
基于Spark Streaming的快速视频转码方法
2019-01-07 12:16杨贺昆吴唐美冯朝胜
计算机应用 2018年12期
付 眸,杨贺昆,吴唐美,何 润,冯朝胜,2,康 胜
(1.四川师范大学 计算机科学学院,成都 610101; 2.可视化计算与虚拟现实四川省重点实验室(四川师范大学),成都 610101; 3.四川师大科技园发展有限公司,成都 610066)(*通信作者电子邮箱fymen@naver.com)
0 引言
随着多媒体服务的蓬勃发展,尤其是智能手机的普及,人们越来越便捷地生成和传播图片、语音、视频等多媒体数据;其中,视频是主要的内容形式之一。根据中国互联网信息中心(China Internet Network Information Center, CNNIC)于2018年1月发布的《第41次中国互联网络发展状况统计报告》[1],截至2017年12月,中国网民总数已达7.72亿;其中,有7.53亿网民同时使用手机。有5.79亿网民使用过网络视频类应用,占总数的75%,比2016年增加了3 437万。
视频内容的制作、上传、分享离不开视频转码处理;尤其是移动端视频分享,例如,通过QQ空间上传分享一段视频,上传完成后,需要一段时间进行视频转码工作,才能在网页中观看,转码时间的长短与视频的参数相关。随着网络视频用户规模的不断增加,传统的单机转码方式开始出现性能瓶颈,各类视频网站或视频应用开始借助云计算技术[2-3],搭建并行转码平台以提升视频转码效率。
本文根据视频转码特点,采用分布式流处理技术,提出一种基于Spark Streaming的快速视频转码方法。本文分析了传统的单机转码方法和基于Hadoop的视频转码方法,改进了视频切割的流程;并减少了批处理转码方式中大量等待时间。实验结果表明,本文提出的转码方法显著提升了转码效率。
1 相关工作
视频数据的编码方式有很多种,如常见的HEVC(High Efficiency Video Coding)[4]、MPEG2(Moving Picture Experts Group 2)、MPEG4、H.264、VP9、VC1等。其中,联合国下属机构国际电信联盟电信标准分局(International Telecommunication Union Telecommunication standardization sector, ITU-T)制定了H.26X系列视频编码标准[5],因其高效的压缩算法、良好的实时传播兼容性,在远程会议、网上聊天、在线视频等领域得到广泛应用。
不同的视频编码方法有不同的使用场景,根据需要将视频编码进行转换是不可或缺的工作。传统视频转码方法是使用单机进行转码工作,但在处理大量视频资源时会有三种情况产生:1)多个视频文件进行转码时,通常会按序进入转码队列;单机在处理长队列视频转码工作十分耗时。2)某个视频转码工作出现问题,后续工作停止,需要人工值守。3)不具备并发视频转码能力。
针对上述情况,使用并行处理方法,可以较好解决以上问题。目前广泛使用Hadoop框架[6]、Mapreduce编程模型[6-8]、分布式文件系统(Hadoop Distributed File System, HDFS)实现分布式存储,开源多媒体处理框架执行视频转码任务。使用Hadoop分布式视频转码方案,一般会有以下几个步骤[9]:1)将源视频切分成视频分片,并上传至HDFS。2)运行Map()从HDFS下载视频分片。3)节点通过多媒体处理框架进行转码,并将转码后的文件上传至HDFS。4)运行Reduce(),对转码后的视频分片进行合并。
根据不同视频转码任务,多媒体处理框架有多种选择,FFmpeg[10]支持多种视频编码方式的解码和编码,并能跨平台运行,成为众多视频转码研究的主要技术。MEncoder[11]因命令行解码的方式,被广泛应用在二次开发的视频播放器中。Kim等[12]的团队对分布式视频转码技术进一步研究,2012年研发了SMCCSE(Social Media Cloud Computing Service Environment),该系统将社交网络作为切入点,以人们在社交网络活动中产生的音频、视频、图像等多媒体文件作为转码对象,使用平台即服务(Platform-as-a-Service, PaaS)云平台[13],构建了基于Hadoop的多媒体转码系统,从而拓展了分布式转码技术的应用范围。Kim等[14]持续关注分布式转码技术的研究进展,于2015年提出了多媒体转码服务的优化转码方案,该方案进一步研究HDFS块大小、块备份数量、Java虚拟机资源占用、输入/输出缓存大小等多种因素对转码效率的影响,通过大量实验,解决了影响效率的关键问题。2017年,Kim等[15]研发了另一套基于Hadoop的分布式视频转码方案HVTS (Hadoop-based Video Transcoding System),该方案的优点是整合了视频上传、视频转码、视频分布式保存等模块,提供了灵活的转码参数配置。
