
RMAPS_Chem V1.0系统SO2排放清单优化效果评估
2019-03-05 11:59赵秀娟崔应杰张方健3
应用气象学报 2019年2期
徐 敬 陈 丹 赵秀娟* 陈 敏 崔应杰 张方健3)
1)(北京城市气象研究院, 北京 100089) 2)(国家气象中心, 北京 100081) 3)(中国气象科学研究院, 北京 100081)
RMAPS_Chem V1.0系统是基于WRF_Chem模式建立的服务于华北区域雾霾等污染预报业务的模式系统,该研究着重针对系统中污染排放清单不确定性带来的SO2浓度预报偏差较大问题,采用EnKF源反演和误差统计订正相结合的方法对排放清单进行了改进,形成了一套优化后的华北区域SO2排放清单。通过输入初始清单和优化清单对2017年10月进行模拟,并与华北地区616个地面环境监测站观测值进行对比,结果表明:EnKF源反演结合误差统计订正的排放清单优化方法适用于SO2排放清单的改进,有效降低了清单系统性偏差,针对主要区域及重点城市的检验显示模拟结果接近观测值;排放清单优化后模拟误差显著降低,如河北南部、山东西部至北京一带模式预报均方根误差与归一化平均绝对误差明显下降,区域内站点模拟误差呈正态分布特征,误差分布范围、最大概率出现范围均明显变窄,且最大误差概率明显上升。
引 言
20世纪80—90年代华北地区能源结构以燃煤为主,颗粒物和SO2污染均十分严重;近些年,随着能源结构的调整、燃煤比例下降,SO2污染得到有效控制[1],已经很少出现SO2超标情况,人们对SO2污染的关注度降低,但SO2作为气溶胶前体物,其浓度水平直接影响气溶胶硫酸盐组分含量。因此,降低SO2等一次污染物排放源的不确定性是准确模拟重霾污染过程中PM2.5浓度与化学组成[2-3],以及能见度[4]时空变化特征的重要基础。
目前,主要采用基于排放系数和活动水平计算得到各类污染源、各种污染物排放量,这种自下而上的排放清单建立方法不确定性大小取决于统计数据和排放系数的准确性,而我国由于本地化的排放系数数据有限,以往排放清单编制主要借鉴美国的排放系数数据库(AP-42)[5],与我国的实际排放特征相去甚远;此外,我国排放清单建立采用的统计数据多以省为单位,城市尺度的数据缺乏,无法体现排放源时空变化差异;且由于SO2排放控制政策的逐步实施,统计数据代表性明显滞后[6]。因此,排放清单作为模式输入的基础数据,无论从清单的不确定性、时效性还是时空精确性等方面均需要不断改进和完善。
在排放清单建立的基础上,利用模式预报结合地面观测和卫星遥感数据,采用某种方法对现有清单进行反算,称为自上而下排放源反演方法,该方法可以弥补自下而上方法的缺陷,反映污染源接近真值的排放特征。针对本文研究关注的华北区域排放清单反演工作,蔡旭晖等[7]及苏芳等[8]利用逆向轨迹方法反演了北京地区CH4排放源,这种方法假定观测点污染物浓度线性可加地来自于各污染源的共同作用,因此,该方法仅适用于大气惰性组分的源强反演。对于非线性大气化学组分而言,较全面考虑污染模式中大气污染物传输、扩散和化学转化规律,建立源强和污染物观测浓度之间的关系, 进而通过最优化或者次优化算法从观测信息反演污染源的方法在近些年较受关注,如Tang等[9]采用集合卡尔曼滤波反演了北京及周边地区的CO排放源,程兴宏等[10]用逐步逼近源同化方法反演了华北地区一次重霾污染过程中SO2和NOx排放源。这些工作有效改进了重点地区污染源分布状况,使排放水平更接近真实情况,但由于这种利用污染物浓度观测结果估计污染源排放的集合方法应用于高维模式时计算代价高昂,报道相对较少,且多为针对短时间污染事件的研究结果。孟凯等[11]利用逐步逼近源同化技术反演了2014 年1,3,7,11月SO2,NOx的局地动态污染源,但反演范围也只针对京津冀地区。上述这些工作对于区域性排放清单的改进远远不能满足空气质量业务应用需求。
