
视觉场景描述及其效果评价*
2019-05-20 06:56王伯龙
软件学报 2019年4期
马 苗,王伯龙,吴 琦,武 杰,郭 敏
1(现代教学技术教育部重点实验室(陕西师范大学),陕西 西安 710062)
2(陕西师范大学 计算机科学学院,陕西 西安 710119)
3(School of Computer Science,The University of Adelaide,Adelaide SA5005,Australia)
视觉场景描述技术通过对输入图像或视频的内容分析,自动生成一个语句或若干语句的形式对视觉场景中的内容进行描述,属于计算机视觉、多媒体、人工智能和自然语言处理等领域的交叉性研究课题.视觉场景描述问题可归结为视觉语义理解、多媒体语义学习、场景理解等领域中的子问题,其历史可追溯到多模态检索、跨模态学习等问题的研究.
近年来,得益于深度学习相关模型、方法的突破性进展和大样本数据集的出现,尤其是随着 MS COCO、Flickr等基准数据集的出现和深度学习框架下卷积神经网络(convolution neural network,简称CNN)、循环神经网络(recurrent neural network,简称RNN)、长短时记忆网络(long short-term memory,简称LSTM)等深度网络模型研究的日益成熟,视觉场景描述技术再度掀起研究高潮,并正在变为现实.然而,由于视觉场景中呈现内容的丰富性和自然语言表达的形式多样性,使得视觉场景描述成为一项复杂而富于变化的挑战性任务.
视觉场景描述问题在业界和学术界均引起了高度重视,国内外相关研究机构包括Google实验室、Baidu研究院、微软研究院、中国科学院、斯坦福大学、伯克利大学、加利福尼亚大学等.在国际知名的学术论文图书馆ACM、IEEE、Elsevier、Springer和国内外学术论文搜索引擎Google Scholar和百度学术中,以“image description、video description、image captioning或video captioning”等为关键字,检索论文,其结果表明:近年来,与视觉场景描述有关的学术论文发表数量一直呈增长趋势,反映最新成果的一系列论文在许多知名国际会议中如雨后春笋般产生.例如,“计算机视觉与模式识别国际会议(IEEE Conf. on Computer Vision and Pattern Recognition,简称CVPR)”[1-22]、“计算机视觉国际会议(IEEE Int’l Conf. on Computer Vision,简称 ICCV)”[23-33]、“欧洲计算机视觉会议(European Conf. on Computer Vision,简称 ECCV)”[34-40]、“神经信息处理系统国际会议(Int’l Conf. on Neural Information Processing Systems,简称 NIPS)”[41-49]和“自然语言处理国际会议(Int’l Joint Conf. on Natural Language Processing,简称 NLP)”[50,51]等.
图1所示为近年来关于“视觉场景描述”在计算机视觉领域中三大会议上论文发表数量的统计图,直观地展现了该技术的研究趋势.这些研究成果不仅推动了计算机视觉、自然语言处理等相关学科的融合发展,而且展现了其在视觉信息相关的跨模态检索、智能监控、海量数据压缩、帮助视觉障碍人士感知与理解周围环境等众多领域的潜在应用.
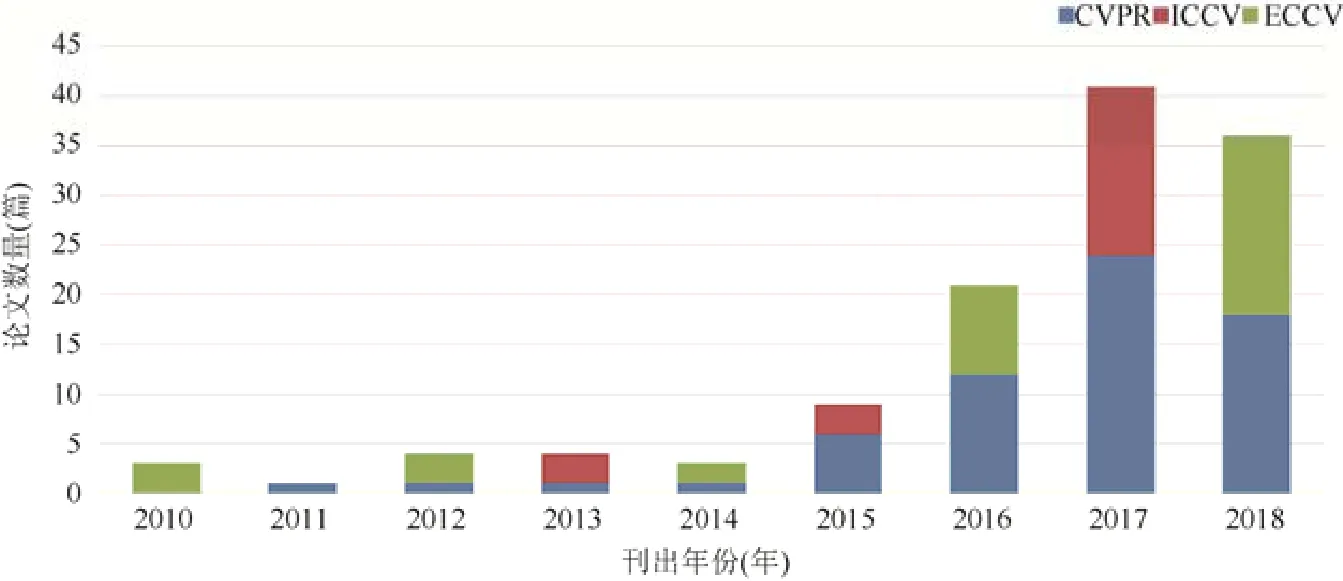
Fig.1 Papers on visual scene description published in the proceedings of three top conferences图1 三大顶级会议关于“视觉场景描述”论文的发表情况
本文综述视觉场景描述及其效果评价的研究现状和进展.具体来说,第 1节论述视觉场景描述的定义、研究任务,简要分析视觉场景描述与跨模态学习、场景理解等相关技术的关系.第 2节分类总结视觉场景描述的主要方法、模型及研究成果.第 3节整理可用于图像描述和视频描述研究与竞技的基准数据集.第 4节讨论客观评价视觉场景描述效果的主要指标、方法和存在的问题.最后,第5节展望视觉场景描述的应用前景.
