
数字水系分级对流溪河模型中小河流洪水预报的影响
2018-12-19 09:51,,,,
长江科学院院报 2018年12期
,,,,
(1.中山大学 地理科学与规划学院,广州 510275; 2. 江西省赣州市水文局,江西 赣州 341000)
1 研究背景
我国中小河流洪水主要由暴雨引起,从暴雨开始到洪水爆发通常只有几个小时,具有突发性强、预见期短、破坏力大的特点,是近几年造成我国人员伤亡主要洪水灾害。中小河流一般处于偏僻的流域上游,缺少长序列的水文气象观测资料,往往需要采用无资料地区的水文预报方法进行预报。集总式水文模型依赖长序列的水文观测资料率定模型参数,而我国中小河流积累的实测洪水资料较短,不能满足集总式模型的参数率定的基本数据要求,导致集总式模型在中小河流洪水预报中难以有效应用。
分布式模型是水文模型的最新发展,具有代表性的模型包括欧洲的SHE(System Hydrological European)模型(Abbott等[1],1986)、美国的Vflo模型(Vieux等[2],2002)、我国的LL模型(李兰[3],2003)、EasyDHM模型(雷晓辉等[4],2010)和流溪河模型(陈洋波[5],2009)等。分布式模型的参数具有一定的物理意义,只需要少量的实测资料就可以进行模型参数优选,在我国中小河流洪水预报中具有很好的应用潜力。分布式模型将流域汇流区分为坡地汇流和河道汇流,采用基于圣维南方程组及其简化形式的水力学方法计算汇流,精细化描述了洪水在流域坡面和河道的运动过程和规律,为中小河流洪水预报模型提供了新的研究方法。分布式模型河道汇流计算需要详细的河道断面尺寸数据,但由于这一资料获取困难,使得分布式模型在实际应用时,不得不采用集总式方法进行河道汇流计算,从而失去了分布式模型的特点和优势。
流溪河模型是主要应用于流域洪水预报的分布式物理水文模型。该模型假定流域河道断面为梯形,采用卫星遥感数据估算河道断面尺寸,为流溪河模型在中小河流洪水预报中的应用提供了条件。模型采用运动波法和扩散波法分别计算边坡汇流和河道汇流,当数字水系分级不同时会改变流域汇流特性,会影响洪水预报的结果。
为了探讨流溪河模型在中小河流洪水预报中的适用性,以及数字水系分级对洪水过程的影响,本文首先构建龙华江流域洪水预报流溪河模型,采用改进的粒子群算法( Particle Swarm Optimization,简称PSO)优选模型参数,最后验证了模型并讨论数字水系分级对流域洪水过程和预报的影响。