快速更新多尺度分析和预报系统化学子系统(RMAPS_Chem V1.0)是基于北京区域环境气象数值预报系统(BREMPS)[12]改进发展而来的业务模式系统,是华北区域雾霾及污染气象条件预报的主要技术支撑。对RMAPS_Chem V1.0系统2017年预报结果的系统性评估检验显示,SO2浓度模拟值异常偏高,京津冀地区约为观测值的7倍,北京地区高出观测值15倍,其中秋季的预报偏差最为突出。对于SO2浓度预报存在系统性极大偏差,来自模式的问题中除了污染排放清单的不确定性外,还包括气象场误差、模式下垫面处理误差、沉降和化学反应过程中的近似误差以及模式分辨率带来的计算误差等。本研究着重从排放清单不确定性角度进行讨论,主要原因如下:①RMAPS_Chem V1.0系统采用的清单基础数据陈旧,亟待更新,如目前RMAPS_Chem V1.0采用的排放清单数据为清华大学创建的MEIC清单,代表年份为2012年,Hong等[13]针对该清单不确定性的研究指出,2004—2012年中国的能源消费统计数据对清单不确定性的影响显著递增,2013年后呈现收敛趋势。②排放清单基础数据时空分辨率较低,无法满足城市尺度预报服务需求:由于SO2对局地源排放极为敏感,区域性排放清单对于小尺度SO2排放描述存在很大的不确定性,模拟难以捕捉城市及更小尺度的SO2空间分布特征[14]。
本研究针对RMAPS_Chem V1.0对秋季SO2预报偏差较大的问题,首先通过模式对气象条件预报准确性的检验,分析SO2浓度预报误差主要来自于排放清单的偏差,进而分别采用集合卡尔曼滤波(Ensemble Kalman Filter, EnKF)源反演,以及源反演结合误差统计订正的方法对初始清单进行了订正,并对比了它们的优劣;最终选择对京津冀及周边地区SO2站点浓度预报改善具有明显优势的清单订正方法,创建一套优化后的华北区域SO2排放清单,开展初始清单和优化清单的模拟对比,分析SO2预报偏差及改进效果。
1 研究方法
1.1 模式系统简介
RMAPS_Chem V1.0系统以WRF_Chem V3.3.1为主积分模式[15],采用气象模式(WRF)和大气化学模式(Chem)在线耦合方式进行同步积分计算,可有效减少离线计算由于时间、空间差值带来的误差,实现对气象-化学反馈效应的研究。此外,就研究真实大气而言,模式考虑了较为详尽的物理、化学过程,广泛应用于区域性污染成因研究[16-18], 以及空气质量预报业务[12,19]。
RMAPS_Chem V1.0系统采用嵌套模拟设置(图1),外层水平分辨率为9 km×9 km,覆盖范围包括内蒙古东部、陕西、山西、山东、河南北部、河北、天津、辽宁及北京等地;内层水平分辨率为3 km×3 km,覆盖京津冀区域。模式采用Lambert地图投影方式,中心点位置为39.5°N,114.8°E;外层经向、纬向格点数分别为223和202,内层依次为232和253;模式层顶为50 hPa,垂直方向分为38层, 1500 m 以下取17层;系统选用的主要物理、化学过程方案设置参见文献[20]。
RMAPS_Chem V1.0系统由BJ-RUC系统提供气象预报场[21];初始排放清单数据采用清华大学创建的MEIC清单(http:∥www.meicmodel.org),该清单包含5 个排放部门(电力、工业、民用、交通、农业),代表年份为2012年,水平分辨率为0.1°×0.1°(由清单创建小组提供,根据0.25°×0.25°分辨率原始清单插值获得),时间分辨率为月。
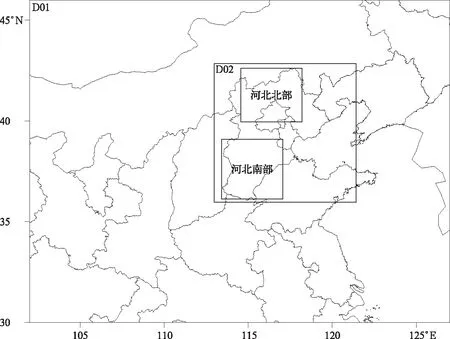
图1 模式预报及检验区域Fig.1 Forecast and evaluation region
1.2 观测数据及检验方法
SO2浓度观测数据取自全国城市空气质量实时监测数据平台(http:∥106.37.208.233:20035)616个数据质量符合标准的监测站,筛选依据为逐日有效小时平均值数据超过75%可参与日平均值计算,逐月有效日平均值数据超过75%可参与月均值计算。考虑该模式系统重点预报服务于京津冀地区,以及该区域内SO2源强分布存在极大空间不均匀性,在检验过程中还划分了河北南部和河北北部(图1),以及北京城市和石家庄城市4个重点区域。用于气象要素预报效果检验的数据为全国自动气象站监测数据,D01区域覆盖有效数据站点总计1411个。
