
生成对抗残差网络的医学图像融合算法
2019-01-06 07:27高媛吴帆秦品乐王丽芳
计算机应用 2019年12期
高媛 吴帆 秦品乐 王丽芳

摘 要:针对传统医学图像融合中需要依靠先验知识手动设置融合规则和参数,导致融合效果存在不确定性、细节表现力不足的問题,提出了一种基于改进生成对抗网络(GAN)的脑部计算机断层扫描(CT)/磁共振 (MR)图像融合算法。首先,对生成器和判别器两个部分的网络结构进行改进,在生成器网络的设计中采用残差块和快捷连接以加深网络结构,更好地捕获深层次的图像信息;然后,去掉常规网络中的下采样层,以减少图像传输过程中的信息损失,并将批量归一化改为层归一化,以更好地保留源图像信息,增加判别器网络的深度以提高网络性能;最后,连接CT图像和MR图像,将其输入到生成器网络中得到融合图像,通过损失函数不断优化网络参数,训练出最适合医学图像融合的模型来生成高质量的图像。实验结果表明,与当前表现优良的基于离散小波变换(DWT)算法、基于非下采样剪切波变换(NSCT)算法、基于稀疏表示(SR)算法和基于图像分类块稀疏表示(PSR)算法对比,所提算法在互信息(MI)、信息熵(IE)、结构相似性(SSIM)上均表现良好,最终的融合图像纹理和细节丰富,同时避免了人为因素对融合效果稳定性的影响。
关键词:医学图像融合;生成对抗网络;计算机断层成像(CT)/磁共振(MR);层归一化;残差块
中图分类号: TP391.4文献标志码:A
Medical image fusion algorithm based on generative adversarial residual network
GAO Yuan, WU Fan*, QIN Pinle, WANG Lifang
(School of Big Data Science, North University of China, Taiyuan Shanxi 030051, China)
Abstract: In the traditional medical image fusion, it is necessary to manually set the fusion rules and parameters by using prior knowledge, which leads to the uncertainty of fusion effect and the lack of detail expression. In order to solve the problems, a Computed Tomography (CT)/ Magnetic Resonance (MR) image fusion algorithm based on improved Generative Adversarial Network (GAN) was proposed. Firstly, the network structures of generator and discriminator were improved. In the design of generator network, residual block and fast connection were used to deepen the network structure, so as to better capture the deep image information. Then, the down-sampling layer of the traditional network was removed to reduce the information loss during image transmission, and the batch normalization was changed to the layer normalization to better retain the source image information, and the depth of the discriminator network was increased to improve the network performance. Finally, the CT image and the MR image were connected and input into the generator network to obtain the fused image, and the network parameters were continuously optimized through the loss function, and the model most suitable for medical image fusion was trained to generate the high-quality image. The experimental results show that, the proposed algorithm is superior to Discrete Wavelet Transformation (DWT) algorithm, NonSubsampled Contourlet Transform (NSCT) algorithm, Sparse Representation (SR) algorithm and Sparse Representation of classified image Patches (PSR) algorithm on Mutual Information (MI), Information Entropy (IE) and Structural SIMilarity (SSIM). The final fused image has rich texture and details. At the same time, the influence of human factors on the stability of the fusion effect is avoided.
