
一种改进的MTCNN人脸检测算法
2019-02-07 05:32吴纪芸陈时钦
软件导刊 2019年12期
吴纪芸 陈时钦

摘要:人脸检测主要运用于机场、火车站等人口密集场所。目前常用的人脸检测算法有MTCNN、YOLOV3、faster-RCNN、SSD等,但已有算法难以兼顾检测速度和检测准确性。通过改进多任务级联卷积神经网络(MTCNN)人脸检测算法,将MTCNN、YOLOV3、faster-RCNN等3个模型进行整合,减少内存与显存之间的数据搬运;然后动态修改Minsize值,减少图像金字塔中图片生成数量,并根据图像相似度对输入图片进行不同处理以提高效率。改进后的MTCNN算法比传统MTCNN算法识别速度提高将近40%,且正确率达到97%,可更好满足现代社会对于人脸检测的应用需求。
关键词:多任务级联卷积神经网络;最小人脸大小;图像金字塔;自适应;人脸检测
DOI:10.11907/rjd k.191728
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2019)012-0078-04
0引言
人脸检测技术应用场景丰富,如通勤人脸打卡、机场、火车站等闸机通道;公安机关通过分布在各处的摄像头,运用人脸检测技术识别犯罪分子;高速公路通过摄像头检测查获超速的司机等,人脸检测技术已渗入众多行业,成为社会生活中不可或缺的一部分。
但在实践中人脸识别技术还存在一些不足,如人脸检测速度较慢,乘客无法快速通过闸机;高速抓拍系统有时无法抓拍到违章司机面部。除去硬件原因,人脸检测算法速度与准确率也有待改进。
目前常见的人脸检测算法是多任务级联卷积神经网络(Multi-task Cascaded Convolutional Network,MTCNN),其检测准确性极高,且能检测到正脸、侧脸,一般只需具有眼睛、鼻子或嘴巴其中一种特征的照片即可识别,但缺点是检测速度较慢。
MTCNN主要分4个步骤:首先将获取到的图像进行不同尺度的缩放,构建一个图像金字塔以检测不同尺寸的人脸图像;其次,将缩放后的图片分别传入PNet层,该网络结构主要获得边界框回归向量以及人脸区域的候选窗口。通过非极大值抑制(NMS)去除重合度很高的候选框,并通过回归向量进行校正;然后,从PNet层输出数据再传入RNet层,该网络结构依然通过边界框回归和NMS去掉高度重合的区域,但由于该网络结构与PNet网络结构有差异,增加了一个全连接层,所以会取得更好的抑制作用;最后,将RNet输出的结果传人ONet层,该层相比于RNet层增加了一层卷积层,所以对面部细节的处理更加精细,其作用与RNet层一样,但因为该层对人脸区域进行了更多的监督,所以最后可输出具有人脸特征的框图。
MTCNN算法使用圖像金字塔,可适应不同的人脸图像,使经过缩放的人脸图片更接近训练时使用的图片大小(20*20),因此检测准确性很高,但也因此图像缩放及各层间数据传递、内存与显存间传递时耗较大。
本文研究内容是如何在现有MTCNN人脸检测算法的基础上,既提高检测速率又保持原有准确性。基于MTCNN算法的基本框架,研究该算法中最影响速度及准确性的PNet模型,根据画面相似度,决定是否改变传人模型最小人脸大小(MinSize),从而减少金字塔图像数目;并将MTCNN 3个模型(PNet、RNet、ONet)合并在一起训练,整合成一个模型,减少数据从内存到显存的次数,加快人脸检测速度;且在图像前处理时,判断画面是否改变,如果相似度大于95%,则使用上一轮输出结果,可大幅提升人脸检测速度,又不影响人脸检测准确性。在图像预处理阶段,将缩放后的金字塔图像整合在一张4K(根据实际情况可以修改)大小的画面上,同时传人缩放后图像的位置信息,与原算法将缩放后的图片逐一导入模型块的做法相比,速度大幅提升。