SO2预报结果检验步骤如下:首先,根据各监测站点的经纬度信息,通过双线性插值法将模式网格预报结果差值至观测站,生成模式预报和观测位置相匹配的数据集;然后,依照上述重点区域的划分(图1),选取各区域覆盖的观测站进行统计分析(其中D01区域的分析数据采用9 km的预报结果,D02及更小区域的分析数据采用3 km的预报结果),评估模式对于不同区域范围预报的准确性。参与评估的统计量选用偏差概率、均方根误差和归一化平均绝对误差。其中归一化平均绝对误差定义为
(1)
就某一站点而言,式(1)中,n代表时间序列样本量,Oi代表第i个时刻的观测值,Pi代表第i个时刻的模拟值。均方根误差和归一化平均绝对误差都表征了模拟值相对观测值的偏离程度,其值越小,表明模式预报精度越高。
1.3 排放清单订正方法
在利用资料同化方法来优化大气污染物排放清单的众多技术手段中,基于集合卡尔曼滤波和模式结合的方法是其中较为通用的一种。该方法通过扰动模式的排放输入,借助模式本身的物理化学模块来预报模拟,从而实现预报误差协方差的动态更新,其原理就是利用最优估计算法将观测与包含物理化学约束的数值模型结合起来得到污染物初始状态或者模式排放输入的最优估计[22-24]。已有工作如Peng等[25]在WRF-Chem模式后接集合卡尔曼滤波,构建了PM2.5排放比例系数的控制变量,并利用GSI(grid point statistical interpolation)同化系统的观测算子及地面PM2.5浓度观测对PM2.5的排放比例系数进行了同化研究。但在该GSI-WRF/Chem-EnKF系统中,主要关注气溶胶初始场和相关排放比例系数的同时同化,主要目的在于提高模式对于PM2.5的预报能力,并未对排放优化结果进行评估。Chen等*Chen D,Liu Z Q,Peng Z,et al.Three-year (2015-2017) winter-time air pollution in China:Part Ⅱ.SO2 emission changes by using WRF/Chem-EnKF coupled data assimilation system.Submitted to Atmospheric Chemistry and Physics,2018.在Peng等[25]的工作基础上进一步更新,在GSI-WRF/Chem-EnKF系统中增加了SO2排放输入的控制变量,并将排放比例系数更新为SO2的直接排放,利用地面SO2浓度观测作为约束实现了对SO2排放的优化。Chen等*Chen D,Liu Z Q,Peng Z,et al.Three-year (2015-2017) winter-time air pollution in China:Part Ⅱ.SO2 emission changes by using WRF/Chem-EnKF coupled data assimilation system.Submitted to Atmospheric Chemistry and Physics,2018.对前置的排放清单MEIC-2010进行多成员扰动,将这些成员的扰动带入模式中进行预报,得到一组污染物浓度模式输出结果;根据统计相关从而得到观测点处模式污染物浓度变化和污染源排放的关系,根据这个统计关系,从观测约束出发对前置排放清单进行优化改进,从而获得2010—2016年1月的排放清单年度变化系数。本文采用该年度排放系数,对整个模拟区域内相应的排放清单网格进行源强订正,获得一套基于EnKF方法反演的SO2排放清单,称为EnKF反演清单。
