
基于权重量化与信息压缩的车载图像超分辨率重建
2019-01-06 07:27许德智孙季丰罗莎莎
计算机应用 2019年12期
许德智 孙季丰 罗莎莎


摘 要:针对智能驾驶领域中需要在内存受限的情况下得到高质量的超分辨率图像的问题,提出一种基于权重八位二进制量化的车载图像超分辨率重建算法。首先,基于八位二进制量化卷积设计信息压缩模块,减少内部冗余,增强网络内信息流动,提高重建速率;然后,整个网络由一个特征提取模块、多个堆叠的信息压缩模块和一个图像重建模块构成,并利用插值后超分辨率空间的信息与低分辨率空间重建后的图像融合,在不增加模型复杂度的基础上,提高网络表达能力;最后,算法中整个网络结构基于对抗生成网络(GAN)框架进行训练,使得到的图片有更好主观视觉效果。实验结果表明,所提算法的车载图像重建结果的峰值信噪比(PSNR)比基于GAN的超分辨率重建(SRGAN)算法提高了0.22dB,同时其生成模型大小缩小为LapSRN的39%,重建速度提高为LapSRN的7.57倍。
关键词:超分辨率重建;车载图像;八位二进制权重量化;对抗生成网络;信息压缩模块
中图分类号: TP391.4文献标志码:A
Vehicle-based image super-resolution reconstruction based on
weight quantification and information compression
XU Dezhi*, SUN Jifeng, LUO Shasha
(School of Electronic and Information Engineering, South China University of Technology, Guangzhou Guangdong 510641, China)
Abstract: For the intelligent driving field, it is necessary to obtain high-quality super-resolution images under the condition of limited memory. Therefore, a vehicle-based image super-resolution reconstruction algorithm based on weighted eight-bit binary quantization was proposed. Firstly, the information compression module was designed based on the eight-bit binary quantization convolution, reducing the internal redundancy, enhancing the information flow in the network, and improving the reconstruction rate. Then, the whole network was composed of a feature extraction module, a plurality of stacked information compression modules and an image reconstruction module, and the information of the interpolated super-resolution space was fused with the image reconstructed by the low-resolution space, improving the network expression ability without increasing the complexity of the model. Finally, the entire network structure in the algorithm was trained based on the Generative Adversarial Network (GAN) framework, making the image have better subjective visual effect. The experimental results show that, the Peak Signal-to-Noise Ratio (PSNR) of the proposed algorithm for