
自然环境下树上绿色芒果的无人机视觉检测技术
2018-12-04 09:03熊俊涛陈淑绵陈伟杰杨振刚
农业机械学报 2018年11期
熊俊涛 刘 振 林 睿 陈淑绵 陈伟杰 杨振刚
(华南农业大学数学与信息学院, 广州 510642)
0 引言
农业航空技术开始于20世纪20年代,如今已经成为世界各国农业领域的重要技术之一[1]。由于无人机具有工作适用性、灵活性和机动性等优势,近年来在农业领域得到了诸多应用,并逐渐成为现代农业工程一种新型设备[2-3]。
国内外关于农用无人机的研究主要集中在病虫害的监控[4-8]以及农药喷洒[9-13]方面,因无人机的空中作业机动性和灵活性较好,也逐渐应用于农作物产量估计上。李昂等[14]利用无人机拍摄从抽穗期到成熟期的水稻冠层影像,根据水稻图像的颜色特征对图像进行分割,提取出水稻穗数量并代入水稻产量估算公式进行估产。赵晓庆等[15]利用无人机获取大豆多个生育期的高光谱数据,并对采样空间尺度进行优化选择,得到能较准确估计大豆产量的采样空间尺度。HUANG等[16]使用无人机拍摄高分辨率的彩色图像,利用从棉花田获取的多个彩色图像,提取三维点云数据,计算棉花的高度,从而估计棉花产量。此外,SENTHILNATH等[17]利用无人机获取的高分辨率图像估计西红柿产量,CARL等[18]通过无人机获取的图像估计黑槐花和花蜜的产量,YU等[19]开发了一种基于无人机的高通量表型分析(High throughput phenotyping,HTP)平台,在大豆生长阶段收集高分辨率多光谱图像,并设计了一种大豆产量估计模型。
从国内外研究可知,使用无人机估计农作物产量的研究对象主要集中于地面生长高度较低的水稻、大豆和棉花等农作物上,较少使用无人机进行树上水果产量估计。而对树上水果产量估计的研究,主要集中在使用地面拍摄设备获取图像[20-23]。对于较高且树冠面积较大的果树,使用地面拍摄设备只能拍摄到离地面较近树冠的水果,而长在高处的水果,只能远距离拍摄或者以仰视的角度拍摄,很难拍摄到树冠顶部的水果。无人机则可以克服这个缺点,实现从空中拍摄到树冠高处和树冠顶部的水果。本文提出一种基于无人机的树上绿色芒果的视觉检测技术,利用无人机获取芒果图像,制作训练集,训练用于识别绿色芒果的YOLOv2模型,实现树上芒果的准确识别,为芒果产量的智能化估计提供视觉技术支持。
1 图像采集及图像拼接
所用无人机为大疆PHANTOM 3 STANDARD型四轴飞行器,如图1a所示,其自带的相机拍摄图像的分辨率为4 000像素×3 000像素,影像最大光圈是F2.8, 94°广角定焦镜头,等效焦距20 mm,拍摄时手动控制在距离芒果树1.5~2 m处进行拍摄,如图1b所示。图像拍摄时间为08:00—10:00,共拍摄471幅图像用于图像识别算法研究,为满足样本的多样性,挑选出包含不同距离和光照情况的图像,共挑选出360幅图像,如图2所示。随机选取300幅图像作为训练集,剩余60幅图像作为测试集。

图1 图像采集现场Fig.1 Image acquisition scence

图2 无人机采集到的芒果图像Fig.2 Mango images collected by unmanned aerial vehicle
为得到整棵树的图像,在采集图像时,手动控制无人机在距离芒果树1.5~2 m处拍摄图像,分两次拍摄树的两侧,如图3a所示。在采集单侧图像时,从树的左上角开始拍摄,从上往下,如图3b所示,按数字顺序采集整棵树的图像,其中相邻两幅图像的重叠位置用于图像拼接,本文使用基于SURF的图像拼接算法[24],按拍摄顺序依次拼接图像,得到整棵树一侧的图像,结合两侧可以得到一棵树完整的图像。本文挑选5棵树进行拍摄,先人工计算没有被遮挡、直接可见的芒果数量,然后再进行图像采集,用于验证模型的有效性。