由于Chen等*Chen D,Liu Z Q,Peng Z,et al.Three-year (2015-2017) winter-time air pollution in China:Part Ⅱ.SO2 emission changes by using WRF/Chem-EnKF coupled data assimilation system.Submitted to Atmospheric Chemistry and Physics,2018.工作是针对中国范围SO2清单的反演,模式分辨率设置为40 km,而本研究采用的基础清单分辨率为0.1°,较低分辨率势必会带来较精细的排放源空间特性描述的不确定性,可能会导致本研究所关注的区域及城市尺度排放清单分布的偏差;此外,由于Chen等①工作是针对冬季污染排放清单反演获得的排放年度变化系数,与本文关注的秋季时段在污染源变化上不完全一致,可能存在季节差异带来的偏差,如仅采用EnKF方法对清单的订正结果显示,在河北东南部、河南北部以及山东等部分地区初始清单对SO2的排放是低估的,而采用初始清单对秋季的模拟检验显示,这些地区模拟结果存在系统性的高估情况;导致这种情况的主要原因在于这些地区冬季取暖散煤燃烧源对SO2排放有较大贡献[26],相比采用统计数据建立的原始清单,EnKF基于观测数据反演的排放清单捕捉到了这些信息,而这种针对采暖季排放清单偏差的纠正可能对于非采暖季在部分地区不完全适用。因此,在采用EnKF源反演对区域排放清单订正的基础上,采用基于秋季模拟和观测结果开展的误差统计订正方法,对环境监测站点及邻近区域所覆盖的模式网格源强做进一步修订,获得一套采用EnKF源反演叠加误差统计订正后的SO2排放清单,称为优化清单。本研究使用的误差统计订正方法受逐步逼近源同化反演方法启发[10,27-28],即假设区域化学传输模式能够较准确地模拟污染物的物理和化学过程,模拟值和观测值的偏差取决于污染排放清单的不确定性。由于SO2对局地源排放极为敏感,就模式需要输入的源强信息而言,可假设某一时间和特定空间范围内SO2排放量的改变与模拟浓度变化间存在近似线性关系。因此,将地面监测站获得的SO2观测浓度与模拟浓度采用线性回归方法建立统计关系,统计结果用以修正该点所在模式网格及相邻3倍网格距范围内的排放源强度,计算公式表达如下:
I(n,m)=O(n,m)×R(i,j)。
(2)
式(2)中,R(i,j)为某观测站点依据经纬度信息差值至清单网格(i,j)坐标处时,该格点初始清单模拟得到的月平均浓度与观测月平均浓度的比值;(n,m)代表了清单中以(i,j)格点为中心临近3倍网格的格点坐标,O(n,m)为这些临近网格处初始清单SO2排放强度,I(n,m)为优化清单的排放强度。
2 结果与讨论
2.1 气象场验证
气象条件影响污染物的传输、扩散、沉降等物理过程,辐射、温度和相对湿度等气象要素直接决定着大气中二次反应进程和转化路径,气象场的准确预报是污染物浓度预报准确的重要因素。因此,首先利用D01区域覆盖的1411个自动气象站数据对与污染物分布特征显著相关的气象要素进行检验。
图2显示D01区域月平均地面温度、风速和相对湿度模拟值与该区域内地面自动气象站观测值的对比。从区域分布特征看,模式预报的各要素区域分布形势与观测场一致,模拟出了内蒙古东部、华北东北部以及陕西、山西和河北北部的低温、低湿和高风速区、华北平原东部的高温、低湿和低风速区,且模拟得到的各要素场高低值相对位置、分布范围与观测场基本一致;模拟和观测结果均显示,太行山前平原地区有一条明显的小风速带,这条小风速带所处位置是京津冀地区来自西南方向污染输送的重要通道[29-30],该特征的准确模拟对于华北地区污染成因的揭示有十分重要的意义。此外,月平均模拟值与观测值对比显示,对于绝大部分站点来讲,温度和相对湿度模拟值与观测值接近,模拟误差较小,但对风速的模拟存在普遍性高估。从日平均值对比看,模式较好体现了地面温度和相对湿度的逐日变化特征,相关系数分别为0.96和0.85,标准化平均偏差较小;与已有研究结果相似[14,20-21,31-32],本研究中模式对风速模拟同样存在明显高估(图2b),平均高估1.2 m·s-1,标准化平均绝对偏差约为79%,但风速相关性较好,相关系数为0.81。总体而言,模式合理再现了主要污染气象要素的区域分布特征以及月平均值分布范围,为化学场的准确模拟奠定了基础。因此,认为RMAPS_Chem V1.0模式对于气象场的预报接近实况,其对于SO2浓度预报的误差很大程度上归结于排放清单的偏差。