Key words: medical image fusion; Generative Adversarial Network (GAN); Computed Tomography (CT)/ Magnetic Resonance (MRI); layer normalization; residual block
0 引言
在臨床诊断和治疗中,医学图像是确定病灶位置的重要判断依据,但单模态医学图像无法达到成像结果全面、清晰,且分辨率高的效果[1-3]。通过将多模态医学图像进行融合,可以解决单模态医学图像信息不足的问题,提高疾病准确诊断和治疗的效率。融合后的医学图像能够准确地表达源图像的细节特征,最大限度地保留多模态源图像信息[4]。
图像融合是一种增强技术,可以将同一场景的多幅图像或序列探测图像合成一幅信息更丰富、全面的图像。医学图像融合主要是以多尺度变换[5]、稀疏表示[6]和脉冲耦合模型[7]等为主的传统方法。多尺度变换将源图像进行分解重构,分解为高频图像和低频图像,再根据各自特点设置融合规则;但由于不同的滤波器其尺度和方向上的参数性能不同,使得融合效果的稳定性受人为因素影响较大[8]。稀疏表示通过字典对源图像进行稀疏编码,得到稀疏系数,再设置一定的融合规则对系数进行融合,最后重构得到融合图像;由于该算法对单个图像块进行编码,存在算法计算效率低且融合后图像信息丢失严重的问题[9]。脉冲耦合模型具有独特的全局耦合性和脉冲同步性;但该模型复杂,运行速率不高,且现有的理论无法解释参数如何设置能达到最优的融合效果[10]。综上所述,传统方法往往需要手动设置复杂的活动水平度量和融合规则,并通过先验知识进行参数初始化,存在融合效果不稳定、模型复杂、运行速率低的问题[11]。近年来,在图像处理领域深度学习比传统方法具有更强的特征捕获能力[12]。而神经网络是一种端到端的模型,并能够避免传统方法中先验知识影响融合效果的问题。其中生成对抗网络(Generative Adversarial Network, GAN)在图像生成方面具有突出的效果,实际应用于图像生成[13]、图像修补[14]、草稿图复原[15]等领域,本文通过对GAN网络模型的改进,能够提高融合效果的稳定性并提高运算速度。
本文在医学图像融合方面提出了一种残差生成对抗网络(Residual Generative Adversarial Network, Res-GAN)。首先,基于医学图像特征丰富、纹理信息复杂的特征,对生成对抗网络中的生成器和判别器两部分的网络结构进行构建。生成器的目的是生成同时具有电子计算机断层扫描(Computed Tomography, CT)和磁共振(Magnetic Resonance, MR)或MR和单光子发射计算机断层成像(Single-Photon Emission Computed Tomography, SPECT)两种图像信息的融合图;判别器的目的是通过训练促使生成器达到最优权重,达到最终融合图像最大限度地保留源图像信息,准确地展现细节特征的目的。
1 相关工作
1.1 生成对抗网络模型
Goodfellow等[16]首先提出了GAN的概念,在深度学习领域引起广泛的研究热潮。GAN在训练期间通过直接进行采样和推断,使GAN的应用效率提升,其强大的图像生成能力在实际应用场景有着广泛的应用。GAN的基本框架如图1所示。
GAN是同时训练两个模型:一个是用来捕获数据分布的生成器模型(Generative, G),一个是用来估计样本的判别模型(Discriminative, D)。G和D在对抗的框架下进行学习,D对真实数据进行建模,使得G避免了这些步骤直接学习去逼近真实数据,在任意函数G和D的空间中存在唯一的解,使最终生成数据达到D无法区分真伪的效果。GAN在优化过程中,由G和D构成了一个动态的“博弈过程”,其模型优化函数如式(1)所示:
优化函数由两项构成:x 表示真实目标图像,z表示输入G的噪声;G(z)表示G生成的图像,D(x)表示D判断真实目标图像为x的概率,D(G(x))表示D判断G(z)为图像x的概率。为了学习生成器关于数据x上的分布Pg(x),定义输入噪声的先验变量Pz(z),然后使用G(z;θg)来代表数据空间的映射。这里G是一个由含有参数θg的多层感知机表示的可微函数,多层感知机D(x;θd)用来输入一个单独的标量。D(x)代表x来自于真实数据分布而不是Pg(x)的概率,同时训练G来最小化lg(1-D(G(z)))。
