
基于OpenPose-slim模型的人体骨骼关键点检测方法
2019-01-06 07:27汪检兵李俊
计算机应用 2019年12期
关键词:肢体
汪检兵 李俊

摘 要:相較于2017年提出的在当时检测效果近乎最优的RMPE模型与Mask R-CNN模型,原用于人体骨骼关键点检测的OpenPose模型有着在保持精度近乎不变的情况下能大幅缩短检测周期的优势,但同时该模型也存在着参数共享率低、冗余度高、耗时长、模型规模太大等问题。针对上述问题,提出了新的OpenPose-slim模型。该模型减小网络宽度,减少卷积块层数,将原并列式结构改成序列式结构并于内模块加入Dense连接机制,其处理过程主要分为3个模块:1)关键点定位模块,检测出人体骨骼关键点的位置坐标;2)关键点联系模块,把关键点位置连接成肢体;3)肢体匹配模块,进行肢体匹配得到人体轮廓。每一个处理阶段之间关联紧密。在MPII数据集、COCO数据集和AI Challenger数据集上的实验结果表明,所提模型使用4个定位模块和2个联系模块,并于每一个模块内部使用Dense连接机制是最佳结构,与OpenPose模型相比,在保持检测精度基本不变的基础上,测试周期缩短为原来的近1/6,参数量缩小了近50%,模型规模缩小为近1/27。
关键词:人体骨骼关键点检测;姿态检测;肢体;Dense连接机制;序列式结构
中图分类号: TP183文献标志码:A
Human skeleton key point detection method based on OpenPose-slim model
WANG Jianbing1,2, LI Jun1,2*
(1. College of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan Hubei 430065, China;
2. Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System
(Wuhan University of Science and Technology), Wuhan Hubei 430065, China)
Abstract: The OpenPose model originally used for the detection of key points in human skeleton can greatly shorten the detection cycle while maintaining the accuracy of the Regional Multi-Person Pose Estimation (RMPE) model and the Mask Region-based Convolutional Neural Network (R-CNN) model, which were proposed in 2017 and had the near-optimal detection effect at that time. At the same time, the OpenPose model has the problems such as low parameter sharing rate, high redundancy, long time-consuming and too large model scale. In order to solve the problems, a new OpenPose-slim model was proposed. In the proposed model, the network width was reduced, the number of convolution block layers was decreased, the original parallel structure was changed into sequential structure and the Dense connection mechanism was added to the inner module. The processing process was mainly divided into three modules: 1) the position coordinates of human skeleton key points were detected in the key point localization module; 2) the key point positions were connected to the limb in the key point association module; 3) limb matching was performed to obtain the contour of human body in the limb matching module. There is a close correlation between processing stages. The experimental results on the MPII dataset, Common Objects in COntext (COCO) dataset and AI Challenger dataset show that, the use of four localization modules and two association modules as well as the use of Dense connection mechanism inside each module of the proposed model is the best structure. Compared with the OpenPose model, the test cycle of the proposed model is shortened to nearly 1/6, the parameter size is reduced by nearly 50%, and the model size is reduced to nearly 1/27.
