
融合Slope One的神经网络协同过滤算法研究
2019-01-22 06:54刘琦罗玉
现代计算机 2018年35期
刘琦,罗玉
(西华大学计算机与软件工程学院,成都 610039)
0 引言
在信息爆炸的时代,推荐系统在减轻信息过载方面发挥了巨大的作用,被众多在线服务,包括电子商务、网络新闻和社交媒体等广泛采用。个性化推荐系统的关键在于根据过去用户交互的内容(评分、点击),对用户对项目的偏好进行建模。个性化推荐技术中运用的推荐算法虽不尽相同,但基于协同过滤算法的推荐由于其简单性、准确性、有效性等优势成为目前应用最广泛的个性化推荐算法。
数据稀疏性一直以来都是协同过滤算法的一大难题,对此,国内外学者进行了大量的研究。有些研究者认为数据稀疏性问题会从近邻搜寻不够准确和近邻评分过少两方面对协同过滤产生不利影响。还有些学者针对推荐系统中的数据稀疏性和冷启动等问题,对社会化推荐系统在信任推理以及推荐关键技术等方面做了比较全面的综述。
本文就近邻评分数据过少,先通过原始数据得到初步的用户相似度和每个用户的近邻,利用Slope One算法计算评分预测值来填充数据,并基于填充后的数据修正相似度和优化近邻选取集合,最终给出目标用户的推荐列表。实验数据集来自MovieLens-100K数据集。
1 算法实现
1.1 Slope one算法
Slope One算法是一种基于物品协同过滤的算法,它的一个主要优点是简洁性、容易实现、执行效率高,推荐的准确性相对传统的基于用户和项目的协同过滤算法也较高。Slope One算法来自Daniel Lemire和An⁃na Machlachlan的论文Slope One Predictors for Online Rating-Based Collaborative Filtering。
Slope One算法是基于不同项目之间的评分差来预测用户对于物品的评分,步骤主要分为两步:
(1)计算偏差
计算项目之间的偏差,记devi,j为评分偏差(两个项目要被同时评分),如公式(1)所示:

其中,card(S)是S集合中的元素个数,X是整个评分集合。因此,card(Si,j(X))是所有同时对i和j进行评分的用户集合。如表1所示:
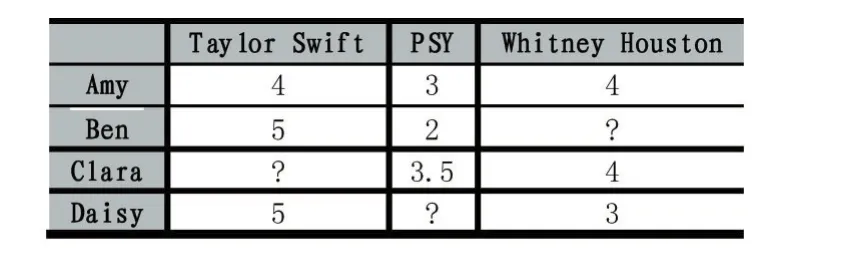
表1 四个用户对三个乐队的评分矩阵
评分区间为1-5之间(1分为最低分,5分为最高分),其中“?”表示缺失项。考虑PSY到Taylor Swift的评分偏差。这种情况下,card(Si,j(X))就应该是2,这是因为有两个用户(Amy和Ben)同时对PSY和Taylor Swift进行了评分。ui-uj是用户对Taylor Swift的评分减去其对PSY的评分。因此,偏差结果为:
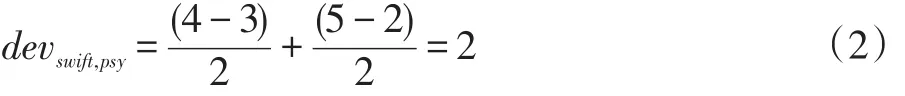