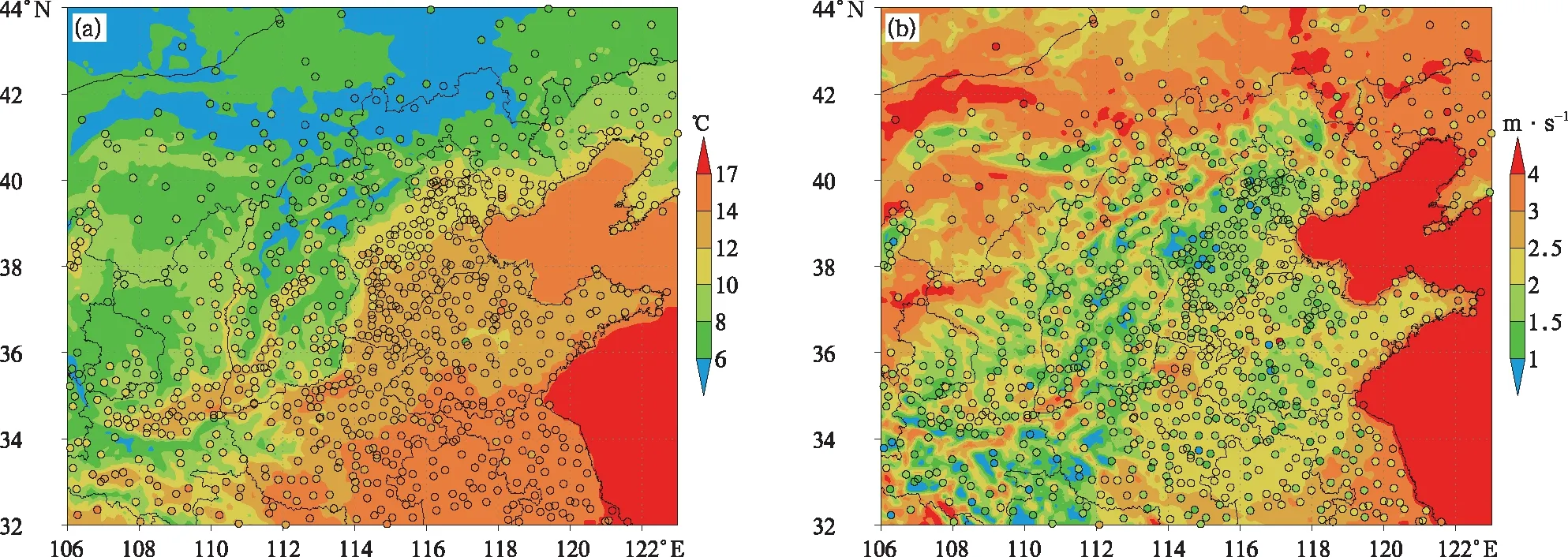
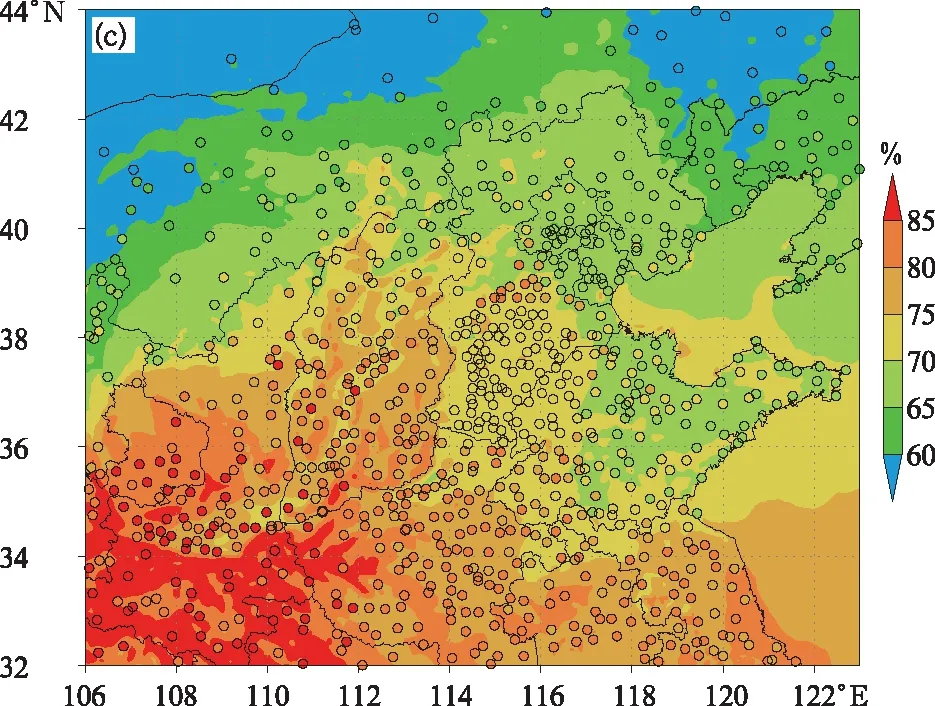
图2 2017年10月月平均地面温度(a)、风速(b)和相对湿度(c)模拟值与观测值对比(色阶底图为模拟值,实心圆点代表观测值,两者采用相同的色标)Fig.2 Comparison of the monthly averaged near-surface temperature(a),wind speed(b) and relative humidity(c) simulated by RMAPS_Chem V1.0 with observations in Oct 2017(simulated and observed values using the same color bar are indicated by shaded base graphics and shaded circles, respectively)
2.2 EnKF反演清单与优化清单模拟结果对比
为了确定最优订正方法,建立一套接近真实状况的SO2排放清单,应用于RMAPS_Chem V1.0业务系统,模拟试验设计如下:首先,鉴于在RMAPS_Chem V1.0业务框架下开展模拟计算和结果检验,需要大量的运算机时和存储空间,选择了本研究关注期间的前三分之一时段(2017年10月1—10日),分别采用初始清单、EnKF反演清单以及优化清单进行模拟,并对比清单变化和模拟结果。
EnKF反演清单以及优化清单相对于初始清单变化区域分布如图3所示,重点区域和城市地区SO2月排放量变化情况见表1,采用上述两种清单得到SO2浓度模拟值与观测值均方根误差及归一化平均绝对误差如图4、图5所示。可以看到,优化清单重点改善了京津冀地区、河南北部以及山东地区的预报偏差;这些地区均方根误差分布自3~80 μg·m-3下降至3~40 μg·m-3,其中均方根误差低于10 μg·m-3的站点增加了17%;归一化平均绝对误差分布自0~9下降至0~4,其中归一化平均绝对误差为0~1的站点增加了33%。优化清单同样降低了整个模拟区域的预报偏差,如采用EnKF反演清单模拟得到的大部分站点误差为-10~20 μg·m-3,误差为0时出现概率最大为52%;而采用优化清单模拟得到的大部分站点误差为-10~10 μg·m-3,误差在0时出现概率最大为67% (图6)。以上模拟结果对比显示,采用EnKF反演结合误差统计订正得到的优化清单更接近排放真值,进而采用该清单对全部关注时段进行模拟,评估了清单优化后的整体改进效果。

图3 2017年10月SO2格点平均月排放量差值(a)EnKF反演清单减去初始清单,(b)优化清单减去初始清单Fig.3 Difference value of monthly mean SO2 emission load for each grid in Oct 2017(a)inversion emissions using EnKF approach minus initial emissions,(b)optimized emissions minus initial emissions
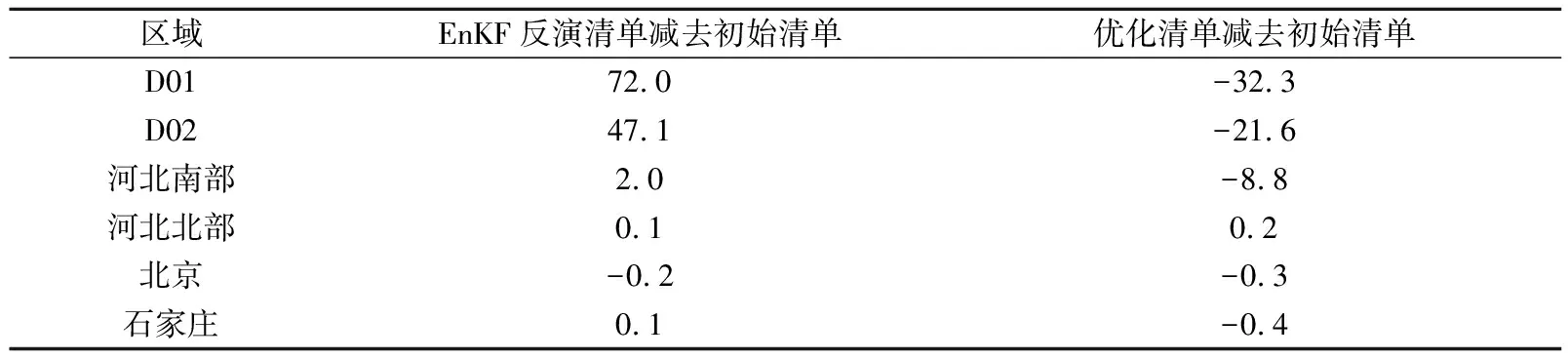