Key words: human skeleton key point detection; attitude detection; limb; Dense connection mechanism; sequential structure
0 引言
随着人工智能(Artificial Intelligence, AI)时代的到来,描述人体姿态、预测人体行为的应用研究在不断进行。人体姿态检测,实现关键物体分析,自动还原人体姿态,在行为检测(利用深度学习技术可以精确检测人物异常行为)、行为识别(快速精确识别人体动作中的各种姿态)、视频捕捉(精确捕捉视频的精彩瞬间)和计算机图形学等领域都有着广泛的应用价值和丰富的业务场景。
在人体骨骼关键点检测的任务中,传统模型方法存在以下一些难题:1)每张图片的人数及出现位置不定,姿态各异,无法提前预知,给空间信息的获取带来困难;2)检测周期会随着识别人数的增加而不断变长;3)检测的鲁棒性不强,泛化能力差,无法将对人体的检测系统方便移植到其他的检测系统中。 Cao等[1]提出了最新的OpenPose模型,相较于到2017年为止检测性能各项指标近乎最优的RMPE(Regional Muti-person Pose Estimation)模型[2]和Mask R-CNN(Region-based Convolutional Neural Network)模型[3]有着在保持检测精度基本不变的情况下能够大幅度缩短关键点检测周期的优势,但是也存在着参数共享率低、冗余度高、耗时长、模型太大等不足之处。
本文在OpenPose模型[1]基础上进行改进,并提出了新的OpenPose-slim模型,对原模型的结构主要作出如下改进:1)减小网络结构的宽度;2)减少3×3卷积核,增加1×1卷积核,不仅可以缓和降维,而且可以突出非线性,减少计算量;3)改并列式结构为序列式结构,降低模型的复杂度;4)使用6个阶段(4个关键点定位阶段和2个肢体连接阶段);5)前4个阶段和后2个阶段分别使用Dense连接机制,大幅提高了参数之间的共享率,并降低了参数冗余度。在MPII数据集、COCO(Common Objects in COntext)数据集和AI Challenger数据集[4]上的实验结果表明,与OpenPose模型相比,所提模型在保持检测精度基本不变的基础上,测试周期缩短为原来的近1/6,参数量缩小了近50%,模型规模缩小为近1/27。
1 相关工作
传统的姿态检测算法是基于模板匹配的几何计算方法,关键是利用多种模板控件进行多维度建模做出适用性更强的模板以适配整个人体结构,但都是基于人工或简单算法实现的匹配,其工作量非常大,精度也很难达到预期要求。近几年来,姿态检测方法主要分为两类:自顶向下方式(顺序是先确定出人的位置,再检测每人的可见关键点)和自底向上方式(顺序是先检测可见关键点,再确定其属于哪个人)。近年来的姿态研究主要分为单人姿态研究和多人姿态研究。
单人姿态方面,Ke等[5]在视频多帧人体姿态检测系统研究中提出姿态检测本质上是检测模型的思想,组合两个AlexNet模型的特征图作为输出,使用简单数据增强的方法在
FLIC数据集上的实验结果表明相较于传统检测算法精度提高了5%;Newell等[6]提出Stacked Hourglass网络结构,将自顶向下方向的下采样与自底向上方向的上采样进行综合处理,每个漏斗样式的结构按照一定模式组合在一起,该模型以正确估计关键点比例PCKh(Percentage of Correct Keypoints of head)@0.5=90.9%的优异成绩在2016年MPII竞赛中暂居榜首。Chen等[7]对其做出了改进,采用生成对抗网络 (Generative Adversarial Network, GAN)的方法进行微调,整体精度提高0.2%。
