
大规模RDF图数据上高效率分布式查询处理∗
2019-04-18 05:06柴乐乐杨雅君柴云鹏
软件学报 2019年3期
王 鑫,徐 强,柴乐乐,杨雅君,4,柴云鹏
1(天津大学 智能与计算学部,天津 300354)
2(天津市认知计算与应用重点实验室,天津 300354)
3(中国人民大学 信息学院,北京 100872)
4(数字出版技术国家重点实验室,北京 100871)
智能数据管理是人工智能发展的重要基石.知识图谱是智能数据的主要表现形式.资源描述框架(resource description framework,简称RDF)是由国际万维网联盟(W3C)制定的表示知识图谱的推荐标准.随着知识图谱相关技术的不断发展,RDF三元组数据日益激增,并且被广泛地应用在多个领域,包括科学、生物信息、商业智能和社交网络等[1].在现实世界中,RDF数据集往往达到数亿条三元组数据.目前,如何有效管理大规模 RDF智能图数据受到越来越多的关注.与传统的关系型数据库中进行的查询不同,RDF数据上 SPARQL的基本图模式(BGP)操作语义等价于数学上的子图同态[2],这是一个著名的NP完全问题[3],即SPARQL查询可以转化为子图匹配问题.因此,提高SPARQL查询性能已成为亟待解决的技术问题.
RDF数据模型是一种特殊的语义图数据模型,表示为实体-关系或者类关系图,基本构件包括实体、属性和值,通过属性和值描述资源之间的关系.每条RDF三元组数据的格式为(s,p,o),是一个陈述,其中,s是主语,p是谓语,o是宾语.(s,p,o)表示资源s与资源o之间具有联系p,或表示资源s具有属性p且其取值为o.RDF数据的主语和谓语都是以统一资源标识符(uniform resource identifier,简称URI)来标识,宾语以URI或者字面值(literal)标识.一条三元组数据可以被看做一条有向边,其中,主语和宾语为顶点.一个三元组的宾语可作为另一个三元组中的主语,于是,RDF数据形成一种有向标签图.
RDF智能图数据上的查询语言随着RDF数据的发展不断发展,早期查询语言包括RQL,RDQL,SquishQLD等[4].目前被广泛使用的是SPARQL(simple protocol and RDF query language),该查询语言是W3C提出的RDF图上的标准查询语言.基本图模式(basic graph pattern,简称BGP)是SPARQL中最常用、最基本的查询模式.实际上,每个SPARQL查询的核心部分是一个BGP查询.例如:在维基百科数据集DBpedia中查询内陆国家及其人口数,SPARQL BGP查询如图1所示.

Fig.1 An example SPARQL BGP queryQ图1 示例SPARQL BGP查询Q
目前,处理大规模RDF智能图数据查询的研究工作分为两大类——单机和分布式.单机SPARQL查询引擎,如RDF-3X[5]和gStore[6],采用基于空间换时间策略构建不同的索引方案,利用索引减少查询匹配的搜索空间;分布式SPARQL查询处理系统以是否采用分解查询图策略分为两类:一类方法将SPARQL查询图分解为三元组模式(triple pattern,至少包含一个变量的三元组)[7-11]或者带有局部结构信息子图的集合,先对分解后的查询子图进行匹配,之后对子图的匹配结果进行连接操作获得最终匹配结果;另一类方法直接处理完整查询图[12-14],大部分通过图探索减少连接操作的较高代价,通过优化探索计划提高查询性能.
本文将RDF图内嵌的语义和结构作为启发式信息(h-值),并利用h-值将RDF查询图分解为星形结构(高度为1的树)的集合进行匹配.Lai等人[15]指出:无向无标签图上基于星形-连接的算法[16]在评估包含多边的星形时会生成大量中间匹配结果,如:将包含3条边的星形结构匹配到最大度为1 000的数据图,产生109个匹配结果.为此,他们提出了基于MapReduce[17]的TwinTwigJoin算法,将查询图分解成TwinTwig结构,该结构只包含一条边或两条相连的边.造成上述问题的根本原因是:顶点和边缺乏可区别信息时,星型结构匹配过程可能会产生大量的中间结果.但是RDF图中的顶点标签是独一无二的URIs,同时,边是有方向且带标签的,因此,Lai等人在文献[15]中提出的问题在RDF图中不存在.与分解成TwinTwig结构[15]相比,星形分解策略可以保持更多原始查询图的信息,同时,在MapReduce计算模型下可以在更少次MapReduce迭代操作内结束查询.
本文的主要贡献如下:
(1) 提出了基于MapReduce计算模型的有效SPARQL基本图模式匹配算法,利用RDF智能图数据丰富的语义和自身的图特性设计星形分解策略,并给出中间结果较少的星形匹配顺序来提高查询效率,每轮MapReduce操作按序连接一个星形结构直至匹配结束;
(2) 为进一步提高算法的性能,引入两种优化技术:一个通过基于布隆过滤器的邻居信息编码技术过滤MapReduce操作中的无用数据输入,另一个技术推迟笛卡尔积操作以提高查询效率;
(3) 在主流大数据处理框架 Spark下实现了上述算法,并在标准合成数据集 WatDiv[18]和真实数据集DBpedia上进行了大量实验,验证了算法的有效性、高效性和可伸缩性,并对查询匹配的时间开销与数据集规模及集群中节点数量的关系进行分析.
本文第1节介绍相关工作.第2节介绍RDF图和SPARQL基本图模式查询的预备知识.第3节描述如何存储RDF数据,分解SPARQL查询,并在分布式计算框架MapReduce下匹配查询.第4节提出两种优化技术:一个通过基于布隆过滤器的邻居信息编码过滤掉 MapReduce迭代中无用的数据输入;另一优化技术将星形匹配过程中的笛卡尔积推迟到MapReduce迭代结束来减少该过程中大量无用的笛卡尔积.第5节在标准合成数据集和真实数据集上进行实验,并在第6节对全文总结.
1 相关工作
近年来,研究者逐步意识到图数据管理的重要性,高效处理RDF数据已成为该方向的研究热点之一.本节将对目前已有的大规模RDF数据上SPARQL查询研究工作进行介绍,主要分为以下两类.