表1 2017年10月各区域及重点城市EnKF反演清单、优化清单较初始清单SO2排放量变化(单位:t)Table 1 Difference of SO2 emission load between inversion emissions using EnKF approach, optimized emissions and initial emissions in different regions and cities in Oct 2017(unit: t)
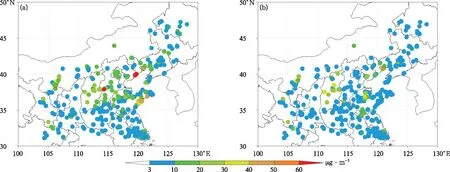
图4 2017年10月1—10日EnKF反演清单(a)、优化清单(b)SO2浓度模拟值与观测值均方根误差Fig.4 Root mean square error between observed and simulated SO2 concentration from 1 Oct to 10 Oct in 2017(a)inversion emissions using EnKF approach,(b)optimized emissions
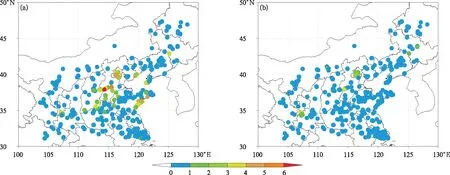
图5 2017年10月1—10日EnKF反演清单(a)、优化清单(b)SO2浓度模拟值与观测值归一化平均绝对误差Fig.5 Normalized mean absolute error between observed and simulated SO2 concentration from 1 Oct to 10 Oct in 2017 (a)inversion emissions using EnKF approach,(b)optimized emissions
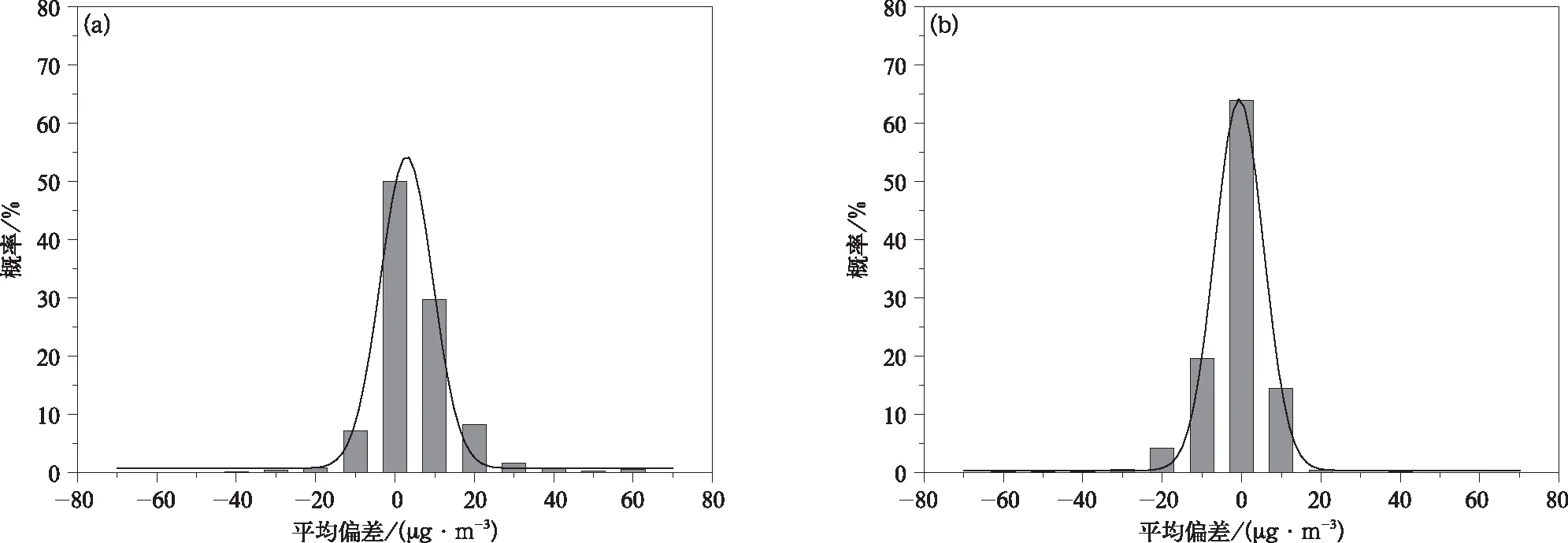
图6 2017年10月1—10日EnKF反演清单(a)、优化清单(b)D01区域内站点SO2浓度模拟值与观测值偏差概率分布Fig.6 Probability distribution of bias between observed and simulated SO2 concentrations from 1 Oct to 10 Oct in 2017 (a)inversion emissions using EnKF approach,(b)optimized emissions
2.3 改进清单预报效果对比
本节通过输入优化清单及初始清单对2017年10月进行了模拟,利用616个环境监测站获得的地面SO2数据对采用不同排放清单的模拟结果进行检验,从时间变化、空间分布特征以及模拟值与观测值的均方根误差、归一化平均绝对误差、误差概率分布等统计特征方面,对比分析了排放清单优化前后模式对于SO2浓度预报效果的差异。
2.3.1 时间变化特征
图7为各区域分别采用初始清单和优化清单模拟得到的2017年10月SO2日平均浓度与观测结果对比。由图7可见,基于初始清单和优化清单模拟的SO2浓度与观测值的逐日变化趋势基本一致。各区域采用初始清单模拟的SO2浓度均明显高于观测值,这种现象在河北南部、北京和石家庄等人为排放源强较大的地区尤为突出。总体来看,排放清单优化后SO2浓度较改进前与观测值更为接近,需要指出的是,在D01和D02区域排放清单优化之前模拟结果较观测值系统性偏高,优化后出现了模式对SO2浓度系统性低估的情况,而这种现象在河北南部、河北北部,以及北京和石家庄城市地区并未出现。对比表1中SO2排放量的变化以及模拟偏差概率分布(图6),分析得出排放清单优化导致D01和D02区域SO2浓度系统性低估的原因主要由误差统计订正引起。利用地面监测站SO2浓度模拟值与观测值的线性回归关系,订正该点所在模式网格及相邻3倍网格距范围内的排放源强度,使监测站点相对密集的京津冀,特别是城市地区源排放更接近真实水平,改善效果更为显著,而对于监测站点稀疏的地区可能导致了模式预报偏差纠正过度的情况。