
基于稀疏框架的静态污点分析优化技术
2019-03-22 03:45何冬杰冯晓兵
计算机研究与发展 2019年3期
王 蕾 何冬杰 李 炼 冯晓兵
(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190) (中国科学院大学 北京 100049) (wanglei2011@ict.ac.cn)
当前,隐私数据保护是信息系统安全的重要研究挑战之一,大量的互联网(电子邮件、社交网络)、移动应用(移动支付、手机定位)、物联网(智能家居、智能医疗等)相关数据需要存放在应用端,如果应用程序因存在漏洞而被攻击者利用(完整性违反)或者第三方应用程序有意地窃取用户系统中本地的数据(保密性违反),则会产生隐私泄露问题[1].对系统应用中潜在的隐私数据泄露风险检测是当前该领域的重要研究方向.污点分析技术[2](taint analysis)是信息流分析技术[3](information-flow analysis)的一种实践方法.该技术通过对系统中敏感数据进行标记,继而跟踪标记数据在程序中的传播,检测系统的保密性和完整性等安全问题.据调查分析[4],在Android应用的静态安全检测中,污点分析是最为流行的分析方案.
污点分析又被分为静态污点分析和动态污点分析.静态污点分析是指在不运行代码的前提下通过分析程序变量间的数据依赖关系来进行污点分析.相比动态运行的污点分析,静态污点分析无需对程序进行插桩而导致运行时出现额外开销,并且不依赖于测试用例输入,可以在程序发布之前对应用程序进行检测,避免发布之后造成的安全问题.然而,当前静态污点分析技术的分析性能仍然不能满足安全检测的需求.例如,MudFlow[5]尝试使用静态污点分析工具FlowDroid[6]对当前Android应用市场的应用进行安全漏洞检测,它只能使用低敏感度的程序分析且在运行内存较大(730 GB)的环境下,一些例子仍然出现检测超时.并且,低敏感度的程序分析会报告出大量的误报,这会给检测人员带来诸多不便,同样降低了检测的效率,类似的问题还存在其他工作中[7-9].因此,对高敏感度的静态污点分析进行空间和时间上的优化是一个值得研究的问题.
最近,在程序分析领域中,大量的研究工作[10-18]尝试使用稀疏的方式对静态程序分析问题进行效率优化.所谓的稀疏程序优化是指数据流值(data flow fact)不再沿着控制流图(control flow graph, CFG)上进行传递,而转移到利用DEF-USE链得到的相关数据结构上传递.例如文献[10]利用了半稀疏(semi-sparse)的方法对指针分析进行优化,将指针数据流值从CFG上的传播转移到数据流图中进行传播.使用DEF-USE链代替CFG来传递数据流值可以消除不必要的传播计算从而达到优化的目的.
由于污点分析只是分析污点能否从污点源(source)传播到汇聚点(sink),是一种按需的分析方式,当前的主流静态污点分析(FlowDroid)是基于IFDS框架的,而目前的IFDS框架是没有对稀疏优化进行支持的.因此,本文的工作内容正是尝试利用稀疏的优化方法对静态污点分析进行优化.
本文的主要贡献包含4个方面:
1) 发现并分析当前基于IFDS(interprocedural,finite,distributive,subset)问题的静态污点工具FlowDroid计算中存在大量无关联传播,并通过实验验证其比例平均高达85.2%.
2) 为了支持稀疏的污点传播,提出了一种稀疏的IFDS数据流分析框架,提供面向流敏感和域敏感的变量使用点索引的计算方法.
3) 设计了基于稀疏数据流分析框架的污点分析技术.
4) 实现一个基于本文技术的原型系统Flow-DroidSP,经过实验验证,该工具在提升性能的同时没有带来精度上的损失.在非剪枝模式下,相比原FlowDroid具有平均4.8倍的时间加速和61.5%的内存降低,在剪枝模式下,具有平均18.1倍的时间加速和76.1%的内存降低.
1 背景知识
1.1 IFDS数据流分析框架
一般而言,静态污点分析问题都是被转化为数据流分析问题[19]进行求解:首先为每一个过程构建控制流图或者过程间的控制流图,然后根据不同敏感度(上下文敏感、流敏感等)进行具体的数据流传播分析(与指针/别名分析).IFDS框架[20]是一个精确高效的上下文敏感和流敏感的数据流分析框架,其全称是过程间(interprocedural)、有限的(finite)、满足分配率的(distributive)、子集合(subset)问题.该问题作用在有限的数据流域中且数据值对并(或交)的集合操作满足分配率.满足上述限定的问题都可以利用IFDS算法进行求解(文献[20]中的Tabulation算法),而污点分析正是满足IFDS算法要求的一个问题.污点分析的数据流值是污点变量,它表示有哪些污点变量可以到达当前程序点.
IFDS问题求解算法的核心思想就是将程序分析问题转化为图可达问题[21].算法的分析过程在一个按照具体问题所构造的超图(exploded supergraph)上进行(如图1例子所示).其中数据流值可以被表示成图中的节点,算法扩展了一个特殊数据流值:0值,用于表示空集合;程序分析中转移函数的计算,即对数据流值的传递计算被转化为图中的边的求解.为了更好地进行描述,算法根据程序的特性将分析分解成4种转移函数(边):1)Call-Flow,即求解函数调用(参数映射)的转移函数.2)Return-Flow,即求解函数返回语句返回值到调用点的转移函数.3)CallToReturn-Flow,即函数调用到函数返回的转移函数.4)Normal-Flow,是指除了上述3种函数处理范围之外的语句的转移函数.IFDS求解算法Tabulation是一种动态规划的算法,即求解过的子问题的路径可以被重复地利用,而由于其数据流值满足分配率,因此可以在分支或函数调用将边进行合并.求解算法包括了2类路径的计算:路径边集(path edges)和摘要边集(summary edges).路径边集表示的是起点0值到当前计算点的可达路径,使用传播函数propagate将计算完成的边继续沿CFG传播到其下一个节点;摘要边集表示的是函数调用到函数返回的边,其主要特点是如果在不同调用点再次遇到同样的函数调用,可以直接利用其摘要边集信息从而避免了函数内重复的路径边集的计算.
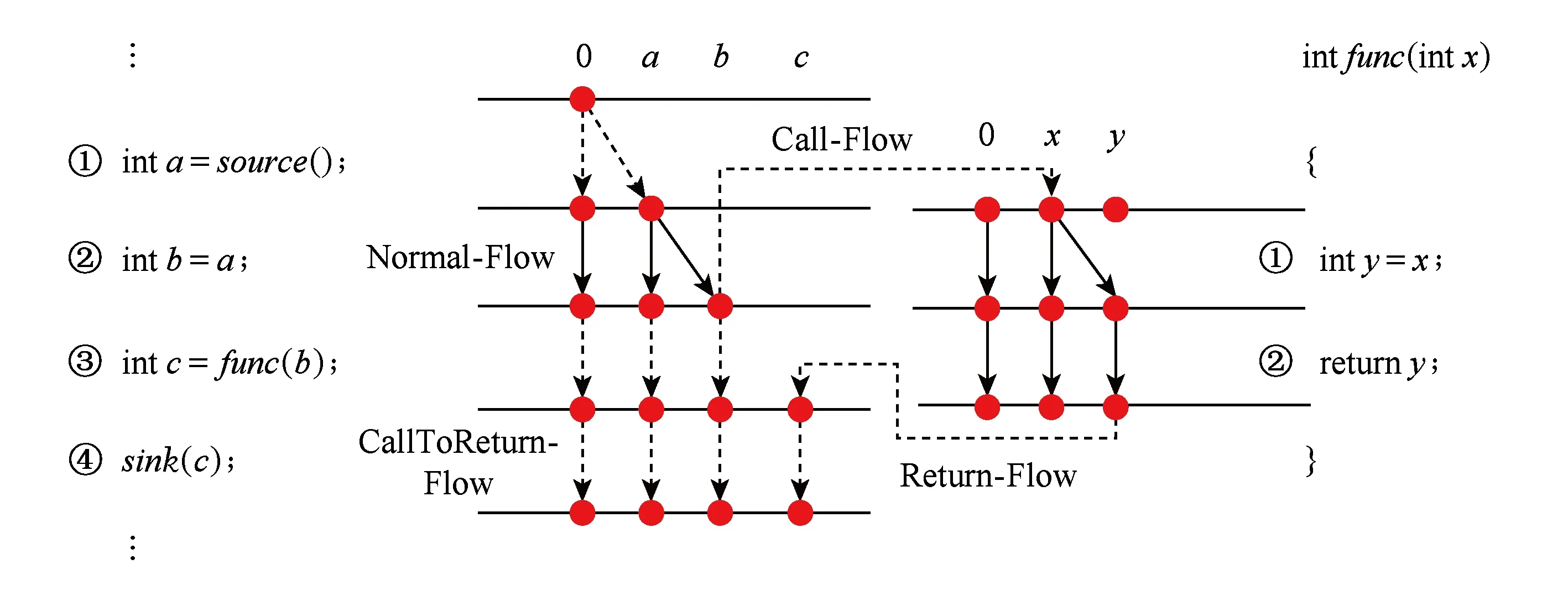
Fig. 1 An example of taint analysis by using IFDS algorithm图1 使用IFDS算法求解污点分析示例
1.2 FlowDroid与别名分析
FlowDroid[6]是当前最为流行的面向Java,Android应用程序的开源静态污点分析工具,被广泛应用于Android App的隐私泄露检测和Java程序相关安全漏洞挖掘.FlowDroid基于Java分析工具Soot[22],将待分析程序字节码转化成Soot中间表示Jimple,随后在Jimple上进行静态的污点分析.其分析的结果是多个污点源到污点汇聚点(source→sink)的集合.在污点传播分析中,FlowDroid正是基于IFDS数据流分析框架.同时,FlowDroid使用访问路径(access path,即形如v.f.g)来支持域敏感,如果访问路径长度超过预定值时,FlowDroid将对其进行保守的裁剪(例如裁剪成v.f.*的形式),在具体实现中访问路径的长度一般设置为5.因此,FlowDroid具有流敏感、上下文敏感、域敏感的高精确度.