1.1 单机系统上的RDF图查询处理
RDF-3X查询引擎[5]采用原生态的三元组存储模式,将RDF数据和按照SPO排列的15种SPO(包含SPO中1,2或3个)索引压缩存储在B+-树中,以冗余存储提高查询性能.该方法通过自底向上的动态规划算法选择出代价最优的连接顺序.另外,RDF-3X收集单个实体的统计信息,大量使用合并连接来换取较高查询效率.gStore[6]是基于图的单机 SPARQL查询引擎,使用邻接链表存储 RDF图,并将顶点类和实体用固定长度的比特串编码压缩存储,通过建立VS*-树索引结构提高查询处理效率并采用剪枝策略减少搜索空间.
随着Tim Berners-Lee发起的Linked Data运动的持续推进,各个领域发布的RDF数据一直持续增长,数据规模达到百亿级.单机已经无法有效处理现有规模 RDF数据上的 SPARQL查询[19],分布式/并行技术已成为RDF数据管理不可或缺的工具.
1.2 分布式系统上的RDF图查询处理
近年来,大量研究者和实践者提出了若干种方法分布式处理大规模RDF图上的SPARQL查询问题,分两类叙述.
(1) 分解查询图.
SHARD[7]基于三元组存储处理RDF数据集上的SPARQL查询,查询图被分解为三元组模式(包含变量的三元组,即一个查询子句)的集合,通过在三元组模式上迭代将变量绑定到数据图的顶点,该绑定必须同时满足查询中的所有约束.每一轮 MapRedue操作通过连接操作只添加一个查询子句.类似地,HadoopRDF[8]中查询图的最小分解单位也是三元组模式,并且它也使用MapReduce计算框架将RDF三元组基于谓语划分到多个小文件中.SPARQL查询中的一个子句,也就是一个三元组模式,只能同时参与到一个 Hadoop作业中.这两种方法都没有使用查询图的结构信息,需要过多的MapReduce迭代操作,并且大量的连接操作导致很高的查询代价.而本文利用部分图的结构特性,在每次MapReduce迭代中添加一个星形,可以在更少的迭代次数内完成查询匹配,从而提高查询效率.同样地,S2X[9]虽然建立在分布式图计算框架GraphX[20]上实现SPARQL的BGP匹配,查询图也被分解成查询子句,也就是三元组模式.首先,BGP查询中所有的三元组模式被匹配;其次,通过迭代计算逐渐舍弃部分中间结果;最后,将剩余的匹配结果进行连接操作,这一阶段可能会导致大量的中间结果.另外,Virtuoso[10]和S2RDF[11]基于关系数据库处理RDF图查询,将SPARQL查询子句转化为SQL语句,通过关系表的连接操作得到匹配结果.S2RDF[11]引入关系划分模型ExtVP存储RDF数据,该方法基于Spark[21]并行计算框架,可以有效最小化查询输入大小.但是ExtVP存储方案的预处理需要提前在垂直划分表上作大量的连接操作,代价非常高.本文将RDF图分布式存储在多个邻接链表中,可以同时在各个主语顶点的邻接链表上并行进行MapReduce计算,加快查询处理.
(2) 完整查询图.
Trinity.RDF[12]将RDF数据模型化为原始图的形式,并使用键-值存储RDF数据,将顶点标识符作为键,顶点的邻接链表作为值.采用基于代价的方法找到最优探索计划,利用图探索而不是连接操作减少中间结果量,但是最终结果需要在集群中心节点上使用单线程获得.此外,Peng等人[13]采用局部计算和装配的分布式框架基于gStore执行SPARQL查询.在局部计算阶段,集群中每个节点匹配完整查询,然后在装配阶段,大量的本地局部匹配结果被发送到中心节点进行连接操作获得最终的结果.当匹配过程的中间结果规模较大时,这两种方法在最后阶段可能是一个性能瓶颈,而本文可以通过 Reduce函数并行连接星形匹配结果得到答案集.TriAD[14]使用MPI协议处理SPARQL查询,建立6个SPO索引,并将RDF三元组划分到这些索引中,同时,使用基于本地的概括图加速查询.同样,采用自底向上的动态规划算法确定最小代价估计的三元组模式匹配顺序.但是与本文方法相比,TriAD中大量的索引导致数据冗余,空间消耗大,如果数据变动需更新大量索引.
不同于以上方法,本文将SPARQL BGP查询图分解为星形的集合,利用RDF数据丰富语义和图的结构确定中间结果较少的星形匹配顺序.在MapReduce并行计算中,Map函数在分布式邻接链表上并行匹配星形,Reduce函数并行连接星形与已经生成的查询子图的匹配结果,加快查询速度.
2 预备知识
本节将详细介绍相关背景知识,包括RDF图、SPARQL BGP查询图、BGP匹配及星形分解等定义,为理解本文后续算法奠定基础.
2.1 RDF图及SPARQL查询
定义1(RDF图).设U和L分别是统一资源标识符和字面值的有限集合,元组(s,p,o)∈U×U×(U∪L)叫做RDF三元组,每个三元组t=(s,p,o)表示资源s和资源o有关系p,或者资源s有值为o的属性p,其中,s,p和o分别表示主语、谓语和宾语.一个有限三元组的集合被称为RDF图.用V,E,Σ分别表示RDF图G的顶点、边和边标签的集合,正式定义为:V={s|(s,p,o)∈G}∪{o|(s,p,o)∈G},E⊆V×V,并且Σ={p|(s,p,o)∈G}.函数lab:E→Σ返回图G中边的标签.
本文定义的RDF图不考虑RDF标准定义中的空节点(blank node),实际上,本文所研究的问题与空节点的包含是正交的,在RDF图定义中省略空节点是为了使表述更简洁.图2是从DBpedia数据集中摘取的RDF图示例G,为节省空间,对URI进行了压缩表示.RDF数据中的每条三元组可以被看做是RDF图中一条有向带标签的边.
定义2(查询图).用Var表示与U和L不相交的变量的无限集合,Var中每个元素的名字按照惯例以字符“?”开始(如?x∈Var).RDF图G上的 SPARQL基本图模式(basic graph pattern,简称 BGP)查询Q被定义为如下形式:Q={(si,pi,oi)|(si,pi,oi)∈(U∪Var)×(U∪Var)×(U∪L∪Var)},其中,tpi=(si,pi,oi)是三元组模式.SPARQL BGP 查询Q也被称为查询图GQ.
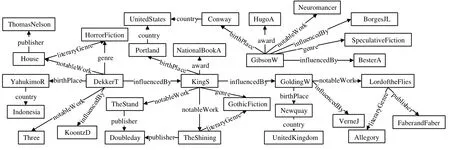
Fig.2 An example RDF graphG图2 RDF示例图G
用V(Q),E(Q)分别表示查询图GQ中顶点和边的集合,对每一个顶点u∈V(Q),如果u∈Var,那么u可以匹配RDF图G中的任意顶点v∈V;否则,u只可以匹配与它标签相同的顶点v∈V.