国内的相关研究工作中,重点是对分布式视频转码技术进行优化。早在2009年,庞一等[16]面向单机多核视频编码并行化技术进行了综述研究,介绍了在多核环境中视频并行化处理的技术特点。分布式视频转码的负载均衡设计也是一个相当重要的研究工作;良好的集群的心跳连接不但可以提升系统稳定性,结合调度算法,还能最大限度提升集群性能[17]。2014年,Song等[18]的团队研发了使用FFmpeg和MEncoder进行解码的分布式系统,该系统的特点是在Map阶段,使用FFmpeg进行转码任务;在Reduce阶段,使用MEncoder进行视频的合并工作。2016年,Chen等[19]提出一种基于Hadoop平台的视频并行转码方法,该方法通过Mapreduce编程,并行化执行FFmpeg命令,实现视频分割、转码、合成。该方法与单机视频转码的实验结果表明,该方法的转码效率有明显提升。但该方法本质是基于Hadoop的批处理方式,转码时,需要等待视频切割任务完成后,Map节点才开始执行视频转码任务,冗余的等待时间使得转码效率提升有限。
2 关键技术
2.1 FFmpeg多媒体框架
FFmpeg是由开源社区维护的多媒体处理框架,提供解码、编码、转码、音频视频合成、音视频分解、流媒体、视频播放等功能。视频转码流程如图1所示。FFmpeg核心组件和功能如表1所示。
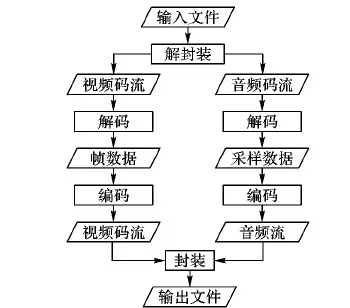
图1 视频转码流程Fig. 1 Flow chart of video transcoding表1 FFmpeg核心库Tab. 1 FFmpeg core library

组件功能libavutil核心工具集,提供编程示例、数学函数、数据结构等libavcodec基本的音视频编码、解码库libavformat对音视频进行分解和合并libavdevice可从第三方抓取和输入媒体流libswscale提供视频按照一定规格进行缩放转换功能libswresam-ple提供对音频进行重采样、重编码等转码操作
FFmpeg通过使用命令行的方式提供强大的多媒体操作功能,可以完成视频的编码、解码。文献[10]研究实现了对H.264和HEVC的视频编码,并能对这两种编码的视频文件进行相互转换。
FFmpeg作为开源的多媒体框架,并不只针对视频进行处理,还擅长处理音频、图片、字幕、视频/图片采集等。
2.2 Spark Streaming流处理框架
Spark是目前流行的分布式框架之一,其核心由一组功能强大的扩展库组成。目前这些库包括SparkSQL、Spark Streaming、MLlib以及GraphX,其他一些Spark库和扩展也在陆续开发中。Spark Streaming是Spark的组件之一,主要功能是实现流处理。
3 构建视频转码模型
Hadoop分布式系统擅长处理批量作业,分布式作业的运行依赖于前一步骤作业的处理结果,需要数据全部处理完毕后,再进行下一步作业;根据视频转码的特性,建立流处理模型,将视频分片数据视为流处理中的最小单元,通过调度算法快速分发视频分片数据,节省Hadoop切片与Mapper之间的等待时间,从而达到提高视频转码效率的目的。要建立视频转码的流处理模型,首先要考虑视频文件的特性,其次基于Spark Streaming框架,分别建立数据源、RDD、视频合并服务器。其中,RDD是研究的关建。
3.1 Spark Streaming数据源设计
Spark Streaming运行时,需要持续不断地获得输入数据。一般视频文件都会有较大体积,视频文件在集群网络中传输,会加重网络开销,降低系统效率,因此通过将完整的视频文件进行切片处理,把切分的视频分片路径作为文本输入数据,减轻了集群网络传输负担。要设计持续稳定的数据源,同时视频分片粒度的大小保持一致,需要稳定性良好的硬件环境和程序设计。
完整的源视频文件需要切分为众多小视频文件,并满足:
(1)
视频文件V的总时长tsum应与各分片S的时长tn之和相同。分片模块调用SplitApp.Split(),在该函数中,调用FFmpeg进行具体切片工作。同时,数据源需要持续不断地产生视频分片数据;因此,需要持续运行SplitApp.Split()并调用FFmpeg命令,使用Java实现循环逻辑,直到视频切片完成为止。分片节点的处理流程为:获得视频文件→调用Split→保存至HDFS目录/slices。该功能伪代码如算法1所示。
算法1 视频文件分片模块。
输入 视频文件;
输出 视频分片统一资源定位符(Uniform Resource Locator, URL)。
BEGIN
raw_video←源视频目录;t←分片时长;output←视频输出文件URL
WHILE(true)
vList=从raw_video目录获取视频列表
FOR(f:vList)
SumTime←获取视频总时长;
start←0;leftTime←0;
FOR(s=start;leftTime>T;)
//ffmpeg视频切片命令
ffmpeg -ss s -i f -c copy -t t output;
leftTime←leftTime-T;
s+=T;
start=s;
END FOR
END FOR
END WHILE
通过监控上传目录raw_video,当有视频文件上传完成,对该视频文件进行分片,并将分片文件URL作为数据源。
数据源的输出为文本文档,文本中包含视频文件名称和视频分片的URL,格式为:
x.avi [空格] /目录1/目录2/x1.avi
建立StreamingContext对象,有以下步骤:
1)创建配置文件。
StreamingContext配置代码格式如下:
SparkConf().setMaster(url).setAppName(String).
