
小样本数据的MIFS过滤式特征选择算法
2019-03-11 06:42王波李时辉郑鹏飞
山东农业大学学报(自然科学版) 2019年1期
王波,李时辉,郑鹏飞
小样本数据的MIFS过滤式特征选择算法
王波,李时辉,郑鹏飞
义乌工商职业技术学院, 浙江 义乌 322000
针对小样本数据特征选择以及最佳特征难确定的问题,本文提出一种MIFS过滤式特征选择算法,同时结合Boruta算法,旨在降低数据集维度,确定出最佳特征的子集。通过实验结果与分析,对比其它三种传统的过滤式算法,验证本文算法的有效性。结果表明:MIFS-Boruta算法体现出更广的特征选择量,并且平均最低分类错误率最低。
小样本; MIFS; 算法
随着互联网及信息技术的发展,大数据应用越来越普遍,但在实际生活中,小样本数据依然不可或缺。例如基因分析数据就是一种典型的小样本数据,主要由微阵列实验进行获取,而实验成本一般比较昂贵,这对实验次数产生了限制。整个基因分析数据规模较小,但数据维数很高,若采用传统型的机器学习算法进行处理,容易导致数据失效。而利用特征选择降低数据的维数,则是一种较为有效的解决办法。特征选择有利于去除数据的不相关性和冗余性,提升数据本身的质量,减少数据集计算的代价,进而使数据挖掘变得更快[1]。常用的特征选择方法有过滤法、封装法和嵌入法[2]。过滤法是直接进行数据训练并评估数据性能的方法,根据评估结果去除相关性小、冗余度高的数据,与分类算法没有关联。封装法和嵌入法都需要进行后续的分类计算,数据的维数越高,计算成本就会越大,不太适合小样本数据特征的选择。过滤法的评估函数是独立的,在其评估标准中不会纳入任何分类器,选出的特征子集与特定的分类算法无关,因此计算成本较低[3]。过滤法与另外两种方法相比,计算也更加的高效。Kamatchi等对小样本数据特征冗余性进行考虑,同时结合特征类型的区分能力,给出一致性度量的标准,若给定样本之间的特征值相同,类别也相同,则可以判断样本是一致的,以此为基础进行数据过滤[4]。Bernick等研究了过滤式特征选择法,认为过滤法可以对特征之间的关系、特征和类型之间的关系进行很好的度量,进而使特征选择变得更加有效[5]。本文研究了MIFS过滤式特征选择算法,并结合Boruta算法进一步拓展,实验证明本算法有效性较高。
1 MIFS特征选择算法的基本步骤与拓展
1.1 MIFS特征选择算法的基本步骤
对于小样本数据来说,特征选择不仅要对特征和类型之间的关联性进行考虑,还要考虑不同特征可能产生的冗余性,当特征和类型关联度有较大差别时,需要进一步避免冗余度的计算。根据以上问题的考虑,本文采用MIFS(MI-haled feature selection)算法,根据小样本数据度量特征和类型的关系,首先按照两者的关联性进行特征排序,然后在一定标准下将特征分组,从中找出所需的特征组成特征子集。
设特征子集的数据集所拥有的样本数量为,特征维度的数量为,而特征则用1,2,…,a
表示,类型用表示,用V表示a的值域,用V表示的值域。通过以上假设,a和的特征选择指数(a,)计算公式如下:
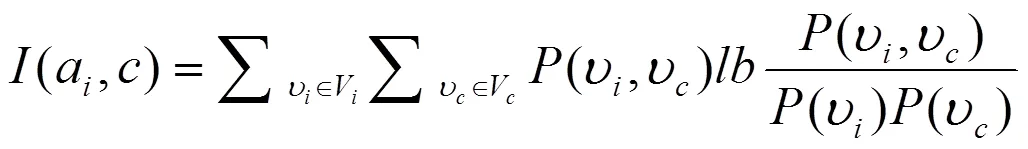
在上式中,(ʋ,ʋ)代表a取值ʋ且取值ʋ的概率,特征选择指数(a,)值越大,特征与类型之间的关联程度就越高。根据式(1)依次计算每一个特征和类型的特征选择指数,然后按照特征选择指数的大小,从高到低排序,并进一步分组特征子集,依据的标准为,该值用以下公式计算:
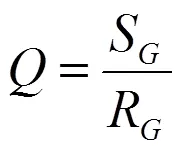
在上式中,代表一个特征组,S是和类型的关联度,R是里面全部特征的相似性。进一步计算S和R:
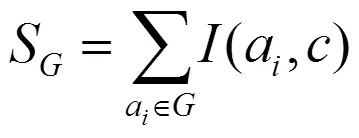
在上式中,里面的特征为a,a,(a,a)则是a和a的特征选择指数,用以下公式计算:
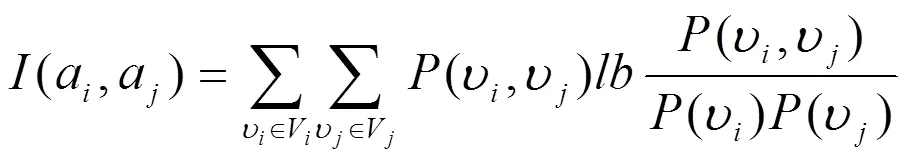
在上式中,(ʋ,ʋ)代表a取值ʋ且a取值ʋ的概率,特征选择指数(a,a)值越大,说明a与a越相似。同样道理,的值越高,该特征组的特征和类型关联度就越大,而组内各特征的冗余度就越小。反之亦然。为计算的初始值,需要在分组中放入2个通过选择的特征:第一个特征是排在首位的1;第二个特征需要计算1和另外各特征a的特征选择指数,得出特征选择指数值最大的特征,该特征与1最为相似。最后根据式(2)对标准值进行计算,记成0。
相对于另外的特征来说,将排在首位的特征在分组中添加并计算值,若≤0,则说明这个特征与其它特征有着较高的冗余度,这时需要进一步添加下一个特征,对新值进行计算并迭代,一直到>0为止,才停止添加特征。这时得到的特征组是第一个分组,没有进入该特征组的其它特征可以重复上面的步骤,产生新的一个特征组,最后目标是全部特征都分配到相应特征组内。候选特征子集则由每一个特征组首个特征所组成。根据以上分析,MIFS算法的基本步骤如下:
输入数据:特征子集的数据集、候选特征数。
输出数据:候选特征子集S。
第1步:根据式(1)计算特征子集的数据集内每一个特征和类型的特征选择指数(a,);
第2步:根据特征选择指数的大小,从高到底进行排序,得出目标特征集;
第3步:使=1,从特征集内取出排首位的特征1,放进特征组G;
第4步:根据式(3)对1和另外每一个特征a的特征选择指数(a,a)进行计算,取最大值特征放进特征组G;
第5步:根据式(2)对G的值进行计算,记成0。
第6步:从目标特征集的剩余特征里,取排在首位的特征放进特征组G,根据式(2)对G的值进行计算,若≤0,重复第5步,若>0,当前的特征组G即可作为首个分组;
第7步:使=+1,从目标特征集的剩余特征里,继续重复第3步到第6步,得出新特征组G,一直到=为止,或者目标特征集的剩余特征全部被分配到特征组;
第8步:取每一个特征组的首个特征,放进候选特征子集S;
第9不:返回候选特征子集S。
1.2 MIFS特征选择算法的拓展
MIFS特征选择算法虽然能够利用特征分组逐步去除冗余特征,但与许多传统型的过滤算法一样,很难确定出最佳特征,这就需要进一步拓展该算法,即将MIFS算法与其它能够有效确定最佳特征的算法相结合。本文选取了Boruta算法进行结合,形成一种新的MIFS-Boruta算法。Boruta属于一种全覆盖型的特征选择算法,其优势在于信息预测,而不考虑关联度的高低,能够根据信息预测找出全部的相关特征,因此比较适合最佳特征的确定。
在MIFS-Boruta算法中,可以对过滤后的结果进行充分利用,不断提高算法的运行效率,同时强化特征子集的分类性能。MIFS-Boruta算法还能确定特征子集内的特征数量,与过滤算法形成良好的互补。该算法的主要目标是提升特征选择算法的效果,能够自动选择冗余度及维数更小的特征,以确定最佳特征,基本计算步骤如下:
输入数据:特征子集的数据集、候选特征数、迭代数。
输出数据:特征子集。
第1步:在中进行MIFS计算,得出含有个候选特征的S;
第2步:从中取出S相对应的数据组成新数据集D;
第3步:在D中进行Boruta计算,迭代数为;
第4步:返回特征子集。
在MIFS特征选择算法初始阶段,会选择与特征选择指数最接近的特征放入最新特征组中,并作为各特征组的代表,被选为最优特征子集中的候选特征。这时需要通过Boruta算法从这些候选特征里面除去一些次要的特征,但是特征选择指数值最高的特征有着很强的分类效果,这样的特征不会被除去,而会在最优特征子集中得到保留。
2 结果与分析
2.1 实验数据
为验证本文算法在高纬度小样本数据中的有效性,选择了9个公开的数据集,所有特征的维数在1024~18847之间,平均维度为7297,有5个数据集的维数大于5000,有2个数据集的维数大于10000,主要类型是图像数据和生物学数据,如表1所示。
2.2 各算法特征选择的结果对比
为验证本文算法能否得到更好的特征选择结果,引入ICAP、CMIM、CIFE三种较为典型的特征选择算法,都属于传统的过滤式算法。为了使对比公平,在实验里分别将这三种算法结合Boruta算法,在每一个样本集中设定好候选特征数量,各算法最终选择出来的特征个数如表2所示。实验结果表明,任何一种算法的特征选择数都低于原始特征的维度,而在9个数据集中,MIFS-Boruta算法有6个数据集的特征数最多,体现了更广的特征选择量。

表 1 实验数据统计
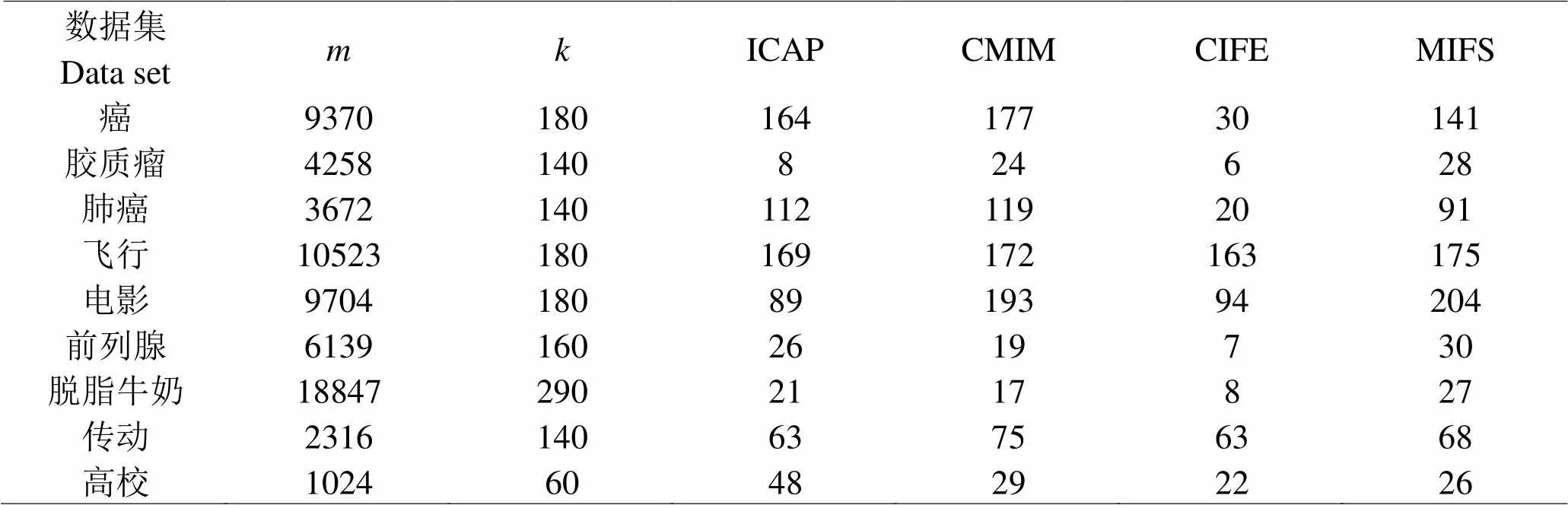
表 2 不同算法组合Boruta得出的特征选择结果
2.3 各算法特征子集的分类性能对比
为验证本文算法对于特征选择的有效性,依然以ICAP、CMIM、CIFE三种较为典型的特征选择算法作对比,分别在支持向量机监督学习模型上进行计算,实验采用以下2个指标验证性能:(1)最低分类错误率;(2)平均最低分类错误率。对比结果如表3所示。MIFS算法共有7个数据集的最低分类错误率最低,而且平均最低分类错误率也是最低,相对于其它算法来说有着良好的表现。
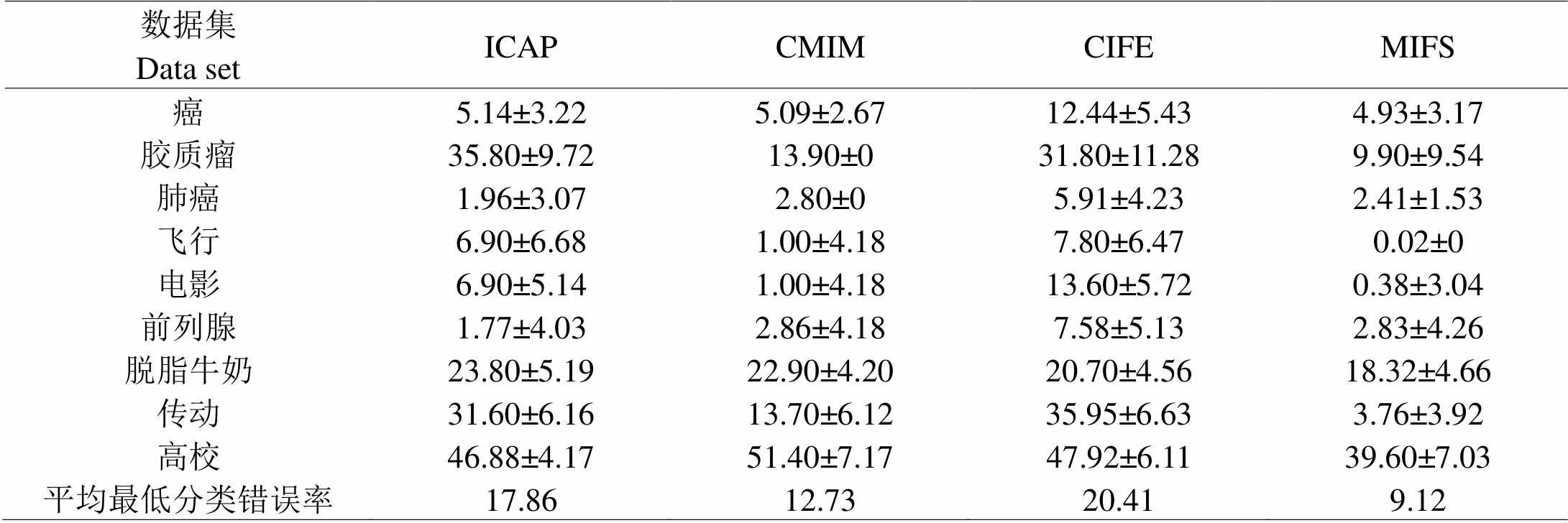
表 3 不同算法在支持向量机上的分类错误率统计(%)
3 讨论
小样本理论创始于十九世纪初,在区间估计和统计假设检验等领域得到广泛应用。小样本统计省钱省力,极大地节约了计算的时间,不仅受到统计学家的欢迎,还被工业、农业、科学研究等领域的工作者所重视。从此次实验结果看,本文提出的算法在高纬度小样本数据中的特征选择较为有效,能够取得更好的特征选择结果。Ekiz等认为小样本数据的特征维数较多,而且具备冗余特征,可以利用特征选择的方法降低数据维数[6]。Brewer等提出一种面向高维数据的迭代式特征选择方法,主要是改进了Lasso方法,实验结果表明,该方法可以较好地选择高维小样本数据集特征,属于当前比较有效的特征选择法[7]。Dahl等基于粒计算角度,提出一种粒化——融合框架下的高维数据特征选择算法,首先将原始数据集粒化成小规模的数据子集,并在每一个粒上建立起若干个套索模型,从而实现粒特征的选择,然后根据权重情况融合各粒特征的选择结果[8]。