1 视觉场景描述
1.1 定义与研究内容
视觉场景描述是指用计算机视觉技术模拟人眼观察到一幅静态图像或观看了一段视频片段后,用自然语言的形式描述观察到的视觉场景内容的方法与技术.由于视觉场景主要源于图像和视频,故视觉场景描述的研究主要针对图像和视频两类输入信息展开.前者用自然语言形式的文本语句描述图像的场景内容,称为图像字幕(image captioning)或图像描述(image description);后者用自然语言形式的文本语句描述视频片段提供的场景内容,称为视频字幕(video captioning)或视频描述(video description).
视觉场景描述的研究任务是自动生成一个或多个句子来描述输入图像或视频中呈现的视觉场景内容,最终目标是用自然语言准确、快速、详细地重述人眼可以观察到的场景,内容涉及场景中存在的目标检测、跟踪(如所在区域、目标属性、目标状态)及各目标或相应事件之间关系的生成与表达等.
图2所示的3个例子给出了通过视觉场景描述技术自动生成自然语言形式描述1幅图像和2段视频片段内容的语句.
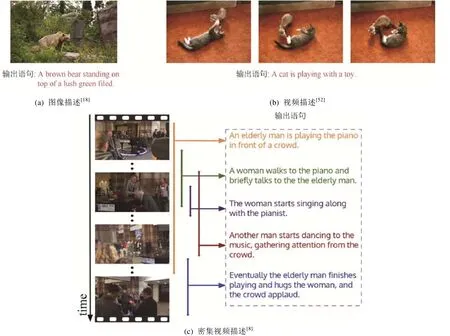
Fig.2 Examples of visual scene description图2 视觉场景描述的一组例子
获得理想视觉场景描述效果的前提是计算机具有和人类类似的视觉感知能力,能够对静态或动态的场景进行感知、分析和理解,并能得出符合人类习惯的语义描述.因此,从这个角度来看,视觉场景描述是场景语义分析和视觉场景理解任务的重要组成部分,也是对场景语义理解和分析结果的进一步呈现方式之一.
1.2 相关技术
鉴于视觉场景描述技术的多学科交叉性质,下面我们分别简要论述与之密切相关的多模态检索、跨模态学习、场景理解、场景分类、场景解析、视觉关系检测、场景图生成、视觉问答、指示表达生成等技术.
(1) 多模态检索、跨模态检索和跨模态学习
模态是指数据的存在形式.现实世界中,人们可以用文本、音频、图像、视频等不同模态的数据描述同一对象或事件,得到同步数据.因此,计算机也可以利用这些同步数据学习同一对象或事件的视觉、声音或文本等不同模态的特征.
多模态检索(multimodal retrieval):这是指融合不同模态的检索方法和技术.其特点在于,它不对各模态信息间的关系建模.查询和待检索的文档不止包含1个模态,但至少有1个模态是相同的.显然,对多媒体数据进行多模态检索可有效提高单模态检索的准确度[53].
跨模态检索(cross-modal retrieval):这是指通过寻找不同模态样本之间的关系,实现利用某一种模态样本搜索近似语义的其他模态样本的方法和技术.其特点在于,检索结果的模态和查询的模态不同.例如用图像检索文本、视频或音频,其关键在于对不同模态的关系进行建模,难点在于需要跨越不同模态间的语义鸿沟[54].
跨模态学习(cross-modal learning):这是指通过对已有多模态训练样本的学习,努力学习到无标记数据的单一模态的更好表示的方法和技术.其特点在于,多模态数据仅在特征学习期间可用,在监督训练和测试阶段,只有单一模态数据可用.
视觉场景描述可看作是一种跨模态学习,即通过大样本视觉场景及其对应的文本形式的描述语句的学习,掌握如何用自然语言去描述未标记的场景内容,包括场景中的对象、对象属性或状态,以及对象之间的关系.在此基础上,可以完成跨模态检索、视觉问答等更高级的场景分析及理解任务.
