
节能标准信息检索创新思路
2019-02-06 01:33卫珂玢大庆油田技术监督中心标准化研究所
石油石化节能 2019年12期
卫珂玢(大庆油田技术监督中心标准化研究所)
众所周知,节能减排一直是企业降本增效的重要手段,而节能标准是企业乃至国家节能制度的基础,是化解产能过剩、推动建设绿色生态环境的有效支撑。节能标准信息的采集是标准使用者吸收节能专业关键内容的有效手段,但随着标准化信息技术的不断创新,标准信息使用者的要求不断多样化,仅针对标准名称、编号进行检索的标准信息处理技术无法满足以下需求:
1)由于节能标准中标准信息的多元化,导致检索者无法精确查询所需要的标准信息。
2)需要采集不同标准中的节能数据或相关技术指标进行对比分析。
因此,需要研究基于节能标准内容的标准检索技术,通过对标准相关内容进行分析和有效组织,提供一个更加丰富详细的标准信息处理工具,满足使用者提取不同标准信息内容的需求。
1 标准层次结构梳理
1.1 标准内容层次结构
若按照GB/T 13017—2008《企业标准体系表编制指南》,可将现有标准数据分为技术标准、工作标准、管理标准[1]三大类。不同类别标准的内容层次繁多,很难统一。如:技术标准中包含技术指标、术语、要求和方法等层次;工作标准包含设备维修保养内容;而管理标准包含管理方法、考核细则等。通过对所有标准结构层次进行分析,确定标准层次(表1)。
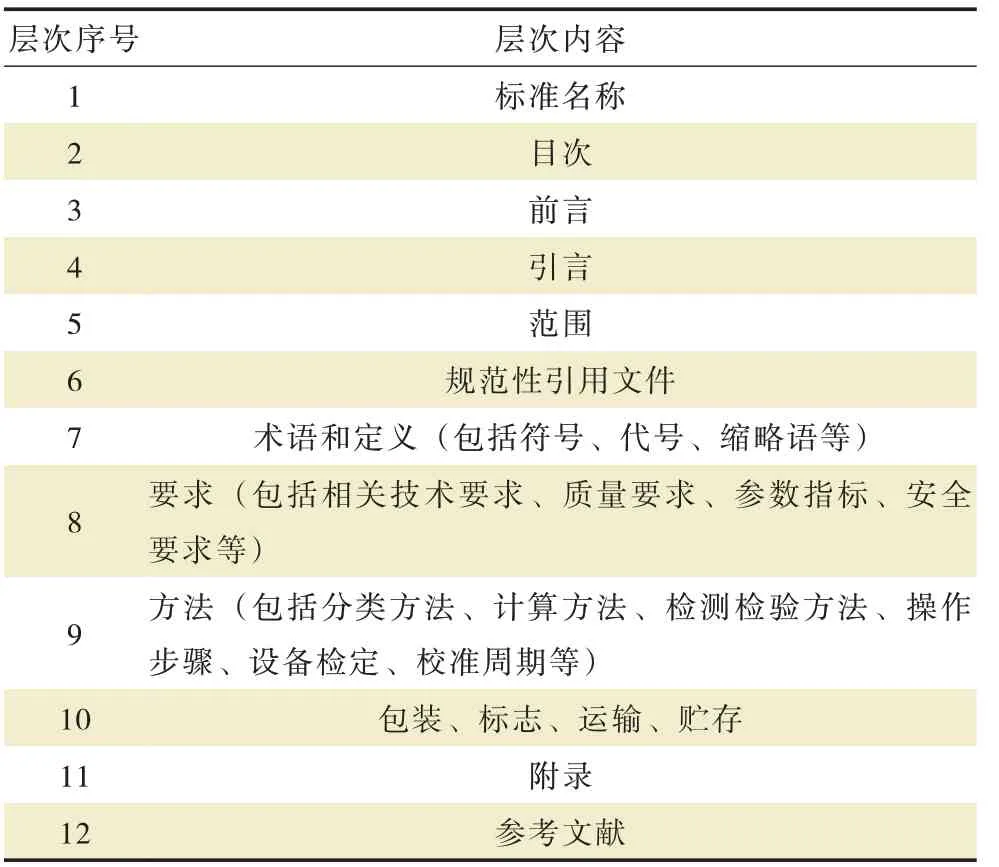
表1 标准结构层次
1.2 标准内容关注度排序
通过梳理出标准内容层次结构,科学、合理地设计调查问卷,对高频使用标准的技术人员和提供技术指导的相关专家展开问卷调查,以确定各部分标准内容关注度的排序情况,为设置权重规则奠定基础。标准内容关注度反馈数据如图1所示。
标准内容关注度排序结果如下:
第一,方法、要求;
第二,标准名称、范围;
第三,术语和定义;
第四,目次、前言;
第五,附录、规范性引用文件、参考文献、包装、标志、运输、贮存、引言。
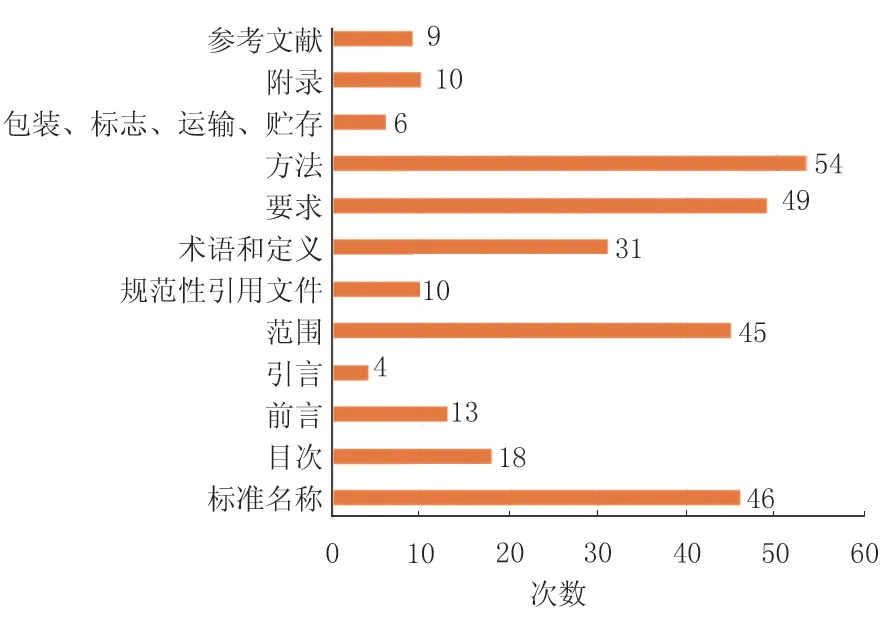
图1 标准内容关注度排序
2 建立节能专业标准索引集