FlowDroid的另一贡献就是提供了一种按需的面向别名的污点传播方法,该方法同样是基于IFDS框架的.具体来讲,FlowDroid在遇到一个堆变量(heap object)的域进行污点赋值时,会启动一个后向的IFDS求解器求解其别名相关的污点值,如果生成与该变量别名的污点变量,则又启动一个前向的IFDS求解器进行前向传播该值.以图2中的伪代码为例,程序的行④污点源(函数source()的返回值)赋值到了一个堆对象的域a.f中,此时将启动一个后向的分析来寻找与a.f别名的污点值(过程1),当后向求解器分析到a使用点行②时,将产生与a别名的对象b的对应污点值,即b.f(过程2),同时启动一个前向分析,继续找b.f的使用位置(过程3).同理,过程4/5/6/7是对b.f和c.f的进一步传播.为了解决流敏感的分析,FlowDroid引入激活点的概念,激活点的作用是保证未被激活的变量只有通过了激活点之后才是一个真正的污点值,否则即便到达泄露点也不会触发泄露.例如在过程6中的c.f变量只有再次经过了行④的激活点到达行⑤触发了sink,才是一个真正的泄露.而对于过程3中的b.f,虽然也到达了函数sink,但是它没有经过激活点,因此行③的sink不能被触发.
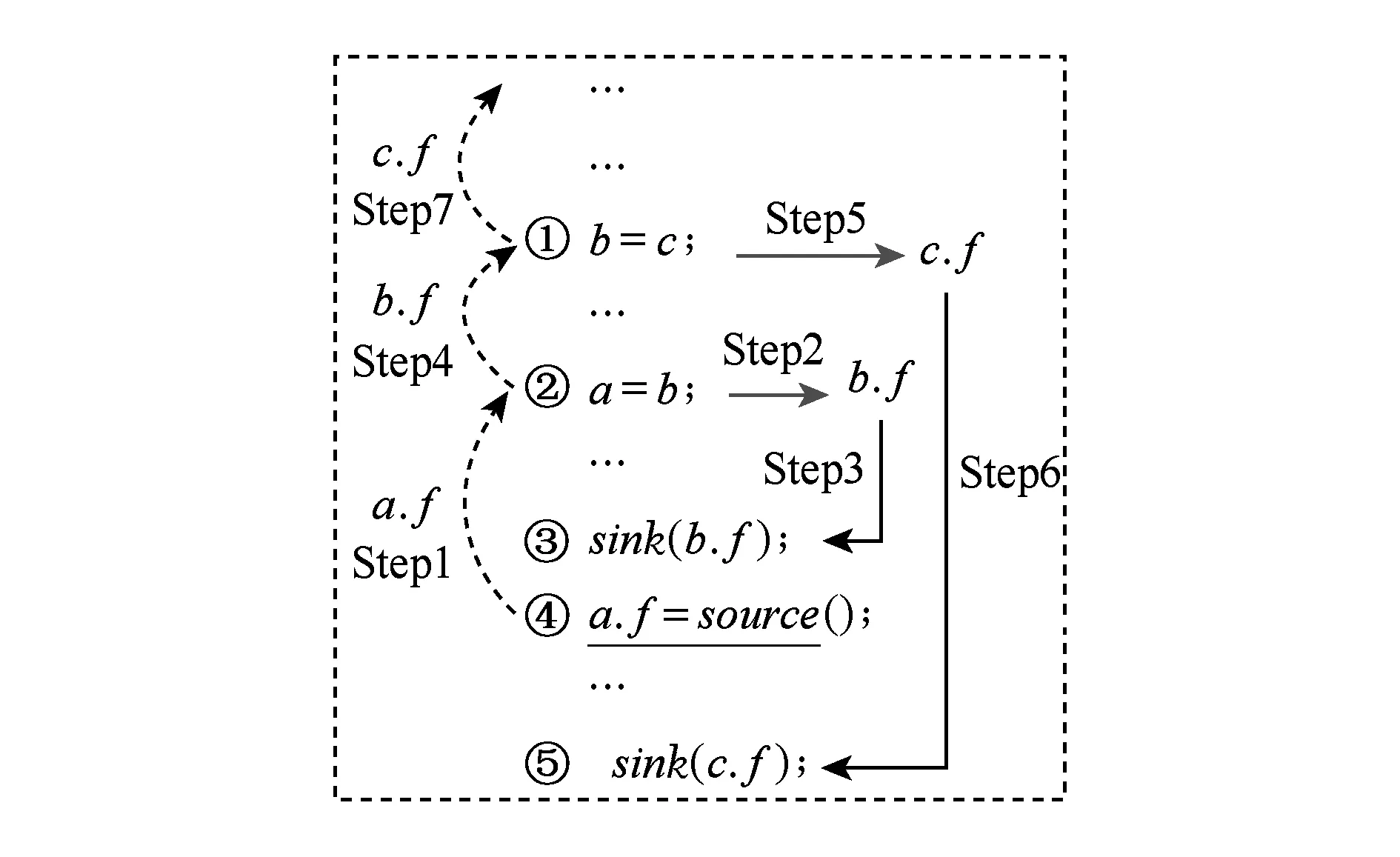
Fig. 2 An example of FlowDroid-style alias based taint analysis图2 FlowDroid方式的别名间污点传播示例
本文的工作正是基于FlowDroid进行扩展优化的,目前FlowDroid中污点传播所使用的数据流分析无论是前向求解还是后向求解(计算别名)都是基于IFDS框架的.IFDS框架的计算规模直接影响了污点分析的开销.然而,当前IFDS框架仍然是基于CFG或过程间CFG的,这会导致数据流分析中存在无关联的传播.所谓的无关联传播是指数据流值传播到某语句,但是该语句不会利用其生成其他数据流值或将其杀死,例如图1中变量a在行①被使用之后还会继续传递到行②~④直到程序结束,而行③~④中没有使用a产生其他数据流值,a在行③~④上的传播正是无关联传播.因此本文的目标正是利用稀疏的优化方法来消除这种无关联的传播,从而达到效率优化的目的.
2 研究动机
在面向高精确(流敏感和域敏感)的污点分析的计算中,无关联的数据流传播还将被扩大,进而产生更大的性能开销.具体来讲:
1) 现代编译器利用中间表示对程序进行分析或者优化,基于3地址的中间表示被各大编译器采用(如Soot的Jimple表示).例如图3(a)程序为一段程序的源码,图3(b)程序是其3地址表示,这种转换过程必然会引入大量的临时变量,对于行②中的b.f.h=a.f语句将被转化为程序图3(b)中的行②~④的程序,其中利用了2个临时变量tmp1,tmp2.这种临时变量的使用会增加无关联传播的规模.

Obj foo(Obj p){ …① a.f=p;② b.f.h=a.f;③ retum b.f.h;} Obj foo(Obj p){ …① a.f=p;② tmp1=a.f;③ tmp2=b.f;④ tmp2.h=tmp1;⑤ retum tmp2.h;}(a) Source code(b) Three-address IR void caller1(){ …① x.f1=source();② Obj y=foo(x);③ sink(y.f1);} void caller2(){ …① x.f2=source();② Obj y=foo(x);③ sink(y.f2);}(c) Caller1(d) Caller2
Fig. 3 An example of unrelated taint propagation
图3 无关联污点传播示例
2)为了支持域敏感的分析,FlowDroid使用访问路径来表示污点变量,由于相同对象的不同域需要不同的区分,这会导致同一份代码因不同域的使用而被执行多次、无关联传播将会被放大.例如,图3(c)和图3(d)中程序都调用了函数foo(),但是它们所传递的参数对应的域是不同的,分别是x.f1和x.f2.对于同一个对象但访问不同参数的情况,IFDS认为它们是不同的变量而不会对其进行摘要优化.此时,参数p.f1传递到tmp2.h 等过程产生的变量,如tmp1.f.f1和tmp2.h.f1等,那么对于p.f2的计算,也同样需要再次生成,如变量tmp1.f.f2和tmp2.h.f2等,可见无关联传播增加了1倍.
3) 为了支持流敏感,FlowDroid使用了激活点的方法,每一个未被激活的数据流都会存在一个激活点,即使数据流值中的访问路径相同但因激活点不同,数据流值仍然是不同的,同理2)这也同样导致摘要优化失效.不同激活点的数据流值通过相同的代码片段将会导致这种无关联传播的增加.
为了验证上述无关联传播确实存在,以及计算其规模和所占比例,我们针对FlowDroid进行实验验证.
具体的评测对象是最新版本的FlowDroid(2017年11月),针对其IFDS计算边进行插桩统计,统计的规则有3项:
1) 对于Normal Flow和CallToReturn Flow,通过该函数生成了其他值或者被杀死,那么置为有关联的,否则视为无关联传播.
2) 对于Call Flow,如果存在被调用函数(callee)且当前数据流值可以通过被调用函数生成相关形参,那么这个变量是有关联的传播.
3) 对于Return Flow,如果数据流值可以通过退出语句生成调用者(caller)的相关返回值,那么将设置其为有关联的传播.
评测的实验机器配置是:64核Intel®Xeon®CPU E7-4809(2.0 GHz)和128 GB RAM,为每一个Java虚拟机分配32 GB的内存.配置选项选择打开流敏感性并且设置访问路径的长度为5.具体的评测用例是在安智网[23]随机下载的25个Android应用程序.由于某些软件是不存在恶意行为的且对计算规模较小的程序评测没有意义,这里去除掉了没有产生泄露结果或分析结果过快(小于10 s)的6个应用和3个运行超出内存的应用,最终评测用例集合包含16个应用程序,它们的基本信息如表1所示,本文后续评测用例所用标号是与该表标号一一对应的.随后使用FlowDroid对其运行3次检测,提取结果并求平均值,其最终的统计运行结果如表2所示.
