
核心词修正的Seq2Seq短文摘要
2018-12-22 07:39方旭,过弋,,,王祺,樊振
计算机工程与设计 2018年12期
方 旭,过 弋,,,王 祺,樊 振
(1.华东理工大学 信息科学与工程学院,上海 200237;2.石河子大学 信息科学与技术学院,新疆 石河子 832003;3.上海数据交易中心有限公司,上海 200436)
0 引 言
摘要包含了原始文本的核心信息,且篇幅不到原始文本的一半或者更少[1,2]。文本自动摘要技术是指通过计算机领域相关的理论和技术实现自动生成原始文本摘要的技术。传统的自动文本摘要方法有基于简单的统计方法、利用外部资源辅助确定重要句子的方法和基于修辞结构的方法等。然而,效果与人工摘要仍然有着不小的差距。进入21世纪,我们步入了一个大数据时代,互联网中的海量信息已经远远超出了人工处理的极限,自动摘要技术的研究越发的迫切和重要。随着机器学习技术在自然语言处理领域的广泛使用,使得自动摘要技术有了新的发展方向。最近几年,深度学习方法在语言生成上展现了巨大的潜力,让人们意识到离生成抽象的文本摘要又近一步,但是研究数量和深度还不够,还需要进一步深化。而且中文自动摘要技术发展较晚,在发展道路上还将面临着更多的挑战。
本文使用LSTM(long-short term memory net-work)构建了一个基于注意力机制的序列到序列模型,使用字词联合特征作为模型的输入,并根据原文的核心词来修正生成的摘要。最后在LCSTS(large scale Chinese short text summarization)数据集上进行了相关实验,实验结果表明了该方法的有效性。
1 相关工作
自动文摘技术起源于20世纪50年代,最早的自动摘要研究是通过统计简单直观的文本特征,一般来说有3种方法[3]:根据重要的单词来评分;根据句子的特征,比如位置和标题相似度来评分;分析句子之间的关系来打分。随着技术的发展,人们开始借助外部资源来辅助确定文档中的词权重,语义关系等来识别文档中的重要句子。比较著名的方法有Salon提出的TFIDF方法,该方法从一个全局的角度来确定词的权重。文献[4,5]都使用了该方法来寻找文本特征,从而进一步进行文本处理。此外研究人员根据词汇链特征来计算句子的评分[6]。20世纪90年代,在自然语言处理领域,开始广泛使用机器学习方法,尤其是有监督机器学习方法。使用人工标注的语料来训练句子特征和重要性的关系模型,就能够实现对未标注语料的重要性进行预测,生成摘要。Hinton等提出了深度置信网络和相应的高效学习算法。该算法无监督学习能力强,而且对人工的依赖比较低,训练高效,逐渐发展成了深度学习算法的主要框架[7]。目前深度学习方法应用广泛,其中序列到序列方法在机器翻译[8]、语言识别、视频字幕等研究上取得了很好的效果。IBM公司的Nallapati等[9]将基于注意力机制的递归神经网络(RNN)编解码器模型应用到了自动摘要研究中,效果优于现有的自动摘要方法。
中文自动摘要技术起步较晚,而且由于中文和英文的语法结构和表现形式有很大的差异,使得中文的相关信息处理研究变得比较复杂。最近几年,循环神经网络(RNN)在机器翻译[10],自动对话和语音识别上展现了强大的能力,然而很少有研究将其运用到文本自动摘要上。而且现有的大部分的中文自动摘要研究都是基于长文本的,而对于网络上的信息的核心载体短文本摘要的研究较少。相对于长文本而言,短文本的话题多,垃圾多,与社会背景关联性较强,而且还具有时效性,使得其自动摘要的研究更复杂。为了研究短文本自动摘要,Hu等[11]构建了一个大规模中文短文摘要数据集(LCSTS),并在该数据集上使用RNN构建序列到序列模型来生成摘要。
2 方法设计
在本节中,我们将详细描述我们的方法及模型。2.1小节介绍我们的整体架构。2.2小节将介绍基于注意力机制的序列到序列模型。2.3小节介绍所使用的特征的生成。在最后的2.4小节介绍核心词的选取以及是如何对生成的摘要进行修正的。
2.1 总体架构
在中文短文本摘要的研究中,只使用了字特征或词特征等单一特征,这些单一特征作为模型的输入是不够的,而且没有考虑使用抽取式方法来对生成式方法相进行优化。所以本文构建了一个使用字词联合特征作为输入的模型,并结合抽取式方法的思想,抽取出原文的核心词来対生成的摘要进行修正。模型如图1所示。首先,我们使用训练数据去训练神经网络,该神经网络是一个基于注意力机制的序列到序列模型,它的输入是短文本的字词联合特征,输出是短文本对应的摘要。由于生成的摘要会包含一些不完全或者错误的词,将这些词与从原文中抽取的核心词进行比较,使用相似的核心词来替换这些词,从而提高摘要的质量。