图3 图像采集Fig.3 Image acquisition
2 基于YOLOv2的绿色芒果视觉检测方法
近年来深度学习在目标检测领域取得了较大的进展,GIRSHICK等[25]提出了区域卷积神经网络(RCNN),在VOC2012数据集上平均精度提高了30%,达到了53.3%。在RCNN的基础上,GIRSHICK[26]和REN等[27]提出了快速区域卷积神经网络(Fast RCNN)和超快速卷积神经网络(Faster RCNN),在提高检测正确率的同时增加了检测速率,检测速率达5 f/s。REDMON等[28]提出了YOLO模型,平均精度达63.4%,检测速率达到45 f/s。随后,REDMON等[29]在YOLO模型的基础提出了YOLOv2模型,在VOC2007上平均识别精度(MAP)达76.8%,识别速率达到67 f/s。
参照文献[30]的思想,将分类和定位整合到同一个网络当中,与之前大部分目标检测框架使用的特征提取网络VGG-16相比,YOLO模型使用类似goollenet的网络结构,计算量小于VGG-16,能在保证正确率的同时拥有较快的检测速率,标准的YOLO模型检测速率达到45 f/s,Fast YOLO模型检测速率达到了155 f/s,但正确率略低于VGG-16。YOLOv2模型以Darknet-19为基础网络模型,包含了19个卷积层和5个最大池化层,在保持YOLO模型检测速率的同时提升了检测精度,使用分辨率为544像素×544像素的图像时,YOLOv2模型在VOV2007数据集上可以在正确率比Faster RCNN高的情况下,处理速率达到40 f/s,如表1所示。
使用YOLOv2模型作为树上芒果的检测方法,先对300幅训练集图像进行人工标记,标记图像中的感兴趣区域(Region of interest,ROI),然后用标记好的图像通过预训练,调整YOLOv2模型网络参数,最后用调整好的参数训练YOLOv2模型网络,如图4所示。
2.1 标记训练数据集
YOLOv2模型需要人工设置标签,根据人工设置的标签进行自我学习,要测试模型检测的精度,也需要对测试集进行人工标记感兴趣区域。所以在训

表1 目标检测模型性能对比Tab.1 Performance comparison of object detection box
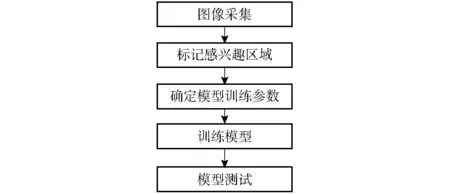
图4 模型训练流程Fig.4 Model training process
练模型之前,需要对训练集和测试集图像进行人工标记感兴趣区域,并记录标记的矩形框的右上角坐标和矩形框的长、宽作为YOLOv2的输入。为了使模型有较高的检测效果,标注的样本中包含了不同光照角度和不同拍摄距离的芒果样本,同时适当加入了遮挡的芒果。在300幅训练集图像中,共标记出2 542个芒果样本,部分芒果样本如图5所示,其中顺光样本1 673个,占样本总数的65.81%,逆光样本869个,占样本总数的34.19%,其中有遮挡的样本中,顺光样本293个,逆光样本125个,共有418个样本,占样本总数的16.44%。

