
基于HBase的海量冠字号码多维索引研究∗
2019-03-01 02:52张重阳
计算机与数字工程 2019年1期
张 艺 张重阳
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
人民币冠字号码管理指的是对钱币的身份编号(冠字号码)进行记录、存储和分析。冠字号码的查询能助推货币政策的贯彻落实和实施,使银行与客户责任清晰,有效抑制洗钱、行贿、偷税等违法行为,及时发现问题钞票,为执法机关提供服务[1]。冠字号码在钱币的流通过程中扮演着非常重要的角色。在经济飞速发展的今天,银行业每天都会产生数量巨大的冠字号码信息,这对传统的人民币冠字号管理模式形成了很大的压力与挑战。目前各大银行冠字号码数据需要集中到总行管理,支持至少三个月的全行数据。
冠字号码数据是一种海量流数据,具有体量大、多维度、更新速度快等特点。由于现在银行业的发展,海量的冠字号码数据会随着时间序列连续产生。具有良好扩展性的HBase分布式数据库适合存储海量的冠字号码数据。但是由于HBase的设计特点,在数据的插入与查询实时性方面还有待提高,其原因为
1)实时数据插入效率问题。在HBase中,region是数据存储的基本单位。而面对海量时序数据时,如果某个时间段内数据特别大,数据则会按字典序依次插入某个region中,当这个region达到预设的阈值时,会触发split操作。而大量的split操作对数据插入效率影响很大。
2)多维数据查询效率问题。HBase采用的是键值对模型,对主键有着良好的查询效率。但是在多维度冠字号码的实际查询中,往往会根据在一定时间间隔内去查询某些条件,这种多维范围查询需要scan表中多个区域,消耗的代价很大。
为了解决这一问题,本文结合分布式数据库HBase与具体的冠字号码数据提出了一种基于时间序列的多维索引结构MT-index(Multi-dimensional index based on Time)。
2 相关工作
近年来,云计算技术的得到了学术界与工业界的广泛关注。而NoSql作为云平台中的分布式数据库也应用于越来越多的地方,这也推动了云数据管理索引技术[2]的发展。文献[3]最早提出了在云平台中使用索引技术,提出了一种在云环境中具有两层索引的计算框架。文献[4]提出了一种在主存建立列数据索引的方法。现主要的研究分为二级索引技术与全局局部索引结合的二层索引方式。
二级索引是一种常用的索引技术,主要应用于键值存储的云数据数据库系统中,如HBase。目前基于二级索引的方案主要有ITHBase、IHBase以及CCIndex[5]。其中,ITHBase与IHBase是开源的实现方案,其原理是索引表存放索引列与原表的键值信息,查询时先通过索引表得到键值再根据键值去原表查询数据。然而查询索引表时得到的键值是大量随机的,去原表查询时也需要通过大量随机查询才能得出查询结果。为此,ZOU等提出了互补聚簇式索引,称为CCIndex,CCIndex的方法是把数据的详细信息也放在索引表中,减少了大量的随机查询,减少了查询时间,但是会造成索引表空间的增大。CCIndex还给出了一种查询优化机制以支持多维查询。二级索引实现简单,维护代价较低,但是多维查询效率低而且空间冗余大。
文献[6]中提出了一种动态多维索引框架,先通过八叉树对云空间进行索引,再使用跳表随机访问层次化的八叉树索引,实现了多维查询,范围查询,动态索引缩放等。文献[7]提出了多种云索引方案,分别为CAN组织所有节点,R-树索引节点内数据;集中式R-树索引全局,KD-树索引节点;Chord覆盖网络并使用MX-CIF索引本地。文献[8]提出了一种MapReduce框架下高维数据近似查询方法。使用MapReduce任务并行处理的优势将整个数据集均匀的划分到集群中的各个计算节点,基于划分的方法构建分布式双层索引。但该方法针对的数据集比较稳定,没有考虑索引的更新。