原始的GAN模型主要目的是拟合出相应的生成和判别函数以生成图像,并没有对生成器和判别器的具体结构作出限制。由于深度学习神经网络在图像处理方面取得的显著成绩[17],本文设计生成器和判别器均采用神经网络模型,同时为了更好地保留源图像的细节信息,在融合过程中要尽可能地在每一层传输的过程中减少信息的丢失,以在融合图像中保留更丰富的信息。
1.2 残差网络模型
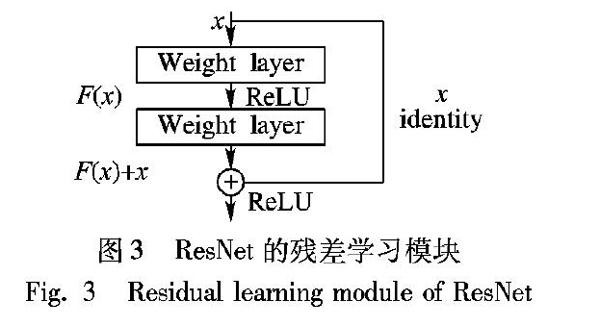
由He等[18]提出的ResNet(Residual Neural Network),通过使用残差块(Residual Block)成功训练出了152层的神经网络,该结构可以极快地加速神经网络的训练,模型的准确率也有较大的提升。ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。在此之前的网络结构是层与邻近层之间连接对输入进行非线性变换,ResNet的思想允许原始输入信息直接传到后面的层中,其网络结构如图2所示。
传统的卷积网络或者全连接网络在信息传递时不可避免会存在信息丢失、损耗等问题;同时在层数过多的情况下,引发梯度消失或者梯度爆炸等问题,导致网络无法训练。ResNet通过在原始的卷积层上增加跳跃连接支路(Skip Connection)以构成基本残差块,使H(x)的学习被表示H(x)=F(x)+x;同时残差块结构的累加,在一定程度上解决了梯度消失或者梯度爆炸等问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别的那一部分,简化了学习目标和难度,如图3所示。
残差网络的Residual Block和Skip Connection结构,改善了网络深度增加带来的梯度消失和网络退化的问题,提升了深度网络的性能。鉴于残差网络结构近年来在图像生成领域上的优异成绩,本文将残差块引入生成器部分的网络结构。
2 Res-GAN的医学图像融合策略
2.1 融合过程
Res-GAN算法,对融合过程中的权重进行自适应,需要输入目标图作为网络对最优融合效果的评判标准。所以,对已配准好的医学图像进行融合的步骤为:
1)从数据库中取出500对CT和MR图像得到图像集{Ici,Imi},其中:下标c表示CT图像,下标m表示MR图像,下标i表示第i对图像。
2)选择当前效果优良的6种图像融合方法:基于卷积稀疏的形态成分分析(Convolutional Sparsity based Morphological Component Analysis, CS-MCA)算法 [19];基于离散分数小波变换(Discrete FRactional Wavelet Transformation, DFRWT)[20]算法;基于离散小波变换 (Discrete Wavelet Transformation, DWT)算法[21];基于非下采样剪切波变换(NonSubsampled Contourlet Transform, NSCT)算法[22];基于稀疏表示(Sparse Representation, SR)算法[23];基于图像分类块稀疏表示(Sparse Representation of classified image Patches, PSR)算法[24]对数据集中的每对图像进行融合,得出融合图像构成融合图像集{f j1, f j2,…, f j500},其中上标j表示第j种融合方法。
3)采用互信息(Mutual Information, MI)、信息熵(Information Entropy, IE)、结构相似性(Structural SIMilarity, SSIM)、空间频率(Spatial Frequency, SF)、平均梯度(Average Gradient, AG)、标准差(Standard Deviation, SD)、对比度(Contrast, C)、峰值信噪比(Peak Signal-to-Noise Radio, PSNR)、相关系数(Correlation Coefficient, CC)、边缘信息保留值(Edge Information Preservation Vlaues, EIPV)10种评价指标,对融合图像集进行评价并进行统计,选择客观指标评价最优的2500张融合图作为目标图组成训练集If。
4)使用Res-GAN的医学图像融合算法进行训练,在通道维度中连接CT图像Ic和MR图像Im,然后将连接图像输入到生成器G中,同时将目标图像If输入到判别器D中,训练过程如图4所示。
2.2 改进思想