2 研究方法
2.1 中小河流洪水预报流溪河模型
流溪河模型(陈洋波等[6-7],2010)采用正方形网格的DEM数字高程模型(Digital Elevation Model)从水平方向将流域划分成网格,称为单元流域,并分成边坡单元、河道单元和水库单元。在单元流域上进行蒸散发量及产流量的计算,各单元流域上产生的径流量通过汇流网络进行逐单元汇流至流域出口,汇流分成边坡汇流和河道汇流。河道汇流采用一维扩散波法,即忽略圣维南方程组的运动方程中的惯性项,考虑摩阻为坡底及压力项的差;采用一维运动波法进行边坡汇流计算,即忽略圣维南方程组的运动方程中的惯性项和压力项,只考虑摩阻和坡底的影响。流溪河模型根据DEM数据,采用D8法(O’Callaghan等[8], 1984)推求河道拓扑结构,采用Strahler法(Strahler[9],1957)进行水系分级。河道分级后,为了便于估算河道断面尺寸,再将同级河道分为若干段。具体做法是采用分段点将河道划分成虚拟河段,假定同一条虚拟河段的河道属性一致,河道断面形状为矩形,用河道宽度和底坡表示断面尺寸。河道底宽采用卫星遥感影像进行估算,底坡则根据虚拟河段内各单元的高程进行估算。流溪河模型提出了基于PSO法的模型参数自动优选方法(Chen等[10], 2017;陈洋波等[11],2017),实际应用中只要有一场数据质量较好的实测洪水过程就可以优选模型参数,大大提高了模型的性能,在我国中小河流洪水预报中应用具有明显优势。流溪河模型已成功应用于水库洪水预报(黄家宝等[12], 2017)、中小河流洪水预报(陈洋波等[13],2017)、大流域水文气象耦合洪水预报(Chen等[14], 2017; Li等[15], 2017)。
2.2 流域数字水系提取和分级
目前基于DEM(熊立华等[16], 2003)提取流域水系最常用的方法是D8法(王正勇等[17], 2016)。该方法假定栅格中的水流只能流向周围的8个栅格,即每个栅格只有一个流动方向,流向根据栅格与周围8个栅格之间的最陡坡度来确定。基于D8法提取数字水系的主观性较大,当对某一流域进行水系提取时,不同的人计算得到结果相差较大。在流溪河模型中,采用分级提取方法对D8法进行改进,减小模型在提取水系时的人为干扰因素。该方法的基本思路是,根据DEM计算流域各个网格单元累积流的数值,然后设定不同的累积流阈值进行水系提取,如果网格单元的累积流大于阈值,则该网格单元被划分为河道单元,如果网格单元的累积流小于阈值,则该网格单元被划分为边坡单元。