图1 总体架构
2.2 基于注意力机制的序列到序列模型
对于中文的短文本,我们可以很容易的想到它是由字、词和标点符号组成的一个有序的序列,而摘要则是这个有序序列中的核心信息。要生成这个短文本的摘要,则需要结合短文本的前后信息来推断或生成。
对于给定的短文本,X=x1,…,xn,我们使用神经网络的方式去计算在该输入X的情况下输出序列每一位置上各个字符出现的概率pyi|X,选取出每一个位置上最大概率的字符组合成最终的输出序列,Y=y1,…,yl。基于注意力机制的方法属于编解码器结构[1],如图2所示。在编码器和解码器中使用的都是长短期记忆网络LSTM,它的结构如图3所示。相比较于标准的循环神经网络RNN(recurrent neural network),它能够很好解决长期依赖问题。首先编码器读取短文本序列X=x1,…,xn,编码成一个隐性状态H=h1,…,hn,其长度和输入文本长度相同。然后,解码器根据隐性状态H得到相应的短文标题Y=y1,…,yl。而编码器和解码器是根据训练数据进行联合训练,模型的训练目标是最小化负对数似然函数的值
(1)
其中,S是训练集,ys是对应的中文短文本s的摘要文本,θ是神经网络中的所有参数集合。

图2 基于注意力机制的序列到序列模型
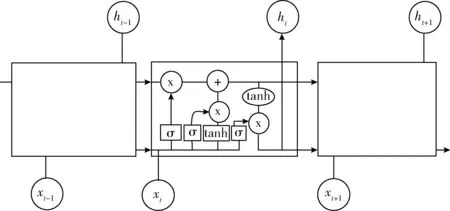
图3 LSTM结构

(2)