在网络结构方面,本文将生成对抗网络应用到图像融合领域,为了更好地保留图像细节信息,减少信息在每一层传输过程中的丢失,本文在传统的GAN模型基础上,采用残差学习框架,让堆叠层拟合残差映射,而不是直接拟合所需的底层映射。针对特征图维度翻倍以及删除构建块后造成分类误差显著增加的问题[25],采用具有金字塔结构的残差网络[26],如图5所示。通过在构建网络的过程中去掉下采样单元以减少图像信息的丢失,同时逐渐增加特征图的维度,使受下采样单元影响的部分均匀地分布在所有单元上,从而使网络在删除下采样单元时性能不会显著下降。
由于CT与MR图像都是灰度图,所有的输入都在同一个区间范围内,经过批量归一化(Bach Normalization, BN)层均值归零、方差归一的算法,拉伸图像的对比度,忽略图像的像素信息只考虑相对差异,会破坏源图像的对比度信息[27],从而影响网络输出的质量。本文为了更好地保留源图像的对比度信息,引入层归一化(Layer Normalization, LN),它在计算得到某层的平均输入值和输入方差时包含该层所有维度输入,最后通过同一个规范化操作来达到转换各个维度輸入的目的[28]。LN针对单个样本进行训练,有效解决了BN受mini-batch数据分布影响的问题;另外,由于它不需要保存mini-batch的均值和方差,可以在很大程度上节省额外的存储空间。
2.3 Res-GAN算法网络结构
由2.1节所述的改进思想,将改进的措施应用到本文的Res-GAN算法中,设计的整个网络结构如图6所示。
2.3.1 生成器
生成器的目的在于提取更多、更深层次的图像特征生成新的融合图像,其网络结构如图6(a)所示。首先,对输入图像进行卷积操作,先进入3×3×3×64的卷积层,即输入为3通道、输出为64通道的3×3的滤波器,设置步长为1,并通过零填充使图片在卷积过程中保持大小不变。其次,两层3×3的滤波器构成一个残差块,通过残差块的堆叠来提取深层次特征,将残差块的数量增加到32个,加深了网络深度。为了最大化地保存源图像中的细节信息,只引入卷积层而不进行下采样;使用线性整流单元(Rectified Linear Unit, ReLU)优化网络性能[29];BN转换的思想是使经过平移和缩放后的不同神经元的输入分布于不同的区间,而LN对于同层的神经元训练可得到同一个转换,从而用LN层替换传统的BN层。最后,采用3×3的滤波器融合深层次特征和快捷连接输入的浅层次特征,采用1×1的滤波器将通道降为3通道,输出融合图像。
2.3.2 判别器
判别器与生成器不同,其根本目的在于分类,先从图像中提取特征,然后进行分类。如图6(b)所示,判别器是简单的卷积神经网络结构。通过4层5×5的滤波器进行卷积操作来提取图像特征,同时为了减小去掉下采样单元引起的图像信息的丢失,逐层增加特征图的通道数,从第一层输入3通道、输出64通道,每层通道数以两倍速度递增,一直增加到输入第4层输入256通道、输出512通道。然后,通过3×3的滤波器的卷积层逐渐降低通道数,且同生成器一样,激活函数采用ReLU。最后,通过全连接层(Fully Connect layer, FC)进行分类,采用Sigmoid函数输出判别的结果。
2.3.3 损失函数
本文算法的损失函数由生成器的损失函数和判别器的损失函数两部分组成,旨在最小化损失以达到训练目的,如式(2)所示:
LRes-GAN={min(LG),min(LD)}(2)
其中:LG为生成器的损失函数,LD为判别器的损失函数,总损失函数LRes-GAN的目的在于最小化LG和LD。
生成器损失LG是生成器和判别器之间的对抗损失V和图像生成过程中的内容损失C之和,α用于在V和C之间取得平衡。采用最小二乘法,其实质是最小化“均方误差”,通过最小化误差的平方和寻找数据的最佳函数匹配,并使得求得的数据与实际数据之间误差的平方和最小,能够使损失函数快速收敛,训练过程更加稳定。
式(4)中:Inf表示融合目标图,其中n∈{1,2,…,N},N表示融合图像的数量;D(Inf)表示分类结果;a表示判别器识别虚假数据为真的标签。式(5)中:H、W分别表示输入图像的高和宽;第一项‖·‖F代表矩阵范数,目的在于将CT图像Ic的信息保留在融合图像If中;第二项表示梯度算子,目的在于保留MR图像Im的细节信息;β是控制两项之间权值的正参数。
判别器损失LD,由MR图像和融合目标图像的分类结果与其对应的真值标签求均方误差之和得到。
LD=1N∑Nn=1(D(Im)-b)2+1N∑Nn=1(D(If)-c)2(6)