以节能标准为基础数据,前期搜集节能标准共171项,梳理标准之间内部层次。按照标准体系建立原则,建立节能专业标准体系,对标准体系内171项标准内容进行索引提取,以标准范围、主要技术内容为对象,提取多个关键词。例如,GB/T 12325—2008《电能质量 供电电压允许偏差》的主要技术要求包含电压、偏差、限值、测量、合格率等关键指标。提取索引时,将这些关键指标作为该标准的次关键索引,以此类推,从而建立标准索引集。最终提取索引共513项,其中关键索引312项,次关键索引201项。
3 建立语义关联模型
3.1 语义相似度计算方法
现阶段常用三种语义相似度计算方法[2]包括基于语义理解的相似度算法[3]、基于汉明距离的相似度算法[4]、基于向量空间模型的计算方法[2]。三种方法对比如表2所示。
由表2可知,基于语义理解的相似度算法遵循词义间结构层次关系的语义树进行计算。该语义树[3]包括实体、属性值、数量值、特征值等数据集合,与使用的节能标准内容所包含的技术指标、数值计算、操作步骤等概念属性不谋而合;其次,该方法描述的概念含义的抽象性与其所表达的数据源所在位置相关,与根据检索词在标准内容关注度排序情况下设置权重规则的理念相同。
结合搜集的171项节能标准提取的关键索引,以及各关键索引语义关联度,可知基于语义理解的相似度算法最为科学合理,其计算公式[2-3]为
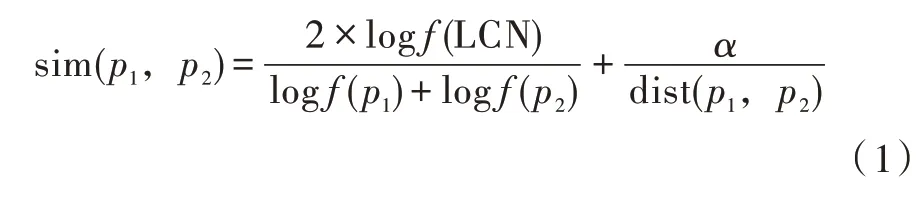
式中:f(p1)、 f(p2)分别为词p1、p2在语义树中连接的节点数(含自身)/语义树总节点数;LCN为两个词最小公共节点;dist(p1,p2)为p1、p2在语义树中的路径距离;α为可调节变量。
3.2 语义树
由语义相似度算法比较及计算公式可知,基于语义理解的相似度算法依据的核心模板为语义树[3]:根据标准体系内部各标准间层次,遵循标准体系内在逻辑关系,结合索引集关键分词,设立父节点和子节点,建立节能专业语义树,如图2所示。
3.3 权重规则
检索词权重值计算规则[3-5]为
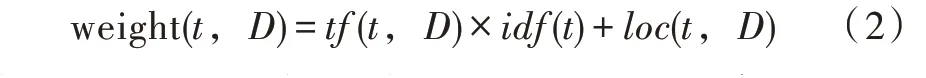
式中:tf(t,D)为标准中词语t出现的频率;idf(t)为与标准频率成反比关系的倒置标准频率[6];loc(t,D)为词语t在标准中的位置。
结合标准内容关注度排序情况,赋予标准不同层次不同的权重分值:排名第一的“方法、要求”分值最高,排名最后的“附录、规范性引用文件、参考文献、包装、标志、运输、贮存、引言”分值最低,记为loc(t,D)。在语义树中,越深层次的索引越具有技术指向性,权重分值也最高。