定义3(SPARQL BGP匹配).RDF图G上的SPARQL BGP查询Q的语义定义为:
(1)μ是从V(Q)中的顶点到V中顶点的映射;
(2) (G,μ)Q当且仅当对任意(si,pi,oi)∈Q满足:i)si和oi可以分别匹配μ(si)和μ(oi);ii) (μ(si),μ(oi))∈E;
iii)pi∈Var或lab((μ(si),μ(oi)))与pi相同;
(3)Ω(Q)是使(G,μ)Q满足的μ的集合,也就是RDF图G上SPARQL BGP查询GQ的答案集.
定义4(星形).星形是一棵高度为1的树,表示为T=(r,L),其中:(1)r是T的根节点;(2)L是二元组(pi,li)的集合,也就是说,li是树T的叶子,(r,pi,li)是从r到li的边.用V(T)和E(T)分别表示星形T中顶点和边的集合.
定义5(星形分解).SPARQL BGP查询Q={tp1,…,tpn}的星形分解定义为D={T1,…,Tm},其中,(1)Ti是一个星形;(2).
根据定义4可知:本文定义的星形结构中,边的方向都是从根节点指向叶子节点.用Sub(Q)表示查询Q中主语的集合,那么Sub(Q)就是查询Q的星形分解D中星形根节点的集合.如图3所示,给出SPARQL BGP示例查询图Q1及其星形分解D1,包含3个星形T1,T2,和T3.

Fig.3 An example SPARQL BGP query graphQ1and the corresponding star decompositionD1图3 SPARQL BGP示例查询图Q1及其星形分解D1
2.2 MapReduce并行计算模型
MapReduce是谷歌提出的用来处理和生成大数据集的并行编程模型,可以运行在由很多普通机器组成的集群上[18].MapReduce的用户通过自己编写Map和Reduce两个函数来表达并行计算.MapReduce计算模型具体定义如下.
定义6(MapReduce计算模型).MapReduce计算模型中包括若干轮Map和Reduce任务,每轮MapReduce任务包括一个 Map函数和一个 Reduce函数,其中,Map函数定义为 Map:(k1,v1)→[(k2,v2)],Reduce函数定义为Reduce:(k2,[v2])→[(k3,v3)],其中,[(ki,vi)]表示key/value对的列表.在Map和Reduce之间是一个shuffle过程,该过程中,相同key的全部value值被发送给同一Reduce函数.
在MapReduce计算中,Map函数输入一个key/value对(k1,v1),输出新的key/value对集合[(k2,v2)]作为中间结果,并将此输出发送给Reduce函数,Reduce函数以接收到的一个中间值key和对应于该key的value集合,也就是(k2,[v2])作为输入,通过归并这些value,生成新的key/value集合[(k3,v3)]并输出.
3 BGP查询匹配算法
本节详细介绍本文的 SPARQL BGP查询匹配方法,具体分为3部分:首先,采用分布式邻接链表存储RDF图;其次,将给定的SPARQL BGP查询分解为星形的集合并确定这些星形的匹配顺序;最后介绍基于MapReduce模型的分布式算法.
3.1 存储模式
本文采用分布式邻接链表模式存储RDF图,对RDF图中的顶点v∈V,用N(v)表示顶点v的邻居信息,N(v)={(pi,vi)|(v,pi,vi)∈G}.RDF示例图G的邻接链表存储方案见表1.RDF三元组中,URIs或者字面值通常是很长字符串,如果直接存储大规模的原始数据而不做其他改变,会浪费大量的存储空间.本文采用编码映射方法,用唯一的ID(整数)代替RDF图中顶点和边的标签,也就是URIs或者字面值.通过该方法可以压缩RDF数据集的存储空间,同时,用整数代替长的字符串可以简化并加速后期的SPARQL查询处理.

Table 1 Adjacency list storage schema表1 邻接链表存储模式
3.2 基于贪心策略的星形分解
这里介绍基于RDF图的结构信息和RDF内含语义的星形分解算法,该算法利用本文自定义的启发式信息h-值对SPARQL BGP查询图Q进行分解,并找到中间结果较少的星形匹配顺序,从而提高SPARQL BGP的查询性能.
在本文中,星形是最小的匹配单位,在RDF图的邻接链表N(v)上匹配星形T时,如果星形T的根节点可以匹配邻接链表N(v)的主语顶点v,对于星形T的所有叶子节点li得到它们在邻接链表N(v)上可以匹配的顶点的集合,本文将此集合定义为叶子节点li的候选集S(li).接下来具体介绍星形在RDF邻接链表上的匹配过程,其匹配算法的伪代码见算法1.
算法1.星形匹配算法.
输入:星形T=(r,L),其中,L={(p1,l1),…,(pt,lt)},v∈V,邻接链表N(v);
输出:星形T在N(v)上的匹配结果:Ωv(T)={μ1,μ2,…,μn}.

在邻接链表N(v)上匹配星形T的过程包括:(1) 第2行匹配星形的根节点T.r和RDF图中的顶点v;(2) 第3行到第7行获得星形T的每个叶子节点li可以匹配的RDF图中顶点的候选集合S(li);(3) 第8行在星形T所有叶子节点的候选集合S(li)上做笛卡尔积操作,得到星形T在邻接链表N(v)上的匹配结果Ωv(T);(4) 第9行返回星形T在邻接链表N(v)上的匹配结果Ωv(T).因此,星形T在RDF图G中的匹配结果Ω(T)为Ωv(T)的并集,其中,v∈V.
例 1:根据算法 1,星形T1在 RDF示例图G上有 6个匹配结果,包括{?w1→DekkerT,?x→KoontzD},{?w1→KingS,?x→GoldingW},{?w1→GibsonW,?x→SpeculativeFiction},{?w1→GibsonW,?x→BorgesJL},{?w1→GoldingW,?x→VerneJ}和{?w1→DekkerT,?x→KingS}.星形T2在 RDF示例图G上有 4个匹配结果,包括{?x→KingS,?y→TheShining,?g→GothicFiction,?w2→GoldingW,?c→Portland,?a→NationalBookA},{?x→KingS,?y→TheStand,?g→GothicFiction,?w2→GoldingW,?c→Portland,?a→NationalBookA}等,T3有{?y→House,?p→ThomasNelson,?g→HorrorFiction},{?y→TheShining,?p→Doubleday,?g→GothicFiction},{?y→LordoftheFiles,?p→FaberandFaber,?g→Allegory}这3个匹配结果.