the reconstructed vehicle-based image is 0.22dB higher than that of Super-Resolution using GAN (SRGAN), its generated model size is reduced to 39% of that of the Laplacian pyramid Networks for fast and accurate Super-Resolution (LapSRN), and the reconstruction speed is improved to 7.57 times of that of LapSRN.
Key words: super-resolution reconstruction; vehicle-based image; eight-bit binary weight quantification; Generative Adversarial Networks (GAN); information compression module.
0 引言
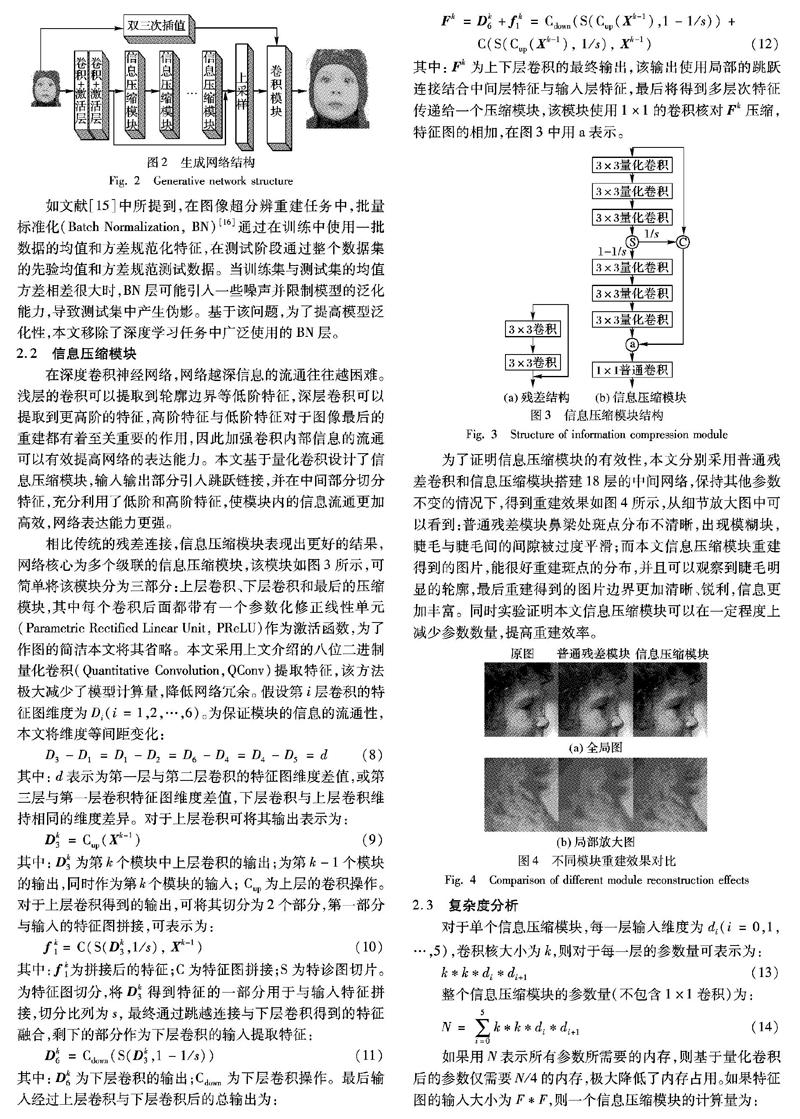
隨着卷积神经网络在图像处理方向表现出明显的优势,深度学习在单幅图像超分辨率重建(Single Image Super Resoluton, SISR)[1-2]领域得到越来越广泛的应用,基于深度学习的单幅图像超分辨重建方法通过训练更深的网络来获得更好的重建效果。Dong等[3]提出的SRCNN(Super-Resolution Convolution Neural Network)是深度学习在超分辨率重建上的首次应用,将深度学习引入到超分辨重建领域,仅仅使用了三个卷积层对双三次插值后的图像做非线性映射。Kim等[4]为简化训练提出了一个20层的卷积模型VDSR(image Super-Resolution using Very Deep convolution network),使用的残差网络结构的思想特别适合用来解决超分辨问题,可以说影响了之后的深度学习超分辨率方法。Mao等[5]提出编码残差网络 (REsiDual coding,RED)算法采用对称的卷积层反卷积层构构成的网络结构,卷积层用来获取图像的抽象内容,反卷积层用来放大图像并恢复图像细节。Lai等[6]提出LapSRN(Laplacian pyramid Networks for fast and accurate Super-Resolution),将低分辨率图片直接作为输入到网络,通过逐级放大,后一级于前一级之前参数共享,并利用前一级得到的结果,在减少计算量的同时有效提高了精度。Tai等[7]设计出更深的网络结构DRRN(Deep Recursive Residual Network),包含52层卷积,该算法采用单权重的递归学习,每个递归模块共享相同的权重,有效减少了模型的大小。Tong等 [8]提出的SRDenseNet(residual Dense Network for image Super-Resolution),引入稠密块(DenseBlock)将每一层的特征都输入给之后的所有层,使所有层的特征都串联起来,减轻梯度消失问题,通过堆叠模块加深网络层来得到更好的表现。
相比传统的残差连接,信息压缩模块表现出更好的结果,网络核心为多个级联的信息压缩模块,该模块如图3所示,可简单将该模块分为三部分:上层卷积、下层卷积和最后的压缩模块,其中每个卷积后面都带有一个参数化修正线性单元(Parametric Rectified Linear Unit, PReLU)作为激活函数,为了作图的简洁本文将其省略。本文采用上文介绍的八位二进制量化卷积(Quantitative Convolution,QConv)提取特征,该方法极大减少了模型计算量,降低网络冗余。假设第i层卷积的特征图维度为Di(i=1,2,…,6)。为保证模块的信息的流通性,本文将维度等间距变化:
D3-D1=D1-D2=D6-D4=D4-D5=d(8)
其中:d表示为第一层与第二层卷积的特征图维度差值,或第三层与第一层卷积特征图维度差值,下层卷积与上层卷积维持相同的维度差异。对于上层卷积可将其输出表示为:
Dk3=Cup(Xk-1)(9)
其中:Dk3为第k个模块中上层卷积的输出;为第k-1个模块的输出,同时作为第k个模块的输入; Cup为上层的卷积操作。对于上层卷积得到的输出,可将其切分为2个部分,第一部分与输入的特征图拼接,可表示为:
fk1=C(S(Dk3,1/s), Xk-1)(10)