3.4 语义关联模型
基于以上研究内容,建立语义关联模型[7],即
f(i)=语义相似度×检索词权重值 (3)
式中:f(i)为一个反馈结果集合,即f(i)∈{标准检索库标准};语义相似度为检索词与索引集索引匹配程度,若与索引精确匹配,则相似度为1;若无任何相似,则相似度为0。

表2 三种语义相似度计算方法比较
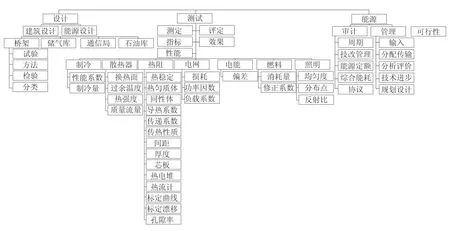
图2 节能专业语义树(部分)
4 验证
在验证程序中输入关键词(评价指标),将程序反馈出的数据结果与现有标准数量进行对比,用以验证提出的语义关联模型的准确率。实验环境为:windows7系统,4G内存。
计算公式中参数虽然还需进一步做出相应的调整,但建立的语义关联模型所计算出的合格率基本符合建立的节能标准检索库中标准检索的要求,实现了基于标准内容检索的初步想法,为进一步研究标准内容检索技术提供了关键性的技术支持。
5 结束语
节能作为企业降本增效的重要手段,其标准化功能也应具备高效的要求,在节能标准信息处理方式上需要进行创新,以满足节能标准使用者日益增加的技术需求。
在现代数据检索技术日趋完美、云计算逐渐完善的大环境下,打破固有的标准检索模式,通过对搜集的节能标准相关内容进行有效组织,建立检索内容相关性表达模型,研究出基于标准内容的检索理论方法,将标准化检索手段推进新的发展阶段,将标准信息处理能力上升新的高度,成为标准化信息的重要处理工具。该创新成果不仅可用于节能标准数据的处理方式中,也能用于各行各业标准关键信息的提取方式中。因此,标准检索系统研究成果的开发可进一步提高标准化信息系统的效益空间,该技术将成为标准化领域的“百度”和“知网”,对中国标准化领域在国际地位的提升具有一定的指导意义。
猜你喜欢
中老年保健(2022年1期)2022-08-17
江苏钢铁(2022年9期)2022-07-02
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
领导决策信息(2017年15期)2017-06-22
领导决策信息(2017年11期)2017-05-17
小雪花·成长指南(2016年11期)2016-12-07
国际公关(2015年10期)2015-12-17