set(String,String)
其中set(String,String)函数可设置多个不同的参数,常用配置参数如表2所示。

表2 StreamingContext 配置参数Tab. 2 StreamingContext configuration parameters
2)参数传递。
根据集群硬件配置,合理的设置参数值,可以让系统更稳定高效地运行,提升流处理作业效率。将配置文件作为参数传递给StreamingContext():
val conf=new SparkConf()
.setMaster(url)
.setAppName(String)
.set(String,String
val ssc=new StreamingContext(conf,Seconds(x))
StreamingContext产生DStream,即一段连续的流数据;除了通过接收数据源的数据产生DStream,也可通过调用DStream算子,产生新的DStream。产生DStream的时间间隔通过参数Seconds(x)指定,x值越大,产生的DStream的时间就越长,实时性越低。通常在实时性要求比较高的流处理模型中,x取较小值。
对DStream的操作,可调用相关操作算子,常用算子如表3所示。
DStream中包含从数据源获得的数据,并封装为一系列RDD,foreachRDD()函数可对每个RDD进行操作,格式为:
foreachRDD(func)=>RDD(func)
该算子将DStream内部的RDD取出,可存放在文件系统中、或传送至网络、存入数据库。
3.2 依赖分析
通常在进行数据处理时,不同的数据之间有一定的依赖关系,这种依赖关系在Spark里称为Lineage,也即RDD的依赖关系,使用有向无环图(Directed Acyclic Graph, DAG)来表示。因此,在Spark中,按照Lineage生成DAG,要根据具体的数据处理流程来确定。
RDD有两种类型的操作算子:Transformation和Action。Transformation类型的操作算子不会立即执行,Action型操作算子会立即触发作业(Job)。DAG Scheduler将作业划分为阶段(Stage),阶段包含要执行的任务集合,任务集合由TaskScheduler分配到节点上执行。划分阶段的依据是RDD的依赖性,分别如下。
宽依赖(Wide Dependency):宽依赖指当前阶段的执行,依赖于多个前一阶段的任务完成。宽依赖如图2所示。

表3 DStream操作算子Tab. 3 DStream operators
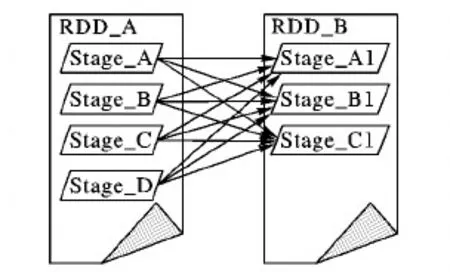
图2 宽依赖示意图Fig. 2 Schematic diagram of wide dependency
窄依赖(Narrow Dependency):当前阶段任务的执行,只与当前任务的前一阶段任务有关。窄依赖示意图如图3所示。
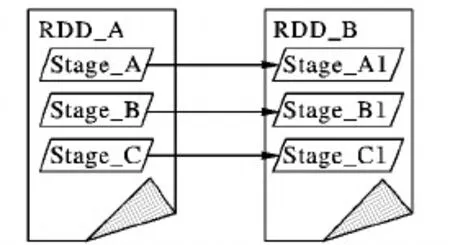
图3 窄依赖示意图Fig. 3 Schematic diagram of narrow dependence
如果当前阶段要执行,需要多个前阶段执行完毕;因此,宽依赖是划分阶段的依据。结合本文的研究内容,分布式视频转码流程有以下7个步骤:1)读取视频文件。2)将视频文件切分为多个视频分片。3)保存视频分片URL至txt文档。4)txt文档作为输入源。5)解析txt文档中的视频分片URL。6)合并已转码视频分片为视频文件。7)调度URL数据至Executor执行转码。
分析以上步骤的依赖关系,按照宽依赖和窄依赖概念划分阶段,可以得到面向流处理的视频转码模型依赖关系图如图4所示。
阶段1和阶段2之间通过GroupByKey将视频分片合并,有Shuffle过程,该过程有较大网络开销。
3.3 构建RDD模型