河道单元确定后,采用Strahler法进行水系分级。对于不同的阈值,水系分级不同,并存在一系列临界值,该值的定义是使得水系分级改变时的累积流值。对于同个流域,采用统一的阈值进行水系提取和分级时,不同的人都得到相同的计算结果,大大降低了直接采用D8法提取水系所带来的不确定性。
3 龙华江流域洪水预报流溪河模型
3.1 龙华江流域概况
龙华江流域面积1 144 km2,主河道长度为89.4 km,主河道纵比降为2.16‰,流域平均高程337 m,流域长度56.4 km,流域形状系数0.36。流域内河系发达,河流水质良好。上游河道窄深,河床多砾石,中下游河道宽浅,河床多沙,属典型的山区性中小河流。流域内地形以低山丘陵为主,上游植被较好,中下游植被较差。龙华江安和水文站建于1976年1月,站址位于上犹县安和乡潭下村,至河口距离18 km,集水面积246 km2,以安和水文站以上流域开展研究,简称龙华江流域。龙华江流域内有8个雨量站,雨量站分布如图1所示。
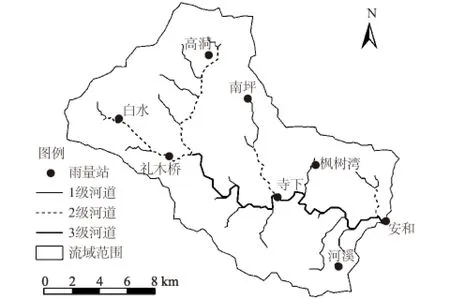
图1 龙华江流域雨量站分布Fig.1 Location of rainfall stations in Longhua river watershed
流域出口处的安和水文站有较长期的水文观测资料,本文收集了龙华江流域内1981年以来的51场实测洪水过程的资料,包括雨量站降雨及水文站流量,均以小时为时段。将洪峰流量<100 m3/s的洪水定义为小洪水,洪峰流量>200 m3/s的洪水定义为大洪水,其它洪水定义为中洪水。则共有小洪水15场,中洪水20场,大洪水16场,都具有较好的代表性。
3.2 流溪河模型构建
流溪河模型建模所需的DEM数据采用SRTM(http:∥srtm.csi.cgiar.org/)公共数据库中的数据,空间分辨率为90 m×90 m。土地利用类型为美国地质调查局全球土地覆盖数据库中的数据 (http:∥landcover.usgs.gov/),土壤类型采用国际粮农组织的土壤数据(http:∥www.isric.org/), 空间分辨率为1 000 m×1 000 m,经重采样转换为与DEM相同的空间分辨率。