考虑匹配顺序T1T3T2,因为星形T1和T3没有共享的顶点,所以对星形T1和T3的匹配结果进行连接操作时生成 6×3=18个中间结果;另一匹配顺序T2T3T1只生成 1个中间结果{?x→KingS,?y→TheShining,?g→GothicFiction,?w2→GoldingW,?c→Portland,?a→NationalBookA,?p→Doubleday,?g→GothicFiction}.基于星形分解进行SPARQL BGP查询匹配时,不同的星形匹配顺序产生的中间结果有明显差异.
对RDF图G上的查询Q,用Pred(u)表示顶点u的属性(也就是谓语)集合,Pred(u)={pi|(u,pi,ui)∈Q}.函数freq:Σ→ℕ返回谓语p在RDF图G中的频率,其中freq(p)=|{(si,p,oi)|(si,p,oi)∈G}|,ℕ表示自然数的集合.本文的启发式信息h-值由两个因子决定:(1) 在查询图中顶点的出度越大,该顶点的邻居节点中变量个数可能越多,那么以该顶点为根的星形被匹配时会绑定更多的变量;(2) 查询图中,顶点的出边标签在RDF数据图中越稀有,该顶点的选择度越高,也就是当匹配以该点为根节点的星形时会产生相对少的匹配结果.如果顶点u的所有属性都是变量,则h(u)=0;否则,查询图中顶点u的h-值的具体定义如下:

由例 1可知,对相同的星形分解结果,不同的星形匹配顺序在查询执行过程中产生的中间结果数目明显不同,基于此查询性能有非常显著的差异.因此,本文以基于 RDF图的结构信息和丰富语义的h-值作为启发信息,通过贪心策略对 BGP查询图进行分解,并得到中间结果较少的星形匹配顺序.该分解策略的算法伪代码见算法2.
算法2.星形分解算法.
输入:SPARQL BGP查询Q:{tp1,…,tpn};
输出:星形分解队列D:{T1,…,Tm}.


算法2根据h-值将RDF查询图分解为星形的集合并给出匹配顺序,具体过程如下:第3行、第4行将Qc中h-值最大的常量顶点作为第1个星形的根节点,这样只在与该查询图中常量顶点匹配的数据顶点的邻接链表上进行匹配,可以很大程度减少中间结果.如果查询图中的主语都是变量,第5行、第6行将Sub(Q)中h-值最大的顶点作为第1个星形的根节点.然后,第7行调用genStar(r,Q,D)函数生成以r为根节点的星形T,并加入星形分解队列D中(第14行、第15行),第16行删除查询Q中已加入到D中的三元组模式.第8行~第11行迭代生成新的星形,直至Q中的三元组模式(也就是查询图中的边)被分解完,其中,第9行得到新生成星形根节点的候选顶点的集合Mv,这些候选的根节点与已经生成的星形分解队列D中至少分享一个相同的顶点.第10行、第11行在候选集中选择h-值最大的顶点作为根节点并生成新的星形.
例 2:考虑上文提及的示例查询Q1,h(?w1)=1/6,h(?x)=5/2,h(?y)=2/3.根据算法 2,第 1个选择的根节点是顶点?x,生成星形T1′,也就是图2 中的星形T2.然后,根据h-值按序生成星形T2′,T3′,即图2 中的星形T3,T1.
3.3 基于MapReduce的SPARQL BGP匹配算法
上节算法2将给定的BGP查询图分解为星形的集合,同时给定这些星形的匹配顺序,该匹配顺序利用启发式信息h-值生成,使得以此顺序匹配这些星形时可以产生较少的中间结果,提高查询性能.本节将详细介绍如何按算法2产生的星形匹配顺序在左深连接(left-deep join)框架下基于MapReduce模型回答SPARQL BGP查询.
定义7(局部查询图).给定 BGP查询图GQ,算法 2生成星形分解D并给出星形的匹配顺序T1…Tm,满足.局部查询图Pj,1≤j≤m是查询图GQ的子图,满足:(1);(2).
由定义7可知,P1=T1,Pm=GQ.用Ω(Ti)和Ω(Pi)分别表示星形Ti和局部查询图Pi的匹配结果.将局部查询图Pt-1与星形Tt顶点交集的匹配结果作为连接的键μkey:V(Pt-1)∩V(Tt)→V,连接Ω(Pt-1)与Ω(Tt)可得到Ω(Pt).每次MapReduce迭代操作新匹配一个星形,并且从第 2次迭代开始,将已经匹配的局部查询图的结果与新匹配的星形结果进行连接操作.图4为处理SPARQL BGP查询方法的MapReduce总体框架图.并行SPARQL BGP查询匹配算法SDec通过多次MapReduce迭代计算得到查询结果,具体算法伪代码见算法3.
算法3.SDec算法.
输入:RDF图G=(V,E,Σ),星形分解队列D:{T1,…,Tm};
输出:答案集:Ω(Q).
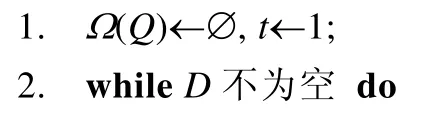

Fig.4 MapReduce framework of our SPARQL BGP matching algorithm图4 SPARQL BGP匹配算法的MapReduce框架图
算法3第2行~第7行通过MapReduce操作,按算法2给定的顺序匹配星形,每轮MapReduce迭代连接局部子图和星形的匹配结果,直到所有星形被匹配.Map函数由两部分组成:(1) Map函数输入值为N(v)时,算法3在RDF图的邻居信息N(v)上并行匹配星形Tt,并且将匹配结果μ以(μkey,μ)对输出(第11行~第19行);(2) 输入值为Ω(Pt-1)中的匹配结果μ时,输出(μkey,μ)对(第 20行~第 22行).第 23行~第 25行,Reduce函数以映射μkey为键,连接局部查询图Pt-1和星形Tt的匹配结果,生成Pt的匹配结果.
定理1.给定RDF图G和查询图GQ,假定算法2分解GQ为星形队列D={T1,…,Tm}.算法3给出正确查询结果并且MapReduce迭代次数为m.