多人姿态方面,不同于单人姿态,多人姿态另需考虑肢体匹配到人体的误差,比较好的多人姿态研究在单人姿态应用上的效果并不好。Rajchl等[8]提出了自顶向下的DeepCut网络结构,首先找出候选的关键点,使用空间联系优化算法得到每一对关键点属于哪个人,找到其内在联系;Insafutdinov等[9]又提出DeeperCut结构,添加残差模块,在MPII多人姿态数据集上表现出mAP(mean Average Precision)[10]为60.5%。Insafutdinov等[11]提出了名为ArtTrack的无约束多人跟踪模型,使用稀疏体简化图结构相较于DeeperCut不仅速度快20%,而且关键点匹配准确率高5%。2017年, Fang等[2]提出了自顶向下RMPE模型,多人姿态检测精度mAP [10]在MPII数据集上达到了76.7%;同年, He等[3]提出了自顶向下的Mask R-CNN新模型,该模型在实例语义分割任务中和关键点检测任务中表现优异,截至2017年,这两种模型检测评估结果近乎达到最优。后来, Cao等[1]提出了自底向上全新的OpenPose模型,使用一种对关键点联系的非参数表示方法——部分亲和字段(Part Affinity Fields, PAFs )方法 [1,12],完成了从关键点检测到肢体连接再到人体骨架的构建过程,相较于前两种模型,在MPII数据集和COCO数据集上的实验结果表明检测精度基本一致,但该模型在检测周期上表现出了不随人数的增加而延长的鲁棒性;但与此同时,該模型也存在参数共享率低、冗余度高、耗时长、模型太大等不足之处。2 OpenPose模型
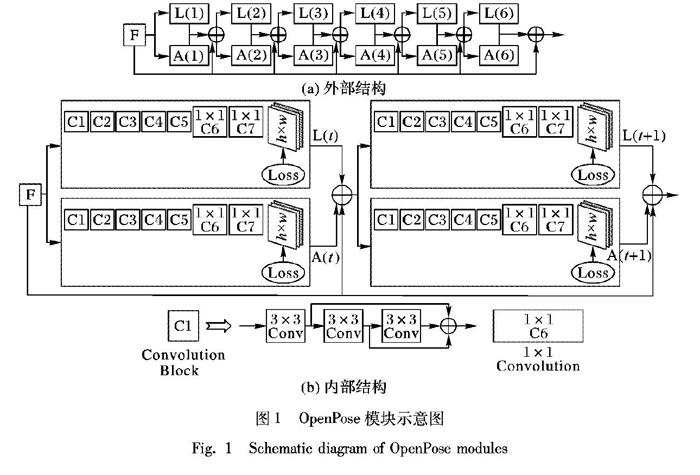
OpenPose模块示意图如图1所示。
图1(a)描述了OpenPose[1]的外部框架结构。首先,输入图片经过VGG-19结构的前10层得到特征图(feature map)F, 接着由特征图作为多阶段输入,每一个阶段分为两部分:一部分是Localization模块(图1中的L(·)部分),用于关键点定位;另一个是Association模块(图1中的A(·)部分),用于连接候选关键点组成连接肢体。大体结构共分为12(2×6)个阶段,过多阶段数会耗费更多计算资源,而且没有参数跨层共享机制,容易生成较多冗余数据。
图1(b)描述了OpenPose[1]内部网络层结构,其中Convolution Block部分是3个3×3卷积核所组成的小残差网络结构,每隔一层都有跳跃连接。为了在提取高层特征信息和空间纹理信息的同时,也不会使得底层的信息被全部忽略,于是将底层的特征信息与高层的特征进行一定程度上的连接,可解决层数过多时导致的梯度消失问题,使用多个3×3卷积核代替5×5或7×7卷积核也可一定程度上减少参数。其后使用1×1卷积核,不仅可用于升维和降维,并且可以增强非线性趋势,使得网络变得更深以提取更高层特征。
3 OpenPose-slim模型
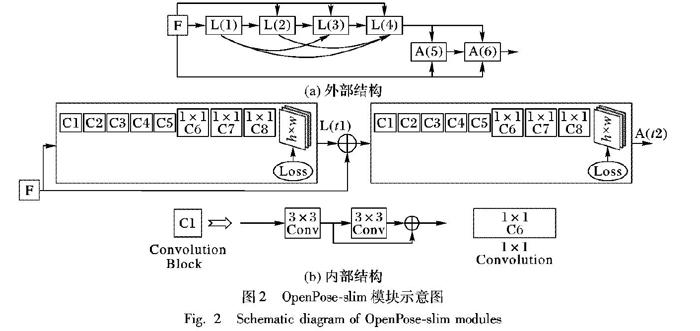
图2(a)描述了OpenPose-slim的外部框架结构,与OpenPose模型[1]在外部细节结构上大体相同,不同之处在于外部结构中使用序列式L-A结构,而不是并列式L-A结构,大体结构只有6个小阶段,相较于OpenPose模型[1]的12个大阶段而言,大幅减小了参数使用量,也缩短了检测处理时间;且参考文献[13-14]提出的DenseNet,在Localization模块和Assocation模块中分别使用Dense连接结构,如此能提高参数的共享性,减少参数冗余量和模型大小。如实验5.3节所示,在COCO数据集上的实验结果表明:总计使用6个阶段(分别在4个Localization阶段与2个Association阶段使用Dense连接机制)的效果最好,相较于(3-L,3-A)结构精度高,表明Localization的过程优化所需要的层数比Association所需的层数更重要;相较于(4-L,2-A)和(4-L(Dense),2-A)结构精度也略高,表明Dense连接对精度提高和参数传递很有帮助。后面的实验都是默认在基于6阶段(4-L,2-A)(Dense)的基础上进行。
图2(b)描述了OpenPose-slim模型的内部结构,在原OpenPose模型[1]基础上做出的改进是每个Convolution Block中去掉了一个3×3卷积核,并在L-Block和A-Block中添加一个1×1卷积核分别用于升维和降维。该模型是原OpenPose模型[1]的改进模型,在保持精度基本不变的前提下,大幅缩短了检测周期且缩小了模型规模。