4 结论
本文针对小样本数据特征选择问题,采用MIFS算法进行特征分组计算,选出最大相关性的特征,降低数据集维度。为解决最佳特征难以确定的问题,拓展了MIFS算法,提出一种MIFS-Boruta算法,在降低数据集维度的基础上,还能确定出最佳特征的子集。通过实验分析,验证了该算法的有效性。但是该算法涉及到的候选特征数量,需要通过人工方式进行设定,若数值偏大将会对最终的特征选择效率造成一定影响,若数值偏小则会对选出的特征性能造成影响,所以这方面还有待于进一步研究。
[1] Ditlevsen O. Baysian estimation of(>) from a small sample of Gaussian data[J]. Structural safety, 2017,68(4):110-113
[2] Lunardon N, Scharfstein D. Comment on "Small sample GEE estimation of regression parameters for longitudinal data"[J]. Statistics in medicine, 2017,36(22):3596-3600
[3] McNeish DH, Jeffrey R. Correcting Model Fit Criteria for Small Sample Latent Growth Models With Incomplete Data [J]. Educational and Psychological Measurement, 2017,77(6):990-1018
[4] Kamatchi PMK, Kavitha DSN. Data analytics: feature extraction for application with small sample in classification algorithms[J]. International journal of business information systems, 2017,26(3):378-401
[5] Bernick CB, Guogen SS. Sample size determination for a matched-pairs study with incomplete data using exact approach[J]. The British journal of mathematical and statistical psychology, 2018,1(1):60-74
[6] Kirubavathi G, Anitha R. Structural analysis and detection of android botnets using machine learning techniques[J]. International Journal of Information Security, 2018,17(2):153-167
[7] Brewer RP, John HM. A Critical Review of Discrete Soil Sample Data Reliability: Part 2-Implications[J]. Soil & Sediment Contamination, 2017,26(1):23-44