为了评估数字水系提取和分级对洪水过程的影响,本文基于空间分辨率为90 m×90 m的DEM,构建不同水系分级的流溪河模型。采用流溪河模型软件计算累积流阈值,其中1,2,3级水系累积流阈值分别为4 622,805,158。累积流阈值是使得水系改变时的累积流值。在本文中,所采用累积流值≥4 622时流域水系划分为1级;采用累积流值∈[805, 4 622)时流域水系划分为2级;采用累积流值∈[158, 805)时流域水系划分为3级。本文采用不同的累积流值为500,2 000,17 000,将流域数字水系分为3,2,1级,采用的累积流值越小,水系河网越密集,如图2。
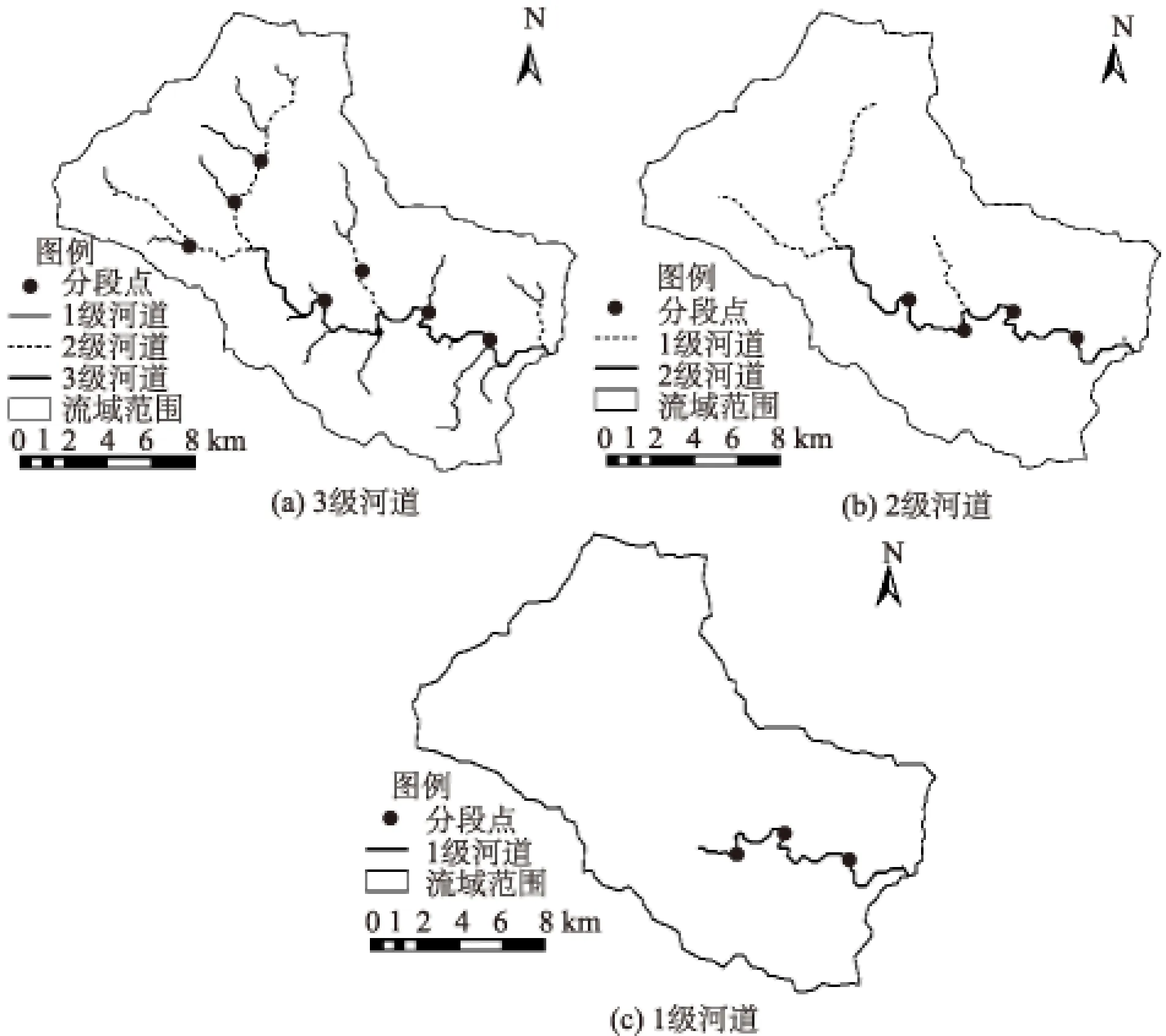
图2 流溪河模型结构示意图Fig.2 Structure of Liuxihe model
当流域数字水系分为4级时,参照赣州市水文局提供流域水系图及遥感影像发现河源部分的水系形态不明显,与实际流域水系分布不符,所以本文采用最高级水系为3级。采用分段点将数字水系划分成若干段虚拟河段,当水系分级不同时,分段点、虚拟河段、河道单元和边坡单元的数量都有所改变,见表1。
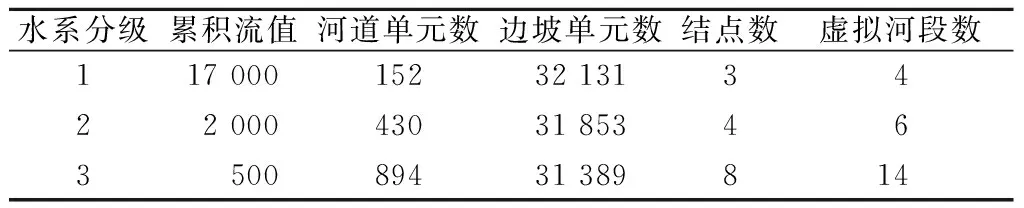
表1 模型结构信息Table 1 Information of model structure
数字水系越密集,河道单元数量越多,边坡单元数量越少,流域的汇流特性也会发生改变,从而影响到流域洪水过程。
3.3 流溪河模型初始参数推求
流溪河模型基于各单元上的流域物理特性确定模型初始参数,对不同水系分级建立的模型,据此确定的模型初始参数相同。参数分成4大类,包括地形类参数、气象类参数、土壤类参数和土地利用类参数。流向和坡度是流溪河模型的地形类参数,根据DEM直接计算确定。气象类参数主要是蒸发能力,所有单元均取为5 mm/d。土地利用类型参数是边坡糙率和蒸发系数。蒸发系数是个非常不敏感的参数,统一取为0.7。边坡糙率根据文献(Wang等[18],1996)推荐值确定。
土壤类参数包括土壤厚度、饱和含水率、田间持水率、饱和水力传导率、凋萎含水率和土壤特性。饱和含水率、田间持水率、饱和水力传导率和凋萎含水率采用由Arya 等[19]提出的土壤水力特性计算器计算,结果如表2。土壤特性值取为2.5。
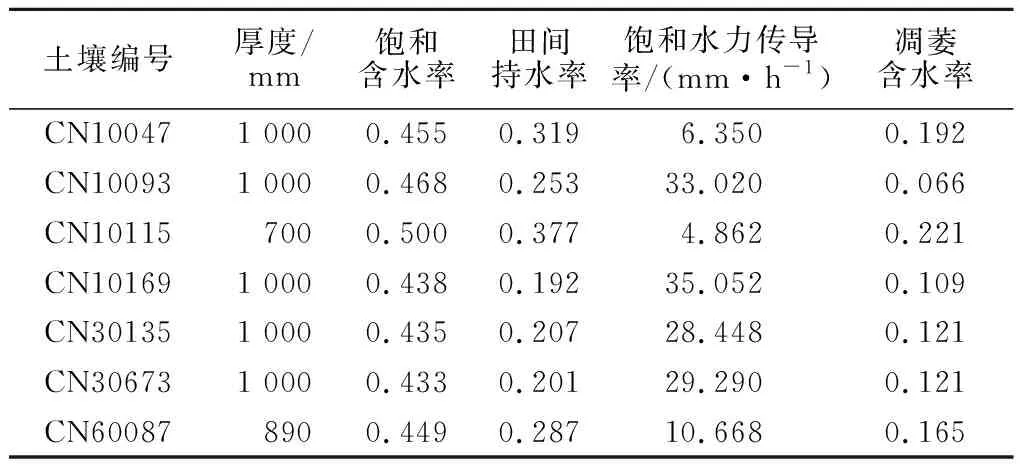
表2 土壤类参数初值Table 2 Initial values of soil type
3.4 流溪河模型参数优选