表1详细描述了OpenPose-slim模型每一个阶段卷积核数目,R*与Y*分别代表左边的Convolution Block与右边的Convolution块,OUTPUT代表该阶段输出的通道数。由表1可知,Localization模块输出的通道数高达1408,Association模块输出的通道数只有896,最后Detector的输出通道数为(关键点数×关键点状态),即14×3=42。
4 模型整体研究过程
本文模型整体研究过程主要分为三个模块,如图3所示,分别是:Localization(关键点定位模块)、Association(关键点联系模块)和Matching(肢体匹配模块)。关键点定位模块主要是为了从图像数据中获取到每类候选关键点位置以及该关键点的置信度,关键点联系模块主要是为了从各个候选关键点中得到每一对异类关键点之间的候选肢体以及该肢体的置信度值,肢体匹配模块是在候选肢体中进行匹配以期选出合适的肢体构建整个人体的骨架。
4.1 Localization
模型输入端为彩色图像数据,从VGG-19的前10层提取高层特征信息得到特征图Feature map,接着输入到用作关键点分类和回归的模型L(t)中,再经过非极大值抑制 (Non-Maximum Suppression, NMS)算法[15]得到离散化的候选关键点集合和每个候选关键点的置信度图Confidence map,每一个关键点的置信度图分为x与y两个方向上的向量,包括x方向上的向量信息和y方向上的向量信息,两个方向上的合向量表示该关键点的置信度Confidence。除此之外,还有对每一个关键点的定位信息。
4.2 Association
根据从关键点定位阶段输出的每个候选关键点相对于第j号关键点的置信度,输入A(t)中经过PAFs算法[1,12]处理得到每一对候选关键点之间的候选肢体集合及每条候选肢体的置信度图。
首先,计算任意一点p在肢体c上的置信度,如式(1)所示:如果点p在肢体c上,则点p相对于肢体c的置信度为肢体c方向上的单位向量;否则为零向量。其中,判断点p是否在肢体c上的方法如图4(a)和式(2)~(3)所示。
Ac(p)=ν, 点p在肢体c上
0,其他 (1)
0≤ν·(p-xj1)≤lc(2)
|νT·(p-xj1)|≤σc(3)
其中: j1与j2为两个不同类的关键点;定义ν向量为从j1指向j2方向上的单位向量,νT向量为ν向量的垂直向量;lc为肢体c的长度;σc为肢体c的宽度;xj1表示候选关键点j1的位置坐标。
接着,使用定积分求出肢体c上所有点的置信度图和代表肢体c的置信度Ec,由肢体c上所有点置信度在c上求定积分后单位化所得,目的是为了在后面作匹配的时候可以统一度量,如式(4)~(5):
Ec=∫u=1u=0Ac(p(u))·dj2-dj1‖dj2-dj1‖2 du(4)
p(u)=(1-u)·dj1+u·dj2(5)
式中:p(u)代表取遍j1到j2之间的任意一点,其中0≤u≤1。
4.3 Matching
獲得每一条肢体置信度后,就按照某一种方案去作匹配,本文提供两种匹配方案,分别是全连接匹配方式和最大二分图匹配方式。将匹配结果中所有肢体置信度求和,找出最大的匹配结果为最终的候选匹配集合。
三类关键点之间的两种匹配方案如图4(b)所示,图中左右框代表两个人,每一组关键点之间四条线(粗实线和细虚线)中的某一种线是一种匹配结果,其中粗实线是正确匹配方式,细虚线是错误匹配方式。全连接匹配方式是四条线全部考虑在内的匹配方式,而最大二分图匹配方式是粗实线或细虚线的两条线匹配方式,它要求任意两条线没有公共节点。所以,含有公共点的细虚线是错误的匹配方式,其边权和Ec为0;粗实线是正确的匹配方式,其边权和Ec为2ν。
不同模型在COCO数据集上的测试结果如图5所示。图5(a)是四种模型随着关键点数目增加而引起的mAP[10]指标在关键点上的平均加权变化曲线,图中OpenPose-slim的关键点检测数目略小于OpenPose模型[1] ,其检测的mAP[10]指标相较于OpenPose模型[1]仅差0.01。图5(b)是四种模型随着帧数不断增加而计算出的FPS指标的平均加权变化曲线,OpenPose-slim模型的FPS指标约是OpenPose模型[1]的5倍,且不会随着检测帧数的增加而明显减小(即检测周期明显变长),而Mask R-CNN模型[3]与RMPE模型[2]会随着检测帧数的变化而导致检测周期变长。