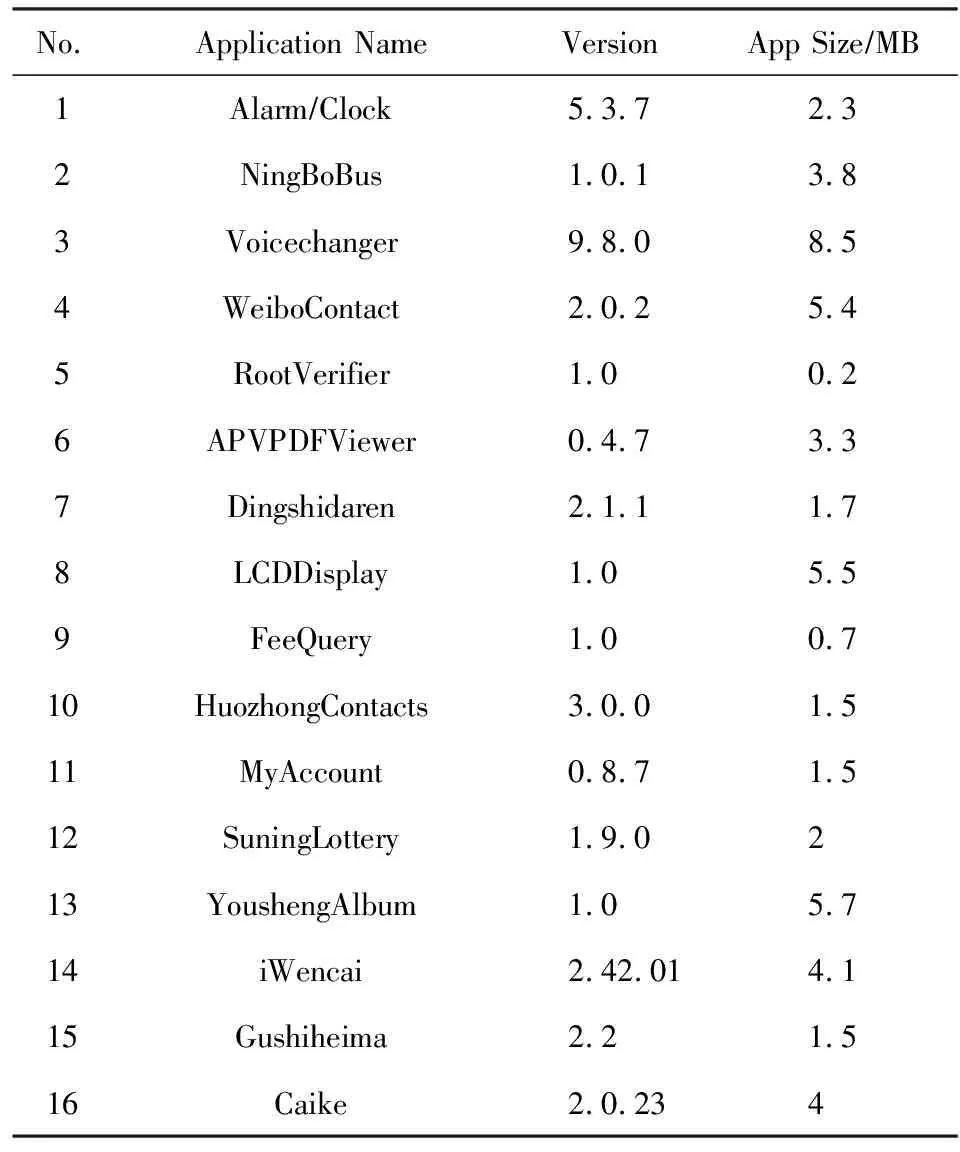
Table 1 The Information of Evaluation Dataset表1 评测用例基本信息
表2中第2列(Running Time)和第3列(Memory Size)是程序的运行时间和内存开销.其中编号11的程序,尽管程序的规模只有1.5 MB,但是程序运行时间却长达1 922 s,这正是由于流敏感和上下文敏感的较高时间复杂度导致的.第5列(#IFDS)是总的IFDS计算边个数,而第6列是无关联的IFDS计算边(#UR-IFDS)个数,其中总IFDS计算边个数平均高达1.1×107,而无关联IFDS计算边个数平均为1.01×107.可见无关联的计算边占总计算边的比例是很高的,其中最低比例是79.1%,最高比例为92.9%,平均比例为85.2%,这也充分验证了前面的分析.所以得出结论是:由于域敏感和流敏感的特性使得IFDS算法的摘要优化失效,当前无关联的计算占总计算的比例较高且规模较大.本文的研究目标正是尝试将数据流值直接传递到其使用点的位置,跨过这些无关联的传播(稀疏的方式),来消除这种无关联的计算.
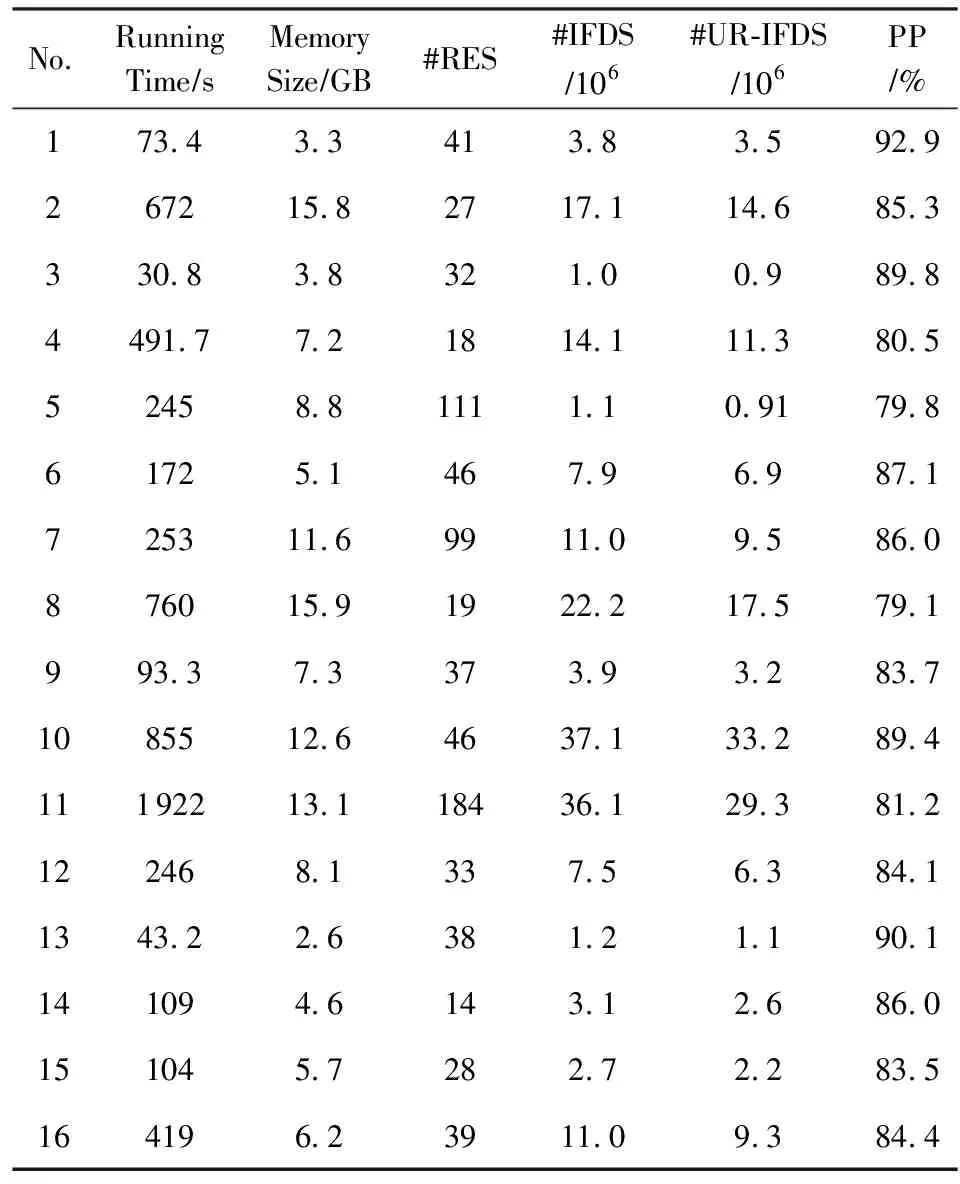
Table 2 The Results on Evaluation of FlowDroid表2 使用FlowDroid对数据集进行评测结果
为了解决该问题,本文的方法将DEF-USE链的思想引入到IFDS计算框架中,在数据流传播时,直接将数据流值从其产生的位置传递到其真正使用点.
3 稀疏的IFDS框架
提供稀疏的污点分析的前提正是提供稀疏的数据流分析框架.本节将介绍如何将经典的数据流分析框架IFDS扩展成稀疏的形式.本文的方法同样是尝试使用DEF-USE链来代替CFG进行数据流值传播.然而与传统方法不同的是:为了支持域敏感和流敏感,本文使用了一种特殊的数据结构来存储变量的使用点,并提供了快速的构建算法(3.3节和3.4节介绍),最后我们在3.5节修改了原IFDS的传播函数,将得到的数据流值直接传播到其使用点.
3.1 指令定义
首先定义本框架中用到的指令规则,将程序中所有语句转化为3地址的形式(Jimple中间表示形式),保证程序中只存在6种与数据流传播相关的指令.为了方便后续规则的表示,这里将赋值语句[COPY]根据目标为左值或者右值的情况分成[READ]和[WRITE]形式.对于堆变量的域访问,如形如v.f变量的访问,我们命名其堆所在对象为基对象(base),即变量v,f则是基对象中的域(field).对堆对象域的读和写被定义为[LOAD]和[STORE]规则.如表3所示为所有的6种指令规则.

Table 3 The Rules of the Instruction表3 指令规则
3.2 变量使用点索引
为了维护域敏感和流敏感性,这里使用一种特殊的数据结构来表示变量的DEF-USE关系.
定义1. 变量使用点索引.变量使用点索引是一个表(map)结构,它的键值(key)是变量的域,它的值(value)是该变量对应域的所有使用点集合.
这里使用一个特殊域null来表示变量中域为空的情况,使用函数setUses[f]=[stmt]表示将语句[stmt]加入到变量的域f的使用点集合中,使用v.getUseStmts(f)来表示获得的f域对应的使用点集合,使用v.getUseStmts(*)表示获得v的索引表中所有域对应的使用点集合.
3.3 自治数据流图ADFG
定义2. 自治数据流图(autonomous data flow graph, ADFG).自治数据流图是一个有向图G=N,E,其中节点N表示程序中的变量且所有变量的基对象相同,边E为表示节点所在语句之间的控制流.