(3)
然后将正向与反向隐状态序列进行拼合得到编码器最终的隐形状态序列H=h1,…,hn,其中
(4)
而该模型的解码器是单向LSTM,其每一时刻的隐状态Si都由上一时刻的隐状态Si-1,上一时刻的输出yi和当前时刻的上下文向量Ci共同决定
Si=LSTMSi-1,yi,Ci
(5)
上下文向量在每一步解码时都会重新计算,计算时使用注意力机制实现软对齐:在i时刻解码时,通过一个前馈神经网络f,求出编码器在每一时刻的输出hi所对应的权重因子αij并以此对hi加权平均,得到i时刻的上下位向量Ci。其中权重因子αij决定了那些输入与当前时刻的解码最相关
eij=fsi-1,hj,yi-1
(6)
(7)
其中,eij是前馈神经网络f的激活输出,αij是对eij做了一个softmax归一化后的结果。
最后,解码器使用softmax计算每一个字符出现在t位置的概率pti
yt=Wht+bs
(8)
(9)
其中,WS∈RN×m是权重矩阵,N是所有可能出现的字符集的个数,m是hs的维数,bs是偏置向量,yti是yt的第i维元素,i∈1,N,分别代表着字符集中的每一个字符元素,t∈1,l,l是所要求输出的摘要的长度。
通过比较pti就可以得到t位置上最有可能出现的字符为maxpti所代表的字符yi,这样通过解码器我们就可以得到中文短文本的生成摘要Y=y1,…,yl。
2.3 输入特征
我们使用中文短文的字特征和词特征的联合特征作为神经网络的输入特征。字特征和词特征都是通过word2vec[12,13]生成的。word2vec是Google开园中的一款工具,它的核心是采用神经网络的方法,采用连续词袋模型和Skip-Gram两种模型将元素映射到同一坐标系,从而得出元素的数值向量。
如图4所示,字特征的生成向量的元素是字,根据短文中每个字的上下文关系,将每个字的关系映射到同一坐标系下。词特征生成特征向量的元素是词,我们需要先将中文文本进行分词,常用的分词工具有LTP和结巴分词等,将输入的短文本分割成一个个词语所组成的序列,然后根据词序列中的每个词的上下文关系来生成词的特征向量,如图5所示。
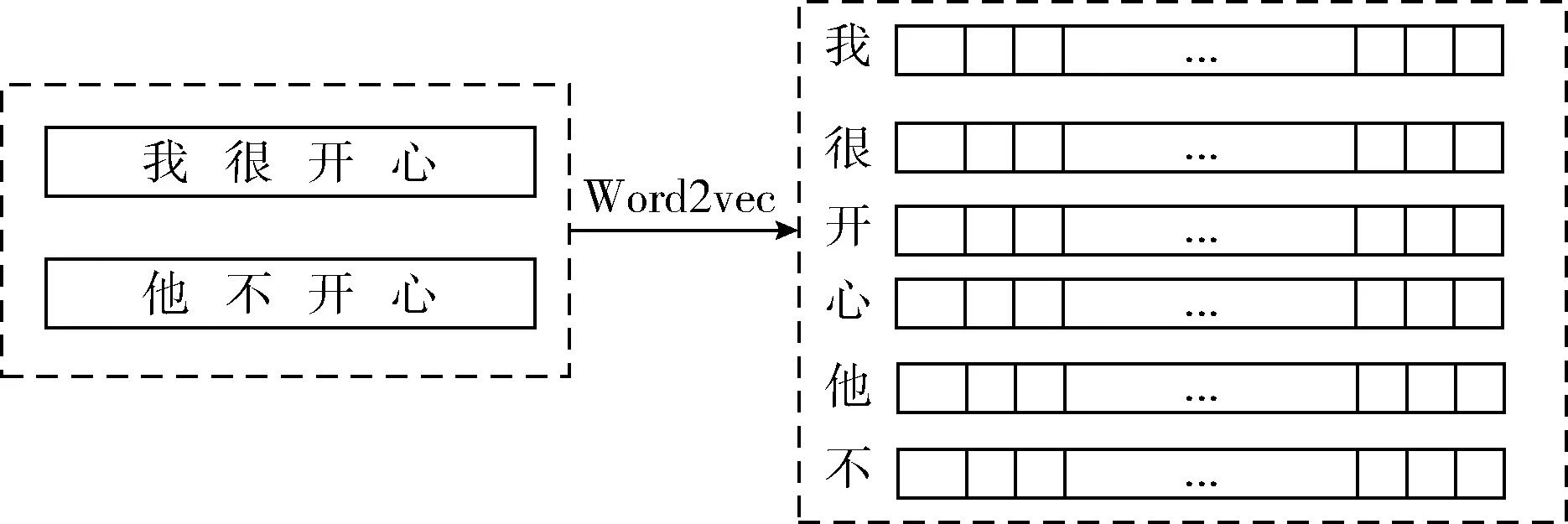
图4 字特征向量