证明:算法3在第1轮MapReduce迭代的Map函数中调用算法 1匹配星形T1,得到答案集Ωv(T1),也就是Ω(P1);从第2轮开始,算法3按照算法2给定的匹配顺序,在每轮MapReduce迭代的Map函数中匹配一个新的星形Tt并得到查询结果Ω(Tt),在Reduce函数中,将上轮得到的局部查询图Pt-1的匹配结果Ω(Pt-1)与星形Tt匹配结果Ω(Tt)进行连接得到Ω(Pt),从而在第m轮MapReduce中得到Ω(Pm),也就是查询Q的答案集.证毕. □
定理2.算法3的时间复杂度为,其中,m为星形个数,|V|为 RDF图的顶点大小,|Nmax|和|Lmax|分别是RDF图G和查询图GQ中最大的出度.
证明:算法3在第m轮MapReduce迭代计算后得到查询Q的答案集,其时间复杂度由两部分组成:(1) 星形匹配的时间复杂度为;(2) 连接操作的时间复杂度为.最坏情况下,星形Tt的每个叶子可以匹配顶点v∈V的所有邻居顶点,也就是.因此,算法 3 的时间复杂度为.证毕.□
4 优化技术
本节提出两个优化技术,提高基本算法的查询效率.虽然不能降低算法的复杂度,但是经过实验验证,可以明显提高查询效率.其中,一个技术通过布隆过滤器编码顶点的邻居信息减少数据输入,另一技术通过推迟笛卡尔积提高查询性能.
4.1 基于布隆过滤器的邻居信息编码
布隆过滤器(Bloom filter)利用位数组简洁地表示一个集合,并且可以快速检索一个元素是否在这个集合中,是一种空间效率很高的随机数据结构.布隆过滤器有可能会出现错误判断,但不会漏掉判断.它的核心思想是,利用多个不同的哈希函数来解决冲突.
布隆过滤器BF初始时是一个包含m位的位数组,每一位都置为0,即,BF整个数组的元素都设置为0.随后,每添加一个元素x,BF使用k个相互独立的哈希函数,分别将集合中的每个元素映射到{1,…,m}的范围中,将数组中对应的比特位置为1.最后,判断y是否属于BF时,只需要对y使用k个哈希函数得到k个哈希值:如果所有hashi(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,那么y是集合中的元素;否则,就认为y不是集合中的元素.
在布隆过滤器中,根据输入元素个数n和BF数组位数m,可得到使误判(flase positive)率f最小的哈希函数的个数k:k=ln2m/n.此外,哈希函数个数k与误判率f满足等式k=-log2f.由该等式可知:k越大,误判率f小.本文借鉴布隆过滤器中的参数设置对RDF图中主语的邻居边及顶点进行编码时,但是不再判断一个元素是否在BF集合中,而是判断一个布隆过滤器集合是否是另一个布隆过滤器集合的子集.形式化定义为:如果BF1&&BF2=BF1,那么布隆过滤器BF1是BF2的子集;否则,就认为不是.即:判断布隆过滤器BF1是否是布隆过滤器BF2的子集时,如果所有BF1为1的位置,BF2对应的位置都被设置为1了,那么布隆过滤器BF1是BF2的子集;否则就认为不是.
对 RDF数据图中的每个主语s的邻居信息基于布隆过滤器进行编码,并将此编码作为它的签名,表示为Sig(s).把主语s的每条出边e=(s,o)∈V×V用k个哈希函数映射成长度为M+N的位数组ecd(e).前M位表示边标签的编码,用k个哈希函数hi(i=1,…,k)将M位中的k位置为“1”.本文选取经典的字符串哈希函数,如BKDRHash,APHash,DJBHash等.对第i个哈希函数hi,设置前M位中的第hi(lab(e)) modM位为“1”,其中,hi(lab(e))表示边标签lab(e)的哈希值.后N位表示顶点的编码,其方式与上述类似,将后N位中的k位采用不同的哈希函数置为“1”.将主语s所有出边的位数组ecd(e)按位或操作后得到它的签名Sig(s)=ecd(e1)|…|ecd(et),其中,ei为主语s的出边.
如图5所示,对RDF图G的顶点GoldingW及图3中的星形T3进行邻居信息编码.首先对顶点GoldingW的出边(GoldingW,LordoftheFlies)进行编码,将边标签notableWork映射成长度为8的位数组,具体操作如下:首先求哈希值APHash(notableWork)和DJBHash(notableWork),并对这两个哈希值mod 8得到余数2和7;然后将位数组从左到右的第 2位和第 7位置为 1(从第 0位开始),其余位置为 0,如图5所示;类似地,将相邻顶点LordoftheFlies映射到长度为12的位数组,取APHash和DJBHash函数的值并mod 12得到余数进行编码,将边标签的位数组和顶点的位数组连接得到边(GoldingW,LordoftheFlies)的编码ecd((GoldingW,LordoftheFlies));最后,将不同出边的编码按位或操作得到GoldingW顶点的签名Sig(GoldingW).值得注意的是:没有出边的顶点,其签名的所有位默认为0.同样地,对星形T3进行邻居信息编码,边标签literaryGenre的两个哈希值mod 8得到余数3和5后编码位数组,如图5所示.因星形中的顶点?g为变量,所以它的位数组12位都置为0,将这两个位数组连接后得到编码ecd((literaryGenre,?g)),计算其他边的编码进行或操作后,得到星形T3的邻居信息编码Sig(T3).