其中: fk1为拼接后的特征;C为特征图拼接;S为特诊图切片。为特征图切分,将Dk3得到特征的一部分用于与输入特征拼接,切分比列为s,最终通过跳越连接与下层卷积得到的特征融合,剩下的部分作为下层卷积的输入提取特征:
Dk6=Cdown(S(Dk3,1-1/s))(11)
其中: Dk6为下层卷积的输出;Cdown为下层卷积操作。最后输入经过上层卷积与下层卷积后的总输出为:
Fk=Dk6+f k1=Cdown(S(Cup(Xk-1),1-1/s))+
C(S(Cup(Xk-1), 1/s), Xk-1)(12)
其中:Fk为上下层卷积的最终输出,该输出使用局部的跳跃连接结合中间层特征与输入层特征,最后将得到多层次特征传递给一个压缩模块,该模块使用1×1的卷积核对Fk压缩,特征图的相加,在图3中用a表示。
为了证明信息压缩模块的有效性,本文分别采用普通残差卷积和信息压缩模块搭建18层的中间网络,保持其他参数不变的情况下,得到重建效果如图4所示,从细节放大图中可以看到:普通残差模块鼻梁处斑点分布不清晰,出現模糊块,睫毛与睫毛间的间隙被过度平滑;而本文信息压缩模块重建得到的图片,能很好重建斑点的分布,并且可以观察到睫毛明显的轮廓,最后重建得到的图片边界更加清晰、锐利,信息更加丰富。同时实验证明本文信息压缩模块可以在一定程度上减少参数数量,提高重建效率。
2.3 复杂度分析
对于单个信息压缩模块,每一层输入维度为di(i=0,1,…,5),卷积核大小为k,则对于每一层的参数量可表示为:
k*k*di*di+1(13)
整个信息压缩模块的参数量(不包含1×1卷积)为:
如果用N表示所有参数所需要的内存,则基于量化卷积后的参数仅需要N/4的内存,极大降低了内存占用。如果特征图的输入大小为F*F,则一个信息压缩模块的计算量为:
2.4 判别网络
GAN模型中,判别网络在训练过程中起到监督作用,训练结束后,判别网络不会参与重建过程。本文中判别网络采
用级联的VGG[17]的结构,每个卷中间每个卷积模块后面都接一个BN层和Leaky ReLU单元,如图5所示。
图5中,k3n64s1表示卷积核为大小为3,输出特征图维度为64,步长为1,经过多次特征提取以及卷积下采样后得到最后的输出。
2.5 损失函数
基于CNN的超分辨率重建网络大多采用均方误差(Mean Squared Error, MSE)作为损失函数,这样虽然可以取得较高的峰值信噪比,但是得到图片过于平滑,丢失细节。本文损失函数由三部分组成:均方差损失、感知损失和对抗损失,可表示为:
lSR=lSRMSE+lSRVGG+10-3 lSRGen(16)
其中:lSRMSE为均方差损失。该损失促使标签IHRx,y与生成样本G(ILR)x,y对应像素点间的均方误差最小化:
其中:lSRVGG为感知损失,为了解决均方差损失缺少高频信息,导致过度平滑的问题,它将真实图片与生成图片卷积后的特征作比较。本文使用以训练好的VGG作为基础网络,该损失如下:
其中:Wi, j、Hi, j表示VGG各自特征图的维度; φi, j表示VGG中各层的映射关系。
lSRGen为对抗损失,基于训练样本在判别器上的概率可将其定义为:
其中D表示判别网络的映射关系。该函数使生成网络得到的图片以更大概率骗过判别器。
3 实验与结果分析
3.1 实验设置
本实验所有训练或测试过程均在32GB内存,英伟达1080Ti GPU的服务器上得到的结果。实验中使用了两部分训练集:
第一部分为200张Berkeley Segmentation Dataset数据集和Yang使用的91张图片,共291张作为训练集训练网络,并在Set5和Set14上验证模型效果。考虑到GPU显存的限制,为了权衡计算复杂度与重建效果,经过多轮调参,网络最终使用72×72的图像块作为输入,BatchSize设置为16,信息压缩模块中D1、d 、s参数分别设置为64、16、4,使用5个级联的信息压缩模块,优化器选择为Adam优化器,β1=0.9, β2=0.999,学习率为0.001。
车载视频中含有大量高分辨率的真实道路图像,信息复杂多样,对车载图像的重建有利于辅助智能驾驶。本文第二部分为车载视屏中得到的车载图像数据集,共2000对不同分辨率图片,其中1800对作为训练集,200张作为验证集。原图像尺寸为1920×1080,图片中包含大量复杂的语义信息,导致重建难度加大。在该部分本文使用第一部分得到的模型作为预训练模型,在此基础上作微调。图像块的输入尺寸为192×192,BatchSize设置为4,为充分利用数据,对输入数据作数据增强,即随机的水平翻转、垂直翻转、通道变换,其他参数不变。训练过程中,先使用Set14数据集预训练得到最好结果,然后使用本文训练集训练网络,当网络在连续10轮内损失函数没有下降时提前停止训练,保存最好的模型。