RDD是Spark分布式处理的关键,也是Spark Streaming的重要环节,结合分布式流处理的视频转码特性,合理划分Partition、Stage、Task,将源视频文件名称和视频分片文件URL组成的〈K,V〉作为要处理的原始数据,能有效避免视频文件因调度带来的网络开销和存储的高I/O。
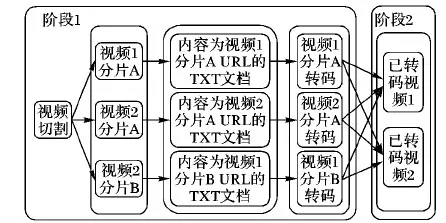
图4 面向分布式视频转码的DAGFig. 4 DAG for distributed video transcoding
构建RDD模型,首先要确定在Spark Streaming中的RDD产生和数据原理,通过3.2节针对视频转码的依赖划分阶段,构建良好的RDD模型。Spark Streaming的核心是操作RDD,DStream最终要分解为一个或多个RDD,即数据流的分布式。任务调度器(Task Scheduler)是并行化的重要环节。在Spark中,从细粒度到粗粒度划分,处理单元可分为如下:1)工作线程(Executor)。处理数据的最小执行单位。2)工作节点(Worker)。一个工作节点为一台物理机器,在一个工作节点上,可以运行多个工作线程。
工作线程是执行处理工作的最小单位,从细粒度到粗粒度划分,要处理的业务对象可分为如下:1)任务(Task)。工作线程要处理的最小工作单位,包含一系列处理方法和数据分区(Partition)。2)阶段(Stage)。一个任务集,阶段按照宽依赖和窄依赖划分;包含一系列宽窄依赖关系的RDD,如图5所示。
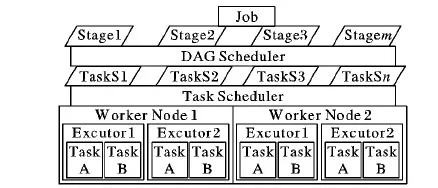
图5 RDD业务分层调度模型Fig. 5 Hierarchical scheduling model for RDD business
结合本文的研究工作,按照数据粒度从细到粗划分,有以下数据对象:
1)分区(Partition):最小的数据单位。结合本文研究内容,将分区定义为一条〈视频名 分片名〉文本记录。
2)RDD(弹性分布式数据集):RDD中定义了多种数据处理方式,即操作算子。结合本文研究内容,将RDD定义为包含多个〈视频名 分片名〉记录,以及对这些记录的处理方法。
3)DStream(离散数据流):DStream包含多个RDD,按照设定的单位时间不断产生。在本文中,产生DStream的数据源是包含〈视频名 分片URL〉记录的txt文档。
以上分别对处理单元、业务对象、数据对象按照粒度由小到大进行区分,并结合本文研究内容,将包含视频分片信息的文本文档作为数据源,〈视频名 分片URL〉为最小数据单元。将以上内容结合3.2节的依赖分析,可得基于视频分片的RDD数据流图,如图6所示。
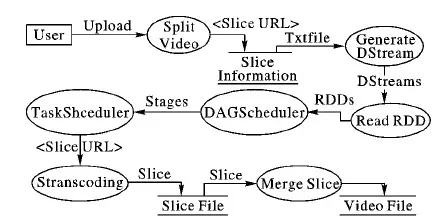
图6 RDD数据流图Fig. 6 RDD data stream diagram
根据数据流图,可建立RDD编程模型,伪代码如算法2所示。
算法2 RDD编程模型。
输入 DStream;
输出 视频分片URL。
BEGIN
DStream.foreachRDD
rdd←从DStream中取得一个RDD
IF(RDD不为空)
rdd1←rdd.map(x=>x.split("")(1))
item←从rdd中取得一个元素
rdd1.foreach
url←从rdd1中取得一个元素
调用转码命令:ffmpeg -i url -c:v libvpx-vp9 output.webm
将output.webm移动至HDFS分片目录中
END foreach
END IF
END foreach RDD
数据源输出的是一条文本记录,该记录则为RDD中的一个基本元素,格式为:
视频文件名[空格]视频分片文件URL
RDD调用map算子进行转换生成RDD1,通过对RDD1进行foreach()运算,得到RDD1中的记录是一条视频分片文件URL。
3.4 视频分片文件合并模型
根据流处理的特性,数据持续地产生和处理,因此要对旧的文件和缓存进行清理,防止因空间不足而导致系统不稳定。视频的合并要按照视频分片的先后次序进行,在分布式转码过程中,无法保证视频按照先后顺序依次转码;因此,需要等待视频文件的所有分片都转码完成后,再进行合并。视频合并伪代码如算法3所示。