同时也看到,北京周边的河北南部和河北北部SO2浓度模拟值与观测值十分接近,北京城区就观测值讲,SO2浓度较周边地区明显偏低,日平均浓度低于6.97 μg·m-3,月平均浓度仅为3.57 μg·m-3,而模拟浓度与周边地区接近,因此,出现了模拟值系统性偏高的情况,而同样针对城市尺度的石家庄模拟则未出现这种现象,主要原因在于:一方面,北京本地排放控制更为严格,SO2作为受局地性排放较强的污染组分,观测得到的浓度处于极低水平;另一方面,北京市域范围较小,观测数据样本量有限,基于站点统计方法的排放清单订正效果较为局地,而周边地区SO2源强相对较高,由于SO2的大气寿命在1 d至数日之间,具有一定的区域传输特性[33-34],因此,受周边地区的传输影响使得北京地区SO2浓度模拟偏高。
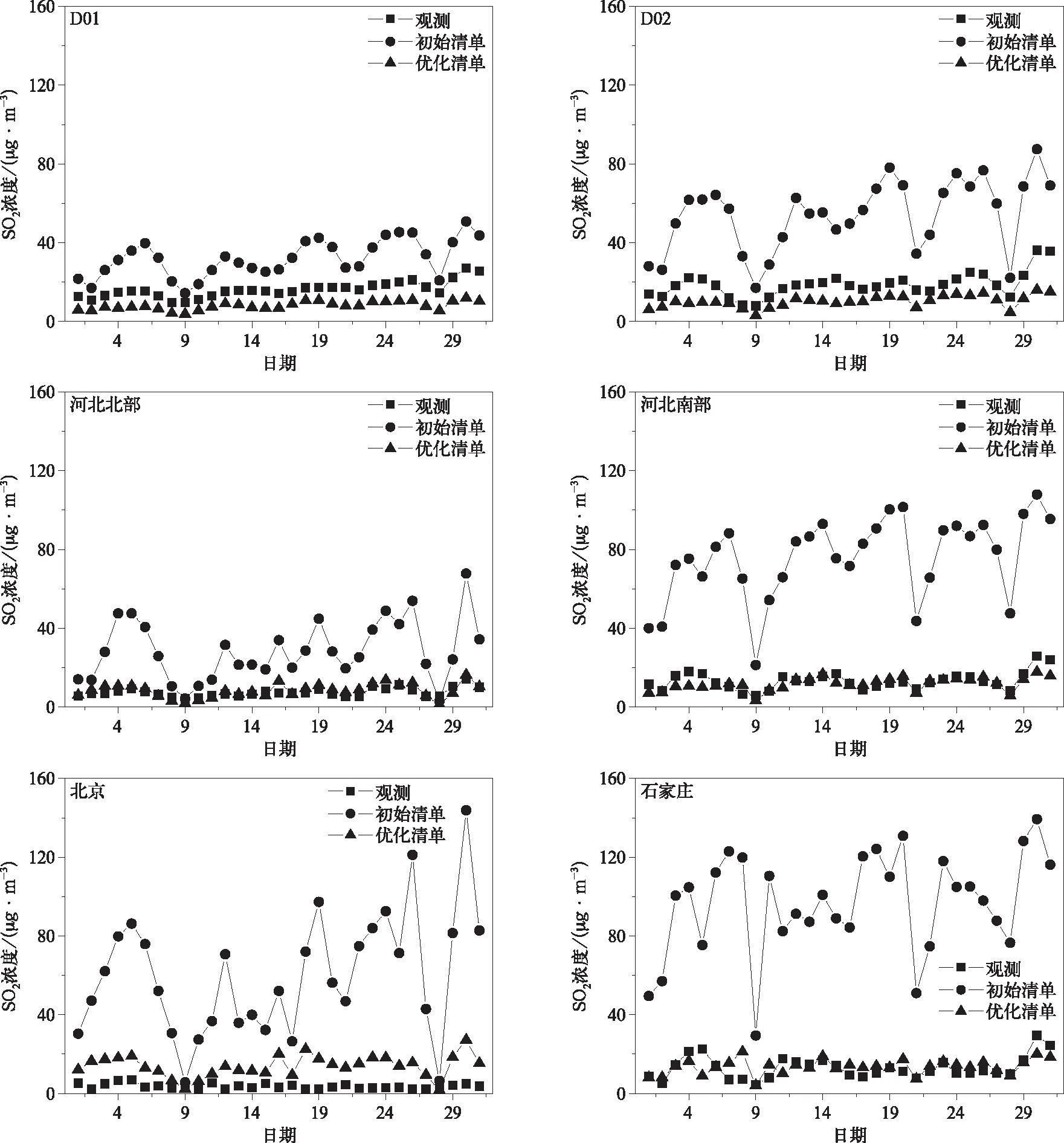
图7 2017年10月排放清单优化前后各区域SO2日平均浓度模拟值与观测值逐日变化Fig.7 Temporal variation of different regional observed and simulated SO2 daily mean concentration with initial and optimized emissions in Oct 2017
2.3.2 区域分布特征
图8和图9分别显示了排放清单优化前后模式模拟值与观测值均方根误差、归一化平均绝对误差。可见,排放清单优化前,模式预报偏差较大的区域主要集中在河北南部、山东西部至北京一带,这些地区SO2月平均均方根误差为30~100 μg·m-3,归一化平均绝对误差为1~20,清单优化后,上述两个统计量的分布范围分别降低至3~20 μg·m-3和0~5。结合图3分析可见,模式预报偏差较大的区域与排放清单优化后源强降低的主要区域吻合,表明这些地区过高的SO2排放是导致模式预报误差的主要原因。

图8 2017年10月排放清单优化前后SO2浓度模拟值与观测值均方根误差(a)初始清单,(b)优化清单Fig.8 Root mean square error between observed and simulated monthly mean SO2 concentration with initial(a) and optimized(b) emissions in Oct 2017
2.3.3 统计特征
进一步对重点区域和城市地区的模拟值和观测值进行统计。由表2排放清单优化前后的对比可以看到,就各区域范围而言,无论是均方根误差还是归一化平均绝对误差在清单优化后均显著降低;其中RMAPS_Chem V1.0系统重点预报服务的河北南部、河北北部以及北京和石家庄城市地区改善效果突出,均方根误差分别从69.53,28.65,64.43,87.70 μg·m-3降低至7.29,7.33,10.93,6.84 μg·m-3;归一化平均绝对误差分别从6.86,6.51,18.11,8.42降低至0.55,1.47,3.97和0.57。这些地区地面环境监测站密集,高分辨率的观测信息输入有利于EnKF源反演修正效果的提高,且进一步基于监测站观测的误差统计订正弥补了EnKF方法中模拟分辨率较低带来排放清单精细化分布特征的偏差,从而使SO2浓度预报效果明显提升;表明本研究采用的EnKF反演和误差统计订正的排放清单订正方法合理,该方法对于排放清单区域性偏差的纠正,以及重点区域和城市地区SO2预报改善十分有效。
2017年10月分别采用初始清单和优化清单模拟得到了D01区域内616个环境监测站SO2月平均浓度模拟值与观测值偏差概率分布特征。图10显示,基于初始清单的SO2浓度模拟偏差呈近似正态分布,大部分误差为-10~30 μg·m-3,误差在10 μg·m-3和20 μg·m-3附近出现概率最大,分别为26%和25%;清单优化后,SO2模拟偏差同样呈近似正态分布特征,误差分布范围明显变窄,大部分误差为-10~10 μg·m-3,误差出现最大概率范围集中于0附近,且最大概率值提高至 57%。由此得出,相比于初始清单,清单优化后误差分布范围、最大概率出现范围均明显变窄,且最大误差概率值明显上升,表明排放清单的改进使模拟误差显著降低。