1MTCNN人脸检测算法改进
1.1MTCNN算法思路改进
(1)动态修改最小人脸大小。MTCNN算法中3个阶段时间占比如图1所示,从图中可以看出Pnet阶段时耗最大,如果图片超过720p,其图像金字塔生成过程时耗最大,且后续还要将生成的多张图片分别传人后端进行计算。因此本文根据最耗时的PNet阶段,动态优化MinSize参数。从图2可知,MinSize直接影响第一阶段的循环次数,本文根据模型后端输出适合的MinSize值与图像匹配(大图用大的MinSize,小图用小的MinSize),可直接减少预处理阶段图像缩放次数,并且在图片金字塔生成过程中,仅对上一次缩放结果再进行缩放,而不是对全图进行缩放,可缩短缩放时间。
(3)将3个模型整合在一起。从表1可以看出。网络复杂度越高,GPU相对于CPU的计算优势越明显。MTCNN算法的3个阶段均是复杂度较低的网络,因此GPU的优势无法真正发挥。另外,MTCNN算法第一阶段生成的图像金字塔会反复多次调用相对简单的PNet、Rnet、ONet网络,导致数据反复在显存与内存间搬运,时耗甚至超过计算本身。因此将3个模型整合,可减少大量传输时间。
(3)相似度大于95%的图像不再传人模型。因为大部分从相机传人的图像是半静止画面,如静止的人物或头部等,无需将图像经过多重处理再传人模型,因为即使再次传人,得到的结果也几乎与原图输出结果一致。
(4)将缩放后的图片拼接在一起传人模型。在图像金字塔生成过程中将生成多张经过缩放后的图片,如果将图片逐一传人模型,将增加内存到显存的传送次数,拖慢算法速度。
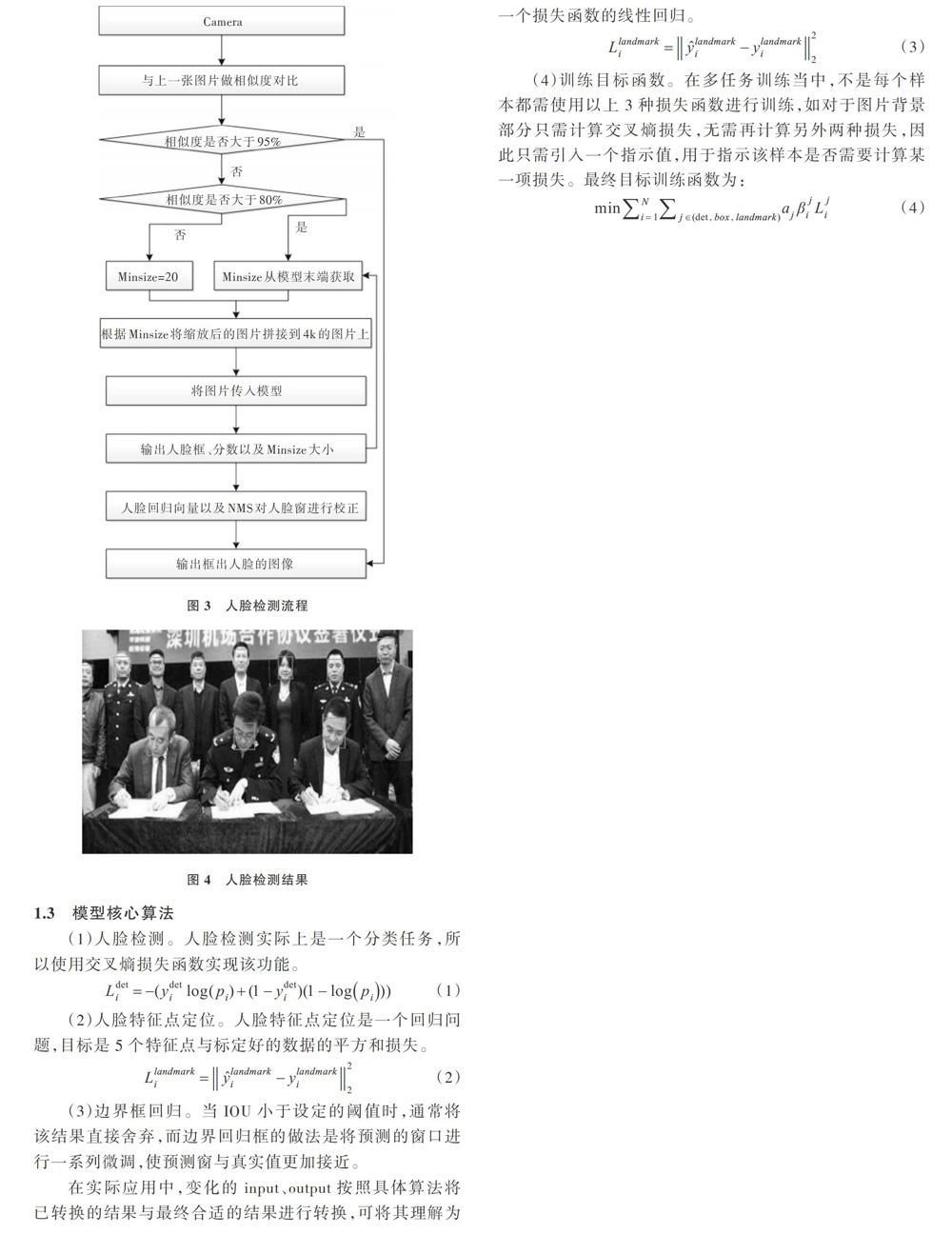
1.2人脸检测流程
(1)从相机(1080p)获取图片,默认设置最小人脸大小(MinSize)为20。
(2)通过MinSize值,将缩放后的图像金字塔图片拼接在一张4K大小的图片上,将拼接后的图片及每张缩放图片在4K图片上的位置信息传人模型中。
(3)通过欧式距离相减计算两张图片相似度,如果前后两张图片的相似度大于80%(因为实际从相机获取的图片多为半静止画面,画面变动比较小),则使用上一轮从模型后输出的MinSize,若相似度小于80%则设置为20。
(4)如果两张图片相似度大于95%,直接输出上一张图片的结果,不拼接图片也不将数据输入模型。
(5)重复以上所有步骤完成人脸检测。具体流程如图3所示,检测结果如图4所示。
(5)非极大值抑制NMS指通过某种方式抑制并非极大值的元素。使用该方法可快速去掉标定为不准确且重合度很高的预测窗口。
在模型初始阶段,会框出很多重合的人脸候选框,使用非极大值抑制可去掉预测分数比较低的窗口,选取分数比较高的窗口,再将对应的预测窗口从模型后端输入。
具体实现方法如下:假设有6个预测的矩形框,并将其按概率从高到低排序,依次为a>b>c>d>e>f:①从概率最高的矩形框a开始,分别判断从b到f与a的重叠程度是否大于预先设定的某个阈值;②假如b,c与a的重叠程度(IOU)超过阈值,则舍弃b与c,并标记矩形框a为经过筛选保留后的结果;③从剩下的矩形框d、e、f中,选择概率最大的d,然后判断d与e、f的重叠程度,如果重叠度大于设置的阈值,则舍弃并标记d是经过筛选保留下来的第二个矩形框;④重复以上步骤,直到找到需要的所有窗口。