算法3 流处理视频合并。
输入 视频名称,分片URL列表;
输出 完整视频文件。
BEGIN
key←视频名称;values←分片URL列表;output←完整视频输出文件
新建文本concatFile←对values进行排序
//运行合并命令
ffmpeg -f concat -safe 0 -i concatFile -c copy output
上传output到HDFS
END
concatFile文本文件中的分片在时间上是有序的,否则会导致视频内容错乱。
4 实验结果与分析
4.1 系统部署
基于本文所提出的快速视频转码方法,设计和实现了快速视频转码原型系统。该原型系统部署在四川师范大学云计算实验室私有云平台,该云平台提供了友好的弹性虚拟机管理界面,通过管理界面可以对目标虚拟机进行复制创建,可短时间按需创建包含一定数量节点的同构集群环境;同时,根据不同的需求,可弹性扩展虚拟机硬件配置,这极大地方便了实验的开展。
4.2 运行环境
4.2.1 硬件环境
Master节点需要运行HDFS的NameNode进程、Spark的Master进程。该节点出现故障会对集群造成灾难性影响,因此该节点配置较大内存和较多核CPU。
SplitServer节点的主要工作是将视频切分,切分工作实际上是将音视频数据按照输入参数复制并保存为音视频数据块。复制为多个小块的过程比转码所需要的CPU运算力要低得多;因此,切分过程由一个节点完成即可,为了应对较大的视频文件存储问题,切分节点SplitServer除了配置与Master节点相同的CPU和内存外,磁盘容量提升至100 GB。在实验中将SplitServer也视为数据源。
MergeServer工作与SplitServer相反,把转码后的视频切片,有序合并成一个视频文件,再上传至HDFS保存。MergeServer的输入数据是有序的、完整的、已经转码的视频分片。
Slave节点,即运行HDFS的Datanode节点、Spark Streaming的Work节点,是分布式存储、分布式转码工作的主要执行节点。Slave节点初始配置4核心CPU、8 GB内存、40 GB存储;初始数量20个,可根据实验要求,在云管理后台进行弹性配置。详细配置如表4所示。
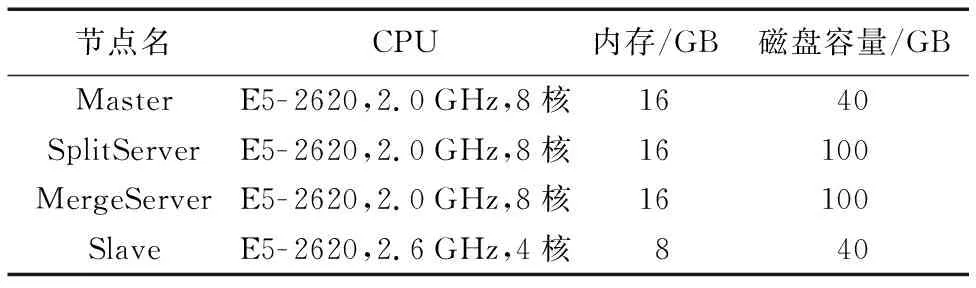
表4 系统部署硬件配置Tab. 4 System deployment hardware configuration
4.2.2 软件环境
本文系统所有软件运行在Linux平台,私有云提供了64位CentOS 6.1操作系统,经测试,本文系统所需要的软件都能正常稳定地运行在64位CentOS 6.1系统中。软件详细参数如表5所示。

表5 系统部署软件环境Tab. 5 System deployment software environment
根据节点信息,绘制节点网络拓扑图,如图7所示。
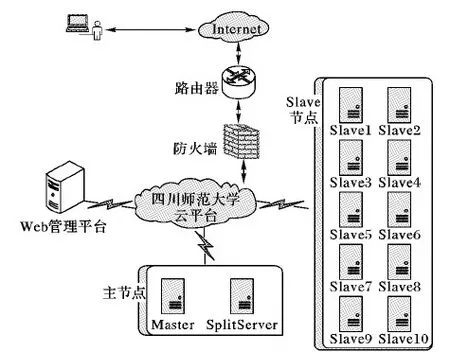
图7 节点网络拓扑Fig. 7 Node network topology
Master节点与Slave节点配置文件基本一致。通过配置一个初始节点,再通过私有云Web管理后台对该节点进行复制、重新分配网卡MAC、重新分配IP的方式快速创建其他节点。
Hadoop配置目录中的slaves文件指定集群由哪些节点组成,每行分别填写节点名“slave1”至“slave20”,由20个节点组成slaves集群。
4.3 实验结果与分析
本节实验对象选取3个不同编码的视频文件。根据具体实验,选取相应视频文件进行实验分析,因视频文件通常带有较多参数信息,不同的参数会在解码和编码过程中,对视频文件产生不同的损益。视频文件的主要参数如表6所示。
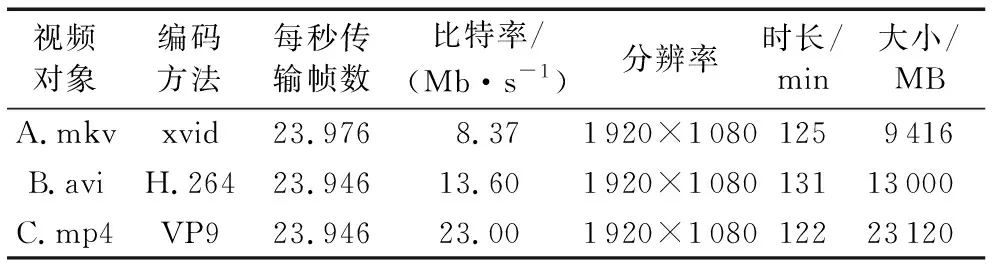
表6 实验视频对象信息表Tab. 6 Experimental video object informationTable