(2) 场景理解、场景识别/分类、场景解析[55-59]
场景理解(scene understanding):这是指以图像及视频为研究对象,分析什么场景(场景分类或场景识别)、场景中有什么目标(目标检测、目标识别、场景解析)、目标之间的相互关系(场景图、视觉关系)以及如何表达场景(场景描述)的方法和技术.该领域中的大规模场景理解挑战赛 LSUN(large-scale scene understanding)主要聚焦于场景分类、显著预测、房间布置估计和字幕生成这4类任务.
场景识别(visual place recognition或scene recognition):这是指将一幅图像或一段视频片段中的场景标记为不同类别的方法和技术.若事先给出待识别场景的类别标签,则场景识别问题可归结为一个分类问题,即场景分类(scene classification)[55-59].
场景解析(scene parsing):这是指对场景图像进行分割,并进一步解析为与语义类别相关的不同区域的方法和技术.其特点在于,它预测场景中每个像素的类别标签、位置以及形状,提供了对场景的完全理解,是自动驾驶、机器人感知等应用的前提和基础.
显然,场景理解涵盖了场景识别、场景解析与场景描述.场景识别与场景解析的结果可以作为场景描述的基础和前提,而场景描述是场景理解、场景识别和场景解析的一种自然语言形式的表达和呈现.
(3) 视觉关系检测、场景图生成和指示表达生成
视觉关系检测(visual relation detection):这是指将对象置于一个上下文语义环境中,研究如何提取不同对象的位置和对象间的空间逻辑关系等内容的方法和技术.不同于视觉内容与自然语言之间的关系,视觉关系检测研究的是各对象之间交互的直接关系,可以为图像注释、问答系统等应用提供深层语义信息[60].
视觉问答(visual question and answer)[26-29,34,41,61]:这是指让计算机根据输入的图像(视频)和问题,研究如何输出符合人类表达习惯且内容合理的答案的方法和技术.目前,该研究多集中在看图问答方面,相关技术涉及目标识别、行为识别和问题解析等.
场景图生成(scene graphs generation):这是指通过显式建模对象、对象属性和对象之间的关系来捕获视觉场景的详细语义的方法和技术.该技术可以为视觉场景描述和视觉问答等应用提供深层次的语义信息,有助于发现和利用场景中各对象之间的关系[62].
指示表达生成(referring expression generation)[63,64]:这是指研究如何明确、清晰地描述特定对象的方法和技术.该技术常使用属性来描述特定对象,进而能够在给定的上下文中辅助识别相应对象.理解和生成是与指示表达相关的两个任务:理解任务要求系统选择给定表达所描述的对象;生成任务是为图像内的指定对象生成表达.
从场景内容分析角度,视觉关系检测、视觉场景图和指示表达生成的相关研究致力于场景中存在的对象、关系及属性、状态,因此,其研究结论均可引入到场景描述中来深入发掘场景构成、对象属性与状态等信息,这均有利于提高视觉场景描述的准确度.
2 主要方法和研究进展
如第 1.1节所述,按照场景载体的不同,视觉场景描述从图像描述和视频描述两个维度展开.根据研究思路的不同,视觉场景描述方法可细分为基于模板的方法(template based approaches)、基于检索的方法(retrieval based approaches)以及目前主流的基于序列学习的方法(sequence learning based approaches).根据生成语句的数目不同,视觉场景描述也可分为基于单一语句的视觉场景描述(用一句话描述场景内容)、基于多语句的视觉场景描述(用一段话去描述场景内容)和基于密集描述的视觉场景描述(以不同区域、不同对象或不同事件为单位,详细地描述场景内容),如图3所示.

Fig.3 Categories of visual scene description methods图3 视觉场景描述方法的分类
下面以视觉场景描述的原理为主线,分别讨论基于模板、检索以及序列学习的视觉场景描述方法、原理和代表性成果.
2.1 基于模板的场景描述方法
该类方法预先定义生成语句的一些特定语法规则,如将句子分为主语、动词和宾语等组成成分,然后检测给定场景的内容、属性,使用概率图模型将状态对齐到属性,并用预定义的句子模板推导出句子结构.
在图像描述方面的代表性工作中,Yang等人(2011年)从Gigaword语料库训练的语言模型获得动作的估计以及名词、场景和介词共同定位的概率,然后将其作为隐马尔可夫模型(hidden Markov model,简称HMM)的参数,模拟句子生成过程[51].Mitchell等人(2012年)给出计算机视觉检测中产生图像描述的 Midge系统,它过滤不可能的属性,并将对象放置到有序的句法结构来生成场景内容的语句描述[65].Krishnamoorthy等人(2013年)利用SVO语言模型来选择“主语、动作、对象”三元组,并生成语句[66].Kulkarni等人(2013年)通过检测图像中的对象和属性及它们的介词关系,使用条件随机场来预测包含这些对象、修饰符和关系的最佳结构[67].Lebret等人(2015年)从图像中预测短语,然后将它们与一个简单的语言模型结合起来,生成关于图像内容的场景描述[68].