图5 词特征向量
字词联合特征则是将字特征和词特征结合起来运用从而更好的代表输入文本的特征信息。结合的方式如图6所示,字词联合特征由输入文本的字特征和该字所在词的词特征前后连接组成,得到的字词联合特征的维度,等于字特征的维度和词特征的维度的和。
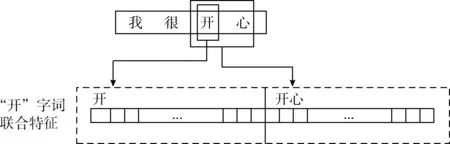
图6 字词联合特征
2.4 核心词替换
对于神经网络生成的摘要,一些原文中比较重要的词无法正确的生成,所以本文使用原文的核心词来対生成的摘要进行修正。
首先,需要从原文中识别出核心词。对于每一个短文本,停用词和表情符号等需要被去除,然后根据每个词的tf-idf的值来选取核心词,计算公式如下所示
(10)
(11)
tf-idft=tft×idft
(12)

得到每个输入的文本的核心词后,将生成的摘要使用相同的中文分词工具jieba来进行分词。将每一个词与核心词比较。如果该词是核心词的子串,就用核心词来代替该词。如果一个词是多个核心词的子串,那么就用式(13)来计算相似度,选择最大的核心词来替换

(13)
其中,Wordg代表生成的词,Kwordi是第i个核心词。fn是归一化函数。
3 实验过程及结果分析
3.1 LCSTS数据集
本文实验所采用的数据集是哈尔滨工业大学所构建的一个大规模中文短文摘要数据集LCSTS[11]。该数据集是从人民日报的微博上爬取短文以及该短文的摘要,然后进行人工打分整理而得到的。该数据集主要包含3个部分的短文数据。
Part I是该数据集的最主要的部分,它包含了2 400 591对短文和摘要。Part II包含了10 666对短文和摘要,并采用人工打分的方式对这些摘要评1~5分,分数越高表示摘要和短文越相关。Part III独立于Part I和Part II,只有1106对短文和摘要,可以用来作为测试集。本文在进行实验时考虑到效果和效率等因素,选取Part II作为实验的训练集,从Part III中选取了666条数据作为实验的测试集来进行实验。
3.2 评价指标
本文采用ROUGE评价方法来评价自动生成的摘要。ROUGE评价方法是由Chin-Yew Lin于2003年提出,该方法的主要思想是将自动生成的摘要和标准摘要进行比对,统计两个摘要之间的基本单元的数目来评价自动摘要的质量。文献[14]就使用ROUGE方法对他们的摘要进行了评分。我们使用ROUGE-1,ROUGE-2和ROUGE-L的评分来评价自动摘要的好坏。由于标准的ROUGE是用来评价英文摘要的,所以需要将中文摘要同意装换成数字编号序列,才能进行ROUGE评分。
3.3 实验过程
实验过程如图7所示。对于训练数据,一些特殊的字符需要被替换成特殊的标签。比如将表情替换成“Tag-BQ”等。然后根据字出现的频次,取前4000个字组成字的集合,并将它们从1开始编号。在对数据进行分词以后,以同样的方式取前60 000个词组成词的集合并从1开始编号。对于那些不在字集和词集中的字或词,全部替换成UNK。然后使用使用word2vec分别获得字和词的特征向量,向量的维度都是128维。将训练数据的字特征和词特征拼接成字词联合特征作为输入来训练神经网络模型,采用AdaDelta[15]方法进行梯度下降,神经网络的隐状态的长度为128。
测试数据使用相同的字集和词集,并提取出每一个短文本中tf-idf值较高的词组成他们的核心词集。将测试数据放入到神经网络模型中,就能得到一个生成的短文摘要,使用核心词对该摘要进行替换修正后,得到最终的生成摘要,并使用ROUGE方法对这个摘要进行评分。
3.4 对比实验
在文献[11]中,他们在LCSTS数据集上使用字特征和词特征进行了基于字特征和词特征的循环神经网络实验,发现基于字特征的实验结果要优于基于词特征的实验结果。但是他们没有联合IDF等特征来训练,也没有使用字词联合特征,而且没有使用一些方法来対生成的摘要质量进行提高。所以本文使用字词联合特征来进行实验,并提出使用原文的核心词来修正生成的摘要。为了验证本文方法的有效性,设计了以下对比实验。所有的实验将在相同的设备上进行,用ROUGE方法对实验结果进行评分。