其中:D(Im)和D(If)分别表示MR图像和融合目标图像的分类结果;b和c分别表示各自的真值标签。
3 仿真实验与结果分析
本文实验使用的是美国哈佛医学院(Harvard Medical School)的数据集,全脑图谱由Keith A.Johnson和J.Alex Becker创建,提供正常脑和一些常见疾病的脑部图像。选取出清晰度高、纹理丰富、细节复杂的高质量CT和MR图像,为了方便训练,将图像均进行归一化。
本实验环境由硬件环境和软件环境构成,硬件环境为测试实验所用的Intel Xeon服务器,搭载2块NVIDIA Tesla M40的GPU,显存共24GB(12GB×2);软件环境为64位Ubnutu 14.04.05 LTS操作系统,Tensorflow V1.2,CUDA Toolkit 8.0,Python 3.5。
3.1 融合效果
以正常脑部、脑弓形虫和脑萎缩的三组CT和MR图像,失智症和胶质瘤的两组MR和SPECT图像为例对本文算法融合效果进行展示。为了验证本文融合算法的医学图像融合效果,选取在医学图像融合领域表现良好的基于DWT算法[21]、基于NSCT算法[22]、基于SR算法[23]、基于PSR算法[24]这四种传统算法与本文算法进行对比。基于DWT算法对两个输入源图像进行小波变换,融合小波系数的融合规则采用基于区域能力最大的融合规则和一致性校验,对融合后的小波系数进行逆小波变换得到融合图像[21]。基于NSCT算法是充分利用NSCT和脉冲耦合神经网络(Pulse Coupled Neural Network, PCNN)的优点所提出的图像融合算法:首先,对源图像进行NSCT分解,低频子带设置“取最大”的融合规则,高频子带采用PCNN模型;然后,修正后的NSCT域空间频率作为输入激励PCNN,选取最大点火频率作为融合图像的系数;最后,通过逆NSCT得到融合图像[22]。基于SR算法提出了基于稀疏表示的多聚焦图像融合方法,首先通过完备字典用稀疏系数表示源图像,其次与“取最大”融合规则相结合,通过组合的稀疏系数和字典重建融合图像[23]。基于PSR算法将源图像在几何方向上划分出分类块,并通过在线字典学习(Online Dictionary Learning, ODL)训练相应的子字典,采用最小角回归(Least Angle RegreSsion, LARS)对每个块进行稀疏编碼并将稀疏系数与取最大融合规则相结合,最后进行重构得到融合图像[24]。
从图7可以看出,针对CT/MR图像融合正常脑部的融合图中:基于DWT和NSCT的算法亮度存在严重失真,融合效果较差,CT轮廓信息没有很好地集成到融合图像中,骨骼和软组织信息不明显;基于SR、PSR的算法和本文算法在保持结构完整性方面表现良好,从细节处看,基于PSR的算法中略微丢失了部分源MR图信息,本文算法有更高的亮度对比度和更清晰的结构信息,很好地保留了边缘的纹理细节。
脑弓形虫的融合图中:基于DWT的算法融合效果不佳,存在伪影,且对MR源图像的信息丢失严重;基于SR的算法视觉效果相对较好,图像信息保存比较完整;基于PSR的算法和本文算法的图像清晰、软组织信息与源图像较接近,融合效果较好,在融合边缘无虚影产生,对源图像信息的保存相对完整。
脑萎缩融合图中:基于DWT的算法图像整体偏暗,对比度不高,视觉效果不好;基于PSR的算法中骨骼信息组织体现不明显,不利于医生对病灶的判断;本文算法融合效果较好,图像亮度提升,对比度较高,纹理信息与边缘信息的保存程度较高,可以获得更好的视觉质量,具有更小的亮度失真和对比度失真。
从融合效果对比综合来看,本文算法都成功地将脑部骨骼和软组织信息进行了融合,相较于四种传统融合方法,本文算法的融合效果更优。
从图8可以看出,针对MR/SPECT图像失智症和胶质瘤的融合图中:基于DWT算法在细节特征信息的表示上性能较差,存在水平和垂直遮挡问题;基于NSCT算法在边缘细节表示方面,与原始MR图像相比,边缘细节模糊;基于SR算法相较其他算法在右上角对比度较低,轮廓不明显;基于PSR算法边缘细节相对明显,但整体对比度较低;本文算法融合效果明显优于其他算法,具有更清晰的细节表现力,对源图像特征信息保留完整,没有暗线并保持了较高的对比度,充分表明了本文算法可以在边缘锐度和对比度等方面获得更好的融合性能。
3.2 评价指标