5.3 结构对比实验
不同阶段数分配方案的结果对比如表5所示。表5结果表明:6个Stages(4个的Localization 模块和2个Association模块分别使用Dense连接)效果最佳。由Stages=3和Stages=4所知,当Stages使用较少时,表现出精度明显不够的情况;但是当Stages过多时,如Stages=7,mAP [10]表现出下降趋势。宏观方面,原因是:随着阶段越来越多,后面的阶段会不断作局部参数优化,而导致“断层”现象,即高层特征提取器提取的信息和低层特征提取器提取的信息不能综合起来,将阈值设置为0.90,则对于更高层信息的获取就更难,表现出平均精度(AP)也会下降得非常大。微观方面,原因是:随着阶段数的增加,梯度容易消失,在反向传播过程中,参数更新非常细微以至于没有变化,即使使用一定的残差结构,但也只能解决部分问题,其根本性问题还是没有完全解决。实验结果中,使用(4-L 2-A)(Dense)结构比包括(4-L 2-A)和(4-L(Dense) 2-A)在内的其他结构效果都好,表明Dense结构对参数的共享效果相较于普通的残差神经网络ResNet(Residual Network)要好,对精度的提高也会表现得更优异。
5.4 系统不足
如图6所示,OpenPose-slim模型也存在一些表现不足的问题:1)图6(a)中,站在前面的人的手无法检测出来,而被误判为后面的人手;图6(b)中,左右手错乱交叠在一起,模型没能准确区分开。2)图6(c)和图6(d)中,人与人形雕塑出现判误问题。
6 结语
本文提出的人体骨骼关键点检测OpenPose-slim模型,是在先前研究的OpenPose模型[1]基础上进行的改进,可对人体骨骼关键点进行精准定位,并以连线的方式将人物的动作用计算机的视觉呈现出来。本文主要解决了以下问题:1)对原模型OpenPose[1]做出多处改进,在保证精度基本不变的情况下,大幅提高了时间效率,减少了参数计算量,缩小了模型规模,进一步满足了严任务高需求。2)从模型结构角度分析使用何种模型结构对本文模型最有利,实验分析得出,使用Dense连接的6个阶段(4个关键点定位阶段+2个肢体连接阶段)最为合适,不仅精度达到了最高要求,而且耗时相对较短。3)本文从三个大阶段去分析整个姿态检测的过程,包括关键点定位阶段、关键点联系阶段和肢体匹配阶段,这三个阶段紧紧相连、相互制约、相互影响。
與此同时,该检测系统也存在一些局限性,有些问题没有给出较好的解决方案:1)不足案例表现出多种待解决问题,如多姿态杂乱的图片中肢体交叠在一起的问题,人物和人形雕塑无法分辨问题,占比面积较小的人体关键点无法精准定位和检测问题等。2)阶段数过多会导致设备内存溢出,故在结构分析过程中只设计到7个阶段,受到设备硬件要求,只能暂时对3~7个阶段进行分析对比,找到局部性最优解。3)随着Slim-Block的不断增多和层数的不断深入,使用DenseNet连接结构的复杂性带来高精度和参数共享优化的同时也会带来参数传递的冗余问题。4)模型仅限于有大量优质数据集的人体姿态检测,对无大量优质数据集的其他类别无法完成检测。5)模型规模还是偏大,仍然有可缩小优化的空间。
针对以上5个问题,接下来分别可从以下方向进行研究:1)由于本文所述的关键点匹配方案存在由多节点姿态形式各异导致的关键点与其他人关键点之间出现错配问题时有发生,可以从关键点匹配阶段对模型进一步优化。2)可使用更优的GPUs计算资源进行实验,找到该模型的最优结构。3)Veit等[20]提出新的可行的Adaptive-Inference领域,对于不同的应用,通过合适的自适应推理算法获得最合适的模型。4)可在GAN研究领域和半监督学习与无监督学习[21]研究领域做到高质量数据增强效果,给姿态研究领域乃至深度学习领域的数据问题做出根本性贡献。5)在保持精度和耗时基本不变的前提条件下或在满足基本要求的范围内,将模型慢慢做小,以适用于更底层的超低内存容量,应用在高需求的芯片硬件设备应用场景,比如自动监控等基础设施中。
参考文献 (References)