3.2 重建速率和模型大小
表1的结果为10张500×500的车载图像放大3倍的平均重建速率。VDSR算法需要在插值后的SR空间提取特征,尽管网络小,模型大小适中,但重建速率不高。DRRN基于递归的循环卷积,使用参数共享,尽管能得到较小的模型,但由于算法仍然在SR空间提取特征并且需要多次循环卷积,重建速率很慢。LapSRN将图像逐级放大,在不同尺寸的特征图上提取特征,尽管网络更深,但重建速率确有显著提高。基于GAN的超分辨率重建(Super-Resolution using GAN, SRGAN)算法基于LR空间提取特征,然后使用普通卷积模块,网络使用简单的堆叠,存在大量的冗余,模型较大。本文算法基于LR空间提取特征,并在几个级联的信息压缩模块中极大地减少计算量,相较于LapSRN,其生成模型大小缩小为LapSRN的39%,重建速度提高为LapSRN的7.57倍。
3.3 有参考质量评估
根据文献[18],基于GAN的超分辨重建算法在PSNR、结构相似度(Structural Similarity, SSIM)[19]等客观指标往往比同类效果低,但是却能得到更好的主观效果,其主观质量得分远高于同类算法,因此本文仅与同类SRGAN作比较。由表2可以得到,本文算法与SRGAN相比在PSNR及SSIM上仍有一定的提升。
3.4 主观质量评估
主观质量评估是观察者对于图像主观的视觉感受,在图像超分辨重建任务中更高的PSNR或SSIM不一定代表更好主观视觉效果,本节直接对比不同算法重建后图片的主观视觉效果。
由于车载图像尺寸较大,图像中包含大量道路信息和纹理结构,增大了重建难度。为了更加直观地体现出重建前后图像在细节方面的差异,本文将不同算法重建后图像的局部放大后进行对比。实验选取了不同图片上交通告示牌、路边建筑和道路裂缝等细节作为展示,如图6。在交通告示牌中本文算法对于文字边缘和色彩的饱和度上有很好的重建效果,不會产生模糊的边界。对于建筑上的线条,其他算法会出现不连续的断点,而本文算法能很好重建出连续且清晰的线条。同样本文算法对于道路裂纹也体现出很好的重建效果。
3.5 无参考质量评估
参考文献[20]所使用熵的比较方法,表3给出了本文重建算法重建前后熵和方差的变化。实验中随机选取3组无参考图片,每组20张,计算图像在3倍超分辨率重建后的平均熵和方差,熵越大表示图像信息越丰富。实验结果显示,用本文算法重建后图片熵有所提高,表明用该算法重建后图像包含的信息更加丰富。
3.6 重建后对目标检测的影响
在目标检测任务中,分辨率越高、图像越清晰往往可以得到更好的检测效果,本部分将车载图像通过本文网络超分辨率重建(2倍)后,用于目标检测任务,共使用1000张测试图片,使用RetinaNet[21]目标检测器,手工统计图片中目标个数(行人和车辆)以及检测到的目标个数,并计算识别率,重建前的平均识别率为75.54%,重建后识别率可提升到78.35%。图7为超分辨率重建前后目标检测的结果比较,为了方便观察本文将图片放大到相同的大小。重建前后图像质量得到明显的改善,轮廓边缘更清晰。重建前会漏检一些较小或不清晰的目标,而重建后可以检测到之前漏检的对象,如第一组图片左下角的车辆和第二组图片左上角的行人,同时检测到目标的置信度有轻微提升。
4 结语
本文基于八位二进制量化和信息压缩模块设计网络结构,并采用GAN结构训练网络,极大地减少了计算量,提高了重建效率;并结合局部和全局的残差学习,通过网络学习LR空间中的高频信息,直接与插值之后的SR空间信息相融合,使网络的学习过程更加轻松。最终的实验结果表明,与VDSR、LapSRN等深度学习方法相比,本文算法不仅可以得到更小的模型、更快的重建速率,同时重建的图片能很好地恢复图像细节,达到良好的主观视觉效果。但由于GAN训练的不稳定性,本文算法在训练过程中有较大的波动,接下来可进一步研究提高算法的稳定性,且行车记录仪中图像具有连续性,可根据帧与帧之间的联系进一步提高算法的重建效果。
参考文献 (References)
[1]EFRAT N, GLASNER D, APARTSIN A, et al. Accurate blur models vs. image priors in single image super resolution [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2013: 2832-2839.