图5 训练样本示例Fig.5 Examples of training sample
2.2 模型参数选择
训练模型时,输入图像的分辨率、批处理量(batch)、学习率都会影响最终模型的检测效果,因此在训练模型之前,需要选择合适的参数。本文训练使用的操作系统为Ubuntu 16.04,训练使用框架为Darknet,CPU为i7-8700,主频为3.2 GHz,六核十二线程,内存32 GB,显卡为GeForce GTX 1080,显存为8 GB,使用YOLOv2官方提供的预训练模型对数据集进行训练。因为40 f/s的速率可以满足实际应用的要求,而识别精度则越高越好,因此,输入图像分辨率设定为544像素×544像素。
2.2.1批处理量
在训练模型的过程中,为准确计算损失函数对参数的梯度,需要对数据集上的每一个样本进行计算,对于深度神经网络而言,这样做计算量会非常巨大。所以,一般在训练深度神经网络时,会分批从数据集中抽取少量的图像,然后计算这批图像的平均值,抽取图像的数量即为批处理量(batch),但批处理量太小会造成模型无法收敛的情况,批处理量太大会使收敛速率变慢,因此要选择合适的批处理量。本文分别选取16、32、64、128、256作为批处理量,其他参数使用默认值,其中学习率为0.01,对模型训练500次的平均精度进行比较,如表2所示。

表2 不同批处理量模型的平均精度对比Tab.2 Performance comparison of model with different batches
从表2可以看出,其他参数不变的情况下,随着批处理量的增大,训练500次模型的检测精度逐渐增大,但MAP并非随着批处理量的增大而线性增大,当批处理量从16增大到64时,MAP增大了18.08个百分点,而批处理量从64增大到256时MAP只增大了3.20个百分点,而批处理量增大会使训练时间明显增加,综合考虑检测精度和训练时间两个因素,本文选择64作为批处理量。
2.2.2学习率
学习率的大小影响模型的收敛速率,学习率太小,会使模型收敛缓慢,学习率太大,会使代价函数震荡,甚至无法收敛。从表2可以看出,当批处理量为64,学习率为0.01时,模型训练500次MAP为74.37%,检测精度高于70%,收敛速率较快,而且还未达到收敛,所以本文设置初始学习率为0.01,前500次学习率保持不变,之后每训练100次,学习率变为当前学习率的0.95倍。
2.3 模型训练与测试
基于YOLOv2官方提供的预训练模型,根据预训练得到的参数对测试集进行训练,其中批处理量为64,初始学习率为0.01,在训练次数达到500次以后,每训练100次学习率变为当前学习率的0.95倍,其他参数使用YOLOv2默认的参数,其中动量系数为0.9,网络损失值变化情况如图6所示。

图6 训练阶段损失值变化情况Fig.6 Change of loss value in training stage
从图6可以看出,随着训练次数的增加,损失值逐渐减小,前500次训练损失值变化较大,训练次数达到500以后损失变化趋于平缓,当训练次数达到2 500以后损失值趋于平稳,从2 500次到4 000次时,损失值一直稳定在0.1~0.2,因此暂停训练,选择训练2 500、3 000、3 500、4 000次的模型,使用60幅测试集图像进行测试,测试结果如表3所示。

表3 不同训练次数的模型检测平均精度对比Tab.3 Performance comparison of model with different numbers of training
从表3可以发现,当训练次数达到2 500以后,模型的MAP变化较小,当训练次数为3 000时,模型的MAP最高,因此选择训练次数为3 000时的模型作为本文的芒果检测模型,经测试使用GeForce GTX 1080显卡运行模型时,检测一幅图像的平均时间为0.08 s,其中部分检测结果如图7所示。