[1]CAO Z, HIDALGO G, SIMON T, et al. OpenPose: realtime multi-person 2D pose estimation using part affinity fields [EB/OL]. [2018-12-30]. https://arxiv.org/pdf/1812.08008.pdf.
[2]FANG H, XIE S, TAI Y W, et al. RMPE: regional multi-person pose estimation [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2353-2362.
[3]HE K, GKIOXARI G, DOLLR P, et al. Mask R-CNN [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988.
[4]WU J, ZHENG H, ZHAO B, et al. AI challenger: a large-scale dataset for going deeper in image understanding [EB/OL]. [2018-12-30]. https://arxiv.org/pdf/1711.06475.pdf.
[5]KE L, QI H, CHANG M C, et al. Multi-scale supervised network for human pose estimation [C]// Proceedings of the 2018 IEEE International Conference on Image Processing. Piscataway: IEEE, 2018: 564-568.
[6]NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 483-499.
[7]CHEN Y, SHEN C, WEI X, et al. Adversarial PoseNet: a structure-aware convolutional network for human pose estimation [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 1212-1230.
[8]RAJCHL M , LEE M C H, OKTAY O , et al. DeepCut: object segmentation from bounding box annotations using convolutional neural networks [J]. IEEE Transactions on Medical Imaging, 2017, 36(2): 674-683.
[9]INSAFUTDINOV E, PISHCHULIN L, ANDRES B, et al. DeeperCut: a deeper, stronger, and faster multi-person pose estimation model [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9910. Cham: Springer, 2016: 34-50.
[10]HENDERSON P, FERRARI V. End-to-end training of object class detectors for mean average precision[C]// Proceedings of the 2016 Asian Conference on Computer Vision, LNCS 10115. Cham: Springer, 2016: 198-213.
[11]INSAFUTDINOV E, ANDRILUKA M, PISHCHULIN L, et al. ArtTrack: articulated multi-person tracking in the wild [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1293-1301.