4.3.1 视频分片大小实验与分析
SplitServer切分的视频分片保存在HDFS中,切分依据为时间长度(单位为ms);通过不同的时长产生不同大小的视频分片文件。HDFS默认块大小128 MB,视频分片大小根据视频文件的格式、码率、分辨率的不同而有差异。本实验分别设置不同时长,分析不同大小的视频分片的转码效率。视频分片大小对转码效率的影响如图8所示。
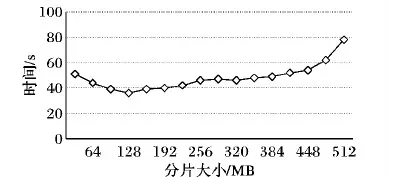
图8 视频分片大小对转码效率的影响Fig. 8 Effect of video fragment size on transcoding efficiency
由图8可知,在视频分片大小为128 MB时,可得到最高转码效率,即当文件越来越接近HDFS块文件时,网络开销越小;当文件大于HDFS块大小时,需要从多个节点的多个块中读取数据,网络开销增大,任务处理时间变长。
4.3.2 流处理产生DStream时长实验与分析
Spark Streaming依据StreamContext()设置的参数产生DStream,本实验分别设置不同时长,分析相应的转码效率。DStream产生间隔对转码效率的影响如图9所示。
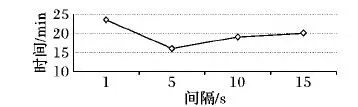
图9 DStream产生间隔对转码效率的影响Fig. 9 Effect of DStream production interval on transcoding efficiency
由图9可知,随着时间间隔的增大,转码效率逐渐提高,在时间间隔为5 s时,可得最高转码效率,然后随着时间间隔增大,效率逐渐变低,并且逐渐稳定在20 min。太短的时间间隔会产生冗余的空作业,减少空作业是优化的一个方向;时间间隔增长时,因硬件配置的限制,集群性能无法应对短时间的大量转码作业,造成作业积压,根据调度算法,将处理作业加入队列,流处理的实时性降低。
4.3.3 视频不同编码互转实验与分析
本实验对常见的视频编码之间的相互转换进行分析,封装格式为MKV。实验对象如表6中A.mkv所示。
本实验选取3种常见的视频编码进行互转码实验,为了结果的准确有效,使用控制变量法,对A.mkv进行转码时,除编码方法外,其他参数不作调整,如表7所示。
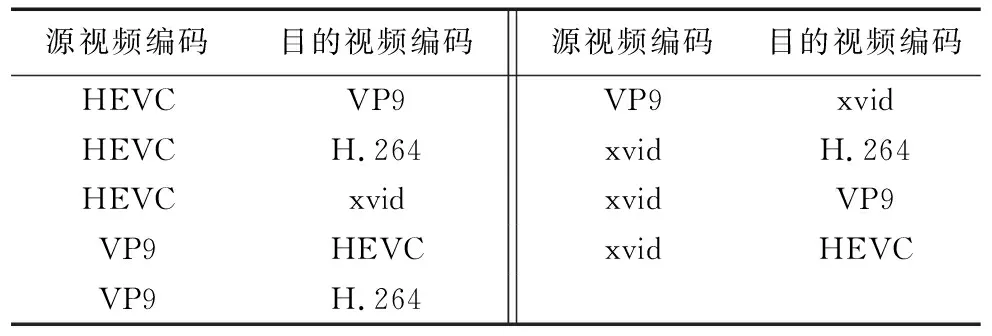
表7 编码相互转换设计Tab. 7 Coding mutual conversion design
因为相同编码的视频转码实际上是将原来的数据进行复制,没有进行解码、重编码工作;所以对相同视频转码的转换时间开销设置为“1”。对表6中的视频文件进行不同编码的转制,不同视频编码的转码效率如图10所示。
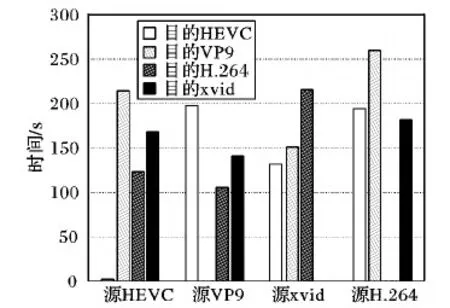
图10 不同视频编码的转码效率Fig. 10 Transcoding efficiency of different video encoding
实验结果表明,不同的编码之间进行转换效率差异很大。不同的视频编码,有不同的编码算法。设有A、B视频文件分别用A1、B1编码算法进行编码。视频转码的流程如图1,原理是首先将A视频按照A1算法进行解码,得到视频帧,将视频帧按照B2进行编码,得到B视频。因此,不同的视频编码因为算法的不同,效率也不同。
4.3.4 源视频与切片时长关系实验
通常码率越大、分辨率越高的视频占用的空间也会越大。通过对不同大小的源视频进行不同方式的切片实验,有助于发现最高效的切分方法。本实验对源视频大小/切片大小进行实验,为了避免相同视频编码方法的相互转换,本实验的目标视频编码为MPEG-4,封装格式为avi。不同时间长度的视频文件转码效率如图11所示。
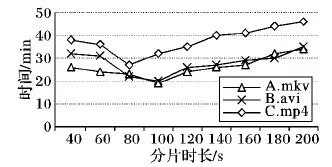
图11 不同时间长度的视频文件转码效率Fig. 11 Video file transcoding efficiency with different time lengths