于是,PSY到Taylor Swift的评分偏差为2,这也意味着用户对Swift的评分平均要比PSY高2分。同样,可以得到Taylor Swift到PSY的评分偏差为:
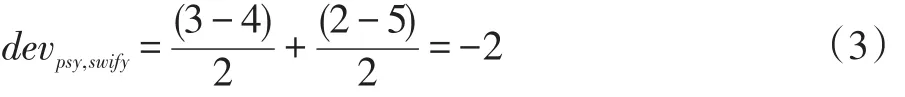
(2)利用Slope One算法进行预测
现在我们拥有了一个非常大的偏差数据集,然后便可以利用该数据集进行评分预测了,公式如下:
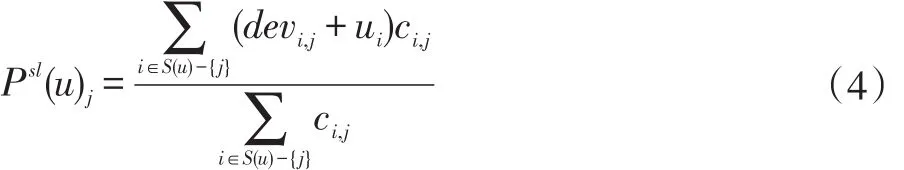
1.2 基于神经网络的协同过滤算法
其中,ci,j=card(Si,j(X)),表示同时对项目i和j有过评分的用户个数。psl(u)j表示用户u对项目j的预测评分。例如 psl(Ben)WhitneyHouston指的是Ben对White Hous⁃ton的预测评分。
“协同过滤”概念最早是由GlodBerg等人在上世纪90年代中期设计Tapestry推荐系统时提出的。近些年随着学者们深入研究和应用,协同过滤技术也得到了长足发展。目前协同过滤技术大体分为三类,分别是基于用户的协同过滤、基于物品的协同过滤以及基于模型的协同过滤。
在基于内存的协同过滤算法中,是通过寻找相似来进行推荐。例如在基于用户的协同过滤算法中,假设要完成的任务是推荐一本书给用户,则算法搜索出与你兴趣类似的其他用户,一旦找到该用户,就看看这个用户所喜欢的书然后将它们推荐给你。又例如在基于物品的协同过滤算法中(上述的Slope One就属于这类算法),算法会计算出书籍之间的相似度,然后推荐给用户消费过的相似书籍。
基于神经网络的协同过滤是基于模型的协同过滤,其本质其实也是一种机器学习模型。本文采用DNN网络进行设计。模型分为三层,分别是输入层、隐藏层以及输出层。输入层输入的是由用户特征和物品特征连接形成的输入向量。输出层是一个神经元,输出的是对物品的评分。在本文中,我们将某用户的评分情况作为它的特征向量,例如在表1中的某一行。我们将某物品的被评分情况作为它的特征向量,例如在表1中的某一列。在本文中,隐藏层的激活函数采用的是relu,输出层的激活函数采用的是sigmoid。因为我们的输出层的输出范围是0~1之间,而标签数据是1~5之间,所以我们还要事先将训练标签归一化处理,这样,标签数据也就映射到0.2~1之间。本文采用随机梯度下降法发来训练网络,代价函数采用的是均方误差(MSE):
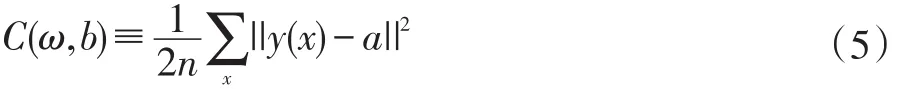
其中,y(x)是我们的预测值,a是我们的实际值,a的取值范围在0.2~1之间。可以看出,本质上该模型其实与基于用户协同过滤有相同点,不过该模型的优点在于它还考虑了特征与评分之间的非线性关系。
1.3 融合Slope one的神经网络协同过滤模型设计
本模型主要分为两个模块:①矩阵填充模块:通过Slope One算法先将原始稀疏的用户-物品矩阵进行填充,该算法对比其他的填充算法(均值、中值等),它避免了填充过于单一的问题,填充的分数可信度也更高。②基于神经网络的评分模块:利用填充过后的用户-物品评分矩阵,然后训练神经网络,这样就一定程度上避免了矩阵过于稀疏的问题。