[12]ZHU X, JIANG Y, LUO Z. Multi-person pose estimation for posetrack with enhanced part affinity fields [EB/OL]. [2018-12-30]. https://posetrack.net/workshops/iccv2017/pdfs/ML_Lab.pdf. // Proceedings of the 2017 IEEE International Conference on Computer Vision PoseTrack Workshop. Cham: Springer, 2017,1-4.
[13]HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269.
[14]黃奕晖,冯前进.基于三维全卷积DenseNet的脑胶质瘤MRI分割[J].南方医科大学学报,2018,38(6):661-668.(HUANG Y H, FENG Q J. Segmentation of brain tumor on magnetic resonance images using 3D full-convolutional densely connected convolutional networks [J]. Journal of Southern Medical University, 2018, 38(6): 661-668.)
[15]HOSANG J, BENENSON R, SCHIELE B. Learning non-maximum suppression [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6469-6477.
[16]李默涵,王宏志,李建中,等.一种基于二分图最优匹配的重复记录检测算法[J].计算机研究与发展,2009,46(S2):339-345.(LI M H, WANG H Z, LI J Z, et al. Duplicate record detection method based on optimal bipartite graph matching [J]. Journal of Computer Research and Development, 2009, 46(S2): 339-345.)
[17]WANG Z, FENG Z, ZHANG P. An iterative Hungarian algorithm based coordinated spectrum sensing strategy [J]. IEEE Communications Letters, 2011, 15(1): 49-51.
[18]PAPANDREOU G, ZHU T, KANAZAWA N, et al. Towards accurate multi-person pose estimation in the wild [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3711-3719.
[19]黃龙,杨媛,王庆军,等.结合全卷积神经网络的室内场景分割[J].中国图象图形学报,2019,24(1):64-72.(HUANG L, YANG Y, WANG Q J, et al. Indoor scene segmentation based on fully convolutional neural networks [J]. Journal of Image and Graphics, 2019, 24(1): 64-72.)
[20]VEIT A, BELONGIE S. Convolutional networks with adaptive inference graphs [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11205. Cham: Springer, 2018: 3-18.
[21]徐毅琼,葛临东,王波,等.基于非监督学习神经网络的自动调制识别研究与实现[J].计算机应用与软件,2011,28(1):79-81,95.(XU Y Q, GE L D, WANG B, et al. On automatic modulation recognition based on unsupervised learning neural networks and its implementation [J]. Computer Applications and Software, 2011, 28(1): 79-81, 95.)
This work is partially supported by the National Natural Science Foundation of China (61572381), the Fund from Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System (Wuhan University of Science and Technology) (znxx2018QN06).
WANG Jianbing, born in 1998. His research interests include computer vision, adaptive reasoning.
LI Jun, born in 1978, Ph. D., associate professor. His research interests include intelligent computing, machine learning.
收稿日期:2019-06-06;修回日期:2019-07-30;录用日期:2019-07-31。基金项目:国家自然科学基金资助项目(61572381);武汉科技大学智能信息处理与实时工业系统湖北省重点实验室基金资助项目(znxx2018QN06) 。
作者简介:汪检兵(1998—),男,江西九江人,CCF会员,主要研究方向:计算机视觉、自适应推理; 李俊(1978—),男,湖北黄石人,副教授,博士,主要研究方向:智能计算、机器学习。
文章编号:1001-9081(2019)12-3503-07DOI:10.11772/j.issn.1001-9081.2019050954
猜你喜欢
健康护理(2022年3期)2022-05-26
VOGUE服饰与美容(2022年3期)2022-02-21
青年文学家(2020年28期)2020-11-02
疯狂英语·新阅版(2020年9期)2020-10-09
疯狂英语·读写版(2020年8期)2020-08-24
疯狂英语·读写版(2020年8期)2020-08-24
第一财经(2019年6期)2019-06-25
学校教育研究(2018年20期)2018-05-14
诗潮(2018年3期)2018-03-26
海外英语(2013年5期)2013-08-27