如图4(b)正是基对象为a的自治数据流图,对于基对象a的所有相关变量均在该图中,且这些变量所在的语句(图4(b)用行号表示)之间的控制流是节点之间相连的边.ADFG的优势就是图中变量的基对象相同且保存了完整的控制流信息,之后对每一个独立的变量计算其DEF-USE(变量使用点索引)时,即可在ADFG中进行,这既提高了分析效率,又保证了流敏感.
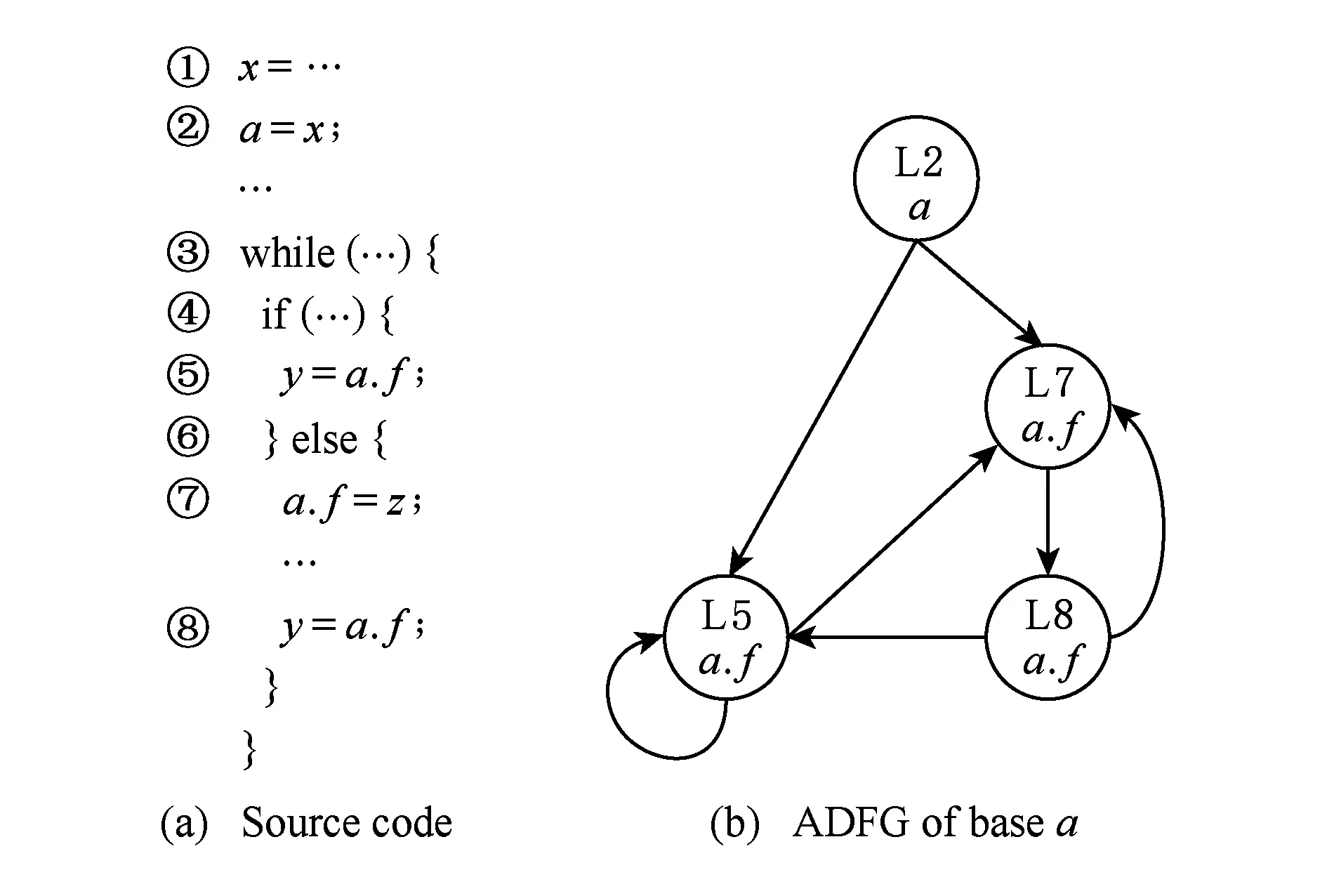
Fig. 4 An example of ADFG图4 自治数据流图(基对象为a)示例
基于ADFG的定义,我们提供了一种快速的构建ADFG的算法.该算法将按照变量的基对象进行分区,然后对于每一个分区中的变量分别计算其独立的数据流图.具体算法如算法1所示:
算法1. 构建自治数据流图算法.
输入:程序的allCFGs;
输出:程序的allADFGs.
①collectVariables(…);
②partitionByBasicBlock(…);
③buildADFG(…).
子过程1.collectVariables.
输入:程序的allCFGs.
① for eachoneCFGinallCFGsdo
② for eachvarin eachstmtofoneCFGdo
③varInfoSetMap[base]←[var,bb,idx];
④ end for
⑤ end for
子过程2.partitionByBasicBlock.
输入:varInfoSetMap.
① for eachvarInfoSetinvarInfoSetMapdo
② for eachvarinvarInfoSetdo
③bb=var.getBasicBlock();
④bbToVarInfoMap[bb]←var;
⑤ end for
⑥ end for
子过程3.buildADFG.
输入:bbToVarInfoMap.
① for eachbbinbbToVarInfoMapdo
②ret=innerBBSolver(bb,bb.varSet);
③ varinfotail=ret.getTail;
④ fornextinbb.getSuccsdo
⑤traverseEachBB(next,tail);
⑥ end for
⑦ end for
子过程4.traverseEachBB.
输入:后继基本块next,和前驱基本块的尾节点preTail.
①ret=innerBBSolver(next,next.varSet);
②varinfohead=ret.getHead;
③preTail.setSucc(head);
④ fornextinbb.getSuccsdo
⑤traverseEachBB(next,ret.getTail);
⑥ end for
函数collectVariables将变量按照其基对象进行分区,存储到Hash表varInfoSetMap中,对于一个变量,这里存储的信息包括变量的值var和其基本块信息bb以及其所在基本块内部的索引号idx.函数partitionByBasicBlock再通过它所在的基本块分区并存储到Hash表bbToVarInfoMap中.之后,函数buildADFG对基对象相同的变量集合按每一个基本块进行遍历,在基本块内部,buildADFG调用innerBBSolver方法顺序的将后继语句加入到前驱语句的后继集合中.在基本块之间,buildADFG通过innerBBSolver的返回值得到每一个基本块的头节点和尾节点,为上一个基本块的尾节点设置下一个基本块的头节点为其后继.
至此,ADFG上每一个变量都包含其控制流中的后继信息,且不包含其他基对象的变量.函数collectVariables和partitionByBasicBlock线性地扫描程序中的变量,所以其算法时间复杂度是线性的.而buildADFG将对每一个基本块进行遍历,在基本块内部则顺序访问每一个变量,所以buildADFG算法的时间复杂度也是线性的,整个构建ADFG算法的时间复杂度是线性的.
3.4 变量使用点索引的计算
在ADFG上,所有变量的基对象均相同且仍包含其控制流信息,整个CFG按照基对象的不同被分成多个ADFG.分析器将分别遍历每一个ADFG,使用数据流分析的方法计算其变量的使用位置,将其存储到使用点索引中.如表4所示为计算使用点索引的数据流转移函数,图5为对应示例.我们将在4.2节讨论如何使用该索引为污点分析的访问路径生成具体的使用点以及对使用点集合进行剪枝.该分析使用了传统的工作集(worklist)算法,初始化集合是所有语句中的变量v/v.f与当前语句[stmt](即变量的定义语句)组成的对[stmt],v/v.f.

Table 4 Data Flow Transfer Function for Computing
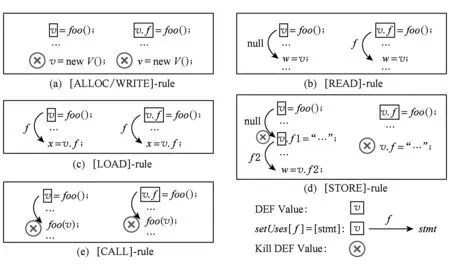
Fig. 5 Examples of variable using map computing图5 计算变量使用点索引示例
表4中,第3列定义值(DEF value)是转移函数的输入,即变量的定义位置传递过来的数据流值,转移函数的功能是决定是否将当前语句设置为该值的使用点.根据3.1节中的指令定义,定义值只能为v或者v.f的形式,例如图5中被方格括住的变量.第4列Set USE Rule表示对定义值设置使用点索引的规则.为了区分域敏感特性,需要为不同的域存储不同的使用点.如3.2节定义,使用setUses[f]=[Stmt]来表示将语句[stmt]加入到变量v的域f的使用点集合中,而setUses[null]表示定义值域是空的情况.第5列IsKill列表示定义值是否被杀死(True)或者继续寻找其使用位置(False).
对于[ALLOC]和[WRITE]规则,如图5(a)中例子所示,无论定义值是v还是v.f,都会将对v变量进行重新赋值,传来的定义值不再有效.因此设置IsKill为True且不会产生使用关系.
对于[READ]规则,如果定义值是v,如图5(b)左侧程序,说明任何的形如v.*的访问路径都会传递到使用点,所以设置空域的使用点集合(setUses[null]=[stmt]).如果定义值是v.f,如图5(b)右侧程序,说明只有形如v.f.*的访问路径会传递到使用点,则设置域f的使用点集合(setUses[f]=[stmt]).
对于[LOAD]规则,说明访问路径第1个域满足和f相等时才会被使用.所以无论访问路径是形如v.*或v.f.*的输入,都将设置域f的使用点集合(setUses[f]=[stmt]).