[8] Dahl JB. Mathiesen O, Karlsen APH. Evolution of bias and sample size in postoperative pain management trials after hip and knee arthroplasty[J]. Acta Anaesthesiologica Scandinavica, 2018,62(5):666-676
MIFS Filtering Feature Selection Algorithm for Small Sample Data
WANG Bo, LI Shi-hui, ZHENG Peng-fei
322000
Aiming at the problem of feature selection for small sample data and the difficulty of determining the best feature, a MIFS filtering feature selection algorithm was proposed, which combined Boruta algorithm to reduce the dimension of data set and determine the subset of the best feature. Through the experimental results and analysis, comparing with the other three traditional filtering algorithms, the effectiveness of the proposed algorithm was verified. The results showed that MIFS-Boruta algorithm had broader feature selection and the lowest average classification error rate.
Small sample; NIFS; algorithm
TP301.4
A
1000-2324(2019)01-0145-05
10.3969/j.issn.1000-2324.2019.01.033
2018-03-26
2018-05-04
浙江省自然科学基金:具有公共自行车子网的城市公交网络建模与优化研究(LY17F030016)
王波(1982-),男,博士,副教授,主要研究方向为自动化技术、计算机技术. E-mail:52672026@qq.com
猜你喜欢
数学物理学报(2022年4期)2022-08-22
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
自动化学报(2018年2期)2018-04-12
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
智能系统学报(2015年4期)2015-12-27
都市丽人(2015年4期)2015-03-20
振动工程学报(2014年4期)2014-03-01
