统的机器学习包括两个功能:训练和推理(运行时间)。训练模型(参见图1)通过对比真实事件(例如,捕捉图像中的对象)实现持续改进和完善。在传统模型中,训练和推理完全在云中运行(图1中左侧的垂直箭头)。然而,这种模式最终会遇到可扩展性问题,如:不可接受的延迟,依赖永远在线的带宽和数据隐私问题等。因此,一种新的机器学习架构正在兴起,处于网络边缘的设备在机器学习中扮演一定角色,尤其是在推理(右侧垂直箭头所示)方面。
对于各种设备制造商而言,这种新的分布式架构是很好的选择。科技产品管理领导者必须了解这一新兴趋势,掌握能够启动设备,将推理放在边缘上或设备中的组件和框架知识。现在,制定路线图成为了必要条件,它将本地Al(人工智能)处理和价值创造考虑到其中。下列设备将受益于新架构结构的开发,并成为设备层面的推理备选项:
●支持虚拟个人助理的扬声器(VPA-enabledspeakers) ;
●家庭网关(home gateways);
●智能手機;
●平板电脑/个人电脑:
●家庭传感器(Home sensors)。
在持续完善机器学习模型和训练过程中,各种个人设备(如:移动设备、汽车和物联网)发挥着不可或缺的作用。
在本文中,我们着重阐了个人设备在优化深度学习架构中发挥的关键作用。
1 Al市场与分布式AI框架相融合
领先的Al框架组合已经成形,并正在支持Al组件的无缝集成。这些框架包括:
●TensorFlow/TensorFlow Lite: TensorFlow是Google的开源工具和软件库,旨在加速机器学习应用的开发过程。2017年5月,TensorFlow Lite在Google I/O上推出。
●Caffe: Caffe是加州大学伯克利分校开发的独立框架。Caffe也是一种开源框架,由全球贡献者网络提供支持。
●MXNet:Nvidia和Amazon是MXNet背后的推动力。Amazon Web Services (AWS)的客户对该开源框架推崇有加。
2 运行中的边缘Al
如今,技术供应商,特别是在智能家居领域的供应商都在面向边缘Al的未来格局设计相关产品,而基于机器学习的智能数据分析就是不错的开端。此类典型产品包括:
●联网家庭中枢和Wi-Fi接入点的制造商Securifi已经将其机器学习功能应用于高端Almond路由器系列,“学习”联网家庭设备的典型行为和流量模式:
●SpeecHmatics正在开发最终可以完全在设备上运行的自然语言处理技术:
●Mojo Networks提供基于Al的工具以检测Wi-Fi或有线网络问题。
3 Al解决方案的开发需要个人设备供应商考虑两个发展阶段
除了确定Al解决方案的使用目的,在评估Al解决方案的部署情况时,技术产品管理领导者必须考虑两个关键的开发阶段,具体如下。
3.1 开发和训练AI模型/神经网络
许多基于Al的项目利用基于数据中心的资源,开发和训练用户与其个人设备互动的模型和神经网络,从而从Al解决方案中获益。利用数据中心资源的原因在于神经网络的初始模型必须经过训练和“提升”,才能承担预期的特定任务,包括语音识别/响应、语音翻译或图像识别。这通常要求模型能够访问大量的“已知”数据和运行模型的连续迭代,来确保提供正确结果。训练神经网络需要高性能的服务器驱动系统,该系统能够实现极高的数据吞吐量,以保证模型的多次迭代在可控时间段内运行。这些系统通常基于高性能x86微处理器,并辅以一系列图形处理器(GPU),来加速神经网络算法的高度并行元素。
在很大程度上,经过训练的神经网络的可靠性取决于训练网络的已知优良数据。这将要求设备供应商的技术产品管理领导者评估目前哪些数据可用,或能够访问哪些数据训练神经网络:在可用数据不足的情况下,可以授权第三方数据集,或获得预训练神经网络模型的访问权限。使用预训练的神经网络可以最大限度地减少对高性能服务器基础架构的投资,而在训练阶段处理大型数据集离不开这些基础架构。
在开发和训练模型或神经网络之后,开发人员通常会优化模型,以便在基于“未知”数据推断新结果,即在供客户使用之时,减少费用和等待时间。