由图11分析可知,源视频的参数不同,切分的视频分片大小不同,转码效率也不同。
4.3.5 节点/CPU核心数量对转码效率的影响
1)节点数量-转码效率。
通过对集群节点数量进行调整,发现节点数量与转码效率的关系。本实验共启用20个节点,每个节点分配1个CPU核心。起始节点数量从2开始,依次递增1。实验对象为A.mkv、B.avi、C.mp4,三个视频文件不分次序转码为flv格式,编码为H.264,10次实验后取均值,结果如图12所示。
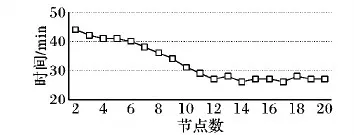
图12 集群节点数量对转码效率的影响Fig. 12 Effect of number of cluster nodes on transcoding efficiency
由图12可以看出,随着节点的增加、集群计算能力的增强,视频转码消耗的时间不断减少。在分布式系统中,节点的增加也意味着分布率的提升。在Spark Streaming中,同一个节点,可能同时运行着多个CPU核心。在节点数量为11时,转码效率没有进一步提升,随着节点数量的增加,三个视频文件的转码总时间在27 min左右。该实验结果表明,当集群节点达到一定规模、转码任务不变的情况下,随着集群节点的增加,并不能带来效率的继续提升。通过查看日志发现,部分节点并没有执行转码任务,处于空置状态。
2)CPU核心数量-转码效率。
本实验通过更改Spark Shell程序提交参数,完成对CPU核心数量的关闭/启用,命令格式如下:
spark-submit --master spark:master:7 077 --spark.cores.maxNa.jar
将N取1~10。实验对象为A.mkv、B.avi、C.mp4,三个视频文件不分次序转码为flv格式,编码为H.264,10次实验后取均值,得到运行结果如图13所示。
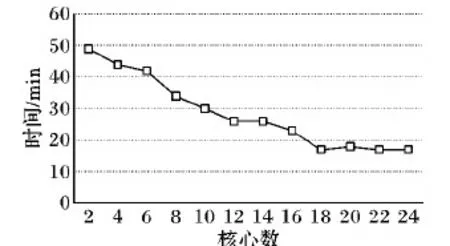
图13 集群CPU核心总数量对转码效率的影响Fig. 13 Effect of total number of cluster CPU cores on transcoding efficiency
集群使用的CPU总核心数量越多,视频转码消耗的时间越小,转码效率越高,至18个时,效率没有随着核心数的增多而提升,这与增加集群节点数量的趋势大致相同。进一步研究节点数量与集群CPU总核心数量之间的转码差异,结果如图14所示。
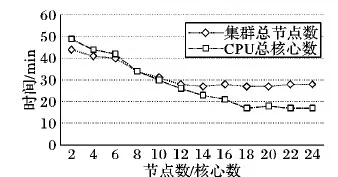
图14 不同集群总CPU/核心数量的转码效率对比Fig. 14 Transcoding efficiency comparison of of different cluster total CPUs/cores
从图14中可以看出,随着集群节点数量与集群CPU总核心数量的增多,视频转码效率在不断地提升;但当集群总节点数与CPU总核心数为8个时,两者转码用时相同;继续增加CPU核心数量和节点数量,CPU核心数量的增加能带来更高的效率。集群节点数在12个时,达到最大转码效率;CPU总核心在集群节点数为18个时达到最大转码效率。结合Spark调度原理,可进一步分析出现这种差异是因为调度管理器会优先将作业交给已经存储有视频分片的节点进行处理,从而降低数据在集群中传输带来的网络开销。
4.3.6 不同平台实现的视频转码系统对照实验
目前使用Hadoop实现的分布式视频转码方法很多,相关学术研究资料丰富,视频转码方案也很成熟。本文对文献[15]、文献[19]、文献[20]的Hadoop的分布式转码方案进行了研究;改进了需要手工进行视频分片的问题,进一步实现了一套基于Hadoop的分布式视频转码系统。因为Spark Streaming与Hadoop有良好的兼容性,所以两者可在相同的硬件环境中运行,因此,可认为基于Hadoop分布式的视频转码方案与基于Spark Streaming的分布式流处理视频转码方案有相同的硬件和软件环境。通过对三个不同的视频文件进行转码,探索基于Spark Streaming实现的转码系统与基于Hadoop实现的视频转码系统中的效率问题。实验对象信息如表6所示。