图7 实验流程
(1)基于字特征的LSTM序列到序列模型。使用中文短文本的字特征作为神经网络的输入。
(2)基于词特征的LSTM序列到序列模型。使用中文短文本的词特征作为神经网络的输入。
(3)基于字词联合特征的LSTM序列到序列模型。使用中文短文本的字特征和词特征拼接后的联合特征作为神经网络的输入,包含了字特征和词特征的信息。
(4)分别将上述3个模型结合IDF特征作为神经网络的输入,对结果进行评分。
3.5 实验结果
在本节中,3.5.1是神经网络隐藏层参数对比实验,从而确定合适的隐藏层数量。3.5.2是各个模型生成摘要的评分对比实验。
3.5.1 神经网络隐藏层参数对比实验
本文采用的是基于注意力机制的序列到序列模型,在模型中需要设定隐藏层数量,通常使用的隐藏层数量为64,128和256层。为了确定隐藏层数量,在相同训练集下,设定不同数量的隐藏层,训练相同的轮次后,计算测试集结果ROUGE评分以及训练过程所耗的时间,得到的实验结果见表1。

表1 隐藏层对比实验结果
从表1中我们可以看出,随着隐藏层数的增加,训练所耗的时间也在不断地增加,但是从测试结果的ROUGE评分上,我们可以发现,当隐藏层数为128时,评分最好。因此模型的隐藏层数为128时效果最佳。
3.5.2 模型实验结果评分
表2是不同特征作为输入下的各个模型在测试集山生成的中文短文摘要ROUGE评分。

表2 实验结果ROUGE评分
由表2的评分结果我们可以看出,使用字特征的效果比使用词特征的效果要好,这也符合文献[11]的结论。在ROUGE-1和ROUGE-L上,字词联合特征的评分比字特征的评分要高0.005,在ROUGE-2上要高0.002。这说明使用字词联合特征比只使用字特征或词特征效果要好。此外,当这些特征结合IDF特征作为神经网络输入时,字特征有了较小的提高,而词特征和字词联合特征评分却降低了,说明直接链接IDF特征作为输入是不合适的。所以采用TF-IDF值选出核心词对字词联合特征的生成结果进行修正,通过ROUGE评分,可以发现,在这些实验中,同时使用字词联合特征和核心词修正方法的评分最高,与其它实验相比,它在各个指标,尤其是ROUGE-2上的评分都有较大提高。这样的结果说明本文的方法是有效的。
4 结束语
互联网已经成为了人们现实生活中必不可少的组成部分,在社交网络上,海量的短文本信息在用户之间互相传递。为了让人们能够更加方便快捷的获得这些短文本的信息,我们需要给这些短文本添加一个简短的摘要。本文使用LSTM构建了一个基于注意力机制的序列到序列的模型,采用短文本的字词联合特征作为输入来进行模型的训练与摘要的生成,再根据TF-IDF的值来选取原文的核心词,使用核心词对生成的摘要进行修正,提高摘要质量。最后我们在LCSTS数据集上进行了一些相关的实验,对实验结果进行了ROUGE评分。通过评分结果,验证了我们的方法是有效的。除此之外,本文对深度学习与传统方法的结合具有借鉴意义。在未来的工作中,我们将提高训练数据量,调整神经网络的结构,并尝试将更多的方法与深度学习方法相结合,使得生成的摘要效果更好。
猜你喜欢
军事文摘(2022年14期)2022-08-26
军事文摘(2022年14期)2022-08-26
军事文摘(2022年12期)2022-07-13
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
重型机械(2016年1期)2016-03-01
海军航空大学学报(2015年4期)2015-02-27
阅读与作文(英语高中版)(2013年12期)2013-12-11