图7 树上芒果图像的检测结果Fig.7 Detection results of mango image on tree
3 试验与结果分析
为检测本文算法对果实识别的准确性,本文设计了果实识别试验,对测试集中的60幅图像进行识别测试,部分识别结果如图7所示。因为芒果是单个生长的,所以本文通过计算正确识别芒果的个数和错误识别芒果的个数作为识别正确率的标准,错误识别数为假阴数和假阳数之和,其中假阴包含漏识别和一框多果两种情况,没有被框标记出来的芒果记为漏识别,一框多果,只记为正确识别一个,其余果记为假阴,例如一个框包含两个果,算正确识别一个,假阴一个;假阳包含误识别和一果多框两种情况,矩形框将背景框出来记为误识别,同时一个果包含多个框,只记为正确识别一个,其余框记为假阳。统计60幅测试集图像中,共有438个芒果,芒果的识别统计结果如表4所示。438个芒果中有397个芒果被正确识别,识别正确率为90.64%,错误识别的芒果数为41个,识别错误率为9.36%,其中假阴(漏识别,一框多果)25个,假阳(误识别,一果多框)16个。为测试不同情况下本文算法的识别正确率,本文分别按图像中含果实数和图像光照情况进行进一步统计分析。

表4 图像检测结果统计Tab.4 Statistics of detection results of images
同时利用Ostu、K-means、模糊C均值聚类(Fuzzy C-means clustering,FCM)算法对60幅测试集图像进行识别,与本文算法进行对比,识别结果如表5所示。由表5可知,因为绿色芒果和背景(树叶)都为绿色,芒果和背景的颜色区别不明显,使用Ostu、K-means、FCM 3种算法识别的正确率较低,这3种算法中,FCM算法有较高的识别正确率,识别正确率为82.42%,Otsu有较高的运行速率,识别一副图像的平均时间为0.09 s。本文算法识别正确率为90.64%,识别一幅图像的平均时间为0.08 s,与Ostu、 K-means及FCM算法相比,本文算法有较高的识别正确率和运行速率。

表5 不同识别算法性能对比Tab.5 Comparison of segmentation algorithms
3.1 不同果实数的图像检测结果分析
在自然环境下拍摄的芒果图像,往往一幅图像中所拍摄的芒果数量是不同的,图像中含果实数目的不同会对检测结果造成不同的影响,如果图像中只有一个芒果,所拍摄的芒果一般比较完整清晰,比较容易识别。相对单果图像而言,如果一幅图像中含有多个芒果,可能会出现2个或多个果实粘连或者相互遮挡的情况,增加检测难度。因此本文按图像中含果实的数量分3个梯度对60幅测试集的检测结果进行了统计,3个梯度分布为图像中果实数小于5、图像中果实数为5~10以及图像中的果实数大于10,含不同果实数图像检测结果统计如表6所示。
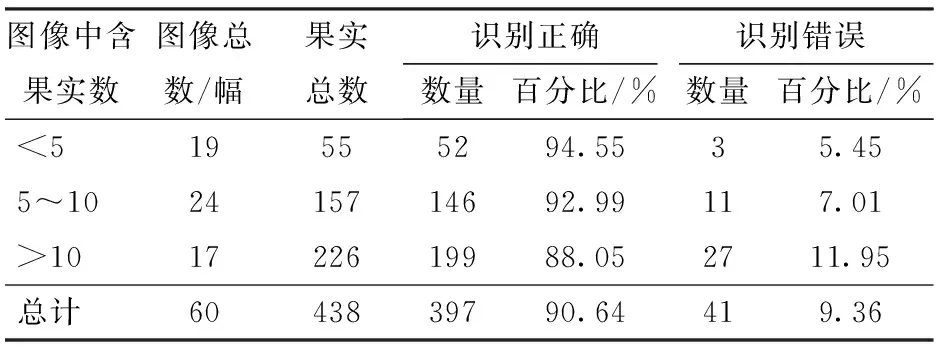
表6 含不同果实数的图像检测结果统计Tab.6 Statistics of detection results of images with different quantities of fruits
由表6可以看出,随着图像中果实数量的增加,识别正确率下降,识别错误率上升。是因为随着果实数量的增加,多个果实粘连和遮挡情况越多,当图像含果实数较多时,几乎每幅图像都有粘连和遮挡情况发生,虽然通过边缘检测分隔了部分粘连的果实,但还是有相互粘连和遮挡的果实会被识别为一个果实,降低识别正确率。除此之外,含果实数量较多的图像,一般拍摄距离较远,因此背景会比较复杂,图像中的芒果也比较小,比较模糊,从而导致识别正确率降低,识别错误率增加。
3.2 不同光照情况下图像检测结果分析
在自然环境下,拍摄时的光照角度不同也会影响检测的效果,在顺光条件下拍摄的图像一般比较明亮清晰,在逆光条件下拍摄的图像会比较阴暗模糊。因此,本文将60幅测试集图像的检测结果分为顺光和逆光两组进行统计分析,统计结果如表7所示。