分别使用基于Hadoop实现的分布式转码系统和基于Spark Streaming实现的分布式流处理转码系统对A.mkv、B.avi、C.mp4进行目标编码方法为MPEG-4的转码。通过10次实验,每项结果取平均值,结果如图15所示。
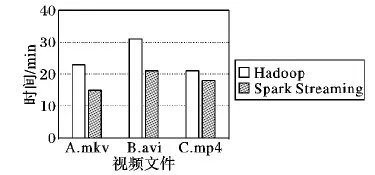
图15 Hadoop与Spark Streaming分布式转码系统效率对比Fig. 15 Efficiency comparison between Hadoop and Spark Streaming distributed transcoding systems
通过图15可以得出,基于Spark Streaming实现的分布式流处理视频转码系统比基于Hadoop实现的分布式转码系统的转码效率提升了26.7%。理论分析结果表明,在视频文件切分到视频分片转码环节,不需要视频文件全部切分完成即可进行转码工作,通过Spark构建的DAG任务模型节省了这部分的时间开销,提升了转码效率。
4.3.7 与文献[19]的视频转码方法对照实验
本文按照文献[19]提出的基于Hadoop平台的视频并行转码方法,实现了一种基于Hadoop的视频转码系统,与基于本文所提出视频转码方法实现的原型系统进行对比实验。实验硬件配置为4个节点(CPU为双核1 GHz、内存为16 GB),通过四川师范大学私有云快速创建与该硬件参数相近的节点。实验选取了三个视频文件作为实验对象[19],参数如表8所示。
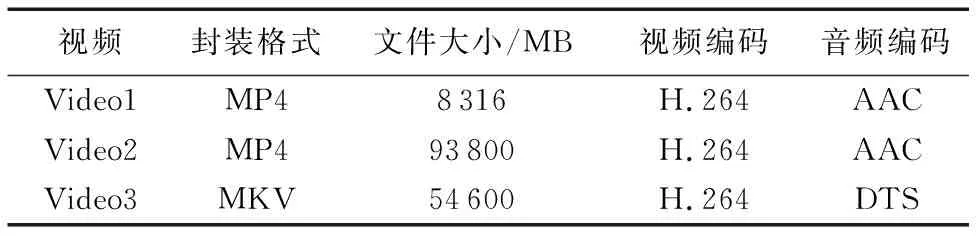
表8 视频文件信息Tab. 8 Video file information
表8中的实验对象通过FFmpeg对一段视频进行处理生成,实验规定了视频转码后的目标参数[19],如表9所示。

表9 视频转码参数Tab. 9 Video transcoding parameters
针对同一视频进行了10次实验,取平均转码时间,实验结果对比如图16所示。

图16 不同方案的转码效率对比Fig. 16 Transcoding efficiency comparison of different schemes
和文献[19]的方法相比,本文方法对Video1的转码效率提升21%,对Video2的转码效率提升了19.7%,对Video3的转码效率提升了19.6%;三个视频的平均效率提升了20.1%。对比实验结果表明,本文提出的视频转码方法较文献[19]方法效率显著提高。
5 结 语
现有的单机视频转码方法存在的转码速度较慢、瓶颈等问题给用户带来较差体验;现有的基于Hadoop的并行转码方法比传统单机转码在转码速度上有较大提升,但其面向批处理的特点决定了转码过程存在较多等待时间,使得转码效率提升不够充分。为此,将Spark Streaming引入到视频转码的设计之中,提出了一种面向流处理的基于并行计算的快速视频转码方法。实验表明,所提出的基于Spark Streaming的视频转码方法在转码效率上有显著提升。本文所提方法也有不足,即当任务量太大时,集群超负荷工作,也会形成队列工作。同时,本文采用Fair调度算法,没有针对视频流的特点进行算法上的改进。因此在使用分布式流处理技术进行的视频转码工作,仍有很大的改进空间。
猜你喜欢
词学(2022年1期)2022-10-27
计算机系统应用(2022年5期)2022-06-27
电子科技大学学报(2022年3期)2022-05-28
电脑报(2021年23期)2021-07-23
缔客世界(2020年1期)2020-12-12
火控雷达技术(2018年4期)2019-01-15
现代职业教育·中职中专(2018年2期)2018-05-14
电脑知识与技术·经验技巧(2017年9期)2018-02-24
电脑爱好者(2016年24期)2017-01-05
中小学信息技术教育(2009年11期)2009-12-23