对于[STORE]规则,如果定义值是v.f,如图5(d)规则右侧程序,同[WRITE]规则,传来的定义值不再有效.如果定义值是v,说明形如v.*的访问路径可能传播到该语句,且需要杀死其中第1个域为f的值.由于当前访问路径是无法表示形如v.{*-f}的数据流值,为了不丢失信息,这里使用一种延迟处理的方法:首先将该语句加入到定义值空域的使用点集合中(setUses[null]=[stmt]),然后保守地认为该定义值全部失效(将其杀死),最后在初始化集合中增加一个虚拟的[stmt],v的定义值,增加新的虚拟定义值的目的是为了继续传播除f域之外的值.以图5(d)左侧程序为例,假设函数foo的返回值得到的访问路径是v.f2,v.f2根据空域的使用点可以传播到[v.f1=“…”;]处,由于域不同,分析规则不会杀死该值,则会继续启动对v.f2使用点的查询,此时将使用虚拟定义值v进行索引查询,即可找到域f2的使用点[w=v.f2;].如果函数foo的返回值是v.f1的话,该值传播到[v.f1=“…”]会根据分析规则被杀死.这种延迟处理的方式既不会损失精度又可以正确地进行更新.
对于[CALL]规则,如图5(e)所示规则.这里设置使用点的规则同[WRITE],这是因为在IFDS框架中函数的参数是否能够通过函数调用继续向下传递是由Call和CallToReturn规则决定的,所以这里直接将定义值置为失效,待Call和CallToReturn产生其返回值再进一步查找与传播.
3.5 传播函数
框架还需修改原IFDS框架的传播函数(文献[20]中算法行35的函数propagate),这里为传播函数增加一个包装函数propagateWrapper,如算法2所示.
算法2. 稀疏的IFDS传播函数propagate-Wrapper.
输入:定义语句src、目标数据流值dtarget;
输出:目标语句use、目标数据流值dtarget.
①useSet=defValue.getUseStmts();
② for eachuseStmtinuseSetdo:
③propagate(useStmt,dtarget)
④ end for
包装函数将通过当前变量及其使用点索引获得其使用点集合,然后将数据流值直接传递到其使用点.本算法不会影响IDFS产生新的数据流值的计算,而只是修改其传播的目的语句,即达到稀疏传播而又不影响正确性.例如图6中a在行②处将仍然会产生b值,但会将b值直接传播到其使用位置,即行③.
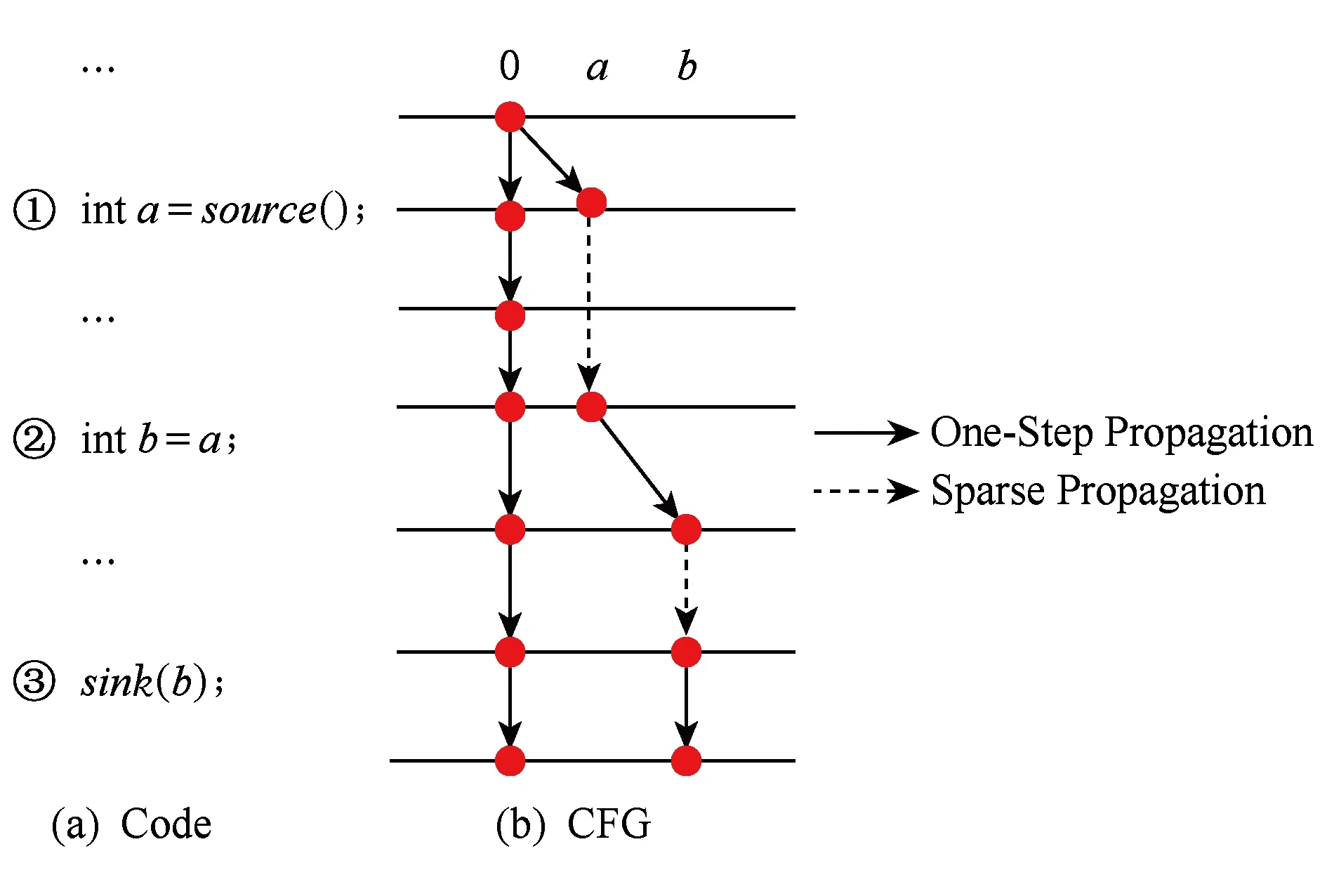
Fig. 6 An example of sparse IFDS framework图6 稀疏的IFDS框架示例
4 基于稀疏框架的污点分析
4.1 总体框架
基于第3节的稀疏框架,本节设计实现了与其适配的污点分析技术,图7所示为其整体框架.相对于传统的污点分析(FlowDroid),该框架增加一个预先分析(preAnalysis)的过程,即构建ADFG和计算变量使用点索引的过程.与FlowDroid一样,分析的第1部分仍是待分析程序的ICFG(图7中Build ICFG过程),以此作为预先分析的输入.预先分析过程生成的使用点索引作为污点传播前向分析和后向分析(别名分析)的输入,最后是输出结果部分.
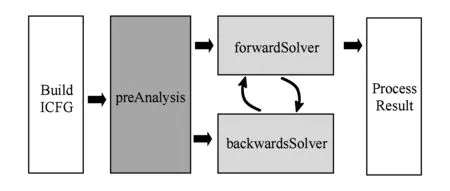
Fig. 7 The overview of the our taint analysis framework图7 基于稀疏的污点分析总体框架
4.2 污点传播中使用点的维护与剪枝
由于在3.4节中提供了面向域敏感和流敏感的变量使用点索引,本节将根据具体的输入使用这些索引产生污点分析的使用点,并达到对使用点集合剪枝的效果.与FlowDroid类似,我们同样使用访问路径来表示数据流值.具体如算法3所示:
算法3. 污点传播使用点集合剪枝算法.
输入:当前语句点stmt、数据流值访问路径apath;
输出:数据流值的使用点集合useSet.
① ifapath.getFirstField≠null do
②useSet=∪getUseStmts(apath.
getFirstField)+getUseStmts(null);
④ ifisStore(stmt) do:
⑤useSet=∪(getUseStmts(*)-
getUseStmts(f));
⑥ else
⑦useSet∪=getUseStmts(*);
⑧ end if
⑨ end if
算法3的输入是当前语句stmt和产生的数据流值的访问路径,这里用apath表示.如果当前apath是形如v.f.*的形式,即访问路径的第一个域是f,那么使用域null和f产生其使用点集合,即算法3中行②.这种方法可以过滤掉和f域不同的且不为空的域的使用点.如果apath是形如v.*的形式,说明当前v的子域不确定,因此需要传播到其所有域的使用点,即算法3的行⑦.一种特殊的情况,如果语句是[STORE]形式,根据表4的[STORE]规则,当前存在一个v的虚拟定义变量的使用点索引,那么查找并使用该索引:除了需要产生所有域的使用点之外,还需要从中减去当前语句被赋值域的使用点,即算法3中行⑤,这是由于当前[STORE]已经将该域更新为其他值,无需再为该域计算使用点.最终算法的输出是useSet,即根据当前访问路径得到的使用点集合.
本文的方法虽然没有改变算法的复杂度(IFDS算法的时间复杂度为O(ED3),空间复杂度为O(ED2),其中E是当前控制流图中的边个数,D是数据流域的大小).但是由于我们的方法对当前控制流图转化成稀疏的形式(自治数据流图),所以E的值将会明显的缩小,此外D的值也由于无关联传播被消除而变小,这也是本文方法能够提高效率的原因.
4.3 面向别名传播的变量使用点索引
在反向的IFDS计算中,后向的别名间污点传播使用的变量使用点索引与前向传播稍有不同:由于需要在使用点计算其别名的污点,所以同样将语句加入其使用点集合中.表5是对应的转移函数,其中与正向的转移函数不同的是:[ALLOC]和[WRITE]和[LOAD]规则,即需要保留它们的使用点.

Table 5 Data Flow Transfer Function for Computing
4.4 流敏感的别名传播维护
为了维护流敏感的别名传播,基于IFDS的污点分析引入了激活点的概念,稀疏的方法同样需要考虑这个问题,由于稀疏的方法不能沿着CFG上的每一条语句进行传播,这给维护激活点带来了挑战.
为了解决该问题,我们利用了可能可达性的概念,所谓的可能可达(may reach)是一种偏序关系|→:如果程序语句S1和S2存在偏序关系S1|→S2,则说明可能存在一条执行路径使得变量从S1到EXIT流经S2.相反,如果S1|→S2不被满足,则说明一定不存在一条执行路径从S1到EXIT流经S2.