表7 不同光照情况下图像检测结果统计Tab.7 Statistics of image test results of different illumination conditions
从表7可以看出,在逆光条件下的检测效果明显比顺光条件下的检测效果差,因为在逆光环境下拍摄的图像比较暗,果实和背景的颜色分量值均降低,各分量值的对比度降低,边缘特征和颜色特征也被弱化,从而增加了逆光条件下的检测难度。
3.3 整棵树芒果数量检测结果分析
为进一步验证模型的有效性,本文选择5棵树,先人工计算没有被遮挡、直接可见的芒果数量,然后再按第1节中的方法进行图像采集和拼接得到整棵树的图像,用本文算法对图像进行检测,用算法检测出来的芒果数量与人工计算的芒果数量进行对比验证。用算法检测树两侧的图像得到整棵树上芒果的数量,统计结果如表8所示。

表8 整棵树芒果数量检测结果统计Tab.8 Statistics of mango count test results
其中,总计为正确识别的芒果数量加上假阳(误识别,一果多框)数量,即算法检测出来的芒果
数量,误差计算公式为
(1)
式中E——误差,%TP——正确识别数
R——人工计算芒果个数
FP——假阳数量
由表8可知,总的识别正确率为79.70%,远低于3.1节和3.2节的正确率,这主要是因为采集图像时,只从2个角度获取芒果树图像,有些芒果在这2个角拍摄不到,而人工计数时可以看到。从误差来看,算法统计的芒果数量小于人工统计的芒果数量,而且误差范围集中在11%~15%之间,平均误差为12.79%,在实际应用时,可统计多棵芒果树的误差,再根据多棵果树的平均误差和算法检测的芒果数,估计芒果的实际产量。
4 结论
(1)提出了一种自然环境下树上绿色芒果的无人机视觉检测技术,使用无人机采集图像,对图像进行人工标记感兴趣区域,通过预训练确定了YOLOv2模型训练的批处理量和学习率,利用预训练确定的训练参数训练YOLOv2模型,最终训练得到的模型在测试集上的平均精度为86.43%。
(2)本算法对芒果识别具有较高的正确率,60幅测试集图像中共拍摄到438个芒果,正确识别的芒果有397个,识别正确率为90.64%,识别错误率为9.36%。对含不同果实图像识别的正确率如下:含果实数小于5的图像,识别正确率为94.55%;含果实数5~10的图像,识别正确率为92.99%;含果实数大于10的图像,识别正确率为88.05%。不同光照条件下识别正确率如下:顺光条件下识别正确率为93.42%,逆光条件下识别正确率为87.18%。
(3)本算法识别一幅图像的平均时间为0.08 s,对于不同情况下的芒果识别正确率较高,使用无人机可以快速准确地估计芒果的产量,为果园自动化管理和收获提供方法支持与参考。
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
中华养生保健(2020年7期)2020-11-16
科学导报·学术(2020年84期)2020-11-08
动漫界·幼教365(中班)(2020年3期)2020-04-20
电脑爱好者(2019年1期)2019-10-30
动漫界·幼教365(小班)(2018年10期)2018-05-14
动漫界·幼教365(大班)(2018年10期)2018-05-14
电脑爱好者(2017年18期)2017-11-03
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