文献[9]提出的A-Tree索引是云环境下适合点查询与范围查询的分布式多维数据索引,A-Tree通过R-Tree实现索引,但R-Tree的缺点是有很多“重复覆盖”的区域,为此通过Bloom过滤器来选择查询区域。但是由于Bloom过滤器的局限性,当数据量越大时出现误判的概率也越大。文献[10]提出了一种基于改进四叉树的空间划分方法,再使用Hilbert曲线进行局部多维索引。这种索引方法高效的实现了多维查询,但构建效率复杂。而如KR+-索引[11]、HQ-Tree[12]、DQuadtree[13]这些多维索引框架都基于经典的空间数据索引,缺点是空间冗余较大。
3 MT-index
对于使用HBase存储实时流数据,如果当某个时间段数据量过大时很容易出现数据热点问题,为了减少数据热点的影响,一般的解决方式是为其建立索引,使得数据不会只集中存储在分布式集群中的某个节点内,而是分散的存入每个节点中。但是在插入数据的同时构建索引,对于数据插入的实时性也有一定的影响。因此,为了解决这一问题,MT-index将索引层划分为全局的粗粒度索引与本地的细粒度索引,数据在插入的时候先按粗粒度索引方式进入预先的分区中并只对粗粒度索引进行维护,等待数据入库后再进行细粒度索引的建立。这样的方式在一定程度上缓解了插入实时性的问题。同时,HBase采用Key-Value的形式进行存储,这种模式只提供了键值的快速查询,对于非键值的查询操作只能使用scan操作,其效率在海量冠字号系统中是不能接受的。现实中冠字号码数据的查询往往是涉及多个查询条件,比如查询某段时间内某人办理的业务涉及的冠字号码等,如果是按照HBase提供的过滤器进行查询,则查询过程消耗太大。为此,在粗粒度索引中使用时间序列与空间曲线结合的方式对数据进行划分并将多维查询条件降为一维,减少索引元所占空间,使用较少的存储空间实现了高效的多维查询。
3.1 整体框架
整体框架如图1所示,整个系统由数据导入模块、HBase分布式数据库模块、索引模块以及查询模块构成。数据导入模块负责将银行网点随时产生的数据导入到云存储空间的HBase中;HBase分布式数据库模块负责将导入的数据按键值对的形式存入HBase表中,产生的数据包括交易流水、交易内编码、冠字号码、时间、操作代码、银行网点编号、机器号、卡号等字段。同时,HBase也负责存储索引模块导入的索引表;索引模块负责构建与维护索引数据,先通过时间序列与空间曲线对数据分区后进行粗粒度的全局索引,当数据存入对应的region之后,再采用二级索引的策略构建本地索引;查询模块根据查询条件先去查询粗粒度的全局索引,确定数据所在的region,再根据本地的细粒度索引查询出具体数据。

图1 系统整体框架
3.2 索引的设计与实现
3.2.1 索引结构
索引结构如图2所示,索引包括了粗粒度索引以及region中细粒度的二层索引。
1)索引的第一层使用B+树将时间序列转为索引。由于随着时间变化会不断的有冠字号码数据更新进入系统,所以在本文中,将时间分为若干个时间段{[T0,T1],[T1,T2],…,[Ti-1,Ti]},这些时间段没有重叠,相加之后为系统需要的时间量。时间段会不断的后移,在规定范围之外的时间段就将其从索引中删除。使用B+树索引时间序列,每个叶子节点指向对应下层空间曲线所表示的区域。
2)使用Z曲线[14]对多维数据进行降维并且分区。Z曲线是一种通过隔行扫描二进制数字的比特到一个字符串来实现降维,并将产生的Z区域按升序填充到线性曲线中。空间Z曲线通过降维后分区,将源数据分为连续的Z空间,每个Z空间都对应着曲线上的一个Z值。在冠字号码数据中,对卡号与银行网点代码、冠字号码这三维构建多维索引,其意义是查询某段时间内,某个用户在某个网点取出或者存入的某张钱币。在查询时,可以将查询条件完整输入也可以输入个别条件。