那么,定义当前污点变量的定义点是defStmt,污点变量的激活点是activeStmt,污点变量的使用点是useStmt,如图8中所示.则污点值被激活的必要条件是:
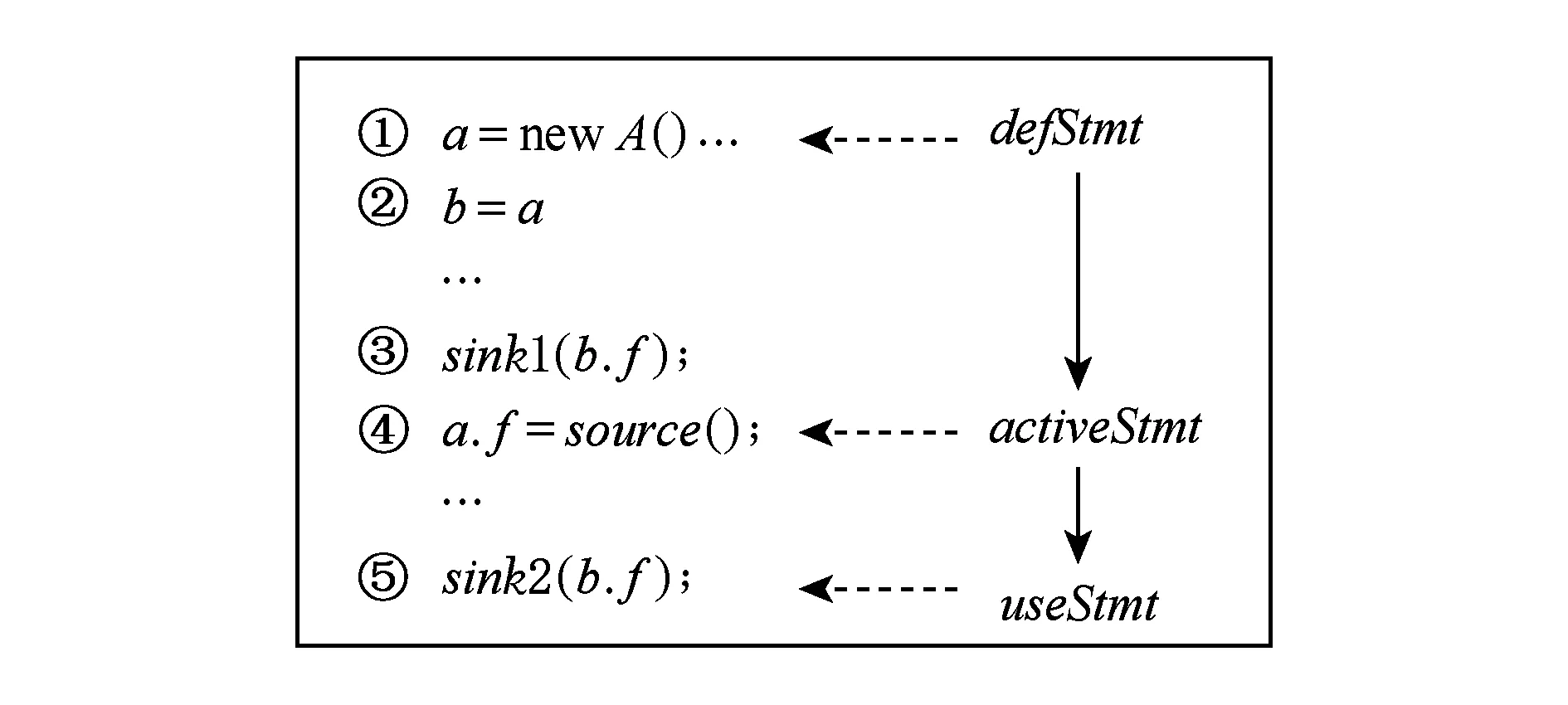
Fig. 8 An example of active stmt maintenance图8 FlowDroid的激活点维护示例
约束1.defStmt|→activeStmt且activeStmt|→useStmt.
证明. 必要性证明.如果defStmt|→activeStmt不满足,那么污点变量不会流经激活点,污点一定不会被激活.如果activeStmt|→useStmt不满足,则说明到达activeStmt的值一定不会到达useStmt,也就不会存在被激活的变量到达useStmt.
证毕.
至于偏序关系|→是可以在预处理阶段计算出的哈希映射进行查询的.比较过程内2点S1和S2的偏序关系|→的方法:如果它们在一个基本块中且该基本块不在循环中,那么直接比较其基本块内部索引号.否则比较基本块之间的可能可达关系.而基本块的可能可达关系可以在预处理中很快的得到一个Hash映射.所以整个偏序关系比较的时间复杂度是O(1)的.
不过满足约束1的情况并不是满足污点激活的充分条件,这是因为会存在数据流值被杀死的情况.为了保证精度,我们为满足约束1的数据流值再启动一个独立的更新(update)分析,更新分析是沿着CFG进行的,直接使用传统数据流方程求解(与FlowDroid方法一致).如果数据流值既满足约束1又不被更新阶段所杀死,则说明是被激活的.
4.5 剪枝优化讨论
至此,本文的算法既保证了稀疏性又保证相比原FlowDroid不会损失任何的精确度.在具体实现中,基于变量使用点索引的剪枝算法还能够消除FlowDroid的误报,提高检测的精度.具体分析:
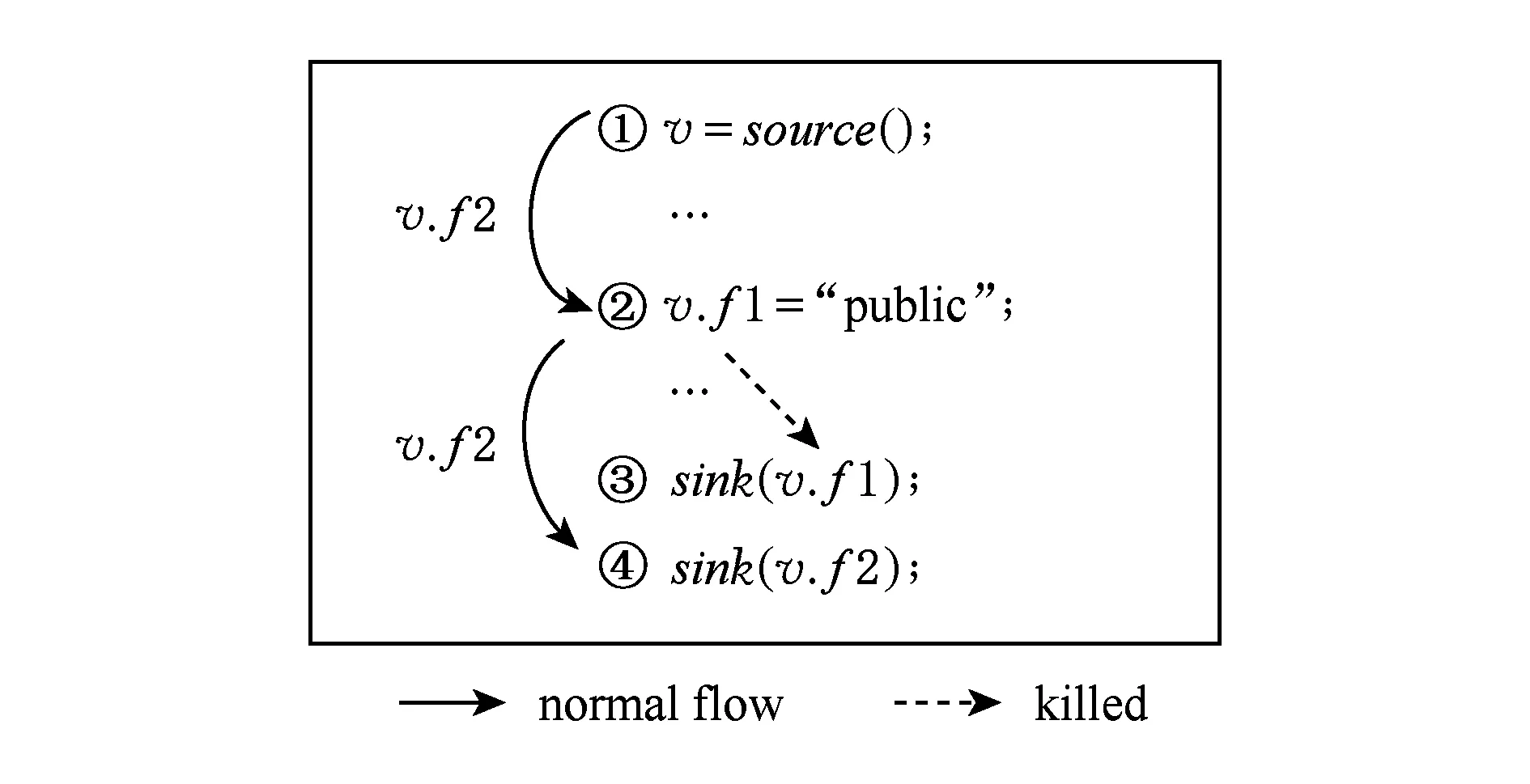
Fig. 9 An example of FlowDroid conservative sub-field process图9 FlowDroid的保守子域处理示例
如果当前分析器不确定具体的访问路径的子域时,FlowDroid会用一种保守的方式为其所有的子域均进行污点标记,即使用形如v.*的访问路径表示v以及v的所有子域均为污点标记.这里命名该处理方式为保守子域处理.保守子域处理方式虽然不会产生漏报,但是显然是会产生误报的.除了分析器不知道具体是哪个子域被标记的之外,还会存在分析器无法对子域进行正确更新的情况.如图9所示,行①的source正是产生了v.*的数据流值,是一种保守子域的处理.当v.*传播到行②时,由于不能确定是哪个子域被更新的(当前数据流值无法表示形如v.{*-f}),此时只能保守地不更新而继续传播v.*值.因此v.*到达行③时则会报告出泄露.而实际上行③的v.f1值已经在行②被设置成非敏感的数据,所以该报告是误报.
而这种误报是可以利用本文的方法进行消除的.具体分析:对于行②的左值v.f1,根据3.4节算法计算得到的使用点索引是(setUses[f1]=[L3]),而当数据流值v.*到达行②时,分析器执行4.2节算法3的行⑤分支,即使用规则[useStmt=∪getUseStmt(*)-getUseStmt(f)]来计算其使用点集合.此时,Hash表中f1域对应的使用点将会从总使用集合中删除.因此,此时使用点集合中只包含行④而不会包含行③,继而误报被消除.