3.2 确定如何有效地为客户部署Al解决方案
用于部署Al解决方案,根据未知数据推断结果的选择有多种:
(1)云端部署
对于许多开发人员而言,这将是很简单的部署方案。开发人员能够利用与开发神经网络相同的系统和技术,这些系统已经成为许多云服务中的“标准”产品。
这种方法面临的挑战是大量原始数据必须传递到云端,以便神经网络做出响应。这需要一个连续的高带宽通信连接到云端,使用具有有线互联网连接的设备,这一切将成为可能(例如智能家居设备和VPA)。然而,当无法保证云端连接或带宽有限时,此方法并不适用(例如蜂窝连接)。
另一个必须考虑的因素是云服务处理输入数据,以及在合理时间内做出响应的能力,这就是所谓的延迟。人们对于在用户心生不满、转而采用其它方法之前的合理系统响应时间内已开展了诸多研究。而且随着Al系统被用于任务关键型/生命关键型决策,延迟将越来越重要(例如自主驾驶系统)。
在很多情况下,应用程序延迟将是数据传输时间与神经网络原始执行时间共同的结果。在任何时候,这两种情况都会受到用户数量的影响。在高峰期,网络带宽或云计算能力可能会限制性能。
(2)个人设备
通过训练神经网络和优化推理模型,运行模型所需的处理资源一般远远少于训练阶段所需的资源。这能够使模型在更简单的设备上运行,如:FPGA、专用神经网络芯片,甚至今天许多个人设备中使用的Arm处理器内核。
在个人设备中部署神经网络模型可以帮助开发人员解决依赖云服务造成的延迟和连接性挑战。
然而,将神经网络模型迂至设备本身也存在挑战。首先,个人设备必须有足够的资源运行神经网络模型和数據存储,保存参考数据,使其能够根据新的未知输入推断答案。
个人设备有各种设计限制。这些限制可能包括外形规格、电池寿命、功能性或大批量可制造性。因此,许多设备都采用定制AP(应用处理器)设计,这些AP将设备的大部分功能集成到单个芯片上。定制AP的典型示例包括苹果公司在其智能手机和平板电脑中使用的A系列处理器,以及用于智能手机的高通Snapdragon AP。专用微控制器也常用于外形尺寸较大的个人设备。所有这些半导体器件都旨在平衡性能要求与延长的电池寿命,即最低的设备功耗。
许多开发AP的半导体供应商正在评估能够运行神经网络的额外功能模块。其中一些模块专用于特定的神经网络功能,例如图像识别。其他模块则提供更多的灵活性,以便开发人员根据自己的需求优化神经网络。
现在,许多IP公司提供可集成到AP设计中的数字信号处理器(DSP)、GPU和FPGA IP模块
所有这些都可以提供运行神经网络模型所需的并行性。
此外,一些公司正在开发专用的AI处理器。但大部分都还没有上市,不过在此期间,这些公司还提出了将AI功能添加到个人设备上的另一个选项。但是,由于这些AI处理器通常基于专有的处理器架构,提供完全集成的软件堆栈可能具有挑战性。因此,应该进行全面的评价,评估收益与替代设计决策对比。
使用标准个人电脑架构的更复杂的个人设备可以选择使用基于周边设备互连高速( PeripHeralComponent Interconnect Express)的GPU或FPGA附加卡(FPGA add-in card)执行神经网络功能。
(3)两者兼具
对于许多应用而言,由于性能、功耗和外形规格因素的限制,完全在个人设备上运行神经网络模型可能并不可行。在这种情况下,最好分离推理操作,在设备和云中的其它设备上进行操作。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
中国信息化周报(2019年18期)2019-06-09
电信科学(2017年6期)2017-07-01
电测与仪表(2015年22期)2015-04-09
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
计算机世界(2009年32期)2009-09-30
电子设计应用(2004年7期)2004-09-02
