
基于分治算法的DNA序列比对成本模型
2019-04-28 05:59刘欣睿四川大学软件学院
数码世界 2019年3期
刘欣睿 四川大学软件学院
引言
DNA序列比对是生物信息学中的一项重要任务,在实际应用中,DNA序列比对可用于DNA亲代测试,同时有助于了解物种和个体差异之间的变化。本文将提供最佳的DNA序列比对,旨在减少任何给定序列的缺失匹配和缺口的数量。算法实现的第一个挑战是巨大的搜索空间,因此本文建立了优化数学模型以修剪搜索方法。其次,不能用蛮力来找到比较的最佳方法。综上本文算法基于这两个挑战而引入。
1 分治算法
对于分治算法需要确定何时退出递归。例如,对于两个DNA序列:X(0,m)和Y(0,n),如果要计算opt(i,j),那么递归的退出可以分为两种情况:

但该算法存在两个缺陷。首先,该算法仅提供最佳成本惩罚,而不是最佳对齐。其次,算法的复杂度非常大并且呈指数增长,在最坏的情况下,该算法的时间复杂度将为O(3 ^ max(m,n))。
2 动态规划算法
为克服上述分治算法的缺陷,本文引入动态规划算法。在设计动态规划算法时,通常可以遵循以下几个步骤:
1.分析和比较最优解的特征;
2.递归定义最优值;
3.通过自上而下的逻辑运算得到最优解,得到函数的最大值或最小值。
这种方法是以时间交换空间。首先,建立一个m乘n的矩阵。然后将opt(i,j)的结果存储到第i行第j列。例如,设有两个DNA序列 X(0,10)和 Y(0,8):
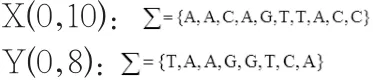
根据递归的终止条件,可以得出以下结论:

3 算法实现结果
由上述算法原理可进一步实现动态规划算法,最终得到已知DNA序列的成本矩阵11*9,如下所示:

i/j 0T 1A 2A 3G 4G 5T 6C 7A 8 -0A 7 8 10 12 13 15 16 18 201A 6 6 8 10 11 13 14 16 182C 6 5 6 8 9 11 12 14 163A 7 5 4 6 7 9 11 12 144G 9 7 5 4 5 7 9 10 125T 8 8 6 4 4 5 7 8 106T 9 8 7 5 3 3 5 6 87A 11 9 7 6 4 2 3 4 68C 13 11 9 7 5 3 1 3 49C 14 12 10 8 6 4 2 1 210- 16 14 12 10 8 6 4 2 0
根据上述矩阵,已知array [0] [0]=7,即可利用tracepath来获得最佳对齐。
(1)如果(0,1)属于路径,则 opt(0,0)= opt(0,1)+ 2 = 6+ 2 = 8> 7,因此这种情况不会退出。
(2)如果(0,1)属于路径,则 opt(0,0)= opt(1,0)+ 2 = 8+ 2 = 10> 7,因此这种情况不会退出。(x0与a对齐间隙)
(3)如果(1,1)属于路径,则 opt(0,0)= opt(1,1)+ 1 = 6 +1 = 7,因此本情况是最佳对齐。(x0与y0对齐,但是x0与y0不匹配)
4 结论
序列比对是生物信息学中最基本的问题。为了进一步研究DNA序列比对问题,本文建立了一个新模型,称为成本模型,以确定比对优化的程度。基于这个新模型,使用Divide and Conquer算法来解决这个问题。但本文选择动态规划算法来克服时间复杂性的缺陷。最后,创建了后向跟踪算法,以找到最佳对齐的轨迹。
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
密码学报(2021年4期)2021-09-14
现代畜牧科技(2021年4期)2021-07-21
成都信息工程大学学报(2021年6期)2021-02-12
天津医科大学学报(2021年1期)2021-01-26
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
环球慈善(2019年6期)2019-09-25
活力(2019年15期)2019-09-25