本文采用粒子群(PSO)算法进行流溪河模型的参数自动优化。PSO算法起源是根据鸟群捕食觅食过程中的迁徙和群集的社会行为提出的一种与进化计算有关的群体智能随机优化策略。PSO算法中的每个粒子代表一个参数解集,粒子通过记忆、追随个体最优及群体最优的位置来更改自身的速度与方向,实现寻优过程。粒子群算法的实质是一种基于群体的、能够全局寻优的优化策略,通过群体中粒子之间的合作、竞争机制,智能地指导群体的优化搜索过程,每个粒子都具有“自我经验总结”和“群体共享”的双重特点。粒子的速度变换及位置变换的转换关系为:
Vi,k=ωVi,k-1+C1(Xi,pBest-Xi,k-1)rand+
C2(XgBest-Xi,k-1)rand ;
(1)
Xi,k=Xi,k-1+Vi,k。
(2)
式中:Vi,k为第i个粒子k时刻运行速度;Xi,k为第i粒子k时刻位置;Xi,pBest为第i粒子个体最优位置,对应流溪河模型参数优选结果的局部最优解;XgBest为粒子全局最优位置,即流溪河模型最终的参数优选全局最优解;ω为惯性加速度;C1和C2为学习加速因子;rand为值介于0~1的随机数。
粒子群算法由于其简单、高效的全局搜寻能力被广泛应用到各行各业,但也显示了算法的一些不足:①易陷入局部极值,PSO寻优过程中无较为精密搜索方法与之配合,往往不能得到精确的结果,即出现早熟收敛;②PSO只是提供了全局搜索的可能,但无验证的数学证明其在全局最优位置的收敛性;③PSO容易造成种族退化,种族多样性差。针对这些不足,主要从以下几点进行改进(Chen等[10],2017)。
(1)学习加速因子C1和C2值并非取原始的PSO算法中的固定值,而是采用经验公式反余弦加速算法动态调整所得,其计算公式为:
(3)
(4)
式中:C1max和C1min为C1的取值上下限,文中分别设为2.75,1.25;C2max和C2min为C2的调整上下限,分别设为2.5,0.5;i为当前迭代次数;Nmax为总迭代数。
(2)惯性权重因子在原始的PSO算法中取值为1。模拟采用的惯性权重因子根据经验公式采用线性递减算法求得,即
(5)
式中:t为当前的迭代次数;T为最大的迭代次数;最大惯性权重因子ωmax=0.9;最小惯性权重因子ωmin=0.1。
在原始的PSO算法中考虑随机扰动次数的干预影响,并保持扰动影响的次数不变(10次)。
改进的粒子群算法的基本步骤如下:
(1)粒子群参数设置。设置种群规模P,确定粒子维数N,惯性因子ω,学习因子C1和C2。