为了更加全面地对融合结果进行评估,本文对测试集图像进行融合并计算客观评价指标MI、IE、SSIM、SF、AG平均值得到评价数据。MI表示融合图像中包含源图像的信息量,MI越大,表明融合图像中包含的源图像信息量越多;IE用来衡量图像的信息丰富程度, IE越大,表明融合效果越好;SSIM从亮度、对比度和结构三个方面衡量融合图像与源图像的相似程度,其值在[0,1]之间,SSIM越大,表明融合图像与源图像结构越相似;SF体现图像整体的活跃程度,SF越大,表示图像的边缘信息越多;AG反映图像细节和纹理等边缘信息的丰富程度,AG越大,表明图像越清晰。
从表1中可以看出:本文算法在大部分客观评价指标上达到了最佳值,在MI、IE、SSIM三个客观评价指标上均有良好的表现,对于正常脑部、脑膜瘤、脑萎缩三种类型,在MI上相较性能相对较好且稳定的基于SR算法分别提升了2.61%、2.54%和20.37%,表明本文算法具有能较好的提取边缘和纹理信息的能力;IE解决了信息的量化度量问题,本文算法在实验中均是最优值,对于正常脑部、脑膜瘤、脑萎缩三种类型,与基于SR算法相比分别提升了16.7%、24.9%和5.9%,客观地表明了本文算法在图像融合效果上的优越性;SSIM是衡量两幅图像相似度的指标,在该指标上本文算法在正常脑部和脑萎缩的实验中是最优的,在脑膜瘤实验中次优。基于DWT和NSCT的算法存在低对比度和结构失真的问题,基于SR和PSR的算法和本文算法在亮度和对比度方面有更好的效果,但基于SR算法中存在细节丢失,综上可以看出,本文所提的算法在针对CT/MR图像进行融合时可以更好地保留边缘、纹理和细节信息。
从表2中可以看出:本文算法在MI和SSIM上的性能均优于其他四种对比算法,平均提高了34%和21.9%。在失智症实验中,本文算法的IE达到最优值,其SF和AG均为次优;在胶质瘤实验中,本文算法在SF上达到最优,相较其他算法平均提高了4.5%,本文算法虽然没有达到每个单项评价指标均最优,但均可保持良好。综上可以看出,本文算法融合效果最好,可以提供更好的融合医学图像,在保持源图像的细节特征信息上表现较优。
由于医学图像具有隐私性和特殊性,在医学图像融合领域没有完整的开源数据库,融合过程中的测试集需要自己手动构造,测试集的质量很大程度上限制了训练网络模型的性能,在实际应用中,若有更准确的数据集,可以进一步提升融合效果,达到更好的客观指标。总体考虑,本文算法较好地保留了源图像的轮廓以及细节信息,客观评价与主观观察结果相符,为精确的病灶定位及手术治疗提供了有利的影像依据。
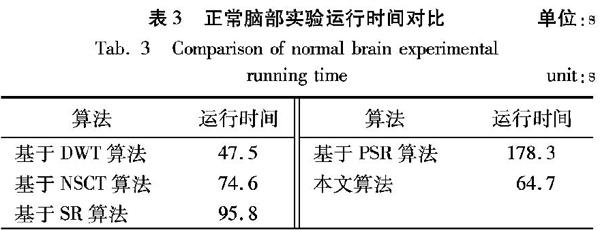
为了验证本文算法的时间效率,记录了正常脑部实验中各个算法的运行时间,结果如表3所示。
算法运行时间算法运行时间基于DWT算法47.5基于NSCT算法74.6基于SR算法95.8基于PSR算法178.3本文算法64.7
通过表3可以看出:由于基于DWT算法没有参数寻优的过程,直接计算区域能量,运行最快,但得到的融合结果并不理想;基于PSR算法需要将源图像进行分块并训练稀疏字典使得其运行时间较长;本文算法相较基于PSR算法运行时间减少了许多,表明采用网络模型省去很多不必要的参数寻优,使得融合过程变得简单和高效。本文实验采用了传统融合方法对目标图进行了构造,耗费的时间主要用于构造数据集和网络训练及测试,将网络运用于医学图像融合领域,得到训练成熟的网络模型后,直接将源图像输入网络模型,可以在较短的时间内得到效果优良的融合图像。
4 结语
基于GAN强大的图像生成特性以及残差块能提取更深层次特征的能力,本文提出了Res-GAN网络并应用于医学图像融合领域。实验结果表明,本文算法较好地保留了源图像的边缘、区域边界及纹理等细节信息,避免了边缘部分产生虚影,达到了较好的融合效果。但医学图像开源的数据集不足,即只有源图像但没有融合的目标图,本文实验是选取了优秀的傳统方法,手动构造目标图,从而造成了时间上的耗费并影响了模型训练的优劣。在实际应用中,若取得质量较好的完整数据集,直接输入网络对模型进行训练,将会大幅减少实验中的工作量,得到训练好的模型便可直接将医学图像进行融合,且由于训练集的质量得到保证,融合效果将会大幅提升。在后续的工作中,需要对网络结构进行进一步的改进,寻求更优性能的多模态图像融合算法,在实验中对目标图的构造进行进一步的探索,减少其对实验结果的限制。
参考文献 (References)
[1]SHEN R, CHENG I, BASU A. Cross-scale coefficient selection for volumetric medical image fusion [J]. IEEE Transactions on Biomedical Engineering, 2013, 60(4): 1069-1079.