2MTCNN模型重建与训练
(1)将原有的pnet、rnet、oflet 3个模型拼接在一起,pnet的输出作为rnet的输入,rnet的输出作为onet的输入;将pnet、rnet的输出结果进行边框回归及非极大值抑制,再将处理后的数据传人下一层。
(2)从网上人脸库下载包含不同亮度、不同角度的人脸图片,并将其转换成20*20的图片,同时根据人脸情况,将其分成人脸(00.45)、部分人脸(0.45-0.8)、非人脸(00.45)。
(3)将数据拼接在一张4K的图像上,并将各张小图的信息传人模型中,直到结果收敛为止。
3算法验证
首先在一个空旷教室的4个角落分别布置好摄像头,并在教室里布置好桌椅。
要求30位志愿者坐在教室中进行不同的活动,利用相机将教室中的场景录制下来,拍摄时间为120分钟,预设场景包括:①全部并排坐着正对着相机,保持1分钟的静止状态;②并排坐着并适当转动脸,80%的人脸对着相机,保持1分钟的静止状态;③并排坐着,适当转动脸,50%的人脸对着相机,保持1分钟的静止状态;④并排坐着,适当转动脸,30%的人脸对着相机,保持1分钟的静止状态;⑤并排坐着,适当转动脸,10%的人脸对着相机,保持1分钟的静止状态;⑥在①、②的基础上调整光线亮度为正常亮度的4/5;⑦在①、②的基础上調整光线亮度为正常亮度的3/5;⑧在①、②的基础上调整光线亮度为正常亮度的2,5;⑨在①、②的基础上调整光线亮度为正常亮度的i/5。⑩让30位志愿者分别在房间里走动,不需要正对着相机,在志愿者走动的过程中,按步骤⑥一⑨调整光线亮度;⑩分别调整①一⑨中志愿者与相机的距离,使人脸大小分别为100*100、80*80、60*60、50*50、40*40、30*30、20*20。
按步骤①-⑩分别截取1分钟的录像,截取其中的图片,并将其拼接成4k的图片导人模型;需框出步骤①所得图片中所有人脸,并且输出的人脸分数在0.8以上;框出步骤②-⑤所得图片人脸,并且输出的人脸分数需在0.45.0.8之间(图像中至少有一个人脸特征);框出步骤⑥-⑨所得图片的人脸,但是分数递减;步骤⑩所得图片根据情况,如果有一个人脸特征,均应框出。
将步骤⑩中不同人脸大小的图片拼接传人模型,测试模型末端输出的最小人脸大小,如果输出结果不对,则需要再调整模型参数。
如果测试结果与预期结果不匹配,则根据本文人脸检测步骤重新训练,直到结果与预期结果相同为止。
4结语
本文提出改进的MTCNN算法,通过动态设置最小人脸,整合3个模型于一体,并且根据欧式距离计算相似度,不再检测相似度高的图片,既极大提高了检测速度,又保证了检测正确性。同时本文算法准确性依赖于训练样本是否全面,算法需用到大量人脸数据,还需训练不同光线、角度、长相的人脸,因此人脸库是否全面,很大程度上影响算法现实检测准确性。与原MTCNN算法相比,优化后的算法提高了近40%的速度,更能满足社会需求。
猜你喜欢
现代电子技术(2016年23期)2017-01-12
中国教育信息化·基础教育(2016年11期)2016-12-27
汽车科技(2016年5期)2016-11-14
中国新通信(2016年16期)2016-10-18