(2)粒子群初始化。在参数空间中随机生成P个粒子(设定种群中的每个粒子初始位置及初始速度)。
(3)开始循环寻优,循环到算法收敛为止,否则重复上述步骤进行寻优。
根据上述粒子群算法的计算步骤及流溪河模型结构、参数分类特征,可归纳总结出基于粒子群算法进行流溪河模型参数优选的计算流程框图,如图3。
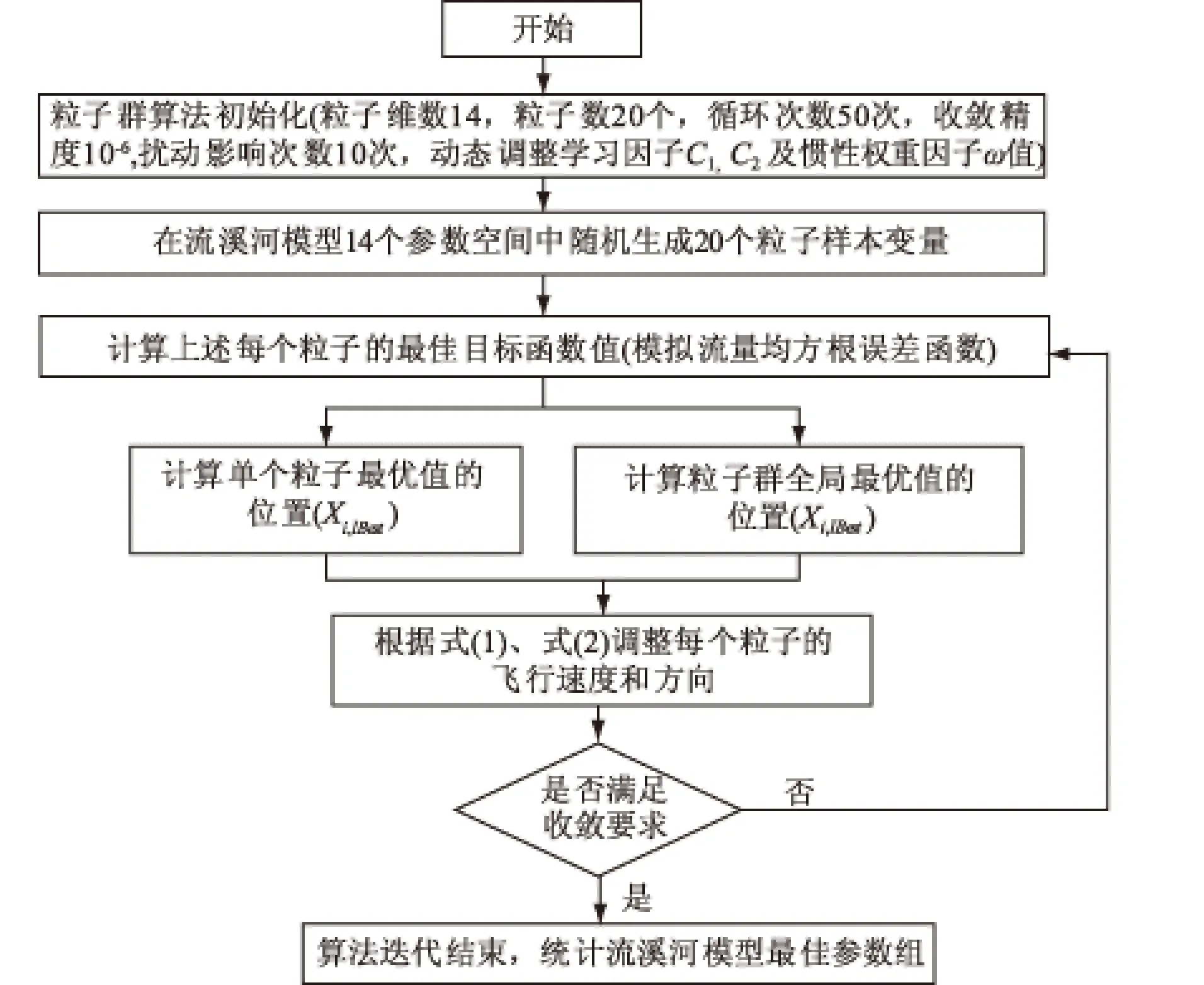
图3 基于粒子群算法的流溪河模型参数优选流程Fig.3 Flowchart for parameter optimization of Liuxihe model by PSO
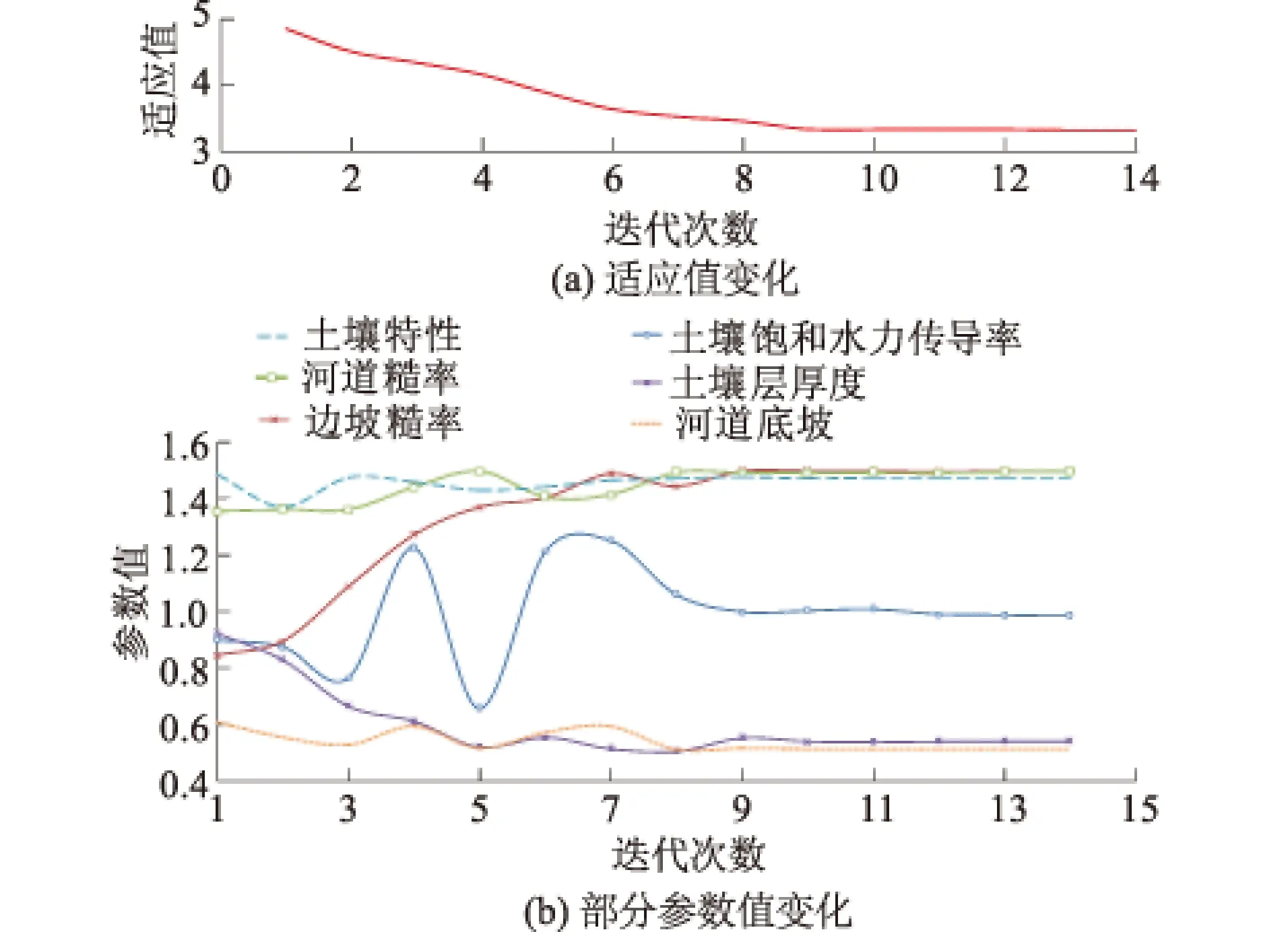
图4 参数优选过程中参数进化图(3级水系)Fig.4 Procedure of parameter optimization (three orders)
本文以2005081308场次洪水进行模型参数优选,其它场次洪水进行模型验证。对不同的水系分级,本文均采用同一场洪水进行参数优选,优选的参数各不相同。粒子群的种群规模为20,最大迭代次数为50次,总计算次数为1 000次。惯性因子取值范围为[0.1,0.9],学习加速因子C1和C2的取值范围均为[0.5,2.5]。限于篇幅,图4仅列出了3级河道参数优选过程中适应值和参数值的进化结果。从图4中结果看出,经过8次的进化计算,模型参数收敛到最优值,说明流溪河模型参数优选具有较好的收敛速度。
4 讨 论
4.1 不同水系分级对流域洪水过程的影响
为了分析水系分级对流域洪水过程的影响,分别采用1,2,3级水系划分时构建的流溪河模型及确定的模型初始参数,对大中型2场典型洪水进行模拟,结果如图5。对模拟结果进行统计,统计指标如表3。

图5 不同水系分级时的洪水模拟结果Fig.5 Flood simulation results with different river orders
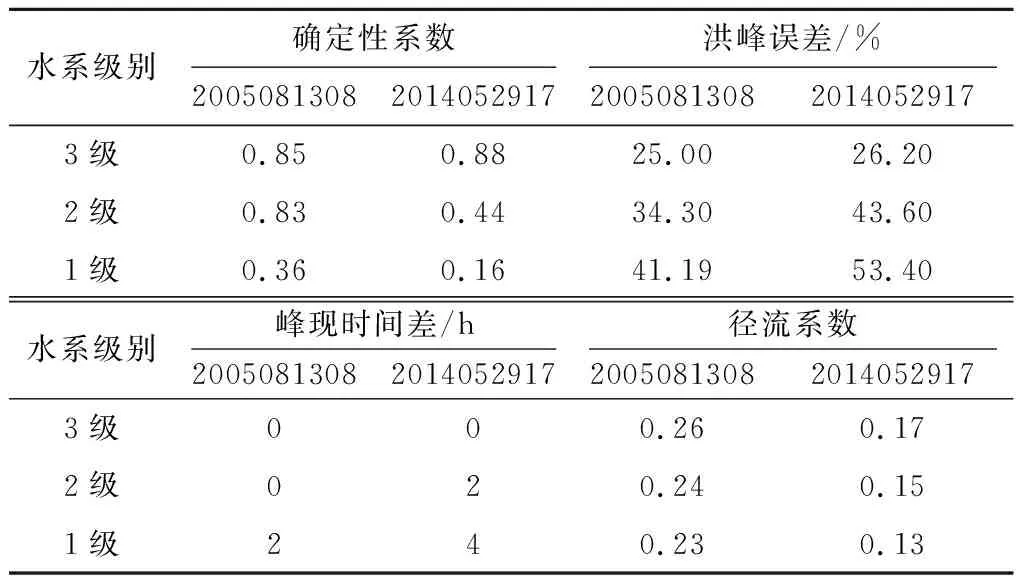
水系级别确定性系数洪峰误差/%20050813082014052917200508130820140529173级0.850.8825.0026.202级0.830.4434.3043.601级0.360.1641.1953.40水系级别峰现时间差/h径流系数20050813082014052917200508130820140529173级000.260.172级020.240.151级240.230.13