3)region中数据的本地索引。本文中在数据插入HBase表中并且维护完上两层索引之后,会构建本地索引,本地索引类似开源框架IHbase,其目的是通过查询条件定位到某一个区域后,通过二级索引的方式能快速地查询出数据,避免扫描操作。由于这层索引是细粒度的,相对于上一层构建消耗较大,因此选择在当前时间序列结束后再对前一个时间段的数据构建本地索引。
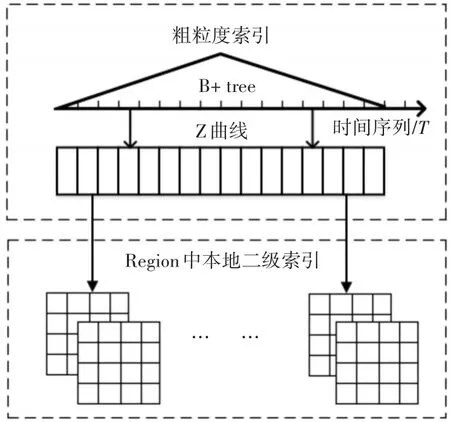
图2 索引结构
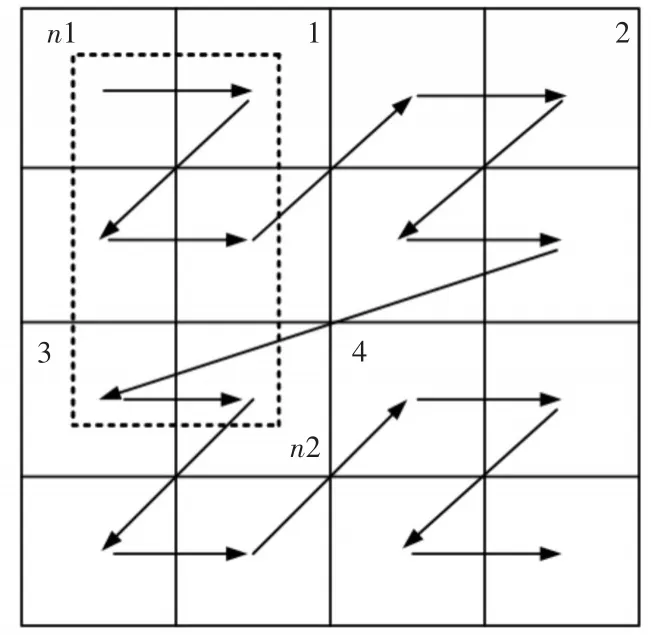
图3 二维Z曲线中范围查询
3.2.2 数据分区
HBase中基本的存储单位是region,每个region都有其对应的regionServer维护。本文的索引方式是时间序列与空间曲线相结合的方式,若直接按照这两点设计RowKey,可能会造成热点数据问题,数据会不断地写入同一个region中,当数据量超过了region的阈值便会调用split方法,数据量增长很快的同时split操作的次数也会很多,对于插入性能影响很大。在region中startKey和endKey是两个非常重要的元素,决定了这个region中RowKey的范围。所以在本文中采用了随机散列与预分区结合的方法来确定startKey与endKey。因为HBase中RowKey不能重复,所以在系统中使用时间序列与交易内编码结合的方式生成RowKey。1)先预测并随机产生未来一段时间序列内会生成的RowKey,使用MD5的方式转为hash在转为bytes,并将这个值拼接在原RowKey之前,升序后放在一个集合之中。2)根据预分区region的个数,对整个集合分割,产生对应的splitKey。产生的splitKey即可作为region的起始与结束位置。3)使用HBaseAdmin中的createTable方法指定预分区。这样可以避免热数据插入问题以及大量的region的分裂操作,提高效率。当预分区的时间序列结束前,系统会产生下一阶段预分区的结果作为下个阶段存储数据的region。
3.3 索引效率分析
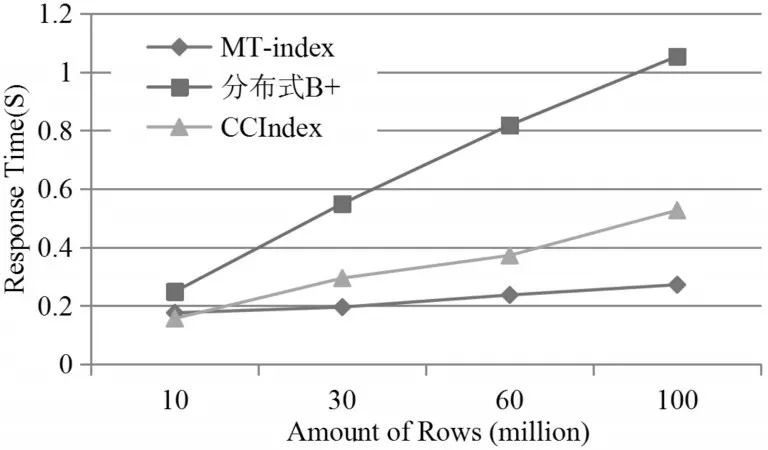
MT-index多维索引是一种以空间换取时间效率的方式,通过全局的粗粒度索引与本地的细粒度索引结合的方式提高数据插入以及多维查询效率。本文使用这种方式的目的在于实现高效的多维查询,现分析MT-index在多维查询方面的效率。多维查询分为多维点查询和多维范围查询,在多维点查询时,通过查询条件的计算,能确切得到数据在空间曲线的某个对应区域,查询的范围为一个区域,不存在效率的问题。而在多维范围查询时,所涉及到的Z区域较多,可能会造成无关区域的搜索问题。如图3所示,在一个二维空间中,查询范围为(n1,n2),那么需要查询的区域应该是虚线框中的范围,对应的Z区域应为1,3两个区域,但在空间曲线上,则会按序查询1,2,3三个区域,这就造成了无关区域的搜索,对效率产生了影响。为此,将B+树与Z曲线结合,如图4所示。可见,基于时间序列B+树中非叶子节点是个三元组 由上面的分析可以得出,粗粒度的全局索引能快速地定位到数据所在的空间区域,尽量减少了无关区域的查询。但是如果查询所给的范围很大,最终会有很多个区域需要查询,由于在数据处理中已经进行了预分区处理,每个region中数据量不会有很大偏差,则每个空间Z区域也不会有很大偏差,符合并发执行的条件,因此使用MapReduce[15]进行并发搜索,提高多维范围搜索效率。同时,在每个region中,会为其中的数据建立二级索引,即将查询条件作为键值,本文中采用用户卡号,该层索引实现比较简单,具体操作为在本地的二级索引表中按条件过滤出对应源数据的主键,目的是避免全区域的scan操作。 