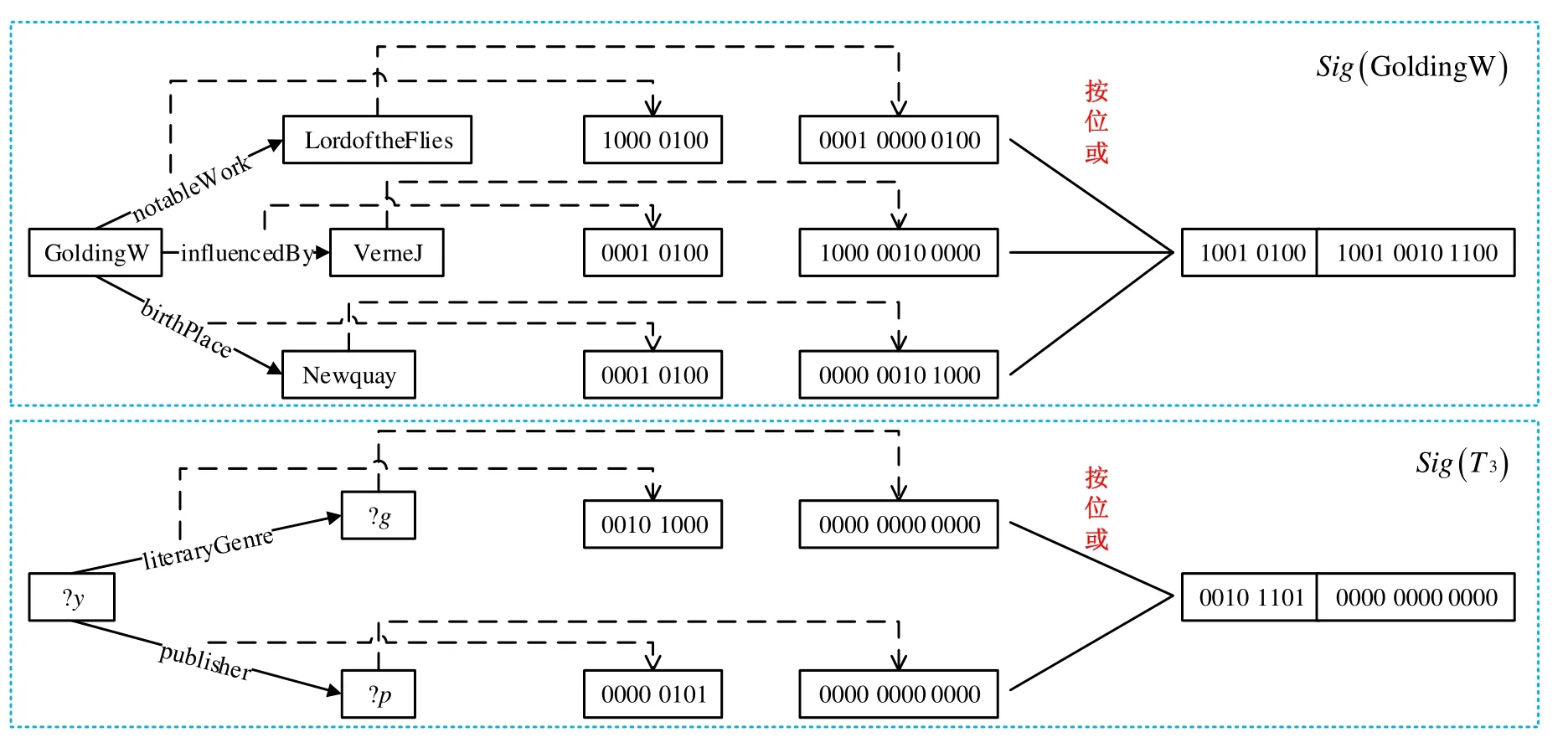
Fig.5 Procedure of the signature generation of vertex labeledGoldingWand starT3图5 主语GoldingW和星形T3签名的生成过程
本文第3节将SPARQL BGP查询图分解为星形结构的集合,对星形T采用相同的方式进行编码,每个星形结构也生成一个长度固定的位数组做为签名,表示为Sig(T).当星形T中的边或顶点为变量时,它的所有编码位都置为0.
剪枝规则.星形T在邻居信息N(v)上匹配时:如果Sig(T)&Sig(v)≠Sig(T),在N(v)上匹配星形T的过程被剪掉.
在每轮MapReduce操作中,Map函数在每个顶点的邻接链表上并行匹配一个新的星形T.如果在顶点v的邻接链表上匹配星形T时满足剪枝规则,也就是星形T的邻居边标签集合不是顶点v邻居边标签的子集,或者星形的叶子节点的集合不是顶点v邻居顶点的子集,那么星形T在顶点v的邻接链表上必然没有匹配结果,因此不再进行算法1的星形匹配.本文通过上述剪枝规则减少MapReduce迭代过程中无用的数据输入,同时减少大量没必要的星形匹配过程中涉及的计算,以此优化BGP查询.
例3:如图5所示,当在邻接链表N(GoldingW)上匹配星形T3时,因为Sig(T3)&Sig(GoldingW)≠Sig(T3)所以在邻接链表N(GoldingW)上的星形T3的匹配过程被减掉,从而可以减少中间结果.
4.2 推迟笛卡尔积操作
在本文的基本算法中,初始星形匹配阶段在匹配星形T=(r,L),其中,L={(p1,l1),…,(pt,lt)},v∈V时,首先根据叶子节点的标签在各个主语v的邻接链表N(v)上得到各个叶子节点li的候选集合S(li),然后通过叶子节点候选集合的笛卡尔积{v}×S(l1)×…×S(lt),得到星形T的所有匹配结果.但是大部分星形匹配结果无法形成最终的查询答案,从而导致在星形匹配阶段做了很多无用的笛卡尔积操作,在Reduce阶段连接代价过高.
本文的优化算法在星形匹配阶段仅仅得到各叶子节点的候选集合即可.在Map函数中计算局部查询图Pt-1和星形Tt的顶点交集V(Pt-1)∩V(Tt)中的各个顶点的候选集,并通过这些顶点候选集的笛卡尔积得到Reduce函数连接的键.MapReduce操作结束后,通过剩余顶点候选集的笛卡尔积得到最终的查询结果.将各个星形匹配过程中叶子节点候选集的笛卡尔积推迟到MapReduce操作结束的时候,做过滤部分无用的计算.
例4:匹配查询图Q1时,在前3轮的Map函数中,仅需要得到每个星形叶子节点的候选集.如图6所示,第2轮 MapReduce中,通过V(P1)∩V(T3)={?y,?g}中顶点的候选集合的笛卡尔积,得到星形T3中{?y,?g}的匹配结果{?y→House,?g→HorrorFiction},{?y→TheStand,?g→GothicFiction} 和 {?y→LordoftheFlies,?g→Allegory};P1中{?y,?g}的匹配结果{?y→TheStand,?g→GothicFiction}和{?y→TheShining,?g→GothicFiction}.将这些匹配结果作为键,在 Reduce过程中进行连接操作,可以观察到,仅当{?y→TheStand,?g→GothicFiction}可以得到局部查询图P2的匹配结果.类似地,在第 3轮 MapReduce中,通过V(P2)∩V(T1)={?x}中顶点候选集合的笛卡尔积,得到星形T1和局部查询图P2中{?x}的匹配结果集合,以这些匹配结果作为键值,在Reduce中进行连接操作.最后,通过剩余顶点集合{?a,?c,?w2,?p,?w1}中各顶点的候选集的笛卡尔积,得到查询Q1的最终匹配结果{?y→TheShining,?g→GothicFiction,?x→KingS,?a→NationalBookA,?c→Portland,?w2→GoldingW,?p→Doubleday,?w2→DekkerT}.在基本算法SDec中,Map函数在邻接链表N(GibsonW)上匹配星形T2时需要各个叶子节点的候选集的笛卡尔积S(?a)×S(?c)×S(?w2)×S(?g)×S(?y),然而查询图中顶点?x匹配 RDF数据图中顶点GibsonW并不能形成最终答案,因此,基本算法做了无用的笛卡尔积,代价较高.相反,优化算法通过推迟笛卡尔积提前过滤掉在邻接链表N(GibsonW)上的笛卡尔积操作.