从图5和表3可以看出,水系分级对模拟的洪水过程的形状、峰值、峰现时间都有影响。对于2005081308场次洪水,随着流域数字水系分级从1级增加到3级,模拟洪水过程线与实测过程吻合程度逐步增高,其中1级水系的模型不能模拟出流域实测洪水过程,2级水系的模型的模拟过程线与实测值趋势相同,3级水系的模型的模拟过程与实测过程趋于吻合;洪峰误差从41.19%降到了25%,模拟的洪水峰值逐渐增大并接近实测值;洪水峰值出现时间误差从2 h变成了0,模拟的洪水峰现时间逐渐提前并接近实测值;径流系数从0.23增加到了0.26,径流系数和洪量都有所增加。
上述结果表明,1级数字水系不能很好地刻画流域洪水的真实汇流过程,采用流溪河模型进行中小河流洪水预报时,不能采用1级数字水系构建模型。
4.2 不同水系分级对流域洪水预报的影响
为了定量评估数字水系分级对流域洪水预报的影响,采用不同水系分级建立的流溪河模型及相应的优选参数,分别对50场洪水进行了模拟,统计了模拟的各场洪水的6个评价指标。由于数据较多,表4仅列出了各级模型的平均统计指标,图6仅绘出了其中6场洪水的模拟结果。
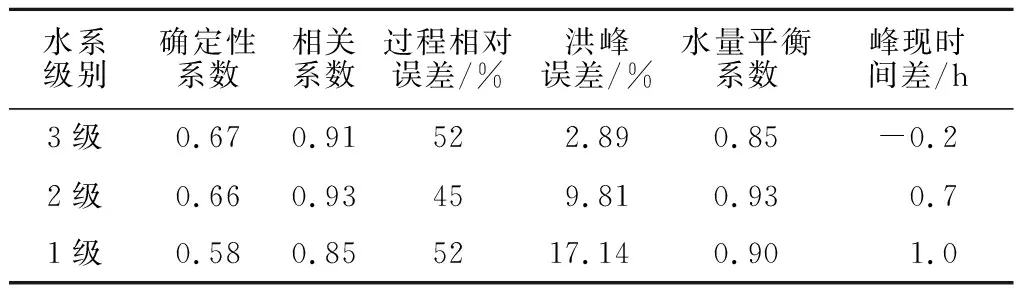
表4 不同水系分级的流溪河模型洪水模拟结果统计指标Table 4 Statistical indicators of flood simulation resultswith different river orders for Liuxihe model
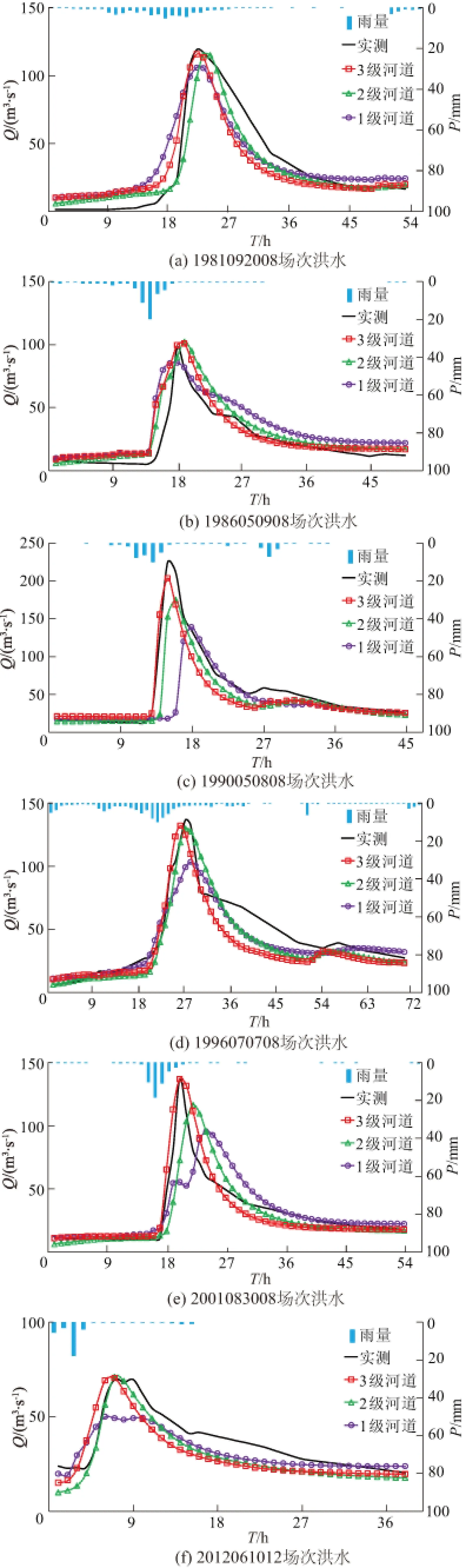
图6 龙华江流域不同水系分级的流溪河模型洪水模拟结果Fig.6 Flood simulation results with different river orders for Longhua river watershed
从上述的模拟结果和统计指标来看,3级水系的模型模拟结果最好,不仅在6个统计指标中结果较好,而且50场模拟洪水过程跟实测值吻合程度最高;2级水系的模型效果比3级的稍差,基本也能模拟出流域实测洪水过程,这也说明了采用PSO算法优选模型参数能有效降低水系分级不确定性对洪水模拟的影响;1级水系的模型不能很好地模拟出实测洪水过程,一般不能模拟出实测峰值,影响到了中小河流洪水预报的精度。结果表明,采用流溪河模型进行中小河流洪水预报时,适宜采用3级水系构建模型。