在视频描述方面的代表性工作中,Kojima等人(2002年)引入动作的概念层次来描述人类活动[69].Rohrbach等人(2013年)采用条件随机场(conditional random field,简称CRF)算法模拟对象和视觉输入的活动之间的连接,并生成描述的语义特征[33].Guadarrama等人(2013年)定义语义层次以学习不同句子成分之间的语义关系[32].此外,Xu等人(2015年)提出了一个由语义语言模型、深度视频模型和联合嵌入模型组成的统一框架,来学习视频和自然语句之间的关联[70].
显然,基于模板的场景描述方法总是能够在预定义的语句模板中直接生成具有检测关键字且语法正确的句子,其不足在于,该类方法高度依赖于预定义的语句模板,生成语句受到固定句法结构的限制,句子描述的内容和形式失去了新颖性和灵活性.
2.2 基于检索的场景描述方法
该类方法的主要思路是通过在数据库中搜索视觉上与输入图像相似的图像,并从检索到的图像标题中利用最近邻法找到最佳描述语句.因此,该类方法本质上是通过从数据库中的句子池中选择语义最相似的句子来生成输出图像的视觉场景描述.
该类方法主要出现在图像描述应用中.Farhadi等人(2010年)使用近邻法则选出候选的图像描述语句,将这些语句和对应图像映射到Meaning Space,并用Tree-F1法则进行匹配,得到5个最佳描述语句[40].Ordonez等人(2011年)提出 Web图像字幕生成方法,该方法依赖于从互联网收集的大量图像数据,使用全局检索或结合内容估计检索这两种策略产生新的图像标题[49].Kuznetsova等人(2014年)提出基于树结构的语句生成方法,其主要思想是从现有的图像描述中收集表达短语,然后选择性地组合所提取的片段来产生新的描述语句[71].Hodosh等人(2015年)提出基于 KCCA的基准系统来进行图像描述和搜索,通过构建序列核及能够捕获语义相似性的核来建立图像与文本间的联合空间,进而描述图像内容[72].Devlin等人(2015年)利用 CNN获得图像的候选词袋,然后用k邻近检索模型获得该图像的共识描述,在COCO基准数据集上性能优良[73].
易知,该类方法产生的视觉场景描述语句与人工标注的描述语句在表达方式和风格上较为一致,不足在于生成效果受检索数据库中句子池里人工标注的样本数量、样本描述精细粒度以及输出图像与检索图像的相似程度的约束和影响.
2.3 基于序列学习的场景描述方法
基于序列学习的场景描述方法是深度网络模型获得突破性进展以来主流的视觉场景描述方法.“编码器-解码器(encoder-decoder)”框架下的“CNN(或 3D CNN)+RNN”和“CNN(或 3D CNN)+LSTM”是该类方法的常见组合.其中,RNN在传统神经网络中引入时序概念,将上一时刻的输出作为下一时刻的输入重新进入到网络,可分为单向 RNN、Bi-RNN和 m-RNN;LSTM模型可视为 RNN的改进版本,又可细分为单向 LSTM 模型、双向LSTM模型、深层结构的双向LSTM模型以及GRU模型等[74-76].该类方法的一般过程如图4所示.
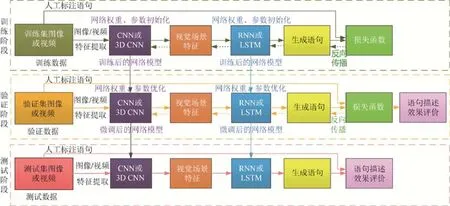
Fig.4 General framework of visual scene description based on sequence learning图4 基于序列学习的视觉场景描述方法的一般框架
在图像描述方面的代表性工作包括:(1) 在“CNN+RNN”方法研究中,Vinyals等人(2015年)从图像中提取特征并与人工标注语句输入到RNN中训练,得到图像内容描述[20].Karpathy等人(2015年)以RCNN(regions with CNN features)为 Encoder提取图像中各个目标区域,再以 BRNN(bidirectional recurrent neural network)作为Decoder,并参考上下文来生成语句,最终得到图像中各个区域的描述[17].(2) 在“CNN+LSTM”方法研究中,Donahue等人(2015年)利用 LSTM 模型生成内容描述[18].Huang等人(2016年)提出具有选择性的多通道LSTM模型,以改进局部图像信息与生成文本语句之间的匹配效果,提升图像描述的合理性[9].Ren等人(2017年)利用局部预测模型“政策网络”和全局评估模型“价值网络”共同协作生成图像描述[2].以上方法均未考虑场景中的感兴趣区域.(3) 在引入注意机制的方法研究中,Xu等人(2015年)将LSTM模型与人类视觉中的注意机制相结合,在生成对应的单词时自动聚焦于显著对象[77].Lu等人(2017年)引入视觉“哨兵”策略,设计自适应视觉注意模型[3].You等人(2016年)使用预生成的语义概念建议来指导描述生成,并学习在不同时刻选择性地关注这些概念[13].Wang等人(2017年)则利用基于视觉注意机制的 CNN提取图像特征,设计了 Skel-LSTM 模型和 Atrr-LSTM 模型,分别用来产生文本语句中的“主、谓、宾”和“定、状、补”[4].(4) 在引入外部知识场景和属性方法的研究中,Wu等人(2016年)用高层次的概念(属性),显著改进了RNN的图像描述质量[14].该属性进一步被You等人(2016年)用来增强图像描述性能[13].