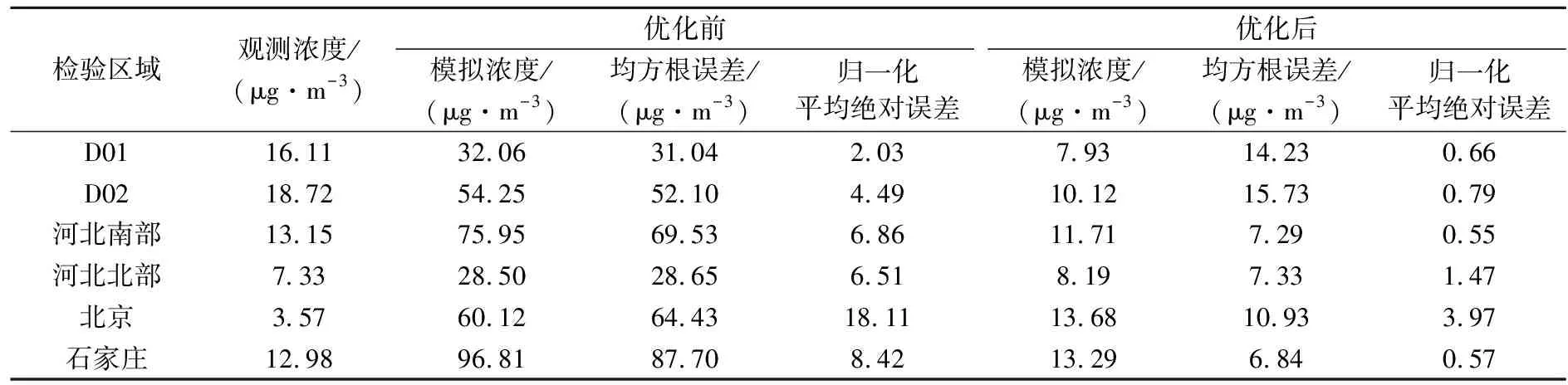
表2 2017年10月排放清单优化前后各区域模拟值和观测值对比Table 2 Comparison of mean SO2 concentration for different regions between observed and simulated with initial and optimized emissions in Oct 2017

图10 2017年10月华北区域616个环境监测站SO2月平均浓度模拟值与观测值偏差概率分布(a)初始清单,(b)优化清单Fig.10 Probability distribution of bias between simulated SO2 concentration using initial(a) and optimized(b) emissions and observations at 616 stations over North China in Oct 2017
3 结 论
采用EnKF源反演结合误差统计订正的排放清单优化方法,改进了华北区域秋季SO2排放清单,通过分别输入初始清单和优化清单对2017年10月进行模拟分析,利用自动气象站气象观测数据和地面环境监测站SO2观测数据对模拟结果进行检验,结果表明:RMAPS_Chem V1.0系统对于气象场的预报接近实况,其对SO2浓度预报的较大误差可主要归结于排放清单的偏差;采用上述优化方法对排放清单的改进显著降低了模式的预报误差,该方法适用于业务模式中排放清单区域性偏差的纠正,特别对于重点区域和城市地区SO2预报准确性提升十分有效,具体如下:
1) 时间序列变化特征对比显示:各区域排放清单优化后SO2浓度模拟值与观测值更为接近,明显降低了模式对SO2浓度预报系统性高估的问题,但改善效果在不同区域表现不同,监测站相对密集的京津冀、特别是城市地区源排放更接近真实水平,改善效果更为显著。
2) 区域分布特征对比显示:模式预报偏差较大区域与SO2排放偏差较大区域吻合,主要分布在河北南部、山东西部至北京一带,排放清单优化使这些地区SO2浓度月平均均方根误差自30~100 μg·m-3降低至3~20 μg·m-3,归一化平均绝对误差分布自1~20降低至0~5。
3) 重点区域及站点统计特征对比显示:排放清单的优化使RMAPS_Chem V1.0系统重点预报服务的河北南部、河北北部以及北京和石家庄城市地区SO2浓度预报效果改善显著,均方根误差分别从69.53,28.65,64.43,87.70 μg·m-3降低至7.29,7.33,10.93,6.84 μg·m-3;归一化平均绝对误差分别从6.86,6.51,18.11,8.42降低至0.55,1.47,3.97和0.57。模式覆盖的616个监测站统计结果显示,清单优化后误差呈正态分布,大部分误差分布范围从-10~30 μg·m-3变为-10~10 μg·m-3,误差概率最大值的分布范围从10 μg·m-3和20 μg·m-3附近集中于0附近,且最大概率值自26%提高至 57%。
猜你喜欢
中等数学(2022年5期)2022-08-29
成都信息工程大学学报(2021年5期)2021-12-30
学生天地(2020年6期)2020-08-25
中等数学(2020年2期)2020-08-24
数学年刊A辑(中文版)(2020年2期)2020-07-25
飞天(2019年6期)2019-07-08
自动化学报(2017年2期)2017-04-04
信息记录材料(2016年4期)2016-03-11
系统医学(2016年8期)2016-02-20
新高考·高二数学(2015年2期)2015-05-27