Fig.6 Matching process of the example SPARQL BGP query graphQ1图6 SPARQL BGP示例查询图Q1查询匹配过程
5 实 验
本节在合成数据集和真实数据集上验证算法的有效性和可扩展性,并且与SHARD,S2X和SDec的优化版本的算法比较.不与S2RDF和TriAD方法作比较的原因如下.
(1) S2RDF使用ExtVP索引提高查询效率,但是预处理时间代价过高,严重限制了该系统对大规模数据集的适用性,最新的文献[22]中通过实验也验证了这一点.例如:在相同的实验环境下,S2RDF预处理DBpedia数据集的时间超过2.5个小时,远大于本文SDec系统的查询执行时间;
(2) 如文献[22]所述,TriAD假设数据必须装载到集群的内存中,如果数据量超过了集群内存大小,TriAD将不再适用.而本文没有这个限制条件,而且TriAD借助了大量的索引加快查询.
因此,与这两种方法进行比较实验是不公平的.
本文的SDec算法与图划分策略和分布式集群环境上的存储策略是独立无关的.实际上,本文使用分布式文件系统HDFS(Hadoop distributed file system)的默认划分策略.
5.1 实验环境和数据集
本文实验平台使用的分布式集群包括 8个相同的计算节点,每个节点使用主频为 3.60GHz的 Intel(R)Core(TM) i7-7700四核处理器,其内存大小为16GB,硬盘大小为500GB.节点间通信使用1000Mbps以太网.实验平台所用集群的所有节点均使用Linux 64-bit CentOS操作系统,其使用的Hadoop版本号为2.7.4,Spark版本号为2.2.0.本文原型系统的所有代码均用Scala语言实现.
本实验使用的数据包括WatDiv标准合成数据集以及DBpedia真实数据集,这两个数据集都是RDF数据集.WatDiv是一个标准的RDF合成数据集,允许用户定义自己的数据集并生成不同大小的数据集,本文使用了3个不同规模的WatDiv数据集(也就是WatDiv1M,WatDiv10M和WatDiv100M)进行实验测试和比较;DBpedia数据集是从维基百科中提取的一个真实数据集.本次实验中,所有数据集均为N-Triple格式,具体统计信息见表2.本文根据RDF查询图的形状将它们分为4类,包括线性查询(linear queries,简称L)、星形查询(star queries,简称S)、雪花形查询(snowflake queries,简称F)和复杂查询(complex queries,简称C),见表3.本文使用WatDiv数据集给定的20个基本查询模板进行实验测试.因为缺乏DBpedia数据集上的查询模板,本文设计8个查询覆盖上文提及的4个查询种类.

Table 2 Datasets表2 数据集

Table 3 Queries表3 查询
5.2 实验结果
本节分4组实验进行详细介绍,包括改变优化算法中哈希函数个数k、改变数据集规模及改变集群中节点个数来验证优化算法SDecopt、基本算法Sdec,SHARD和S2X这4种方法的效率和可伸缩性.以下实验结果中,每个查询测试3次取平均值,避免随机误差.
(1) 改变编码优化技术中参数k测试查询性能.
本组实验分别设置哈希函数个数k=1,2,3,在WatDiv100M数据集上测试20个模板查询.随着k从1增加到3,误判率f减小,可以在星形匹配阶段过滤更多的无用数据输入,加快数据查询;同时,随着RDF数据图中主语签名的位数组长度变长,占用内存空间越多,影响查询效率.
如图7所示,当k=3时,编码邻居信息增加查询运行时内存带来的影响占主要因素,导致查询时间增加;k=2时,在绝大部分查询上可以取得最好的查询性能.随着哈希函数个数从1到3,邻居信息BF编码的运行时内存变化.本文以下的所有实验中,优化方法中的哈希函数个数k取值为2.
(2) SPARQL BGP查询性能测试.
本组实验分别在合成数据集WatDiv100M和真实数据集DBpedia上验证集群节点个数为8时本文所提方法的查询效率.如图8所示,在合成数据集 WatDiv上,SDecopt在 20个模板查询上都可以获得最高的查询效率;同时,SDec也优于SHARD和S2X.在本文中,运行时间超过1×104s用INF表示.如图8所示:对查询F3和C2,S2X不能在该时间限制内结束,而本文的优化算法仅需要19.24s和36.92s就可以得到查询结果.对剩余的18个查询,本文优化算法的查询时间与S2X相比提高了7倍~40倍,平均查询时间提高17倍.究其原因:S2X将BGP中所有三元组模式的匹配结果进行连接操作会产生大量的中间结果,代价较高;而本文的最小匹配结构为星形,同时考虑 RDF图的丰富语义和结构信息,减少了大量无用的中间结果.与 SHARD相比,SDecopt的查询时间提高了16倍~99倍,平均查询时间提高40倍.SHARD采用三元组存储也将BGP查询分解为三元组模式进行匹配,在包含3列的数据表上进行连接操作,连接代价高.因此,SDecopt算法的查询时间比S2X和SHARD平均提高了一个数量级.

Fig.7 Experiments of changing the number of hash functionsk and the run memory图7 改变哈希函数个数k的实验结果及运行时内存变化

Fig.8 Query efficiency of different SPARQL processors over synthetic dataset图8 不同SPARQL处理器在合成数据集上的查询效率
此外,与基本算法SDec相比,优化算法时间减少了60.68%~87.00%,即,SDecopt可以更有效地评估BGP查询.该实验结果说明,本文的优化技术效果非常显著.原因包含以下两点:(1) 优化算法对邻居信息进行 BF编码,在星形匹配阶段,如果星形结构的签名与RDF图中主语s的签名不匹配,直接将N(s)上的星形匹配剪掉,以此过滤掉大量的无用计算;(2) 基本算法在星形匹配阶段进行了大量的无用笛卡尔积,而优化算法通过推迟笛卡尔积操作减少很多无用的笛卡尔积操作,提高了查询性能.