算法流程根据上述模型,整理算法流程如下:(1)输入原始稀疏的评分矩阵;
(2)对每一个物品计算它与其他物品的评分偏差并得到偏差数据集;
(3)利用偏差数据集进行评分填充,得到填充过后的稠密矩阵;
(4)将得到的稠密矩阵送入网络中进行训练;
(5)用训练得到的神经网络进行评分预测。
2 实验设计
2.1 实验数据
使用的数据集是来自美国明尼苏达州立大学的GroupLens研究小组整理的MovieLens标准数据集。本次采用里面的ml-100k数据集。该数据集包含了943个独立的用户对1682部电影作品的10条评分数据,数据的稀疏程度为0.063。该数据集有三个数据文件:存储了用户信息的users.dat,存储了电影信息的movies.dat和存储用户对电影评分信息的ratings.dat。本次实验使用第三个数据文件即可,即ratings.dat。rat⁃ing的范围在1~5之间,数值越大,表明用户对该部电影的评价越高,反之越低。
2.2 评价指标
推荐系统的评估大体分为两类:离线测试和A/B测试。离线测试是在线下通过准备好的测试集对模型进行测试。A/B测试是一种线上测试方法,通过将用户随机分为两组,然后对这两组用户分别使用不同的推荐算法,然后通过用户的点击率购买率等来判断两种方法孰优孰劣。本次实验采用均方根误差(RMSE)作为评测指标。公式为:

2.3 实验设计与分析
实验使用Python作为开发语言,我们将数据集90%作为训练集,10%作为测试集。并且我们与其他算法做对比实验,实验结果如表2所示:
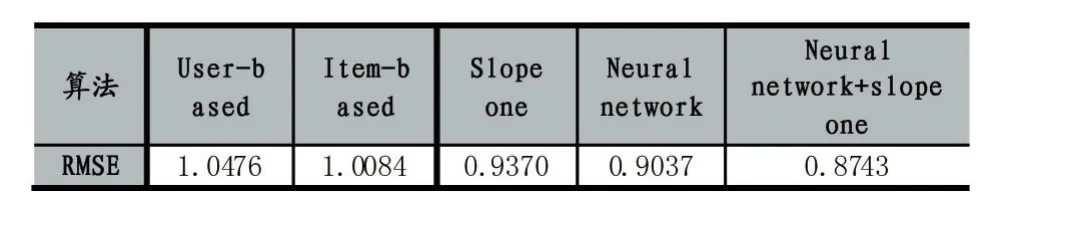
表2
从实验结果可以看出,我们提出的方法在与另外四种方法的对比中得到了最小的RMSE值。
3 结语
评分数据过于稀疏的问题一直是一个影响推荐效果的因素,在一定程度上缓解了协同过滤推荐中的数据稀疏性问题,并弥补了空值填补法填补值过于单一的问题。随后,在填充后的用户-项目评分矩阵下给出推荐列表及测试集的预测值,并与其他协同过滤推荐算法进行比较,结果表明本文算法可以改善数据稀疏性问题,并推高推荐系统的推荐质量。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
现代电力(2022年2期)2022-05-23
商界评论(2022年1期)2022-04-13
疯狂英语·初中天地(2021年11期)2021-02-16
学生天地(2020年6期)2020-08-25
电子制作(2019年19期)2019-11-23
少年漫画(艺术创想)(2019年2期)2019-06-06
电子制作(2019年24期)2019-02-23
草原(2018年2期)2018-03-02
北京航空航天大学学报(2017年3期)2017-11-23