在视频描述方面的代表性工作包括:(1) 在“3D CNN+RNN”方法研究中,Socher等人(2014年)利用RNN和C3D从视频帧序列中提取出来的三维特征进行时序上的编码并进行建模,最后融合音频特征完成视频分类与单句视频内容描述[78];为了产生更多的句子来详细描述视频场景中的内容,Yu等人(2016年)利用分层递归神经网络结合视觉注意机制建模句子间的依赖性,从而生成视频的多句描述[12];(2) 在“CNN+LSTM”方法研究中,Subhashini等人(2014年)利用CNN提取每个视频帧序列特征图并将它们进行平均池化,再利用LSTM模型生成描述语句[52].Torabi等人(2016年)用 CNN提取待描述视频的 C3D矩阵作为视频信息的三维特征,再通过LSTM模型生成描述语句[79];Pan等人(2017年)利用基于 COCO数据集的弱监督多实例学习的语义检测器,分别提取图像和视频的语义属性,将整合后的语义属性送入 LSTM-TSA网络实现视频场景内容的语义描述[5].同年,Zhang等人(2017年)提出任务驱动的动态融合机制来降低视频描述中的模糊度,细化对视频内容的刻画程度[6];Shen等人(2017年)利用弱监督的多事例多标记学习方法建立视频区域与词标注的全卷积网络,实现视频内容的多样化密集描述[7].(3) 在引入事件概念的方法研究中,Krishna等人(2017年)以事件为单位,通过检测事件、分析事件间的时序关系,建立基于事件驱动的视频描述模型[8].在此基础上,Wang等人(2018年)将“只利用过去上下文来进行建议预测”改进为“用双向建议模块编码过去和将来的上下文”,提出双向视觉融合的密集视频描述方法.该方法能够区分和描述时间上高度重叠的事件,进一步提高对视频内容进行密集描述的能力[1].
该类方法的特点在于,利用深度网络模型在视觉内容和文本句子的联合空间中学习概率分布,来生成句法结构灵活的句子,能够提供较为准确的场景描述效果.其优点体现在,通过“CNN+RNN”等深度网络结构自动获取场景内容的特征表达能力,去掉了繁杂的人工特征提取过程,属于端到端的解决问题方式,但是该类方法依赖于大样本基准数据集的支撑,其在应用中的性能取决于实际场景与大量样本场景间的相似性.相似度高的场景内容描述质量高,反之,场景内容描述结果可能与实际情况不符.
3 视觉场景描述的基准数据集
在视觉场景描述的研究中,尤其是Encoder-Decoder框架下基于序列学习的方法及模型构建大多属于有监督的机器学习方法,因此离不开人工标注的基准数据集的发展.这些基准数据集不仅提供了大量的图像和视频等资源,而且提供了对数据集中图像、视频对应的人工标注语句.它们一方面供研究人员对所提出模型或方法的正确性与有效性进行检验,另一方面也为不同场景描述方法或模型的性能对比提供了开放的平台.
下面给出人工标注的产生和视觉场景描述的常用基准数据集.
3.1 人工标注的产生
近年来,人工智能技术被引入各类复杂应用,如语音理解、物体识别、环境感知等.然而,这些智能系统的构建往往需要含有标注的大量数据样本作为训练资源,而提供这些符合分类规则和人类认知规律的标注还不能完全由计算机生成.实际上,绝大多数图像、视频的标注还是人工完成的.
随着机器学习应用的不断普及,人工主导、监督学习、半监督学习和无监督学习的混合训练方法将是未来人工智能系统的主要学习方式.这意味着越来越多的数据需要被正确标记.实际上,针对此任务,亚马逊、苹果、谷歌、微软等均有自己的劳务众包平台或直接使用第三方服务.其中,始于 2005年的亚马逊劳务众包平台(Amazon mechanical turk,简称AMT)是最有影响的在线劳务众包平台之一.目前AMT注册工作人员累计超过50万.这些工作人员被称为Turker,他们通过互联网可以全天候地完成数据标定任务.例如,在计算机视觉领域产生重要影响的ImageNet数据集中大部分标注工作是在AMT上由50 000名Turker历时约2年完成.
3.2 视觉场景描述的基准数据集
目前,国际上可用于视觉场景描述研究与竞技的公开基准数据集有 10余种.其中,图像描述基准数据集包括 Pascal VOC[80]、Flickr系列[72,81,82]、MS COCO[83]、YFCC100M[84]、Visual Genome[85]和 ICC[86]等,见表 1.