[2]张宁,王永成,张欣,等.基于深度学习的单张图片超分辨率重构研究进展[J/OL].自动化学报[2019-07-07].http://kns.cnki.net/kcms/detail/detail.aspx?doi=10.16383/j.aas.c190031.(ZHANG N, WANG Y C, ZHANG X, et al. A review of single image super-resolution based on deep learning [J/OL]. Acta Automatica Sinica [2019-07-07]. http://kns.cnki.net/kcms/detail/detail.aspx?doi=10.16383/j.aas.c190031.)
[3]DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Cham: Springer, 2014: 184-199.
[4]KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks [C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1646-1654.
[5]MAO X, SHEN C, YANG Y. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections [C] // Proceedings of the 2016 Annual Conference on Neural Information Processing Systems. La Jolla: Neural Information Processing Systems Foundation, 2016: 432-449.
[6]LAI W, HUANG J, AHUJA A, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5835-5843.
[7]TAI Y, YANG J, LIU Y. Image super-resolution via deep recursive residual network [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2790-2798.
[8]TONG T, LI G, LIU X, et al. Image super-resolution using dense skip connections [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4809-4817.
[9]COURBARIAUX M, BENGIO Y, DAVID J P. BinaryConnect: training deep neural networks with binary weights during propagations [C]// Proceedings of the 2015 Annual Conference on Neural Information Processing Systems. La Jolla: Neural Information Processing Systems Foundation, 2015: 3123-3131.
[10]HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[11]袁昆鵬,席志红.基于深度跳跃级联的图像超分辨率重建[J].光学学报,2019,39(7):0715003-1-0715003-10.(YUAN K P, XI Z H. Image super resolution based on depth jumping cascade [J]. Acta Optica Sinica, 2019, 39(7): 0715003-1-0715003-10.)
[12]OODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 2014 Annual Conference on Neural Information Processing Systems. La Jolla: Neural Information Processing Systems Foundation, 2014: 2672-2680.
[13]OHNSON J, ALAHI A, LI F. Perceptual losses for real-time style transfer and super- resolution [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 694-711.
[14]RASTEGARI M, ORDONEZ V, REDMON J, et al. XNOR-Net: ImageNet classification using binary convolutional neural networks [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016: 525-542.
[15]LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1132-1140.
[16]IOFFE S, SZEGEDY S. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 2015 32nd International Conference on Machine Learning. New York: JMLR, 2015: 448-456.
[17]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2019-03-20]. https://arxiv.org/pdf/1409.1556.pdf.
[18]LEDIG C, THEIS L, HUSZR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 105-114.
[19]WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity [J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
[20]劉杰平,杨业长,韦岗.结合暗通道先验的单幅图像快速去雾算法[J].华南理工大学学报(自然科学版),2018,46(3):86-91.(LIU J P, YANG Y Z, WEI G. A fast single image dehazing algorithm based on dark channel prior [J]. Journal of South China University of Technology (Natural Science Edition), 2018, 46(3): 86-91.)
[21]LIN T Y, GOYAL P, GIRSHICK R. Focal loss for dense object detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007
This work is partially supported by the Science and Technology Research Project of Guangdong (x2dxB216005).
XU Dezhi, born in 1995, M. S. candidate. His research interests include machine learning, computer vision.
SUN Jifeng, born in 1962, Ph.D., professor. His research interests include machine learning, pattern recognition, computer vision.
LUO Shasha, born in 1994, M. S. candidate. Her research interests include computer vision, data mining.
收稿日期:2019-05-13;修回日期:2019-07-30;录用日期:2019-07-31。基金项目:广东省科技计划项目(x2dxB216005)。
作者简介:许德智(1995—),男,湖北荆州人,硕士研究生,主要研究方向:机器学习、计算机视觉; 孙季丰(1962—),男,广东广州人,教授,博士生导师,博士,主要研究方向:机器学习、模式识别、计算机视觉; 罗莎莎(1994—),女,江西吉安人,硕士研究生,主要研究方向:计算机视觉、数据挖掘。
文章编号:1001-9081(2019)12-3644-06 DOI:10.11772/j.issn.1001-9081.2019050804