如图9所示,在真实数据集DBpedia上,SDecopt在所有查询上的效率也是最高的.回答查询C2时S2X报错,导致时间缺失.这说明S2X无法有效回答涉及大量中间结果的复杂查询.对于剩余的7个查询,优化算法SDecopt查询时间比S2X快7倍~497倍,平均查询时间比S2X快120倍;同时,与SHARD相比,优化算法SDecopt查询时间快7倍~26倍,平均查询时间快15倍.即:在真实数据集上,本文算法的平均时间也比SHARD和S2X快一个数量级.另外,由图9观察到:优化算法的查询时间明显提高,比基本算法SDec查询时间减少49.63%~78.71%.
(3) 改变数据集规模的查询性能测试.
本组实验通过改变WatDiv数据集规模从1M~100M在8个节点的集群上测试18个查询.本文将这18个查询分为4个查询种类,分别计算SDec,SDecopt,S2X和SHARD的4类平均查询时间.如图10所示,随着数据规模增大,所有SPARQL查询处理器的查询时间都增加,SHARD和S2X的查询时间增加幅度远大于本文方法.观察图10可知:数据集规模从10M个三元组增加到100M个三元组,S2X和SHARD的查询性能严重下降.如:对雪花形查询,SHARD和S2X在WatDiv100M上需要将近1000s的时间才可以得到查询结果,而本文的优化算法仅需10s左右.

Fig.9 Query efficiency of different SPARQL processors over real-world dataset图9 不同SPARQL查询处理器在真实数据集上的查询效率

Fig.10 Experiment results of changing the size of datasets图10 改变数据集规模的实验结果
(4) 算法可伸缩性测试.
本组实验在 WatDiv100M和 DBpedia数据集上进行,改变集群节点个数,从 4~8.从每类查询中随机选取 1个查询,也就是L4,S4,F2,C3.如图11所示:随着集群节点个数的增加,在合成数据集WatDiv上,这4个SPARQL查询处理器的查询时间减少.原因是随着集群节点个数的增加,CPU核数增加,查询过程中计算的并行度增加,查询所需的总时间减少.由图11可以看出,SDecopt的查询性能始终是最高的.
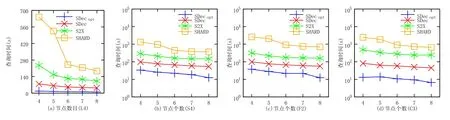
Fig.11 Experiment results of changing the number of sites on synthetic dataset WatDiv100M图11 改变集群节点个数在合成数据集WatDiv100M上的实验结果
在真实数据集DBpedia上,改变集群节点的个数验证算法的可伸缩性.本次实验选取L1,S1,F1,C1查询,即,从每类查询中随机选取1个查询进行实验.如图12所示:随着集群节点个数从4增加到8,上述4个SPARQL查询处理方法的查询时间逐渐减少.
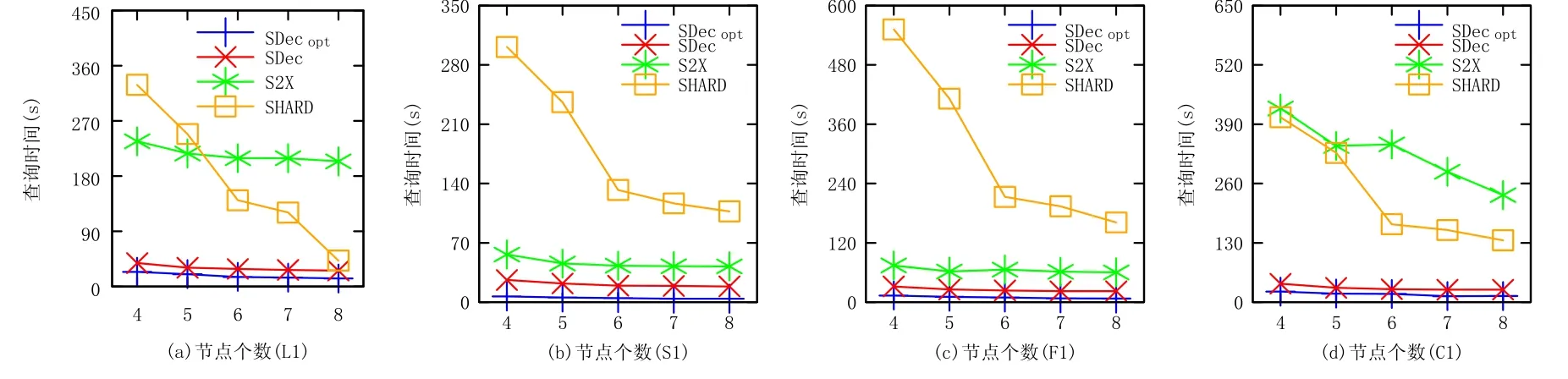
Fig.12 Experiment results of changing the number of sites on real-world dataset DBpedia图12 改变集群节点个数在真实数据集DBpedia上的实验结果
6 总 结
本文提出了基于MapReduce框架的查询处理器SDec,有效回答大规模RDF智能图数据上的SPARQL BGP查询.本文的SDec算法利用RDF图内嵌的丰富语义和RDF图结构分解查询图为星形集合,并确定这些星形的匹配顺序,以此减少星形匹配过程中的中间结果.此外,为了进一步提高查询算法的效率,本文设计了两个优化技术,包括对邻居信息编码过滤无用的数据输入和推迟笛卡尔积操作改进基本算法的性能.合成数据集和真实数据集上的大量实验验证了本文所提算法的有效性、高效性和伸缩性,并且实验结果显示,本文的算法优于SHARD和S2X.
猜你喜欢
传染病信息(2022年2期)2022-07-15
计算机应用与软件(2022年5期)2022-07-07
计算机与生活(2022年3期)2022-03-13
宁波大学学报(人文科学版)(2021年4期)2021-07-07
计算机应用与软件(2021年4期)2021-04-15
神经损伤与功能重建(2020年11期)2020-12-01
青年生活(2020年16期)2020-07-06
五邑大学学报(自然科学版)(2019年3期)2019-09-06
第二课堂(课外活动版)(2019年12期)2019-02-10
初中生世界·七年级(2018年7期)2018-09-07