Table 1 Datasets on image captioning表1 图像描述的基准数据集
与之类似,现有的国际上通用的视频描述基准数据集包括 MSVD[87]、YouCook[22]、TACoS multilevel dataset[88]、YouTube2Text[32]、MPII-MD[89]、M-VAD[90]、MSR-VTT[11]、ActivityNet Captions[8]和 YouCook2[91]等数据集,见表2.

Table 2 Datasets on video captioning表2 视频描述的基准数据集

Table 2 Datasets on video captioning (Continued)表2 视频描述的基准数据集(续)
4 视觉场景描述的效果评价
随着视觉场景描述生成方法及模型日渐增多和基准数据集的不断丰富,研究人员希望能够通过设计一些客观指标自动判断视觉场景描述生成的深度网络模型及方法的有效性,由此提出了一些客观的性能评价指标[9,19,92-105].这些指标的本质是对人工标注语句和自动生成语句的相似度比较.
常见的客观评价指标见表3.
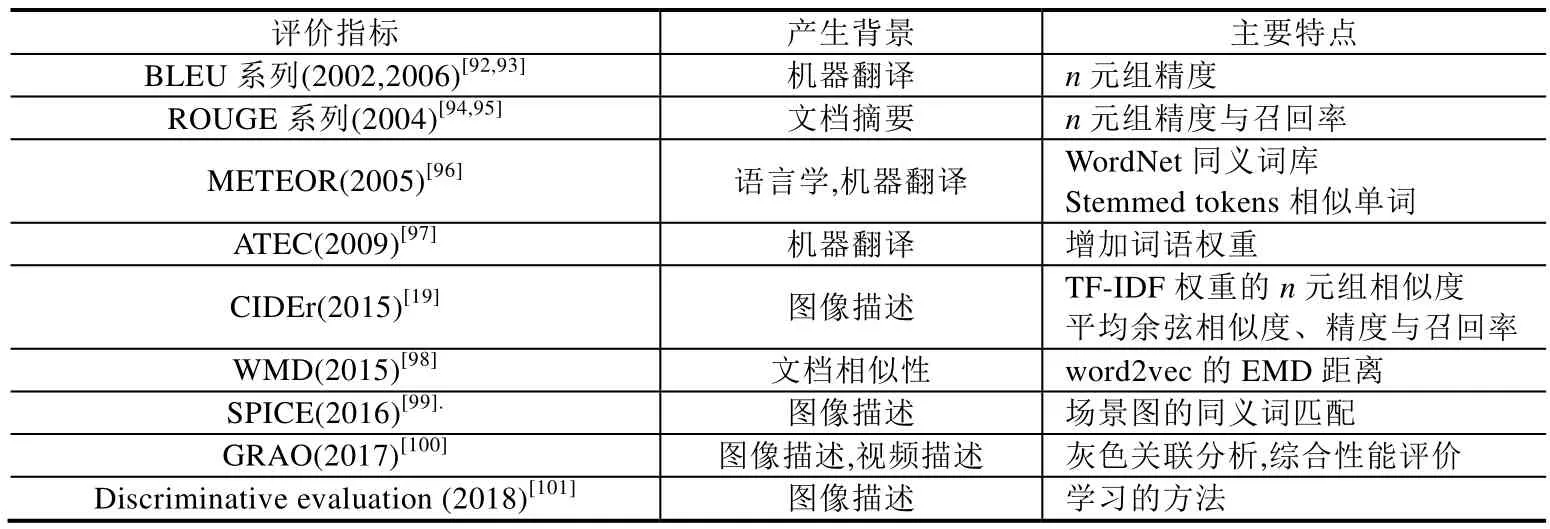
Table 3 Performance evaluation on visual scene description表3 视觉场景描述的性能评价
4.1 基于n元组匹配的客观评价
早期的研究工作主要集中在基于n元组的匹配情况来评价生成语句与人工标注语句之间的相似程度.然而,由于此类方法未考虑语义信息的一致性,有时这些方法的评价结果与人类感知不符.
(1) BLEU指标系列[92,93].包括BLEU-1、BLEU-2、BLEU-3、BLEU-4,主要思想是基于人工标注语句与生成语句之间n个连续字符的严格匹配情况进行评价.它的计算过程是对生成语句与人工标注语句的n元组进行比较,并计算出匹配片段的个数.这些匹配片段与它们在文字中的位置无关.匹配片段数越多,该指标取值越大,说明生成语句与人工标注语句相似度越高,场景描述效果越好.因该系列指标计算简单,故广泛用于机器翻译的效果评价.不足之处在于,计算过程中人工标注语句的单词会被重复利用,易引起评价结果出现偏差.
(2) ROUGE指标系列[94].包括ROUGE-L、ROUGE-N、ROUGE-W和ROUGE-S[95].其中,ROUGE-L用于计算一个生成语句与一个人工标注语句之间的相似度,主要思想是对比系统生成语句与人工标注语句,通过统计二者之间基本单元的重叠数目来评价生成语句的质量;ROUGE-N用于计算一个生成语句与多个人工标注语句之间的相似度,当单一生成语句与多个人工标注语句计算评分时,ROUGE-N最终取值为生成语句与各人工标注语句ROUGE-L评分中的最高分.该指标取值越大,说明生成语句与人工标注语句相似度越高.不足在于,其计算过程只是简单地采用人工标注语句与生成语句间的公共子序列长度进行计算,未考虑生成语句与人工标注语句之间的语句关联度.