另外,据实验观察,这种保守子域的处理方式存在的情况是比较多的,这是因为不但直接引入的变量会产生保守子域处理,如果访问路径的长度超过预先设置的值时,FlowDroid会将该访问路径进行裁剪(cut off),裁剪后的变量也是一种保守子域处理的方式.例如预先设置的访问路径阈值为3时,当生成的访问路径为v.f.g.h时,则会保守地转化成v.f.g.*的情况.如果程序中存在循环的情况(使得访问路径长度不断增加),这种裁剪而导致的保守子域处理的情况尤为突出,我们在实验评测部分统计验证了经过裁剪的数据流值占总数据流值所占比例是较大的(5.4节).
5 实现与实验
基于本文方法,我们在FlowDroid和Soot的基础上实现了原型系统FlowDroidSP,其中重用了FlowDroid创建ICFG、访问路径、提取结果部分以及计算污点的转移函数(4种IFDS转移函数).为了保证函数调用和函数返回的过程能够找到参数和返回值对应的使用点,这里在创建ADFG时,为函数参数和返回值增加了虚拟的定义值.最后,我们使用了100多个单元测试用例测试其健壮性.
为了验证本文方法的精确度,FlowDroidSP实现了2种模式:剪枝模式和非剪枝模式.剪枝模式(简称FlowDroidSP-P)正是利用了具有域敏感和流敏感的变量使用点索引进行剪枝的实现版本.如在4.5节所讨论,由于FlowDroid的保守子域处理,导致剪枝的模式会对FlowDroid的精度进行提升,然而这不利于验证其是否会损失精度.因此,我们实现了非剪枝的模式(简称FlowDroidSP-NP)专用于验证精确度.在非剪枝模式的实现中,我们将4.2节的算法3中所有分支都执行[useSet=∪getUseStmt(*);]规则,即使用其所有域的使用点,不进行剪枝处理.非剪枝算法理论上是和FlowDroid原算法精度完全一致的.
所有实验所使用的机器的配置是:64核Intel®Xeon®CPU E7-4809(2.0 GHz)和128 GB RAM,为每一个Java虚拟机分配32 GB的内存.同FlowDroid一样,设置访问路径的长度为5.这里所使用的测试集合同第2节中的16个应用程序.使用FlowDroidSP对每一个测试用例独立运行3次,提取结果并求平均值.
5.1 评测问题
本节我们将试图利用实验验证3个评测问题:
1) 相比FlowDroid,本文的方法是否会损失精度.
2) 预处理阶段和独立更新算法的开销是多少.
3) FlowDroidSP相比FlowDroid的性能提升效果是多少.
5.2 问题1:精确度验证
验证精确度需要使用非剪枝版本.这里的评价标准是产生的结果数目是相同的.表6是Flow-Droid和FlowDroidSP的对比运行结果.表中F-Res列为原FlowDroid产生的结果个数而NP-Res列为非剪枝模式FlowDroidSP产生的结果个数,可见非剪枝版本的FlowDroidSP与FlowDroid产生的结果个数是完全一致的,总共产生341个泄露结果.这进一步验证了本文的方法相比FlowDroid方法是没有精度损失的.
5.3 问题2:预处理和更新阶段开销
如表6所示,表中PRE-T列是FlowDroidSP非剪枝模式下的预处理过程的运行时间,其中标号16的程序最高为2.6 s,标号9的程序最低为0.2 s,平均为0.9 s.对于内存开销(PRE-Mem列),其中标号16开销最高为429 MB,标号9开销最低为11 MB,平均为126 MB.预处理的平均消耗时间占平均总分析时间的百分比小于1%,而内存消耗平均占比为4%.由此可见,预处理的时间和空间开销是很低的.时间上,相对于分析的平均时间91.1 s,这种开销几乎可以忽略不计.预处理开销低的原因是由于线性复杂度的ADFG构建算法和在此基础上的过程内的DEF-USE分析.同样,对于独立更新阶段的时间消耗(表6中SP-T列),最高时间消耗是4.1 s,最低是0.07 s,平均时间消耗是1.3 s.可见,虽然独立更新阶段算法不是线性复杂度的,但是由于我们首先使用了约束1进行过滤,导致需要独立更新的数据值已经很少了.为此,本实验单独的统计了独立更新的值(Active-SP)与需要激活但不满足约束1的值(Active)之间所占百分比的对比,结果如图11所示.可见,独立更新部分所占比例是较小的(平均4.2%).
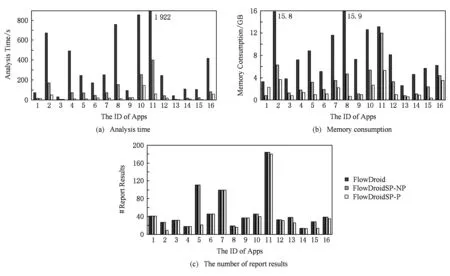
Fig. 10 Comparison on FlowDroid and FlowDoidSP beyond different mode图10 FlowDroid和FlowDroidSP不同模式下的结果对比
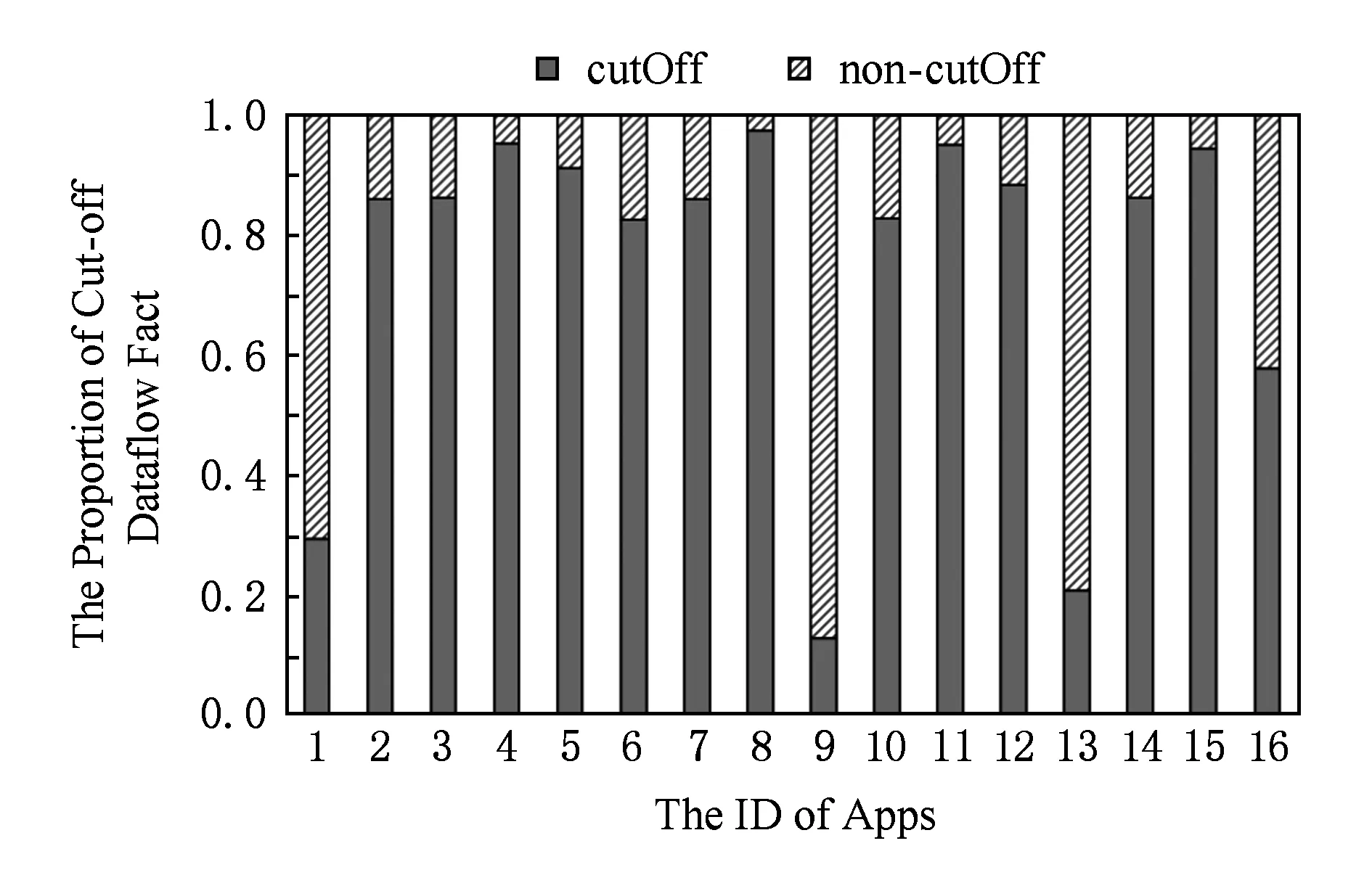
Fig. 11 Proportion diagram of independent updating 图11 独立更新计算值占可激活值的比例图
5.4 问题3:性能提升效果
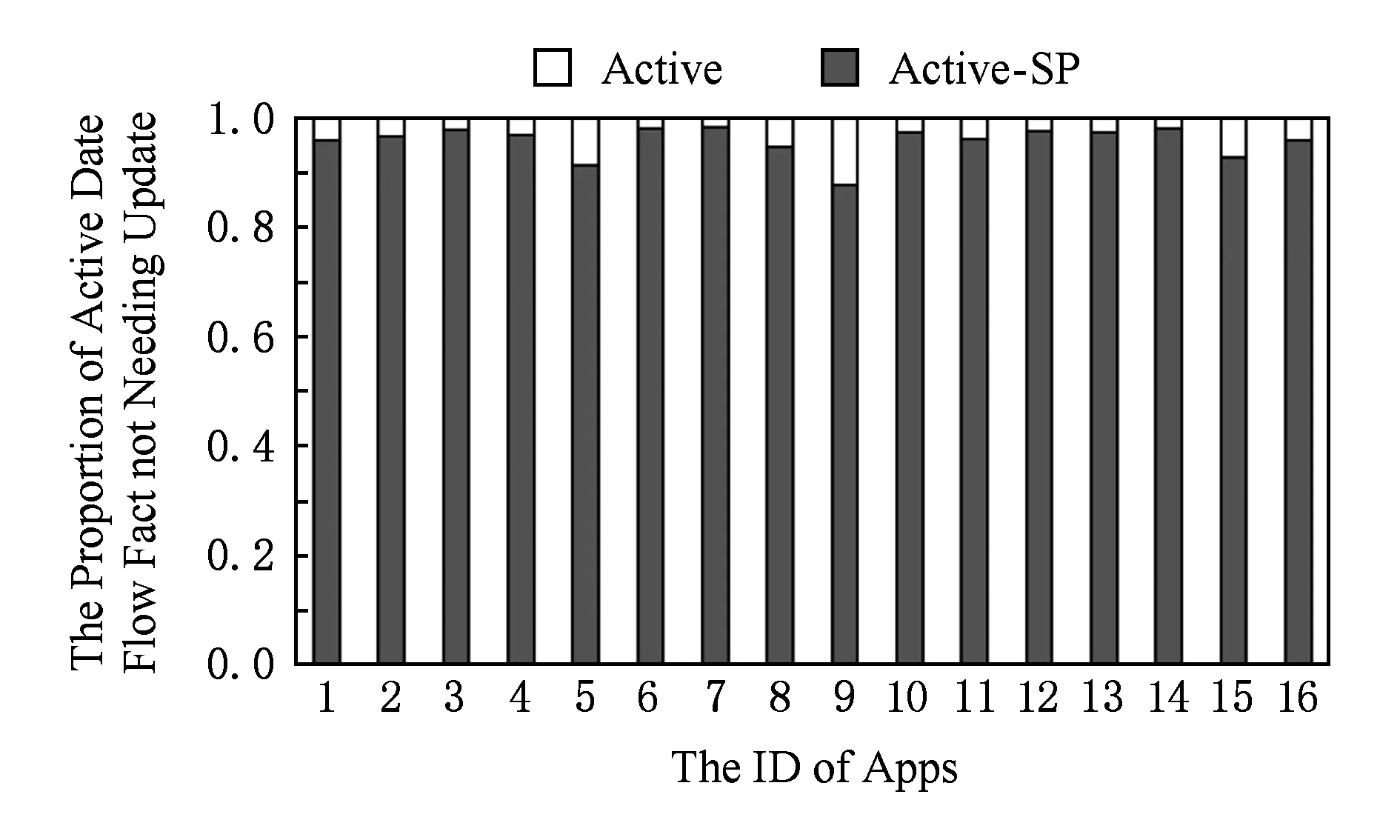
Fig. 12 Proportion diagram of cutting off date flow facts图12 具有裁剪标识的数据流占总数比例图
本节将对打开剪枝优化进行评测,如表6中列P-Time,P-Mem,P-Res为剪枝模式下FlowDroidSP的运行时间、内存消耗和产生泄露的结果数量.最终图10给出了3种评测模式(原FlowDroid,非剪枝模式,剪枝模式的FlowDroidSP)的在运行时间,内存消耗和产生结果数量的对比柱状图.在运行时间上,非剪枝版本平均加速比为4.8倍,在剪枝版本中,平均加速比为18.1倍.非剪枝版本的时间消耗加速比波动范围正常,最低3.3倍,最高8.6倍.而剪枝版本的加速比波动范围是非常大的,最低提升4.2倍,最高提升高达54倍,这是一方面由于剪枝方法本质决定,如果在程序传播初始阶段就能够有效地杀死不该传播的数据流值,会避免后续污点大量的扩散,另一方面我们猜测剪枝方法的加速比也和程序中保守子域的规模有关,保守子域处理的情况越多,可能剪枝的情况就会越多.为此,我们统计了具有被裁剪标识(当前访问路径被裁剪后会得到一个裁剪标识)的数据流的数量,如图12所示为该数目占当前所有数据流值的比例.对于编号1、编号9、编号13的例子,其所占比例为25%,12.9%,20.9%.所以剪枝优化对其提升比例不高(分别为4.8,4.2,13.9倍).而对于其他例子中该规模是相对较高,例如编号8的比例高达97.4%,所以剪枝算法对其优化的加速比可以高达54倍.对于内存消耗上,在非剪枝模式下,FlowDroidSP降低内存消耗平均为61.5%.在剪枝模式下,FlowDroidSP降低内存消耗平均为76.1%.另外对于产生泄露结果数目的影响,在剪枝模式下,FlowDroidSP是有一定精确度提升的,一共消减了154个误报结果,占总数的17.7%.