本文采用水系分级为3级,河道断面形状为矩形时的流溪河模型为龙华江流域洪水预报流溪河模型,参数采用优选的模型参数。该方案对50场洪水模拟的确定性系数均值为0.67,相关系数达0.91,洪峰误差均值为2.89%,最大的也没有超过20%,平均峰现时间为-0.2 h,洪水过程的模拟结果与实测值吻合很好。根据我国水文情报预报规范,该预报方案等级可评定为甲等,可用于龙华江流域实时洪水预报。
5 结论与展望
为了探讨流溪河模型在中小河流中的适用性,以及基于DEM的数字水系提取和分级对流域洪水预报的影响,本文首先针对江西省龙华江流域构建了龙华江流域洪水预报流溪河模型,采用PSO算法优选模型参数,最后验证模型并讨论了数字水系分级对流域洪水预报的影响。结果表明:
(1)数字水系分级越高,流域洪水模拟过程线越接近实测值、洪峰值增大、峰现时间提前、径流系数越大。
(2)1级数字水系不能刻画流域洪水的真实汇流过程,采用流溪河模型进行中小河流洪水预报时,不能采用1级数字水系构建模型,适宜采用3级水系构建模型。
(3)流溪河模型采用PSO算法的自动优选模型参数,实际应用中只需要一场具有代表性的实测洪水过程就可以优选模型参数,有效提高了模型的性能。
(4)基于3级水系构建龙华江流域洪水预报流溪河模型,采用PSO算法优选模型参数,对50场洪水模拟的确定性系数均值为0.67,相关系数达0.91,洪峰误差均值为2.89%,洪水过程的模拟结果与实测值吻合很好,模型可用于龙华江流域实时洪水预报。
数字水系分级不同会引起流域汇流特性的改变,从而影响到流域的洪水形成、洪峰、峰现时间等,在采用分布式水文模型进行中小河流洪水预报时,需要谨慎考虑水系分级对洪水预报的影响。本文的研究可为分布式模型在我国中小河流洪水预报的应用提供参考和思路。
猜你喜欢
水利水电快报(2022年7期)2022-07-18
水利规划与设计(2020年1期)2020-05-25
娃娃乐园·综合智能(2019年6期)2019-07-10
学苑创造·B版(2019年3期)2019-04-24
天津诗人(2017年2期)2017-11-29
智能建筑电气技术(2015年5期)2015-12-10
雷达与对抗(2015年3期)2015-12-09
少儿科学周刊·儿童版(2015年7期)2015-11-24
少儿科学周刊·儿童版(2015年7期)2015-11-24
太阳能(2015年7期)2015-04-12