图4 B+树与Z曲线结合结构图 本实验平台由Hadoop-2.7.3集群组成,搭建于4个节点之上,每个节点上搭建了14.04的64位Ubuntu系统,每个节点CPU为Inter(R)Core(TM)i5,3.20Hz,内存为4G。Hadoop集群中有一个主节点与三个从属节点,分别提供管理与存储功能。使用的数据库为HBase-1.2.3,在HBase环境中有HMaster与HRegionServer两个角色。本实验中将HMaster部署在主节点,其余节点作为从属节点。实验数据采用冠字号码记录信息,记录信息包括交易流水、冠字号码、时间、银行网点号、网点机器号、卡号。HBase表中数据格式如表1所示。数据通过仿真生成,模仿了100个网点三个月生成的业务量。每笔业务都有其对应的冠字号码集,截取100万,300万,600万,1000万数据进行插入实验以及1000万,3000万,6000万,10000万数据量进行查询实验。插入实验的数据是直接调用HBase中的API而查询实验的数据则是使用HBase提供的Bulk-Load方式批量导入。在实验中,使用MT-index与CCIndex以及分布式B+树进行比较。 在该实验中,分别对三种索引结构进行四组不同数据量的数据插入,统计对于插入一定数量的流数据,系统需要消耗的时间。由实验结果(图5)表明,对于数据插入方面,三种索引结构的时间都是随着数据量的增加呈现线性增长。当数据量较小的情况下,MT-index消耗的时间要略大于CCIndex以及分布式B+树,其原因为MT-index需要计算空间曲线Z值以及计算预分区,这些时间消耗在总时间中所占比重较大。而当数据量变大后,MT-index的插入时间则小于CCIndex与分布式B+树。实验结果表明,MT-index在大量的流数据情况下,具有较好的数据插入性能。其原因在于对于多维索引,分布式B+树会根据多个属性建立多个索引表,同样CCIndex的索引冗余很大,构建需要较多的时间。而MT-index则采用了Z曲线将多维降为一维,只需要构建一个索引表,且采用粗细粒度索引分离的方式,所以数据插入的性能更高。 图5 数据插入耗时 数据查询实验中,采用4组数据进行查询实验。分别从源数据中获取100份范围查询数据,在MapReduce框架进行连续实验,记录完成时间,再取平均值作为该索引在该数据量下的查询响应时间。实验结果如图6所示。相对于分布式B+树与CCIndex,MT-index的查询响应时间更短。当数据数据较小的时候,三种索引方式的查询效率差不多,而当数据量不断增大,MT-index在查询效率方面的优势是很明显的。而且,查询响应时间受数据规模的影响较小。其原因是在MT-index这种索引模式下,最终要查询的区域随着数据量的增长变化并不大。所以MT-index具有高效的查询效率。 图6 查询响应时间 本文基于HBase提出了一种冠字号码数据的多维索引模型,为海量冠字号码数据的存储与查询提供了方案。实验表明,该方法具有较好的插入、查询效率,易于实现,受数据规模影响不大,能够适用于数据规模不断增长的实时冠字号码数据查询系统。本文的工作重点在于对索引的构建,目的是提高实时数据插入与查询的性能。对于解决海量冠字号码问题具有重要的参考价值和实用意义。
4 实验论证
4.1 实验环境
4.2 数据插入实验

4.3 数据查询实验
5 结语
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
小学生学习指导(低年级)(2020年6期)2020-07-25
故事会(蓝版)(2020年1期)2020-01-19
电子制作(2019年22期)2020-01-14
电子制作(2019年13期)2020-01-14
奥秘(创新大赛)(2019年10期)2019-10-24
制导与引信(2017年3期)2017-11-02
燕山大学学报(2015年4期)2015-12-25
小说月刊(2014年1期)2014-04-23
