
基于python的Web大数据采集和数据分析
2018-11-26 09:32肖乐丛天伟严卫
电脑知识与技术 2018年22期
关键词:大数据
肖乐 丛天伟 严卫
摘要:该设计使用python语言作为开发语言,主要采用了两个框架:Scrapy和Django,用Scrapy来实现数据的采集技术,让数据采集效率更高,错误率低等;用Django来实现web网页展示数据可视化功能,使用户能更加清晰、透明的了解到通过数据分析生活未来发展的趋势,以及解决社会存在的某些问题等等。
关键词:Python;大数据;Scrapy;Django
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)22-0009-03
Abstract: This design mainly adopts two frameworks: Scrapy and Django, using Django to achieve the web page display data visualization function, users can be more clear and transparent to the future through the development trend of life data analysis, and solve some social problems. Using Scrapy to achieve data acquisition technology, data acquisition efficiency is higher, error rate is low, the framework can also extend functions and expand protocols to meet more complex needs.
Key words: Python; Scrapy; Big data; Django
1 背景
随着互联网技术的不断发展,我们所生活的世界正在被数据所淹没,而这些数据经过精心的系统整合所形成大数据,开始展现出其从量变到质变的价值时代[1]。
采集是大数据价值挖掘最重要的一环,其后的分析挖掘都建立在采集的基础上。数据的采集有基于物联网传感器的采集,也有基于网络信息的数据采集。比如在智能交通中,数据的采集有基于GPS的定位信息采集、基于交通摄像头的视频采集,基于交通卡口的图像采集,基于路口的线圈信号采集等[2]。本文是研究互联网上的数据采集,是对各类网络媒介,如搜索引擎、新闻网站、论坛、微博、博客、电商网站等的各种页面信息和用户访问信息进行采集,采集的内容主要有文本信息、URL、访问日志、日期和图片等。之后把采集到的各类数据进行清洗、过滤、去重等各项预处理并分类归纳存储。对这些数据进行智能处理,从中分析和挖掘出有价值的信息[3]。
该设计基于python语言,运用scrapy框架进行对淘宝,京东等网站进行数据采集,达到更快速和高层次的屏幕抓取和web抓取数据,用NumPy进行数据的清理,过滤,子集构造,转换,排序,描述统计等操作,通过matplotlib进行数据可视化分析。运用Django框架把数据图表显示在web页面上[4]。
2 Web大数据采集技术
2.1 Scrapy爬虫设计
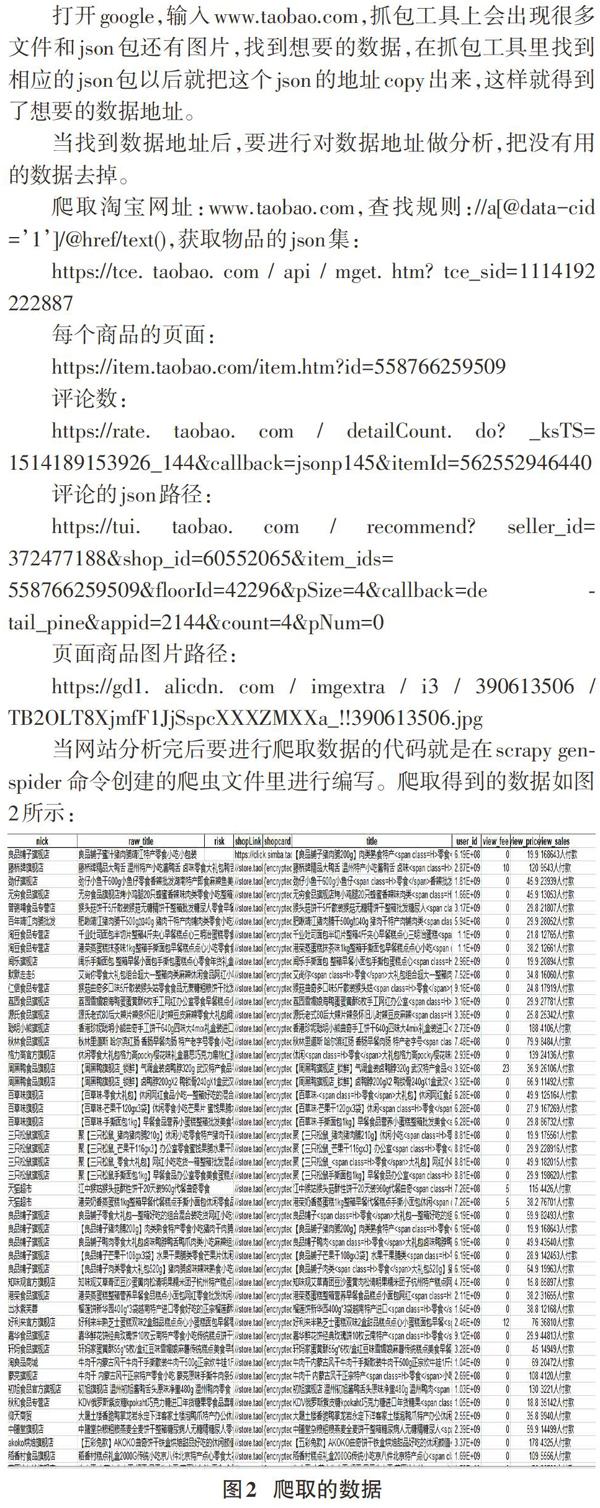
在爬取数据之前首先要对网站进行分析,获取初始的URL。获取的方法可以通过抓包工具对要爬取的内容进行分析, 当找到数据地址后,对数据地址做分析,每获取一个新的URL,先确定这个URL是否有效,把没有用的数据去掉,爬取完后确定下一步的爬取URL,将新的URL放入爬取队列中,如此循环下去,直到满足设定的条件,结束爬取网络数据,流程如图1所示。