6 相关工作对比
数据流分析是静态程序分析的经典分析方法,IFDS框架[20]率先将流敏感和上下文敏感的分析问题转化成图可达问题进行求解,提高了分析的效率,该算法的最坏时间复杂度是O(ED3),其中E是当前控制流图中的边个数,D是数据流域的大小.文献[24]在2010年对IFDS进行了效率提升,它利用一种按需的方法对ICFG进行构建,为调用函数和被调用函数建立一个映射关系,当调用退出时只有存在于映射里面的调用者才会为其计算返回值.后来,该方法被实现到开源工具Heros[25]中,FlowDroid正是基于这个版本的IFDS进行实现的.FlowTwist[7]利用了祖先和邻居的数据结构将数据值之间的传播关系进行连接,以保证来自不同源的数据流值可以进行合并,增加了分析的扩展性.然而,当前没有工作探索对IFDS进行稀疏化的支持.同样,本文的方法本质是修改IFDS的传播函数,因此也适用于上述2个工作.
针对FlowDroid进行利用以检测安全问题的工作有很多[4].例如,达姆施塔特大学的安全软件工程实验室围绕了FlowDroid构建了一整套的安全检测生态系统[26],这包括使用Susi[27]来提供污点分析所使用的源和汇聚点;使用IccTA[28]提供敏感信息通过组件间进行泄露的检测方法;使用StubDroid[29]利用FlowDroid对库函数进行摘要提取;Harvester[30]利用FlowDroid提取关键路径信息,然后动态的验证这些信息是否是泄露等工作;静态污点分析的另一大挑战就是流敏感的别名分析,FlowDroid的流敏感的别名分析最初思想来源于Andromeda[31],其本质是基于CFL-图可达问题的变体;Sridharan等人[32]尝试将对Java的别名分析转化为CFL-图可达问题;随后又在文献[33]中提出了基于精简(refine-ment)的优化,然而,基于CFL的Java指针分析都是流不敏感的.为了解决流敏感问题,FlowDroid引入了激活点的方法;Boomerang[34]是最近提出的一个面向Java的按需的别名分析工具,它也是基于IFDS的,可以支持流敏感和上下文敏感.同样Boomerang也会面临类似的效率问题,我们认为本文的方法同样适用于Boomerang来提高其分析效率.
稀疏程序优化方法是目前指针分析领域的重点优化方案.Hardekopf和Lin[10]在2009年首次将流敏感的指针分析应用到百万行代码量的程序分析中,提出了半稀疏的流敏感指针分析方法,该方法利用部分SSA(partial SSA)使得本地变量的分析转移到该表示中,构建了SEG(sparse evaluation graph)进行具体指针分析;随后Hardekopf[11]又利用了流不敏感的分析做为预处理将其扩展成全稀疏的形式;Lhotak和Chung[13]的SUPT同样利用全稀疏的SSA表示并提供了强更新(strong update)的支持;Li等人[14]将图可达的思想引入到值流图(value flow graph)中进行按需的流敏感的指针分析优化.然而,上述的工作都是针对于C/C++语言进行开展的且这些分析往往需要一定的预处理(SSA或者流不敏感的分析支持).
污点分析技术是一类重要的程序分析技术,如今大量的研究工作应用其解决计算机系统信息的保密性和完整性问题:Mino[35]在硬件级别上扩展了寄存器的标志位来实现污点分析用来进行一些基础漏洞挖掘,如缓冲区溢出;TAJ[36]工具利用了混合切片的静态分析技术提供Java Web安全漏洞的检测;TaintDroid[37]是当前最流行的动态Android应用隐私泄露检测工具,它使用的多层次的插桩来完成污点传播.然而,TaintDroid必须在运行时对APK文件进行检测,这依赖于APK输入测试集合来触发敏感数据流,且TaintDroid会对Android系统本身带来一定开销,每次Android版本更新之后,Taint-Droid都需要重新进行定制.CHEX[38]尝试使用静态的污点分析方法检测智能手机组件劫持漏洞;DroidSafe[39]结合Android Open Source Project实现了与原Android接口语义等价的分析模型,并使用精确分析存根(accurate analysis stub)将AOSP代码之外的函数加入到模型,在此基础上进行污点分析.
7 总结与未来工作
本文针对检测移动应用隐私泄露问题的污点分析技术进行性能提升.基于稀疏优化的思想,本文将传统数据流分析框架扩展成稀疏的形式,即将数据流值直接传播到其使用点,避免其在定义点和使用点之间的无关联传播.我们提出了一种特殊的数据结构-变量使用点索引来存储流敏感和域敏感的DEF-USE关系,并提供快速的构建算法.以此结构为输入,提供了对应的污点分析技术.另外,本文还发现基于流敏感和域敏感的DEF-USE关系可以对污点分析中保守子域处理的情况进行有效的剪枝,可以同时提升其效率和精度.
最后本文实现了工具FlowDroidSP并进行评测.实验表明,FlowDroidSP在提升性能的同时没有带来精度上的损失.在非剪枝模式下,可以带来时间加速比4.8倍,内存消耗降低61.5%,在剪枝模式下,可以带来时间加速比18.1倍,内存消耗降低76.1%,并且消减了17.7%的误报结果.
由于IFDS框架分配率的限制,当前污点分析还不能支持别名之间的强更新,后续我们将探索如何利用预处理信息提供别名间的强更新.此外,根据5.4节的实验结果不难得出的结论是当前保守子域问题也是限制污点分析扩展性的瓶颈,尽管稀疏框架可以对其进行优化剪枝,但仍然不能完全消除其误报,未来对保守子域的精确计算也是一个值得研究的方向.
猜你喜欢
保健医苑(2022年5期)2022-06-10
网络安全与数据管理(2022年2期)2022-05-23
成都信息工程大学学报(2021年6期)2021-02-12
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
计算机应用(2020年5期)2020-06-07
计算机技术与发展(2020年5期)2020-05-22
散文诗世界(2019年10期)2019-09-10
思维与智慧·下半月(2019年4期)2019-05-04
计算机技术与发展(2018年1期)2018-01-23