(3) CIDEr-D指标[19].主要思想是将每个句子都看作“文档”,将其表示成 TF-IDF向量的形式来计算每个n元组的权重,将句子表示成向量形式,每个人工标注语句和待评价语句之间通过TF-IDF向量的余弦距离来度量其相似性,在n元组的计算过程中同时考虑了精度与召回率,提高了以往计算指标在度量共识方面的准确性.当单一生成语句与多个人工标注语句计算评分时,CIDEr-D最终取值为生成语句与各人工标注语句 CIDEr-D评分中的最高分.该指标常用于图像描述的语句评价,取值越大,说明生成语句与人工标注语句相似度越高.
(4) GRAO指标[100].主要思想是先用单一性能指标对源于不同描述生成算法得到的语句给出评分,再对这些评分结果进行带权值的灰色关联分析,实现对各种描述生成算法的性能优劣排序.该评价指标的特点在于把人们主观评价时的先验知识映射为权值,与多个客观评价指标相结合进行综合性能评价.不足在于,其计算结果依赖于各单一指标的取值.
4.2 基于语义信息匹配的指标
基于n元组匹配的度量指标在“因单词不同而语义相同”或“句子中的n元组相同但语义不同”两类场景描述语句评价时,结果往往与人类感知不符,难以合理地度量和反映视觉场景内容生成的形式多变的语句与内容的一致性,严重时可能会得到与人类感知相反的结果.为解决此类问题,研究人员提出了基于语义信息匹配的度量指标[6].
(1) WMD指标[98].主要思想是在计算人工标注语句与生成语句的相似度时,把其中一个语句的多个单词映射到多个隐层向量里,分别计算各单词间的距离,再通过加上单词的权重来计算两个语句间的距离.该指标取值越大,说明生成语句与人工标注语句的相似度越低.
(2) METEOR指标[96].将“准确匹配的单词”扩展到基于WordNet同义词库或“Stemmed Tokens”的“语义相似单词”,计算最佳生成语句与人工标注语句之间的精度与召回率的调和均值.当单一生成语句与多个人工标注语句计算评分时,METEOR最终取值为生成语句与各人工标注语句 METEOR评分中的最高分.该指标考虑了人工标注语句与生成语句的单词或词组的前后顺序,但因其依赖语句间n元组的相似性,无法评估待评价语句的语义相关度.该指标取值越大,说明生成语句与人工标注语句相似度越高.
(3) ATEC指标[97].将选择的单词及其语序视为句子表达中的两个关键要素,根据多匹配模板和单词信息量化评价选择的单词,通过对单词的位置距离及词序的差异性评价单词的语序,并通过训练的方式来确定两者的最佳权重.该指标取值越大,说明生成语句与人工标注语句相似度越高.
(4) SPICE指标[99].考虑了同义词现象,并运用WordNet模块的Synset功能来进行同义词合并与匹配.该指标计算语句间的单词相似度,也参考了语句间的关联度,与人类判断有很好的相关性,其不足在于未参考句子的句法结构,仍依赖n元组的匹配情况.该指标取值越大,说明生成语句与人工标注语句相似度越高.
(5) SM LSTM指标[9].主要思想是用全局“视觉-语义”相似度度量图像和句子之间的匹配关系.全局相似性可看作由图像(对象)和语句(词)成对实例之间的多个局部相似性的复合聚集.因此,Huang等人(2016年)提出了一个选择性多模态的长短时记忆网络,用来计算图像和句子间的匹配程度.
综上所述,人们提出了很多客观指标或评价方法来判断视觉场景描述方法的性能优劣.但是,合理、有效、快速地评价视觉场景描述结果仍然充满挑战,主要原因包括:
① 用不同方法或模型对同一场景进行描述时,场景内容与生成语句之间的关系为“一对多”映射,即生成语句具有非唯一性.
② 同一场景或视频序列的生成描述已经可以由一个语句扩展到多个语句组成的一段语句.但是,如何用现有数据集提供的一个人工标注语句去匹配若干语句形成的段落还有待进一步研究.
③ 人类语言表达方式的多样性使得即使在语义相同的情况下,对同一场景的描述语句也会千差万别.例如,生成语句和人工标注语句之间由于表述问题可能存在主谓倒装、一义多词的现象,这使得生成语句与人工标注语句间的主、谓、宾匹配变得更加复杂,因此有必要研究基于语义的性能评价指标.
④ 已有文献表明,注意力机制、概念(属性)等策略可以用来有效提升语句的描述能力,但是现有的评价指标并不支持基于感兴趣区域或关注对象的描述效果评价.