打开google,输入www.taobao.com,抓包工具上会出现很多文件和json包还有图片,找到想要的数据,在抓包工具里找到相应的json包以后就把这个json的地址copy出来,这样就得到了想要的数据地址。
当找到数据地址后,要进行对数据地址做分析,把没有用的数据去掉。
2.2 数据的清洗
抓取到数据后,由于数据里有许多“脏数据”,所以要对数据进行缺失值的处理和数据异常值的清洗处理。通过numpy的库里的函数describe()来得出这堆数据里的极大值,平均值,中位值,极小值,方差等数据来分析数据里有哪些缺失值或者是异常值。
抓取到的原始数据,在数据清洗前价格与销量的散点分布情况如图3所示,横坐标代表商品价格,纵坐标代表销售量。发现商品价格0-500元之间有几个商品的销售量在60000-100000之间,分析得出这些商品存在异常;商品价格在1500-2000元之间有几个商品的销售量是0,可以肯定这是残缺数据,一般情况是把中位数作为补给数据填补给缺少的数据,这样可以让数据能更加的合理化,关联性更加的高。
將这些异常值进行数据清洗后得到图4合理的价格与销量分布散点分布可视化图。
当把数据清洗完成后,还需要进行数据的转换、规划等操作,方便之后的数据分析。数据转换和规划后结果如图5所示,图中可以看出有五千多种商品分类,和某个时间段内,各种商品的销售总数和销售总产值。
3可视化数据分析
对于数据的可视化设计采用matplotlib工具,运用Django框架把数据图表显示在web页面上。
3.1 不同价格区间商品的平均销量分析
图6分别对商品价格区间在0~13元,0~28元,0~49元等价格区间进行统计销量,结果发现:价格区间在0~50元之间小零食商品的销量都在3000~5000之间,差别不是很大,当价格超过50元,销量开始明显下降,分析得出消费者对于20~30元之间的小零食类商品最受喜爱。一方面是这个价格的商品符合大众需求,另一方面这个价格满足淘宝包邮策略所以销售数量最多。电商可以在其他商品或者价格策略上得到相应的启发,改变销售策略,获得最大收益。
3.2 不同地区的同一商品销量分析
图7是在不同地区对同一商品的销量统计,其中销量排名前三的分别是安徽,河南,湖北,上海作为消费大都市,却只排在了第七位,由此分析出对于零食的需求量主力军并不在南方,而是在中部地区。但从商品分布图8统计结果来看:上海浙江等地的商品数量排名靠前,而之前的安徽,河南等地区的商品数量确排名不高,所以接下来的销售商考虑的策略应该是尽量减少在上海和浙江等地区的商品数量存货,提高安徽,河南等地区的商品数量,达到市场供需平衡。
4 结束语
随着大数据应用越来越广泛,如何应用大数据更好地了解客户以及他们的爱好和行为是大数据研究的关键领域。本文研究如何从互联网上采集相关数据,让数据采集更高效,把采集到的各类数据进行清洗、过滤、归纳存储,将有用的数据进行统计和可视化分析,从中分析和挖掘出有价值的信息。
参考文献:
[1] 周苏, 王文. 大数据导论[M]. 北京: 清华大学出版社, 2016.
[2] 李联宁. 大数据技术及应用教程[M]. 北京: 清华大学出版社, 2016.
[3] 王星. 大数据分析:方法与应用[M]. 2版. 北京: 清华大学出版社, 2013.
[4] Wesly McKinney. Python大数据分析基础教程[M]. OReilly Media, 2013.
【通联编辑:谢媛媛】