[2]TAO L, QIAN Z. An improved medical image fusion algorithm based on wavelet transform [C]// Proceedings of the 7th International Conference on Natural Computation. Piscataway: IEEE, 2011: 76-78.
[3]江泽涛,杨阳,郭川.基于提升小波变换的图像融合改进算法的研究[J].图像与信号处理,2015,4:11-19.(JANG Z T, YANG Y, GUO C. Study on the improvement of image fusion algorithm based on lifting wavelet transform [J]. Journal of Image and Signal Processing, 2015, 4: 11-19.)
[4]曹义亲,雷章明,黄晓生.基于区域的非下采样形态小波医学图像融合算法[J].计算机应用研究,2012,29(6):2379-2381.(CAO Y Q, LEI Z M, HUANG X S. Region-based algorithm for non-sampling morphological wavelet medical image fusion [J]. Application Research of Computers, 2012, 29(6): 2379-2381.)
[5]LI S, YANG B, HU J. Performance comparison of different multi-resolution transforms for image fusion [J]. Information Fusion, 2011, 12(2): 74-84.
[6]WANG J, PENG J, FENG X, et al. Fusion method for infrared and visible images by using non-negative sparse representation [J]. Infrared Physics and Technology, 2014, 67: 477-489.
[7]XIANG T, YAN L, GAO R. A fusion algorithm for infrared and visible images based on adaptive dual-channel unit-linking PCNN in NSCT domain [J]. Infrared Physics and Technology, 2015, 69: 53-61.
[8]MA J, ZHOU Z, WANG B, et al. Infrared and visible image fusion based on visual saliency map and weighted least square optimization [J]. Infrared Physics and Technology, 2017, 82: 8-17.
[9]HE G, XING S, HE X, et al. Image fusion method based on simultaneous sparse representation with non-subsampled contourlet transform [J]. IET Computer Vision, 2019, 13(2): 240-248.
[10]DING S, ZHAO X, XU H, et al. NSCT-PCNN image fusion based on image gradient motivation [J]. IET Computer Vision, 2018, 12(4): 377-383.
[11]藺素珍,韩泽.基于深度堆叠卷积神经网络的图像融合[J].计算机学报,2017,40(11):2506-2518.(LIN S Z, HAN Z. Images fusion based on deep stack convolutional neural network [J]. Chinese Journal of Computers, 2017, 40(11): 2506-2518.)
[12]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2012: 1097-1105.
[13]RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. [2019-01-20]. https://arxiv.org/pdf/1511.06434.pdf.
[14]PATHAK D, KRHENBHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2536-2544.
[15]ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5967-5976.
[16]GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2672-2680.
猜你喜欢
祝您健康(2020年4期)2020-05-20
科学中国人·下旬刊(2019年5期)2019-09-10
阅读与作文(英语初中版)(2019年8期)2019-08-27
大众健康(2019年11期)2019-01-19
价值工程(2018年3期)2018-01-23
电子技术与软件工程(2017年19期)2017-11-09
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
科技与创新(2015年19期)2015-10-14