5 视觉场景描述面临的问题与挑战
尽管视觉场景描述的研究得到了国内外计算机视觉、自然语言处理、多媒体等相关领域研究人员的普遍重视,但其真正走向实际应用还有很多关键问题需要解决,包括:
(1) 从场景描述内容角度来看,现阶段最先进的视觉场景描述模型都是有监督方法,即公开的基准数据集提供了人工标注语句作为理想输出,而实际应用中的场景数据往往是特定场合的,如记录公安侦查过程、描述学生课堂行为等.这些特殊应用中的词汇往往不能被现有公开基准数据集所涵盖,因此没有现成的语句可供参考,无法生成符合真实场景的词汇和描述语句.
(2) 从描述准确性的角度来看,生成语句的精细度取决于训练阶段和验证阶段选用的训练样本和验证样本的人工标注语句的精细程度.现实中的视觉场景可能千变万化、转瞬即逝,是否能够准确地捕捉到各个事件及其起止时间,给出相应细微变化的内容描述非常困难,如人脸微表情变化的判断与精细描述.
(3) 从场景描述的时长角度来看,现有基准数据集提供的视频多是几秒或几分钟的短视频,而在实际应用中,各类视频文件历时较长,需要能够支撑更长序列预测的模型来完成,例如在标准化考试场景中,潜在的作弊行为的关注需要持续更长时间才能捕获有用信息,这不仅涉及由短时间视频向长时间视频方法转换的问题,而且还包括了“微弱动作”的时序检测等问题.
(4) 从场景描述的语言呈现角度来看,绝大多数基准数据集提供的人工标注是英文的,少数有其他语言的标注.尽管从技术环节来看,不同语言的描述转换可以通过机器翻译的手段完成,但是不同语言间的转换结果受各国文化背景、生活习俗及表达风格等因素的影响.
(5) 从场景载体的质量角度来看,真实应用中的实际场景与训练样本集中图像、视频的质量匹配情况,以及训练资源的丰富程度(数量、质量)是决定描述语句质量的关键因素.此外,场景载体文件的低分辨率、低对比度、复杂背景和其中可能存在的不同方向、样式、颜色、对齐方式的文字信息也使场景内容的理解与描述变得复杂.
(6) 从视觉场景描述的多学科交叉角度来看,根据第1.2节和第2节,现有的场景描述技术与场景图、视觉关系检测、指示表达生成等相关技术的最新结果并未被充分应用在改善视觉场景描述语句的生成质量上.如何以管道(pipeline)方式将其集成在场景描述模型中,以及如何优化和完善深度网络的体系结构,使之能够以更少的参数、更小的内存,更快地加以训练,是未来值得深入研究的又一问题.
6 未来应用前景
视觉场景描述技术利用计算机模仿人眼的“视觉功能”和大脑的“语言功能”,以自然语言的形式自动描述视觉场景内容,有效连接了视觉信息和语言信息,是集计算机视觉、人工智能、多媒体、自然语言处理等领域的交叉性研究课题.随着更多特定场景数据集的出现,我们相信,该技术在未来 10年内会在许多行业和领域中有力地推动视频内容分析与理解的研究进程,并加速跨模态检索、视觉问答技术相关应用的发展,具有重要的应用价值,例如:
(1) 个性化教育中的学生行为分析:各类视频监控系统为代表的现代化教育设施迅速普及到传统教室、图书馆、报告厅、标准化考场等,由此产生了海量的与学习者行为、活动及状态相关的学习场景原始数据.通过视觉场景描述技术可将这些海量数据转换为文字表达的描述语句,利用跨模态检索技术准确地捕获学习者的个性化特征并综合分析不同学习者的共性特征,进而提供有针对性的评估、引导与干预.例如,在智慧课堂教学中,利用计算机实时分析统计学生行为,帮助老师及时掌握学生的学习特征和状态;在军训等集体活动中,预判学生可能发生的危险行为,提高安全防范能力;在中小学生课堂纪律维持方面,通过行为分析对学生的不良行为予以及时警告,避免其因课堂注意力不集中而导致学业警示等.
(2) 智能服务中的人机交互应用:有效的人机交互在任何服务型机器人应用中都至关重要.视觉场景描述技术提供了人机交互的自然语言交互接口.通过该技术,智能机器人能够以人类易于理解的自然语言方式来实现视觉场景内容信息的表达.另一方面,视频场景内容的自然语言描述也可以作为机器人内部场景的表现形式,为基于自然语言问答的智能环境感知提供了良好基础[76].使这些机器人可以像人一样有“感情”地进行语言表达,提供高质量的服务和陪伴是未来的研究重点之一.
(3) 视力障碍人员的辅助视听:该类应用旨在对人类活动场所中的视觉感知物体进行检测、识别、分析和判断,并给视力障碍人员予以提示,以辅助视力障碍人员顺利完成行为活动.其中,如何有效地将感知到的信息正确地传递给视力障碍人员是辅助视听应用技术的关键问题之一.如何快速、有效地感知人类活动场景中与活动相关的环境信息,通过视觉问答,并以友好的方式将相关信息传递给视力障碍人员是视觉场景描述应用中需解决的重要问题.
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
北京航空航天大学学报(2022年8期)2022-08-31
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
电影新作(2014年1期)2014-02-27
